第十三章 DFS与BFS
DFS即Depth First Search,深度优先搜索。简单地理解为一条路走到黑。那么什么叫一条路走到黑呢?假设我们想在如下的地图中走出一条最长的路,那么最粗暴的方式就是枚举出每一种情况。
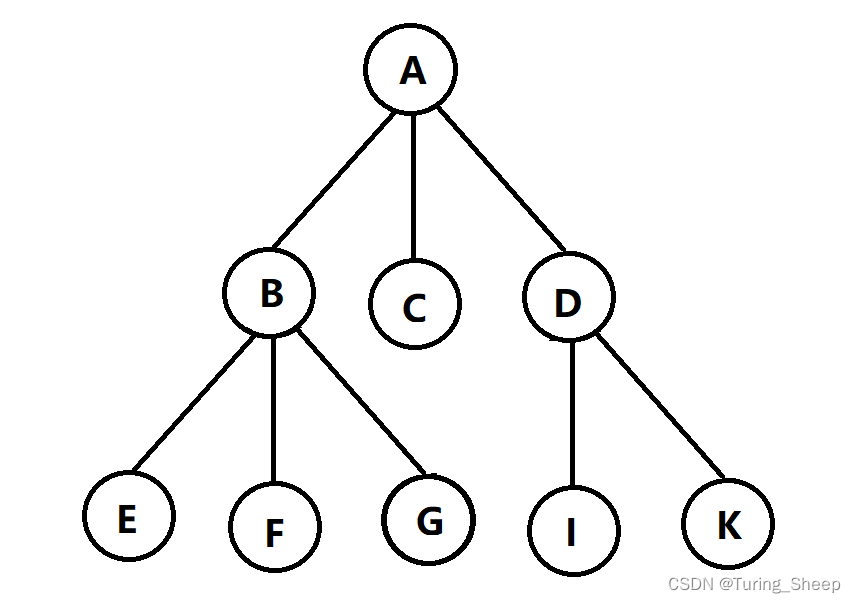
因此,按照DFS一条路走到黑的思想,我们将会出现如下路线:
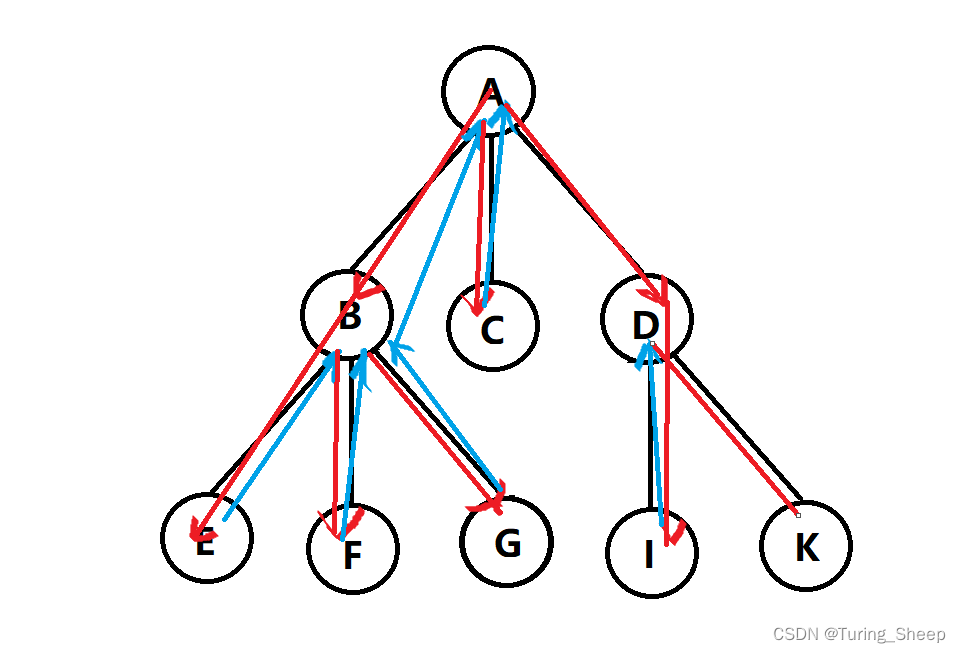
先走A,然后到B,到了B有三种情况,意味着这条路还没走完,那我就接着走,从B走到E,走到E之后没路了。那我就回溯到B,为什么呢?
