官方源码仓库:https://github.com/ultralytics/yolov5
文章下载地址:没有
视频讲解:https://www.bilibili.com/video/BV1T3411p7zR
文章目录
在前面我们已经介绍过了YOLOv1~v4的网络的结构,今天接着上次的YOLOv4再来聊聊YOLOv5,如果还不了解YOLOv4的可以参考之前的博文。YOLOv5项目的作者是Glenn Jocher并不是原Darknet项目的作者Joseph Redmon。并且这个项目至今都没有发表过正式的论文。之前翻阅该项目的issue时,发现有很多人问过这个问题,有兴趣的可以翻翻这个issue #1333。作者当时也有说准备在2021年的12月1号之前发表,并承诺如果到时候没有发表就吃掉自己的帽子。
(⊙o⊙)…,emmm,但这都2022年了,也不知道他的帽子是啥味儿。过了他承诺的发表期限后,很多人还去该issue下表示"关怀",问啥时候吃帽子,下面这位大哥给我整笑了。
本来Glenn Jocher是准备要发表论文的,但至于为啥没发成作者并没有给出原因。我个人的猜测是自从YOLOv4发表后,有很多人想发这方面的文章,然后在YOLOv4上进行改动,改动过程中肯定有人把YOLOv5仓库里的一些技术拿去用了(YOLOv4论文4月出的,YOLOv5仓库5月就有了)。大家改完后发了一堆文章,那么YOLOv5的技术就被零零散散的发表到各个文章中去了。Glenn Jocher一看,这也太卷了吧,你们都把我技术写了,那我还写个锤子,直接撂挑子不干了。
当然以上都是我个人yy哈,回归正题,YOLOv5仓库是在2020-05-18创建的,到今天已经迭代了很多个大版本了,现在(2022-3-19)已经迭代到v6.1了。所以本篇博文讲的内容是针对v6.1的,大家阅读的时候注意看下版本号,不同的版本内容会略有不同。前几天我在YOLOv5项目中向作者提了一个issue #6998,主要是根据当前的源码做了一个简单的总结,然后想让作者帮忙看看总结的内容是否有误,根据作者的反馈应该是没啥问题的,所以今天就来谈谈我个人的见解。下表是当前(v6.1)官网贴出的关于不同大小模型以及输入尺度对应的mAP、推理速度、参数数量以及理论计算量FLOPs。
| Model | size (pixels) | mAPval 0.5:0.95 | mAPval 0.5 | Speed CPU b1 (ms) | Speed V100 b1 (ms) | Speed V100 b32 (ms) | params (M) | FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.0 | 45.7 | 45 | 6.3 | 0.6 | 1.9 | 4.5 |
| YOLOv5s | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| YOLOv5m | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
| YOLOv5l | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
| YOLOv5n6 | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
| YOLOv5s6 | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
