这篇文章本身是图匹配经典论文《Factorized Graph Matching》的阅读笔记,后来发现该文介绍并串联了许多图匹配相关的知识,甚至可以看作一个小小的综述性文章,因此就作为图匹配的学习笔记了。因为笔者本人才疏学浅,对于图匹配也是刚刚开始接触,所以文章内容难免存在纰漏和错误,也欢迎各位朋友批评指正。
目录
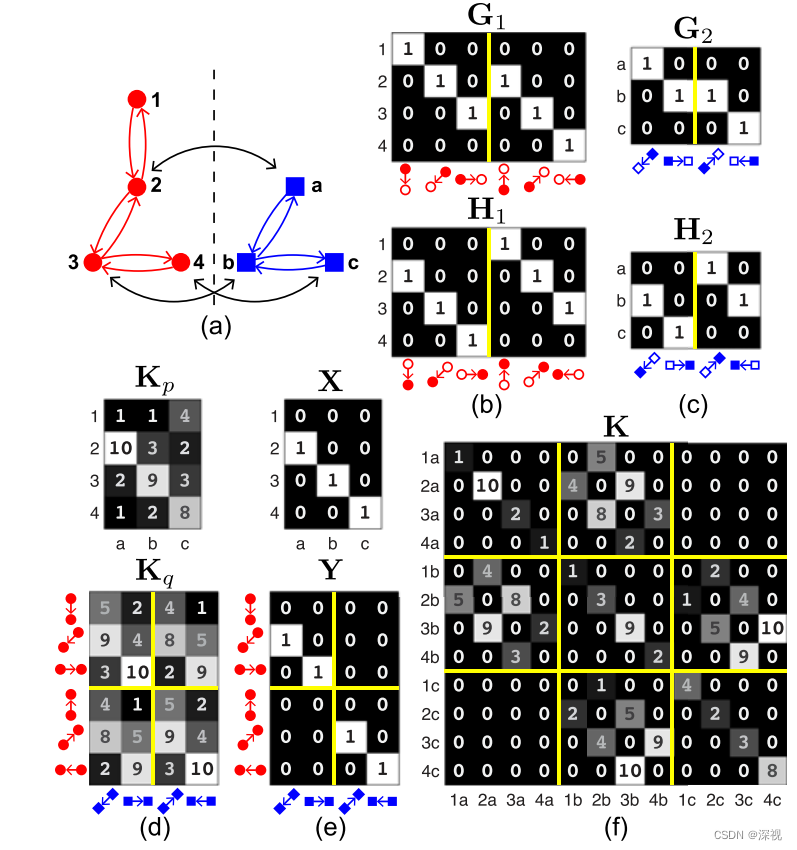
如图(a)所示,图匹配就是将两个图中的各个节点一一对应起来,不仅要求匹配的节点相似度高,而且要求节点之间的连线,也就是边的相似度也要高。图匹配问题可以分成两个类别,一个是精确图匹配(Exact Graph Matching),其要求每个节点和对应的边都准确的与另一个图匹配对应,且相似度达到最高。这个约束是非常严格的,求解的难度很大,而且在实际应用中也很少存在这种情况,因此近些年已经很少有人研究和关注精确图匹配问题了。另一个是非精确图匹配(Inexact Graph Matching),他将图匹配问题转化为寻找能够使的节点相似度和边相似度之和最大化的一个优化问题。 也就是说其允许两个图有差别,甚至允许一定程度的错误匹配,但要求能让节点和边的相似度尽可能的大。这为图匹配的求解带来了可能,也带动了相关研究的发展。下面给出图匹配形式化的定义。
在定义图匹配之前,我们首先明确图的描述方式。这里我们选择《Factorized Graph Matching》(FGM)最新2016年版本中的定义方式,将图定义为一个四元组 G = { P , Q , G , H } \mathcal{G}=\{P,Q,G,H\} G={P,Q,G,H},其中 P ∈ R d p × n P\in \mathbb{R}^{d_p \times n} P∈Rdp×n表示节点的特征, d p d_p dp表示特征维度, n n n表示节点个数。例如我们用SIFT算法提取图像中关键点的特征,其节点特征维度 d p = 128 d_p=128 dp=128。 Q ∈ R d q × m Q\in \mathbb{R}^{d_q \times m} Q∈Rdq×m表示边的特征, d q d_q dq表示特征维度, m m m表示边的个数。例如我们我们可以用边的长度和方向来描述边的特征,那么边的特征就是一个二维向量。 G , H ∈ { 0 , 1 } n × m G,H\in \{0,1\}^{n\times m} G,H∈{0,1}n×m描述了节点和边的对应关系,或者说描述了节点之间是怎么连接的,也就是这个图的结构(Structure)。其中 G G G表示边的起点, H H H表示边的终点,具体而言若 g i c = h j c = 1 g_{ic}=h_{jc}=1 gic=hjc=1那么就说明图中的第 c c c条边由节点 i i i指向节点 j j j, 图(b)和(c)中给了非常直观的例子。
除了这种描述方式,还有另一种更简单的描述方式,即用邻接矩阵(Adjacent Matrix) A ∈ { 0 , 1 } n × n A\in\{0,1\}^{n\times n} A∈{0,1}n×n来表示节点之间的连接关系,例如 a i j = 1 a_{ij}=1 aij=1表示节点 i i i和 j j j之间存在一条边。包括FGM的早期2012版本中也采用了这种描述方式,但作者说这种方式只能用于描述无向图,而新的描述方式(用 G , H G,H G,H描述)更加通用,能够用于有向图和无向图。但我觉得如果用 a i j a_{ij} aij和 a j i a_{ji} aji分别表示由 i i i指向 j j j的边和由 j j j指向 i i i的边,邻接矩阵 A A A同样可以描述有向图呀,这里我并不是非常理解。