因为我原本走到B的时候就有三种情况,但是刚刚只走了一种情况,因此我要回到B再去尝试第二条路,于是我们就从E回到B,然后从B去F。到了F,又没路了,那我们就回到B走第三种情况,从B到G。这样我们就走完了从A->B的三种情况。又因为在A处其实还有三种情况,因此我们走完B的三种情况后,回到A,去走除了从A->B的第二种情况,即A->C。由此以往。
简而言之,就是我们一头扎进去,撞了南墙,我就退一步,但是决不放弃,在原基础上做出局部的改变去尝试第二条路,直到所有的情况我都试了,实在没有其他情况了,那我就回到A,从头出发,再做选择,再一头扎进去,直到成功。
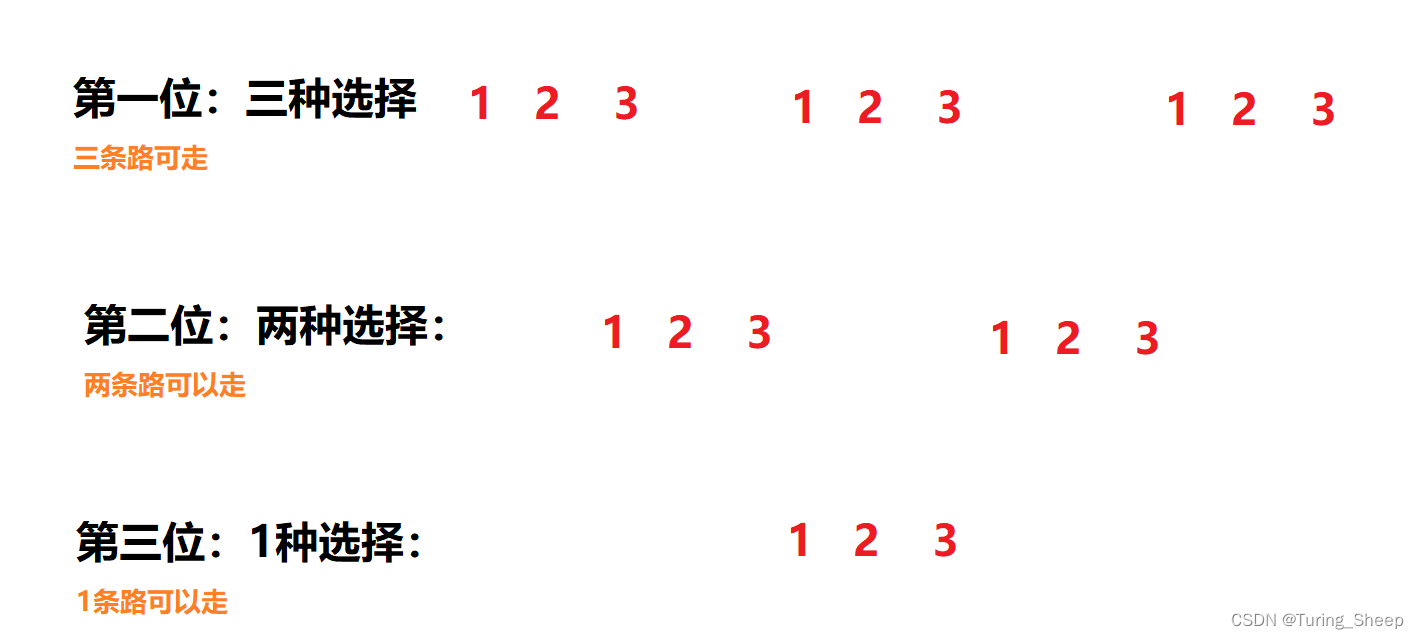
我们将其各种选择,继续画成一棵树:
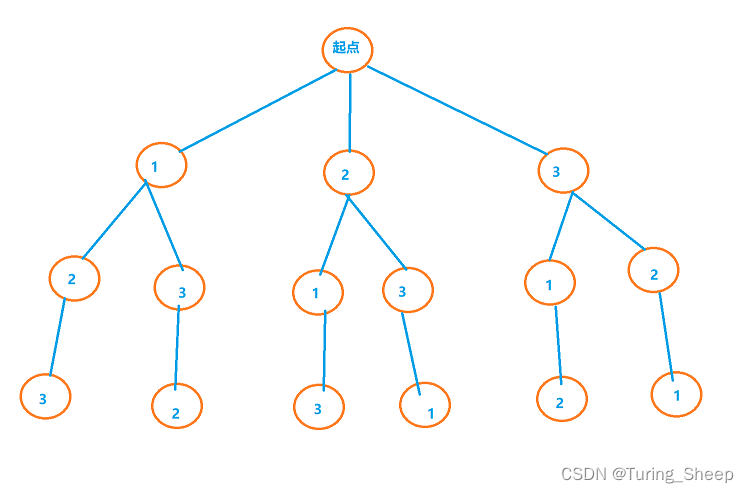
这张图就清晰很多了,因此想要用DFS,我们首先要有逻辑地画出一张地图,有了地图才能去搜。
#include<iostream>
using namespace std;
const int N=10;
int ans[N];
bool mark[N];
int n;