| YOLOv5m6 | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
| YOLOv5l6 | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
| YOLOv5x6 + TTA | 1280 1536 | 55.0 55.8 | 72.7 72.7 | 3136 - | 26.2 - | 19.4 - | 140.7 - | 209.8 - |
关于YOLOv5的网络结构其实网上相关的讲解已经有很多了。网络结构主要由以下几部分组成:
New CSP-Darknet53SPPF, New CSP-PANYOLOv3 Head下面是我根据yolov5l.yaml绘制的网络整体结构,YOLOv5针对不同大小(n, s, m, l, x)的网络整体架构都是一样的,只不过会在每个子模块中采用不同的深度和宽度,分别应对yaml文件中的depth_multiple和width_multiple参数。还需要注意一点,官方除了n, s, m, l, x版本外还有n6, s6, m6, l6, x6,区别在于后者是针对更大分辨率的图片比如1280x1280,当然结构上也有些差异,后者会下采样64倍,采用4个预测特征层,而前者只会下采样到32倍且采用3个预测特征层。本博文只讨论前者。下面这幅图(yolov5l)有点大,大家可以下载下来仔细看一下。

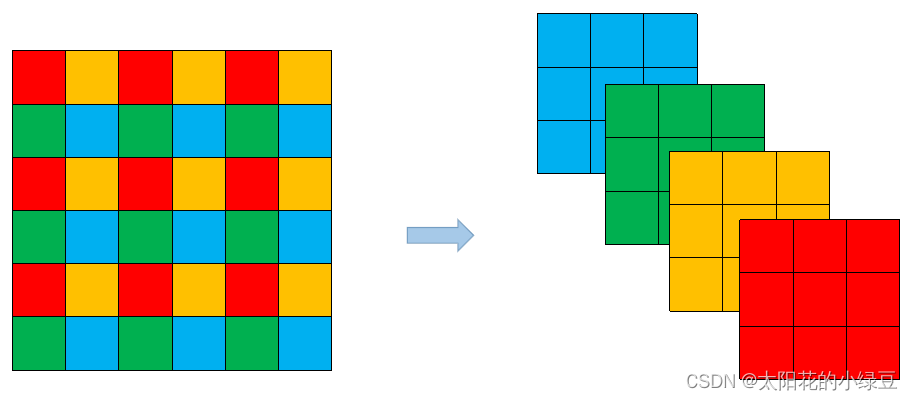
通过和上篇博文讲的YOLOv4对比,其实YOLOv5在Backbone部分没太大变化。但是YOLOv5在v6.0版本后相比之前版本有一个很小的改动,把网络的第一层(原来是Focus模块)换成了一个6x6大小的卷积层。两者在理论上其实等价的,但是对于现有的一些GPU设备(以及相应的优化算法)使用6x6大小的卷积层比使用Focus模块更加高效。详情可以参考这个issue #4825。下图是原来的Focus模块(和之前Swin Transformer中的Patch Merging类似),将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map,然后在接上一个3x3大小的卷积层。这和直接使用一个6x6大小的卷积层等效。
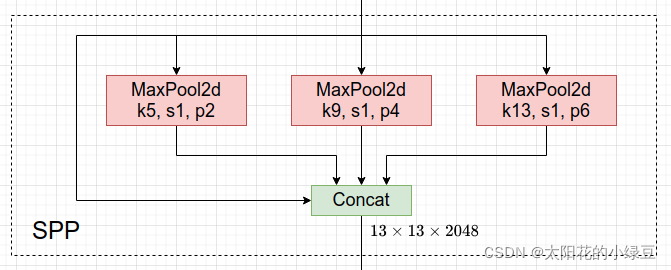
在Neck部分的变化还是相对较大的,首先是将SPP换成成了SPPF(Glenn Jocher自己设计的),这个改动我个人觉得还是很有意思的,两者的作用是一样的,但后者效率更高。SPP结构如下图所示,是将输入并行通过多个不同大小的MaxPool,然后做进一步融合,能在一定程度上解决目标多尺度问题。
而SPPF结构是将输入串行通过多个5x5大小的MaxPool层,这里需要注意的是串行两个5x5大小的MaxPool层是和一个9x9大小的MaxPool层计算结果是一样的,串行三个5x5大小的MaxPool层是和一个13x13大小的MaxPool层计算结果是一样的。
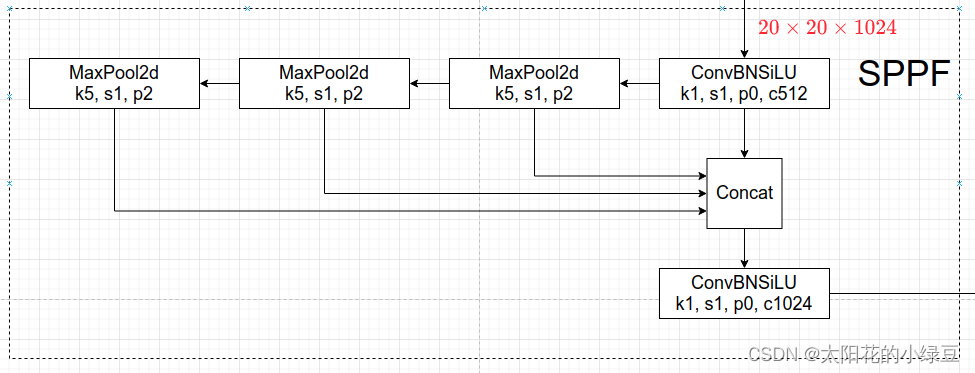
下面做个简单的小实验,对比下SPP和SPPF的计算结果以及速度,代码如下(注意这里将SPPF中最开始和结尾处的1x1卷积层给去掉了,只对比含有MaxPool的部分):
import time
import torch