知道了图的描述方式后,我们给定两个图
G
1
=
{
P
1
,
Q
1
,
G
1
,
H
1
}
\mathcal{G}_1=\{P_1, Q_1, G_1, H_1\}
G1={P1,Q1,G1,H1}和
G
2
=
{
P
2
,
Q
2
,
G
2
,
H
2
}
\mathcal{G}_2=\{P_2, Q_2, G_2, H_2\}
G2={P2,Q2,G2,H2},并定义两个关联矩阵(Affinity Matrix)
K
p
∈
R
n
1
×
n
2
K_p \in \mathbb {R}^{n_1 \times n_2}
Kp∈Rn1×n2和
K
q
∈
R
m
1
×
m
2
K_q \in \mathbb {R}^{m_1 \times m_2}
Kq∈Rm1×m2分别表示两幅图节点和节点之间以及边和边之间的相似度。例如
k
i
1
i
2
p
=
ϕ
p
(
p
i
1
1
,
p
i
2
2
)
k_{i_1i_2}^p = \phi_{p}(p_{i_1}^1,p_{i_2}^2)
ki1i2p=ϕp(pi11,pi22)就表示图
G
1
\mathcal{G}_1
G1中的第
i
1
i_1
i1个节点和图
G
2
\mathcal{G}_2
G2中的第
i
2
i_2
i2个节点之间的相似程度,同理
k
c
1
c
2
q
=
ϕ
q
(
q
c
1
1
,
q
c
2
2
)
k_{c_1c_2}^q = \phi_{q}(q_{c_1}^1,q_{c_2}^2)
kc1c2q=ϕq(qc11,qc22)就描述了图
G
1
\mathcal{G}_1
G1中的第
c
1
c_1
c1个边和图
G
2
\mathcal{G}_2
G2中的第
c
2
c_2
c2个边之间的相似程度,如图(d)所示。则图匹配问题就变成寻找两幅图之间最优的匹配关系
X
X
X,使得节点间的相似度和边之间的相似度之和最大。
J
g
m
(
X
)
=
∑
i
1
i
2
x
i
1
i
2
k
i
1
i
2
p
+
∑
i
1
≠
i
2
,
j
1
≠
j
2
,
g
i
1
c
1
1
h
j
1
c
1
1
=
1
,
g
i
2
c
2
2
h
j
2
c
2
2
=
1
x
i
1
i
2
x
j
1
j
2
k
c
1
c
2
q
(
1
)
J_{gm}(X) = \sum_{i_1i_2}x_{i_1i_2}k_{i_1i_2}^p+\sum_{i_1\neq i_2, j_1 \neq j_2, g_{i_1c_1}^1h_{j_1c_1}^1=1, g_{i_2c_2}^2h_{j_2c_2}^2=1 }x_{i_1i_2}x_{j_1j_2}k_{c_1c_2}^q \qquad (1)
Jgm(X)=i1i2∑xi1i2ki1i2p+i1=i2,j1=j2,gi1c11hj1c11=1,gi2c22hj2c22=1∑xi1i2xj1j2kc1c2q(1)
式(1)中第一项表示匹配节点之间的相似度之和,第二项表示匹配边之间的相似度之和。其中
X
X
X表示了两幅图节点之间的匹配关系,
x
i
1
i
2
=
1
x_{i_1i_2}=1
xi1i2=1就表示图
G
1
\mathcal{G}_1
G1中的第
i
1
i_1
i1个节点和图
G
2
\mathcal{G}_2
G2中的第
i
2
i_2
i2匹配,如图(e)所示。节点之间的匹配关系要满足一一对应的约束,即
X
∈
Π
X\in \Pi
X∈Π为一个置换矩阵(Permutation Matrix)
置换矩阵是只有0和1元素组成的矩阵,他的每一行和每一列都有且仅有一个元素为1,其余均为0.