void dfs(int u)
{
//"回头"的条件
if(u==n)
{
for(int i=0;i<n;i++)cout<<ans[i]<<" ";
puts("");
return;
}
for(int i=1;i<=n;i++)
{
if(mark[i]==false)
{
mark[i]=true;
ans[u]=i;
dfs(u+1);
//复原
mark[i]=false;
ans[u]=0;
}
}
}
int main()
{
cin>>n;
dfs(0);
return 0;
}
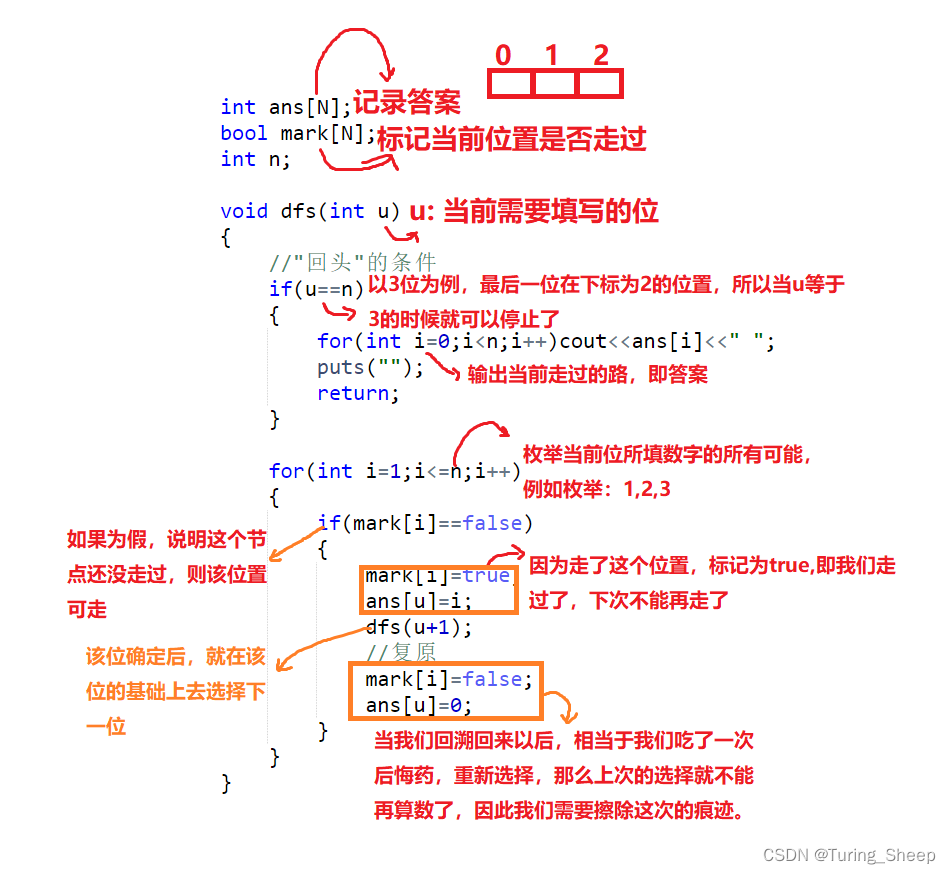
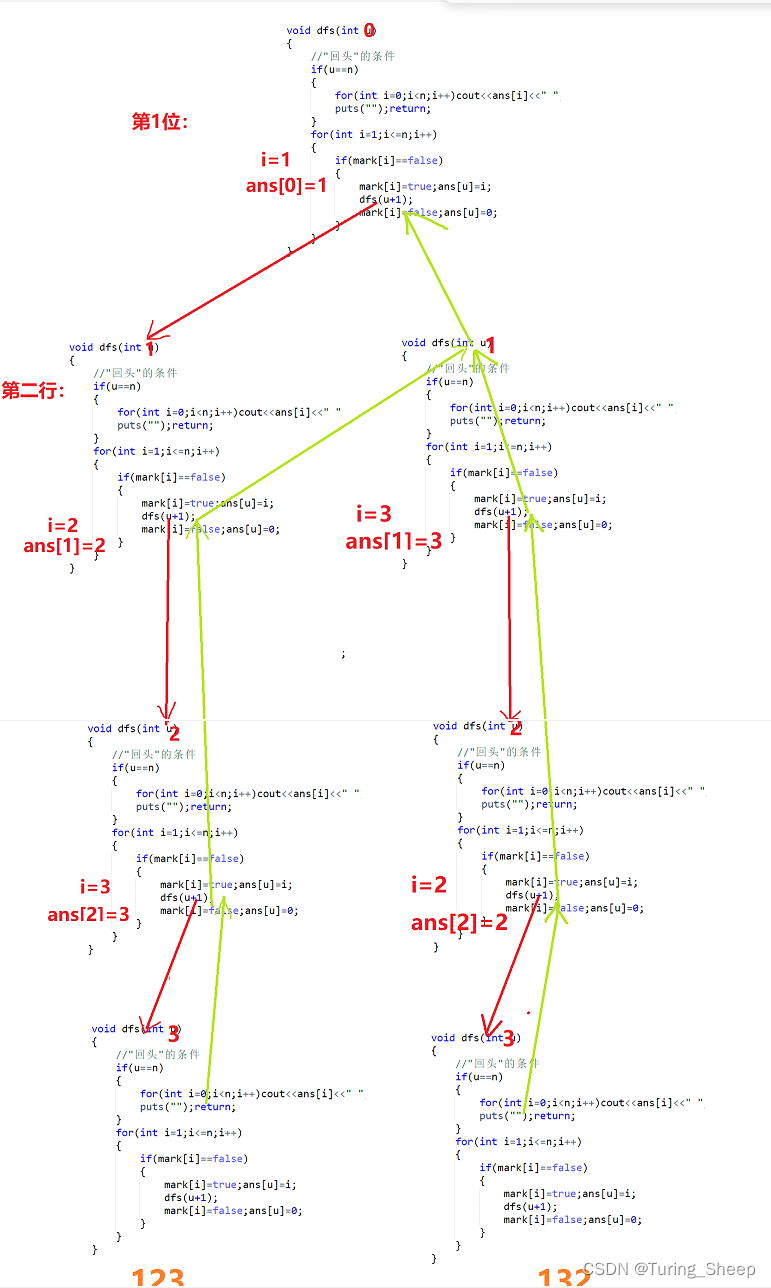
当然这个过程很抽象,那么我就帮大家模拟一下函数进行的过程吧^ _ ^(这里只模拟一部分,不理解的读者可自己模拟完。)
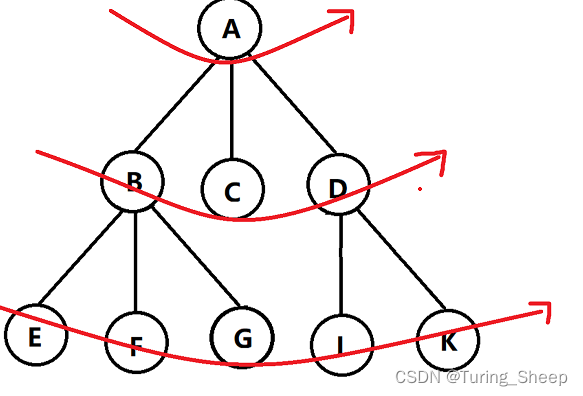
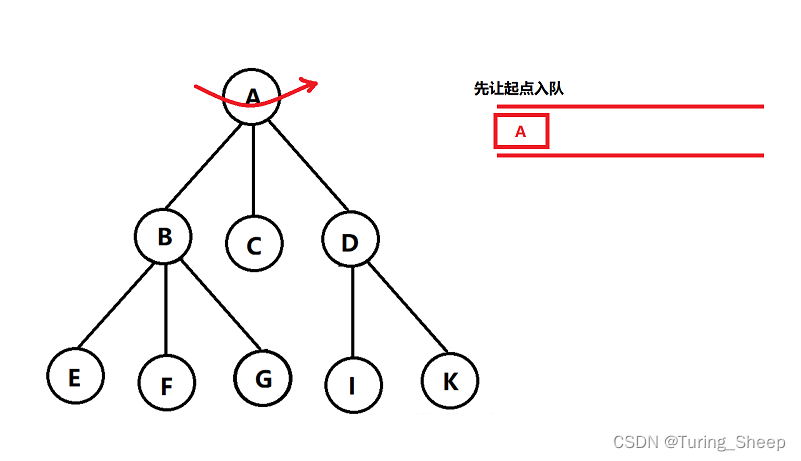
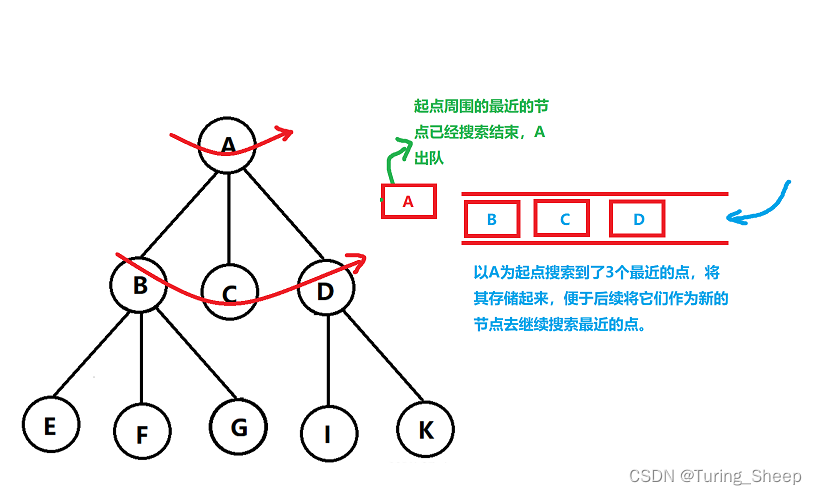