import torch.nn as nn
class SPP(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)
self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)
self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)
def forward(self, x):
o1 = self.maxpool1(x)
o2 = self.maxpool2(x)
o3 = self.maxpool3(x)
return torch.cat([x, o1, o2, o3], dim=1)
class SPPF(nn.Module):
def __init__(self):
super().__init__()
self.maxpool = nn.MaxPool2d(5, 1, padding=2)
def forward(self, x):
o1 = self.maxpool(x)
o2 = self.maxpool(o1)
o3 = self.maxpool(o2)
return torch.cat([x, o1, o2, o3], dim=1)
def main():
input_tensor = torch.rand(8, 32, 16, 16)
spp = SPP()
sppf = SPPF()
output1 = spp(input_tensor)
output2 = sppf(input_tensor)
print(torch.equal(output1, output2))
t_start = time.time()
for _ in range(100):
spp(input_tensor)
print(f"spp time: {time.time() - t_start}")
t_start = time.time()
for _ in range(100):
sppf(input_tensor)
print(f"sppf time: {time.time() - t_start}")
if __name__ == '__main__':
main()
终端输出:
True
spp time: 0.5373051166534424
sppf time: 0.20780706405639648
通过对比可以发现,两者的计算结果是一模一样的,但SPPF比SPP计算速度快了不止两倍,快乐翻倍。
在Neck部分另外一个不同点就是New CSP-PAN了,在YOLOv4中,Neck的PAN结构是没有引入CSP结构的,但在YOLOv5中作者在PAN结构中加入了CSP。详情见上面的网络结构图,每个C3模块里都含有CSP结构。在Head部分,YOLOv3, v4, v5都是一样的,这里就不讲了。
在YOLOv5代码里,关于数据增强策略还是挺多的,这里简单罗列部分方法:
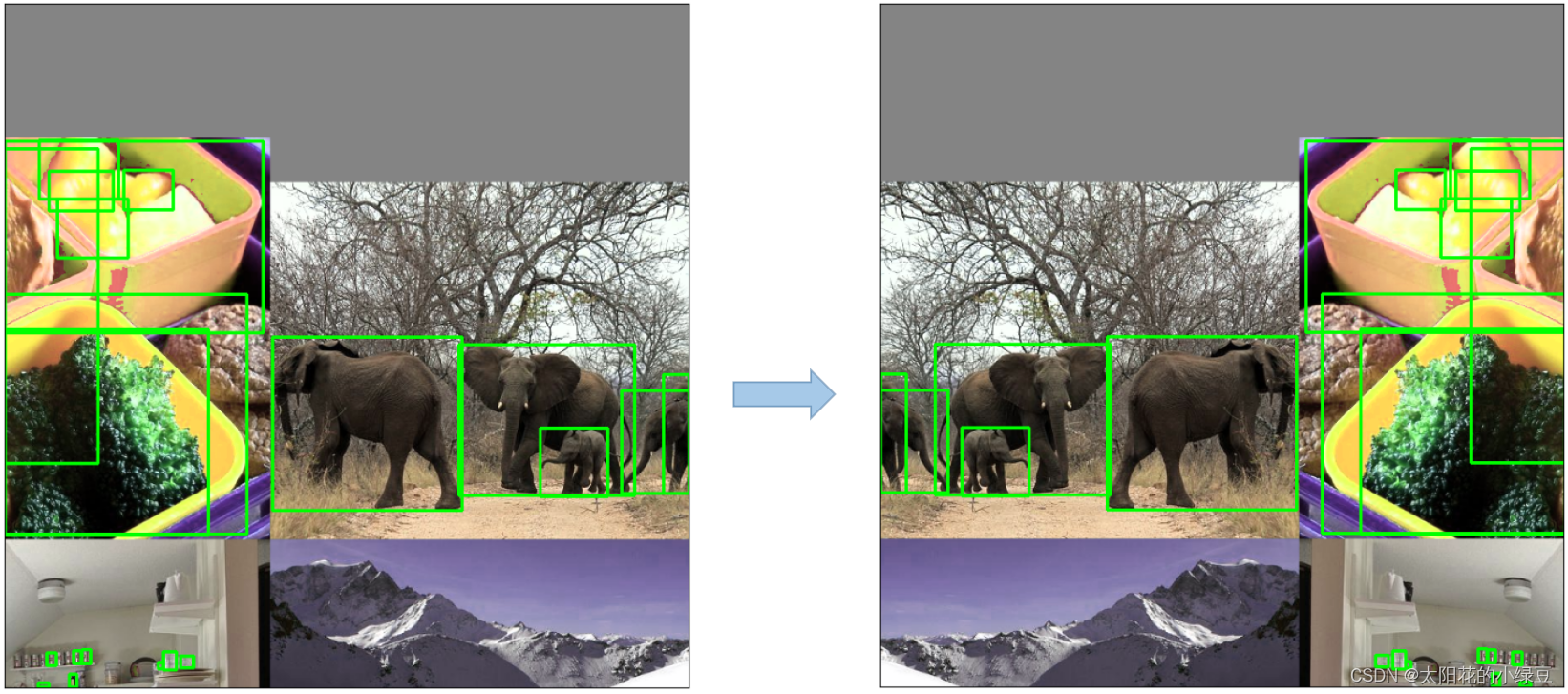
Mosaic,将四张图片拼成一张图片,讲过很多次了

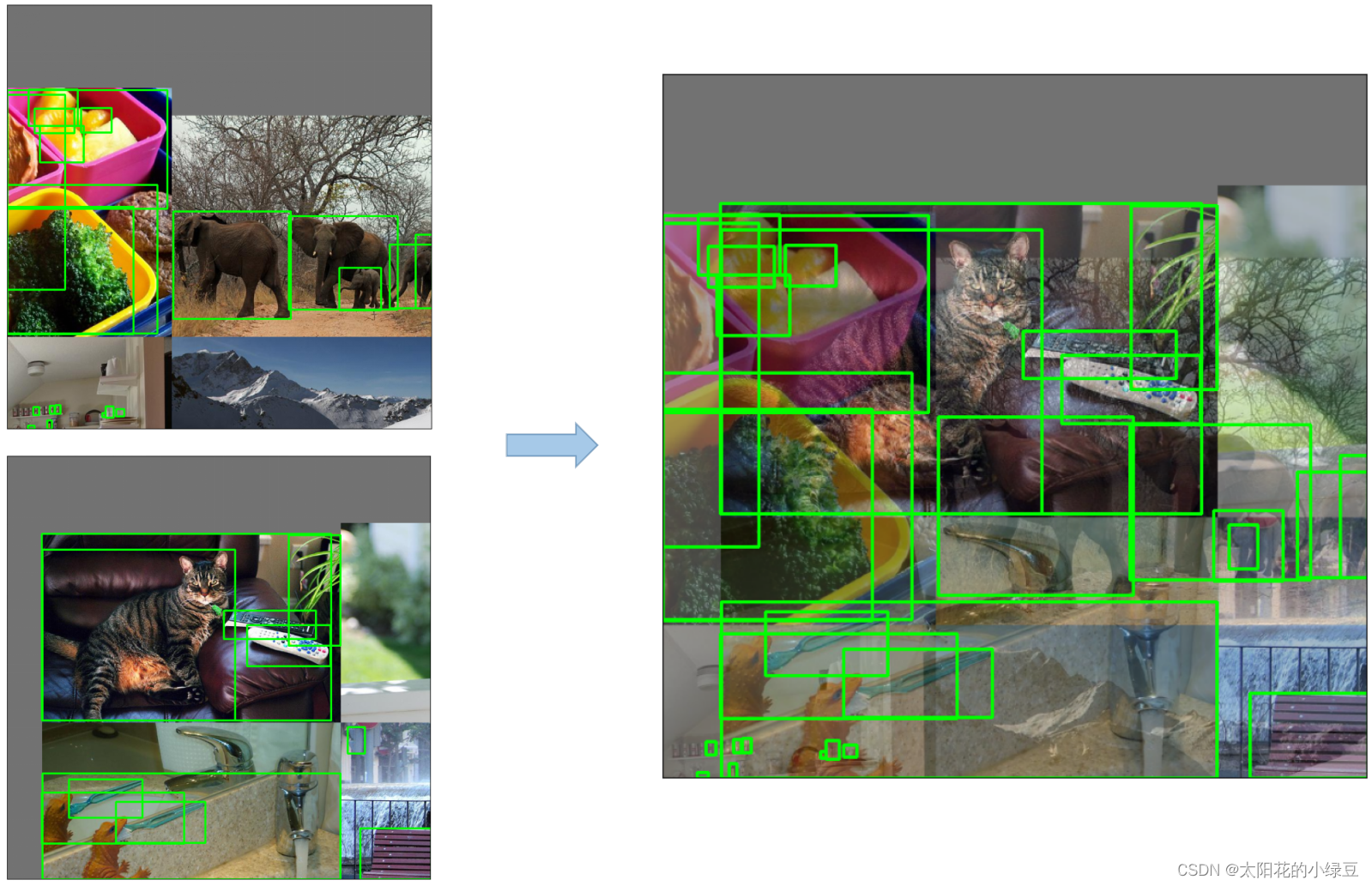
Copy paste,将部分目标随机的粘贴到图片中,前提是数据要有segments数据才行,即每个目标的实例分割信息。下面是Copy paste原论文中的示意图。