Π
=
{
X
∣
X
∈
{
0
,
1
}
n
1
×
n
2
,
X
1
n
2
≤
1
n
1
,
X
T
1
n
1
=
1
n
2
}
(
2
)
\Pi=\{X|X\in\{0,1\}^{n_1 \times n_2}, X\mathbf{1}_{n_2}\leq\mathbf{1}_{n_1},X^T\mathbf{1}_{n_1}=\mathbf{1}_{n_2}\}\qquad(2)
Π={X∣X∈{0,1}n1×n2,X1n2≤1n1,XT1n1=1n2}(2)
其中
1
n
\mathbf{1}_{n}
1n表示长度为
n
n
n且元素均为1的列向量。我们允许图
G
1
\mathcal{G}_1
G1和
G
2
\mathcal{G}_2
G2的尺寸不相同(即节点数目不相同),为不失一般性,我们约定
n
1
≥
n
2
n_1\geq n_2
n1≥n2。式(2)约束图
G
2
\mathcal{G}_2
G2中的每个点都与
G
1
\mathcal{G}_1
G1中的点有唯一对应的匹配关系。
为了更加清晰地描述和表达图匹配的目标,我们将节点和边的关联矩阵统一为一个关联矩阵
K
∈
R
n
1
n
2
×
n
1
n
2
K\in\mathbb{R}^{n_1n_2 \times n_1n_2}
K∈Rn1n2×n1n2,如图(f)所示。
k
i
1
i
2
,
j
1
j
2
=
{
k
i
1
i
2
p
,
i
f
i
1
=
j
1
a
n
d
i
2
=
j
2
,
k
c
1
c
2
q
,
i
f
i
1
≠
j
1
a
n
d
i
2
≠
j
2
a
n
d
g
i
1
c
1
1
h
j
1
c
1
1
g
i
2
c
2
2
h
j
2
c
2
2
=
1
,
0
,
o
t
h
e
r
w
i
s
e
k_{i_1i_2,j_1j_2}=\left\{\begin{matrix} k_{i_1i_2}^p, & if \quad i_1 = j_1 \: and\: i_2=j_2,\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\\ k_{c_1c_2}^q, & if \quad i_1 \neq j_1\: and\: i_2 \neq j_2 \: and \: g_{i_1c_1}^1h_{j_1c_1}^1g_{i_2c_2}^2h_{j_2c_2}^2=1,\\ 0,& otherwise \quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\end{matrix}\right.
ki1i2,j1j2=⎩
⎨
⎧ki1i2p,kc1c2q,0,ifi1=j1andi2=j2,ifi1=j1andi2=j2andgi1c11hj1c11gi2c22hj2c22=1,otherwise
K
K
K中的对角线元素表示了节点之间的相似度,也就是原来的
K
p
K_p
Kp,非对角线元素表示边之间的相似度,也就是
K
q
K_q
Kq,例如非对角线元素
k
i
1
i
2
,
j
1
j
2
k_{i_1i_2,j_1j_2}
ki1i2,j1j2就表示了图
G
1
\mathcal{G}_1
G1中
i
1
i_1
i1和
j
1
j_1
j1节点之间的边与图
G
2
\mathcal{G}_2
G2中
i
2
i_2
i2和
j
2
j_2
j2节点之间的边的相似程度。有了关联矩阵
K
K
K我们就很容易的将图匹配问题形式化为一个二次分配问题(Quadratic Assignment Problem, QAP)
二次分配问题,也叫二次指派问题,是一个经典的组合优化问题,其已经被证明为NP-hard。而一次分配问题(线性分配问题, LAP),如有权二部图的匹配问题,则可以利用匈牙利算法(Hungarian Algorithm)在多项式时间内求解。
max
X
∈
Π
J
g
m
(
X
)
=
v
e
c
(
X
)
T
K
v
e
c
(
X
)
(
3
)
\max_{X\in\Pi}J_{gm}(X)=vec(X)^TKvec(X) \quad (3)
X∈ΠmaxJgm(X)=vec(X)TKvec(X)(3)
式(3)即为被广泛采用的Lawler’s QAP范式,除此之外还有另一种形式化方式,Koopmans-Beckmann’s QAP
max
X
∈
Π
t
r
(
K
p
T
X
)
+
t
r
(
A
1
X
A
2
X
T
)
(
4
)
\max_{X\in \Pi}tr(K_p^TX)+tr(A_1XA_2X^T) \quad (4)
X∈Πmaxtr(KpTX)+tr(A1XA2XT)(4)
式(4)中的第一项表示节点之间的相似度,第二项表示边之间的线性相似度。其中加权邻接矩阵
A
1
∈
[
0
,
1
]
n
1
×
n
1
,
A
2
∈
[
0
,
1
]
n
2
×
n
2
A_1\in{[0,1]^{n_1\times n_1}},A_2\in{[0,1]^{n_2\times n_2}}
A1∈[0,1]n1×n1,A2∈[0,1]n2×n2分别表示图
G
1
\mathcal{G}_1
G1和图
G
2
\mathcal{G}_2
G2各个节点之间的软连接关系,注意与前面提到的邻接矩阵只有
{
0