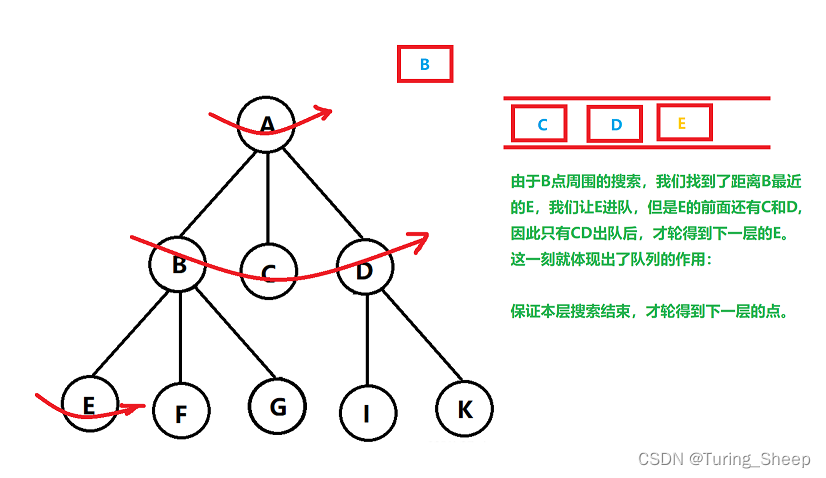
BFS即Breadth First Search,即广度优先搜索。如果说DFS是一条路走到黑的话,BFS就完全相反了。BFS会在每个岔路口都各向前走一步。因此其遍历顺序如下图所示:
我们发现每次搜索的位置都是距离当前节点最近的点。因此,BFS是具有最短路的性质的。为什么呢?这就类似于我们后面要学习的贪心策略。这里简单地介绍一下贪心,假设我们可以做出12次选择。我们想得到一个最好的方案。那么我们可以在第一次选择的时候,做出当前最好的选择,在第二次选择的时候,再做出那时候最好的选择,由此积累。当我们在每次的选择面前,都做到了当前最好的选择,那么我们就可以由局部最优推出整体最优。
这里也是类似的,我们可以在每次出发的时候,走到离自己最近的点,由此我们每次都保证走最近的,那从局部最近推整体最近,必有一条路是整体最近的。所以我们可以利用BFS做最短路问题。

本题求的是最短路,因此我们可以利用BFS从当前节点出发,每次都向周围拓展。
#include<iostream>
#include<cstring>
#include<queue>
using namespace std;