Random affine(Rotation, Scale, Translation and Shear),随机进行仿射变换,但根据配置文件里的超参数发现只使用了Scale和Translation即缩放和平移。

MixUp,就是将两张图片按照一定的透明度融合在一起,具体有没有用不太清楚,毕竟没有论文,也没有消融实验。代码中只有较大的模型才使用到了MixUp,而且每次只有10%的概率会使用到。
Albumentations,主要是做些滤波、直方图均衡化以及改变图片质量等等,我看代码里写的只有安装了albumentations包才会启用,但在项目的requirements.txt文件中albumentations包是被注释掉了的,所以默认不启用。
Augment HSV(Hue, Saturation, Value),随机调整色度,饱和度以及明度。

Random horizontal flip,随机水平翻转
在YOLOv5源码中使用到了很多训练的策略,这里简单总结几个我注意到的点,还有些没注意到的请大家自己看下源码:
Warmup热身,然后在采用Cosine学习率下降策略。YOLOv5的损失主要由三个部分组成:
BCE loss,注意只计算正样本的分类损失。obj损失,采用的依然是BCE loss,注意这里的obj指的是网络预测的目标边界框与GT Box的CIoU。这里计算的是所有样本的obj损失。CIoU loss,注意只计算正样本的定位损失。
L
o
s
s
=
λ
1
L
c
l
s
+
λ
2
L
o
b
j
+
λ
3
L
l
o
c
Loss=\lambda_1 L_{cls} + \lambda_2 L_{obj} + \lambda_3 L_{loc}
Loss=λ1Lcls+λ2Lobj+λ3Lloc
其中,
λ
1
,
λ
2
,
λ
3
\lambda_1, \lambda_2, \lambda_3
λ1,λ2,λ3为平衡系数。
这里是指针对三个预测特征层(P3, P4, P5)上的obj损失采用不同的权重。在源码中,针对预测小目标的预测特征层(P3)采用的权重是4.0,针对预测中等目标的预测特征层(P4)采用的权重是1.0,针对预测大目标的预测特征层(P5)采用的权重是0.4,作者说这是针对COCO数据集设置的超参数。
L
o
b
j
=
4.0
⋅
L
o
b
j
s
m
a
l
l
+
1.0
⋅
L
o
b
j
m
e
d
i
u
m
+
0.4
⋅
L
o
b
j
l
a
r
g
e
L_{obj} = 4.0 \cdot L_{obj}^{small} + 1.0 \cdot L_{obj}^{medium} + 0.4 \cdot L_{obj}^{large}
Lobj=4.0⋅Lobjsmall+1.0⋅Lobjmedium+0.4⋅Lobjlarge
在上篇文章YOLOv4中有提到过,主要是调整预测目标中心点相对Grid网格的左上角偏移量。下图是YOLOv2,v3的计算公式。

其中:
Sigmoid激活函数,将预测的偏移量限制在0到1之间,即预测的中心点不会超出对应的Grid Cell区域关于预测目标中心点相对Grid网格左上角
(
c
x
,
c
y
)
(c_x, c_y)
(cx,cy)偏移量为
σ
(
t
x
)
,
σ
(
t
y
)
\sigma(t_x), \sigma(t_y)
σ(tx),σ(ty)。YOLOv4的作者认为这样做不太合理,比如当真实目标中心点非常靠近网格的左上角点(
σ
(
t
x
)
\sigma(t_x)
σ(tx)和