,
1
}
\{0,1\}
{0,1}两种元素不同,加权邻接矩阵的元素是从
[
0
,
1
]
[0,1]
[0,1]之间的权重值,表示两个节点之间的连接强度。可以看到,两种形式化方式的区别主要集中在第二项,也就是边之间相似度的计算方式上。为什么我们说Koopmans-Beckmann’s QAP的第二项是线性相似度呢,因为他只能通过边的权重值之间的内积(
A
1
⊗
A
2
A_1 \otimes A_2
A1⊗A2)大小来描述边和边的相似性,而Lawler’s QAP中的
K
K
K可以采用包括高斯核函数在内的非线性相似性度量方式。也就是说Koopmans-Beckmann’s QAP只是Lawler’s QAP的一个特例,即当
K
=
A
1
⊗
A
2
K=A_1 \otimes A_2
K=A1⊗A2时,Lawler’s QAP退化为Koopmans-Beckmann’s QAP。
尽管非精确图匹配相对于精确图匹配已经做了一定的松弛,但其仍然是一个NP-hard问题。因此需要继续对置换矩阵约束(公式(2))进行松弛,以近似求解图匹配问题。常用的松弛策略包含以下几种:
谱松弛(Spectral Relaxation)
Umeyama等人[1]将置换矩阵
X
X
X松弛为正交矩阵,即
X
T
X
=
I
X^TX=I
XTX=I,则图匹配问题可以通过计算特征值的方式求得闭式解,但这类方法只能用于Koopmans-Beckmann’s QAP形式的图匹配问题。Leordeanu等人[2]将
X
X
X松弛为单位长度,即
∥
v
e
c
(
X
)
∥
2
=
1
\|vec(X)\|_2=1
∥vec(X)∥2=1,则最优的匹配关系
X
X
X即为
K
K
K的主特征向量。但这种松弛方式,忽略的一对一对应的约束条件,并且只计算主特征向量是对
K
K
K做了秩为1的近似,但实际上
K
K
K通常是满秩的。因此该方法计算的准确性较差。
半正定规划松弛(Semidefinite-programming (SDP) Relaxation)
半正定规划(SDP)是一类标准的凸优化问题。通过引入一个新的变量
Y
∈
R
n
1
n
2
×
n
1
n
2
=
v
e
c
(
X
)
v
e
c
(
X
)
T
Y\in\mathbb{R}^{n_1n_2\times n_1n_2}=vec(X)vec(X)^T
Y∈Rn1n2×n1n2=vec(X)vec(X)T,将图匹配问题的非凸约束松弛为
Y
−
v
e
c
(
X
)
v
e
c
(
X
)
T
≥
0
Y-vec(X)vec(X)^T\geq 0
Y−vec(X)vec(X)T≥0的半正定凸约束。利用SDP算法求解
Y
Y
Y,然后再采用随机算法[3]或赢家通吃策略[4]近似求解得到
X
X
X。这类方法的优势在于理论上能够保证在多项式时间内找到近似解。然而在实际应用中,由于
Y
Y
Y的尺寸是
X
X
X尺寸的平方,使得求解SDP问题的成本十分高昂。
双随机松弛(Doubly-stochastic Relaxation)
这类方法将
X
X
X松弛为一个双随机矩阵(矩阵的每行之和与每列之和均为1),
X
∈
D
X\in\mathcal{D}
X∈D,其为置换矩阵的一个凸包
D
=
{
X
∣
X
∈
[
0
,
1
]
n
1
×
n
2
,
X
1
n
2
≤
1
n
1
,
X
T
1
n
1
=
1
n
2
}
(
5
)
\mathcal{D}=\{X|X\in[0,1]^{n_1\times n_2}, X\mathbf{1}_{n_2}\leq\mathbf{1}_{n_1},X^T\mathbf{1}_{n_1}=\mathbf{1}_{n_2}\}\qquad(5)
D={X∣X∈[0,1]n1×n2,X1n2≤1n1,XT1n1=1n2}(5)可以看到
D
\mathcal{D}
D和
Π
\Pi
Π的区别在于,
X
X
X的取值范围从
{
0
,
1
}
\{0,1\}
{0,1}变为了
[
0
,
1
]
[0,1]
[0,1],这一改变使得图匹配问题松弛为了非凸的二次规划问题(Quadratic Programming,QP),有许多方法可以找到局部最优解。Zaslavskiy等人[5]采用路径跟随算法(Path-following Algorithm)来求解该非凸的二次规划问题。Gold and Rangarajan[6] 提出毕业分配算法(Graduated Assignment Algorithm)利用泰勒展开式将目标函数分解为一系列线性近似,再通过迭代的方式求解。
除了上述松弛化的方法,还有一些方法可以提高图匹配的效果,例如:可以通过监督或无监督的方式学习得到更好的关联矩阵 K K K[7] [8];还可以通过讲关联矩阵 K K K从二维矩阵提到的高阶张量,使得GM具备刚性变换(旋转和平移)不变性[9] [10],但阶数提高一点,就会导致计算复杂度爆炸性增长,因此高阶图匹配算法通常只能用于非常稀疏的图;由于图匹配问题非常依赖初始的图结构,为了解决这一问题Cho and Lee [11]提出一种渐进式的框架,将目标图的构建过程和图匹配结合起来,根据匹配结果重新估计最合理的目标图。
本文从图匹配的介绍入手,分别介绍了图的描述方式、图匹配的定义和两种形式化的方式。接着总结了三种常见的松弛方法和对应的求解算法,并列举了三种提高图匹配效果的策略。但截至目前,我们还没有开始介绍本文的核心算法FGM是如何实现图匹配过程的,在下篇文章中我们将详细展开。