const int N=110;
typedef pair<int,int> PII;
int map[N][N],mark[N][N];
int dx[4]={-1,0,1,0},dy[4]={0,1,0,-1},n,m,ans;
void bfs()
{
memset(mark,-1,sizeof mark);
queue<PII>q;
q.push({0,0});
mark[0][0]=0;
while(!q.empty())
{
PII top=q.front();
for(int i=0;i<4;i++)
{
int nex=top.first+dx[i],ney=top.second+dy[i];
if(nex>=0&&nex<n&&ney>=0&&ney<m&&mark[nex][ney]==-1&&map[nex][ney]==0)
{
mark[nex][ney]=mark[top.first][top.second]+1;
q.push({nex,ney});
}
}
q.pop();
}
cout<<mark[n-1][m-1];
}
int main()
{
cin>>n>>m;
for(int i=0;i<n;i++)
{
for(int j=0;j<m;j++)
{
scanf("%d",&map[i][j]);
}
}
bfs();
}

BFS要保证的第一件事就是我们需要先走最近的,因此,队列的作用就是基于此的。
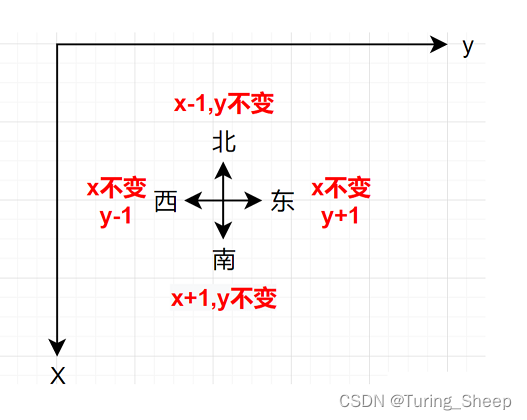
我们将上面的方向变化可以写成如下的数组:

我们每个点都是同时向外拓展一步,并且只拓展一次。那么我们将其速度看作1步/次。每个点都向外探索一次。那么此时我们的次数可以类比为时间,由此每条路的速度和时间都是一样的,因此每条路的路程都是一样的。
而各个点都是从起点开始扩散的。我们看下面的例子:
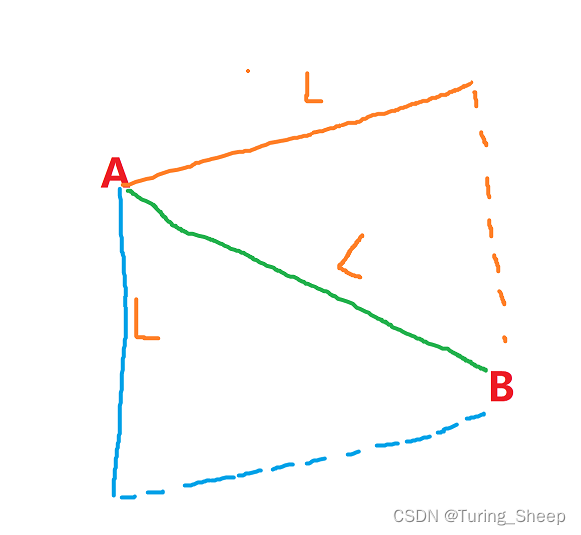
某时刻,绿色线到达了B点,此时各个路线的长度都是L,那么接下来再走的话,蓝色线的路程和黄色线的路程只会更长,因此其再到达B点的时候,必不如绿色线近。== 因此,第一次到达某个点的路线,就是最短的路线 ==
由于mark数组中的点,踩过一次后,就不许再经过了。于是,我们惊奇地发现,每个点记录的路程都是从起点到该点的最短路!!!