σ
(
t
y
)
\sigma(t_y)
σ(ty)应该趋近与0)或者右下角点(
σ
(
t
x
)
\sigma(t_x)
σ(tx)和
σ
(
t
y
)
\sigma(t_y)
σ(ty)应该趋近与1)时,网络的预测值需要负无穷或者正无穷时才能取到,而这种很极端的值网络一般无法达到。为了解决这个问题,作者对偏移量进行了缩放从原来的
(
0
,
1
)
(0, 1)
(0,1)缩放到
(
−
0.5
,
1.5
)
(-0.5, 1.5)
(−0.5,1.5)这样网络预测的偏移量就能很方便达到0或1,故最终预测的目标中心点
b
x
,
b
y
b_x, b_y
bx,by的计算公式为:
b
x
=
(
2
⋅
σ
(
t
x
)
−
0.5
)
+
c
x
b
y
=
(
2
⋅
σ
(
t
y
)
−
0.5
)
+
c
y
b_x = (2 \cdot \sigma(t_x) - 0.5) + c_x \\ b_y = (2 \cdot \sigma(t_y) - 0.5) + c_y
bx=(2⋅σ(tx)−0.5)+cxby=(2⋅σ(ty)−0.5)+cy
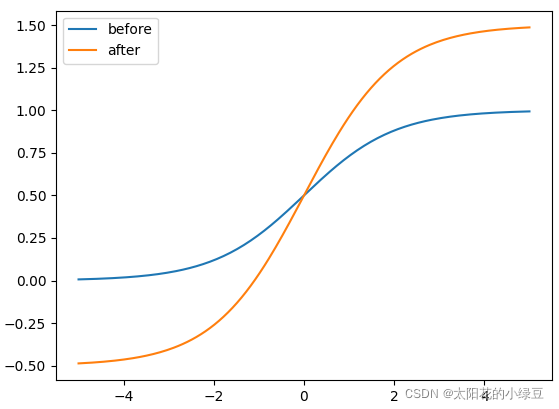
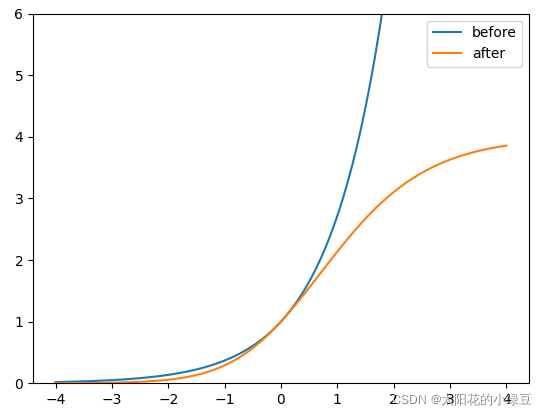
下图是我绘制的
y
=
σ
(
x
)
y = \sigma(x)
y=σ(x)对应before曲线和
y
=
2
⋅
σ
(
x
)
−
0.5
y = 2 \cdot \sigma(x) - 0.5
y=2⋅σ(x)−0.5对应after曲线,很明显通过引入缩放系数scale以后,
y
y
y对
x
x
x更敏感了,且偏移的范围由原来的
(
0
,
1
)
(0, 1)
(0,1)调整到了
(
−
0.5
,
1.5
)
(-0.5, 1.5)
(−0.5,1.5)。
在YOLOv5中除了调整预测Anchor相对Grid网格左上角
(
c
x
,
c
y
)
(c_x, c_y)
(cx,cy)偏移量以外,还调整了预测目标高宽的计算公式,之前是:
b
w
=
p
w
⋅
e
t
w
b
h
=
p
h
⋅
e
t
h
b_w = p_w \cdot e^{t_w} \\ b_h = p_h \cdot e^{t_h}
bw=pw⋅etwbh=ph⋅eth
在YOLOv5调整为:
b
w
=
p
w
⋅
(
2
⋅
σ
(
t
w
)
)
2
b
h
=
p
h
⋅
(
2
⋅
σ
(
t
h
)
)
2
b_w = p_w \cdot (2 \cdot \sigma(t_w))^2 \\ b_h = p_h \cdot (2 \cdot \sigma(t_h))^2
bw=pw⋅(2⋅σ(tw))2bh=ph⋅(2⋅σ(th))2
作者Glenn Jocher的原话如下,也可以参考issue #471:
The original yolo/darknet box equations have a serious flaw. Width and Height are completely unbounded as they are simply out=exp(in), which is dangerous, as it can lead to runaway gradients, instabilities, NaN losses and ultimately a complete loss of training.
作者的大致意思是,原来的计算公式并没有对预测目标宽高做限制,这样可能出现梯度爆炸,训练不稳定等问题。下图是修改前
y
=
e
x
y = e^x
y=ex和修改后
y
=
(
2
⋅
σ
(
x
)
)
2
y = (2 \cdot \sigma(x))^2
y=(2⋅σ(x))2(相对Anchor宽高的倍率因子)的变化曲线, 很明显调整后倍率因子被限制在
(
0
,
4
)
(0, 4)
(0,4)之间。
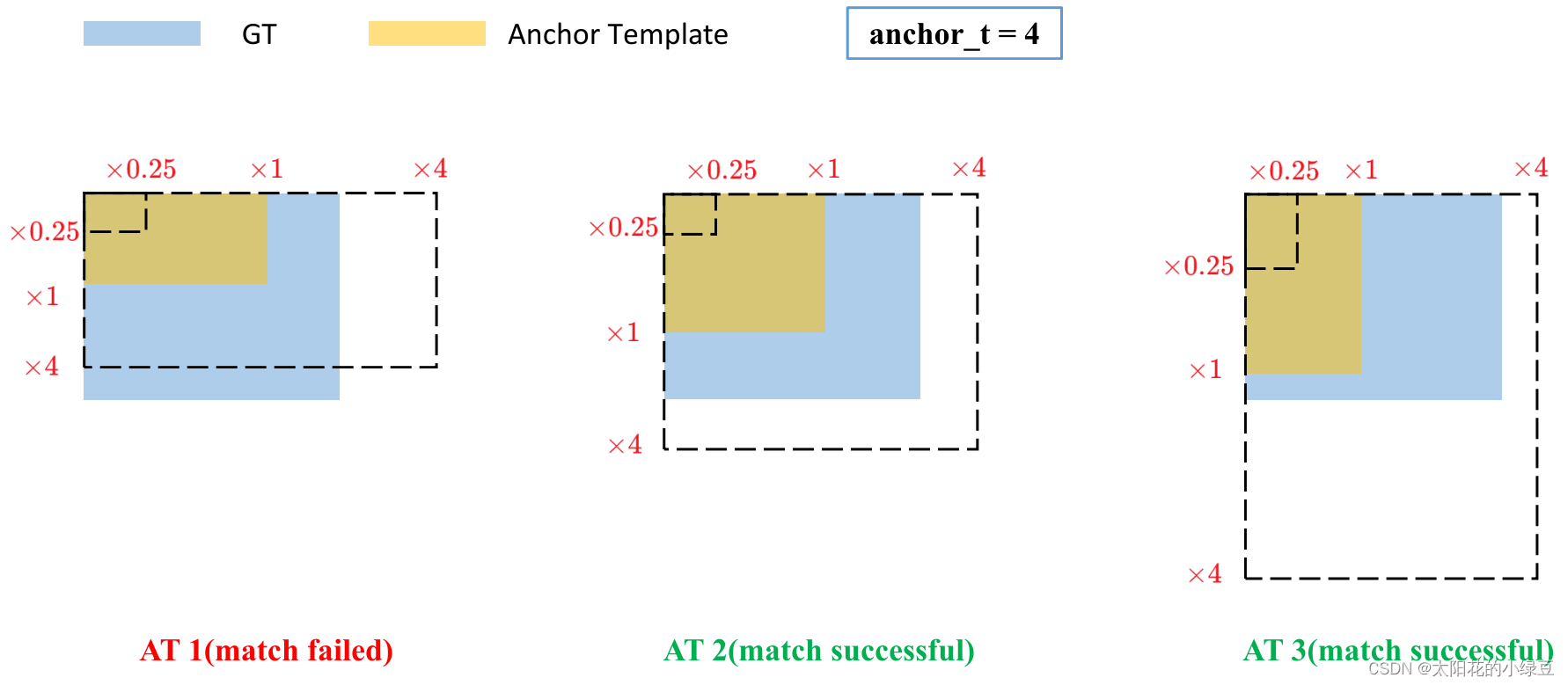
之前在YOLOv4介绍中有讲过该部分内容,其实YOLOv5也差不多。主要的区别在于GT Box与Anchor Templates模板的匹配方式。在YOLOv4中是直接将每个GT Box与对应的Anchor Templates模板计算IoU,只要IoU大于设定的阈值就算匹配成功。但在YOLOv5中,作者先去计算每个GT Box与对应的Anchor Templates模板的高宽比例,即:
r
w
=
w
g
t
/
w
a
t
r
h
=
h
g
t
/
h
a
t
r_w = w_{gt} / w_{at} \\ r_h = h_{gt} / h_{at} \\
rw=wgt/watrh=hgt/hat
然后统计这些比例和它们倒数之间的最大值,这里可以理解成计算GT Box和Anchor Templates分别在宽度以及高度方向的最大差异(当相等的时候比例为1,差异最小):
r
w
m
a
x
=
m
a
x
(
r
w
,
1
/
r
w
)
r
h
m
a
x
=
m
a
x
(
r
h
,
1
/
r
h
)
r_w^{max} = max(r_w, 1 / r_w) \\ r_h^{max} = max(r_h, 1 / r_h)
rwmax=max(rw,1/rw)rhmax=max(rh,1/rh)
接着统计
r
w
m
a
x
r_w^{max}
rwmax和
r
h
m
a
x
r_h^{max}
rhmax之间的最大值,即宽度和高度方向差异最大的值:
r
m
a
x
=
m
a
x
(
r
w
m
a
x
,
r
h
m
a
x
)
r^{max} = max(r_w^{max}, r_h^{max})
rmax=max(rwmax,rhmax)
如果GT Box和对应的Anchor Template的
r
m
a
x
r^{max}
rmax小于阈值anchor_t(在源码中默认设置为4.0),即GT Box和对应的Anchor Template的高、宽比例相差不算太大,则将GT Box分配给该Anchor Template模板。为了方便大家理解,可以看下我画的图。假设对某个GT Box而言,其实只要GT Box满足在某个Anchor Template宽和高的