电脑0x0000001A蓝屏错误怎么U盘重装系统教学分享。有用户电脑开机之后遇到了系统蓝屏的情况。系统蓝屏问题很多时候都是系统bug,只有通过重装系统来进行解决。那么蓝屏问题如何通过U盘重装新系统来解决呢?来看看以下的详细操作方法教学吧。 准备工作: 1、U盘一个(尽量使用8G以上的U盘)。 2、一台正常联网可使用的电脑。 3、ghost或ISO系统镜像文件(Win10系统下载_Win10专业版_windows10正式版下载-系统之家)。 4、在本页面下载U盘启动盘制作工具:系统之家U盘启动工具。 U盘启动盘制作步骤: 注意:制作期间,U盘会被格式化,因此U盘中的重要文件请注
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式
目录一、安装包链接二、安装详细步骤1.安装Wireshark和WinPcap2.安装OracleVMVirtualBox3.安装ensp三、安装后注册四、启动路由器出现40错误怎么解决一、安装包链接二、安装详细步骤链接:https://pan.baidu.com/s/1QbUUYMOMIV2oeIKHWP1SpA?pwd=xftx提取码:xftx1.安装Wireshark和WinPcap找到Wireshark安装包所在文件夹,双击它,按照以下步骤安装。2.安装OracleVMVirtualBox找到OracleVMVirtualBox安装包所在文件夹,双击它,按照以下步骤安装。注:可自定义安装
Nginx安装1.官网下载Nginx2.使用XShell和Xftp将压缩包上传到Linux虚拟机中3.解压文件nginx-1.20.2.tar.gz4.配置nginx5.启动nginx6.拓展(修改端口和常用命令)(一)修改nginx端口(二)常用命令1.官网下载Nginxhttp://nginx.org/en/download.html这里我下载的是1.20.2版本,大家按需下载对应稳定版即可2.使用XShell和Xftp将压缩包上传到Linux虚拟机中没有XShell可以参考《Linux操作系统CentOS7连接XShell》3.解压文件nginx-1.20.2.tar.gz1)检查是否存
因学习需要用到keras,通过查找较多资料最终完成Anaconda、TensorFlow和Keras的简单安装。因为网上的相关资料较多但大部分不够全面,查找起来不太方便,因此自己记录一下成功下载安装的详细过程,顺便推荐一下借鉴的写的很好的相关教程文章。keras需要在TensorFlow之上才能运行,所以要先安装TensorFlow,而TensorFlow只能在3.7以前的python版本中运行,所以需要先创建一个基于python3.6的虚拟环境,因此便需要先下载Anaconda。一、Anaconda3下载和安装Anaconda下载安装教程原文链接:https://blog.csdn.net/
【动态规划】一、背包问题1.背包问题总结1)动规四部曲:2)递推公式总结:3)遍历顺序总结:2.01背包1)二维dp数组代码实现2)一维dp数组代码实现3.完全背包代码实现4.多重背包代码实现一、背包问题1.背包问题总结暴力的解法是指数级别的时间复杂度。进而才需要动态规划的解法来进行优化!背包问题是动态规划(DynamicPlanning)里的非常重要的一部分,关于几种常见的背包,其关系如下:在解决背包问题的时候,我们通常都是按照如下五部来逐步分析,把这五部都搞透了,算是对动规来理解深入了。1)动规四部曲:(1)确定dp数组及其下标的含义(2)确定递推公式(3)dp数组的初始化(4)确定遍历顺
1.深度优先搜索(DFS)深度优先遍历主要思路是从图中一个未访问的顶点V开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底…,不断递归重复此过程,直到所有的顶点都遍历完成。例题P1605迷宫题目描述给定一个N×MN\timesMN×M方格的迷宫,迷宫里有TTT处障碍,障碍处不可通过。在迷宫中移动有上下左右四种方式,每次只能移动一个方格。数据保证起点上没有障碍。给定起点坐标和终点坐标,每个方格最多经过一次,问有多少种从起点坐标到终点坐标的方案。输入格式第一行为三个正整数N,M,TN,M,TN,M,T,分别表示迷宫的长宽和障碍总数。第二行为四个正整数SX,S