×
0.25
\times 0.25
×0.25倍和
×
4.0
\times 4.0
×4.0倍之间就算匹配成功。
剩下的步骤和YOLOv4中一致:
GT投影到对应预测特征层上,根据GT的中心点定位到对应Cell,注意图中有三个对应的Cell。因为网络预测中心点的偏移范围已经调整到了
(
−
0.5
,
1.5
)
(-0.5, 1.5)
(−0.5,1.5),所以按理说只要Grid Cell左上角点距离GT中心点在
(
−
0.5
,
1.5
)
(−0.5,1.5)
(−0.5,1.5)范围内它们对应的Anchor都能回归到GT的位置处。这样会让正样本的数量得到大量的扩充。Cell对应的AT2和AT3都为正样本。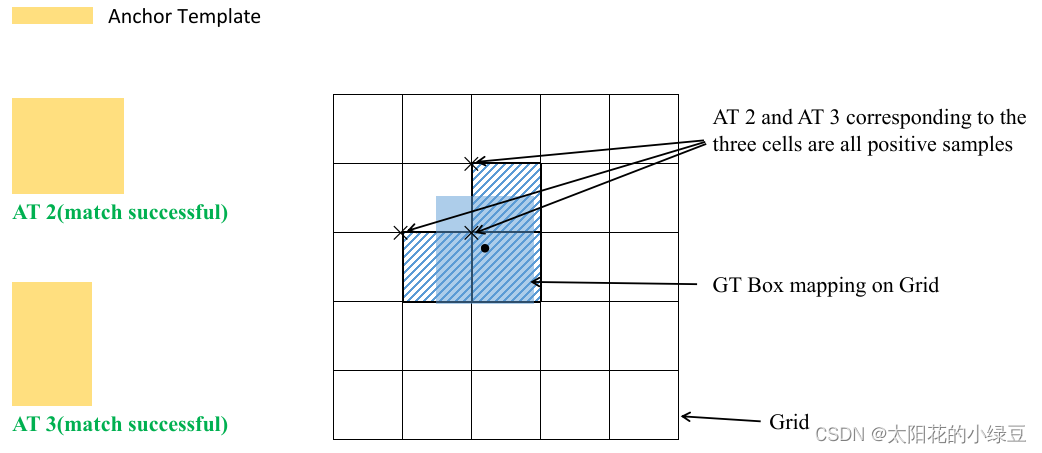
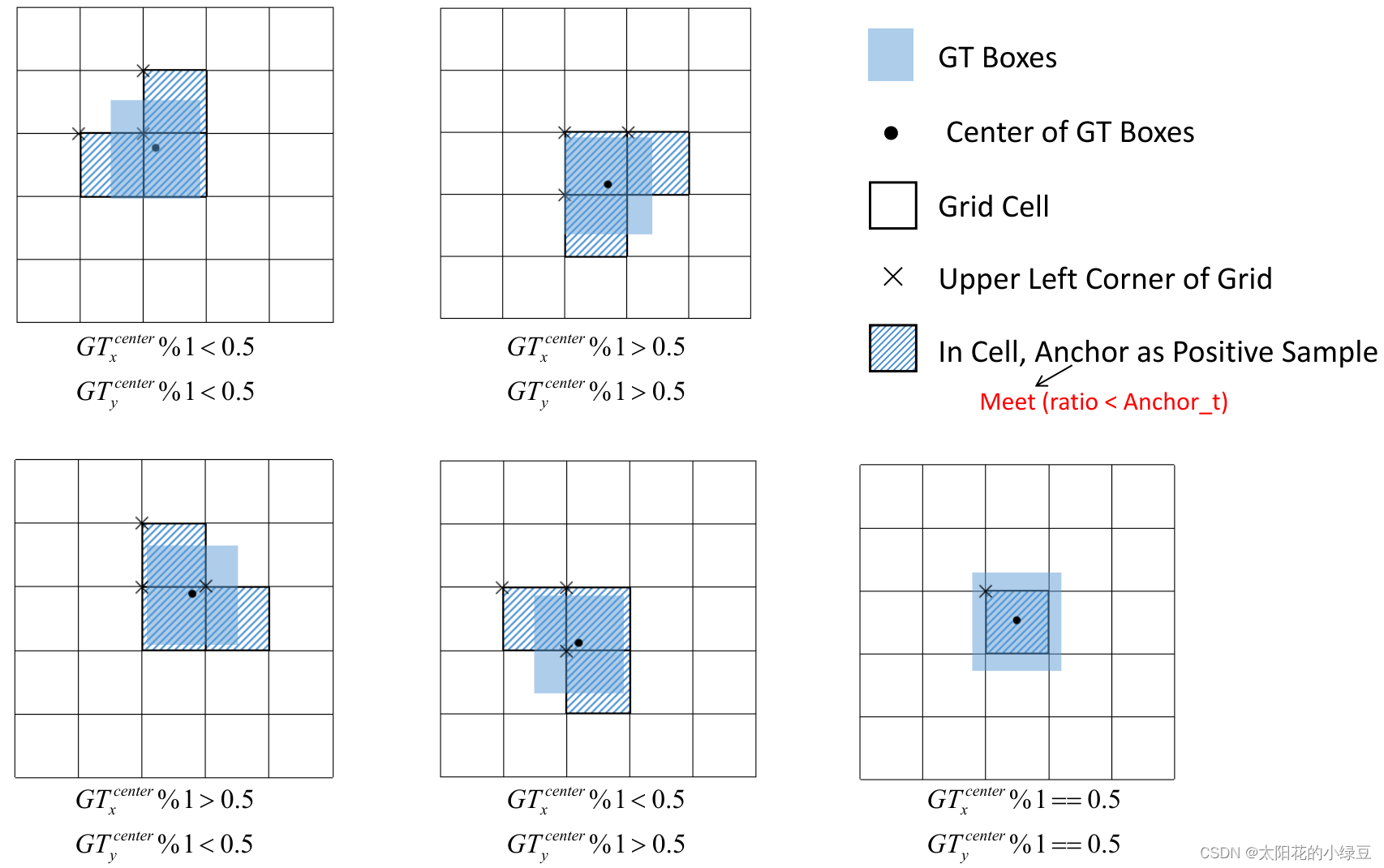
还需要注意的是,YOLOv5源码中扩展Cell时只会往上、下、左、右四个方向扩展,不会往左上、右上、左下、右下方向扩展。下面又给出了一些根据
G
T
x
c
e
n
t
e
r
,
G
T
y
c
e
n
t
e
r
GT_x^{center}, GT_y^{center}
GTxcenter,GTycenter的位置扩展的一些Cell案例,其中%1表示取余并保留小数部分。
到此,YOLOv5相关的内容基本上都分析完了。当然由于个人原因,肯定还有一些细节被我忽略掉了,也建议大家自己看看源码,收获肯定会更多。
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
是否可以在不实际下载文件的情况下检查文件是否存在?我有这么大的(~40mb)文件,例如:http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm这与ruby不严格相关,但如果发件人可以设置内容长度就好了。RestClient.get"http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm",headers:{"Content-Length"=>100} 最佳答案
我在这方面尝试了很多URL,在我遇到这个特定的之前,它们似乎都很好:require'rubygems'require'nokogiri'require'open-uri'doc=Nokogiri::HTML(open("http://www.moxyst.com/fashion/men-clothing/underwear.html"))putsdoc这是结果:/Users/macbookair/.rvm/rubies/ruby-2.0.0-p481/lib/ruby/2.0.0/open-uri.rb:353:in`open_http':404NotFound(OpenURI::HT
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
(本文是网络的宏观的概念铺垫)目录计算机网络背景网络发展认识"协议"网络协议初识协议分层OSI七层模型TCP/IP五层(或四层)模型报头以太网碰撞路由器IP地址和MAC地址IP地址与MAC地址总结IP地址MAC地址计算机网络背景网络发展 是最开始先有的计算机,计算机后来因为多项技术的水平升高,逐渐的计算机变的小型化、高效化。后来因为计算机其本身的计算能力比较的快速:独立模式:计算机之间相互独立。 如:有三个人,每个人做的不同的事物,但是是需要协作的完成。 而这三个人所做的事是需要进行协作的,然而刚开始因为每一台计算机之间都是互相独立的。所以前面的人处理完了就需要将数据
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
安全产品安全网关类防火墙Firewall防火墙防火墙主要用于边界安全防护的权限控制和安全域的划分。防火墙•信息安全的防护系统,依照特定的规则,允许或是限制传输的数据通过。防火墙是一个由软件和硬件设备组合而成,在内外网之间、专网与公网之间的界面上构成的保护屏障。下一代防火墙•下一代防火墙,NextGenerationFirewall,简称NGFirewall,是一款可以全面应对应用层威胁的高性能防火墙,提供网络层应用层一体化安全防护。生产厂家•联想网御、CheckPoint、深信服、网康、天融信、华为、H3C等防火墙部署部署于内、外网编辑额,用于权限访问控制和安全域划分。UTM统一威胁管理(Un
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
Linux操作系统——网络配置与SSH远程安装完VMware与系统后,需要进行网络配置。第一个目标为进行SSH连接,可以从本机到VMware进行文件传送,首先需要进行网络配置。1.下载远程软件首先需要先下载安装一款远程软件:FinalShell或者xhell7FinalShellxhell7FinalShell下载:Windows下载http://www.hostbuf.com/downloads/finalshell_install.exemacOS下载http://www.hostbuf.com/downloads/finalshell_install.pkg2.配置CentOS网络安装好