[1] S. Umeyama, “An eigendecomposition approach to weighted graph matching problems,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 10, no. 5, pp. 695–703, Sep. 1988.
[2] M. Leordeanu and M. Hebert, “A spectral technique for correspondence problems using pairwise constraints,” in Proc. 10th IEEE Int. Conf. Comput. Vis., 2005, pp. 1482–1489.
[3] P. H. S. Torr, “Solving Markov random fields using semidefinite programming,” in Proc. Int. Workshop Artif. Intell. Statist., 2003, pp. 1–8.
[4] C. Schellewald and C. Schn€orr, “Probabilistic subgraph matching based on convex relaxation,” in Proc. 5th Int. Conf. Energy Minimization Methods Comput. Vis. Pattern Recog., 2005, pp. 171–186.
[5] M. Zaslavskiy, F. R. Bach, and J.-P. Vert, “A path following algorithm for the graph matching problem,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 31, no. 12, pp. 2227–2242, Dec. 2009.
[6] S. Gold and A. Rangarajan, “A graduated assignment algorithm for graph matching,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 18, no. 4, pp. 377–388, Apr. 1996.
[7] M. Leordeanu, R. Sukthankar, and M. Hebert, “Unsupervised learning for graph matching,” Int. J. Comput. Vis., vol. 95, no. 1, pp. 1–18, 2011.
[8] T. S. Caetano, J. J. McAuley, L. Cheng, Q. V. Le, and A. J. Smola, “Learning graph matching,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 31, no. 6, pp. 1048–1058, Jun. 2009.
[9] R. Zass and A. Shashua, “Probabilistic graph and hypergraph matching,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recog., 2008, pp. 1–8.
[10] O. Duchenne, F. Bach, I.-S. Kweon, and J. Ponce, “A tensor- based algorithm for high-order graph matching,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 33, no. 12, pp. 2383–2395, Dec. 2011.
[11] M. Cho and K. M. Lee, “Progressive graph matching: Making a move of graphs via probabilistic voting,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recog., 2012, pp. 398–405.
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
如何匹配未被反斜杠转义的平衡定界符对(其本身未被反斜杠转义)(无需考虑嵌套)?例如对于反引号,我试过了,但是转义的反引号没有像转义那样工作。regex=/(?!$1:"how\\"#expected"how\\`are"上面的正则表达式不考虑由反斜杠转义并位于反引号前面的反斜杠,但我愿意考虑。StackOverflow如何做到这一点?这样做的目的并不复杂。我有文档文本,其中包括内联代码的反引号,就像StackOverflow一样,我想在HTML文件中显示它,内联代码用一些spanMaterial装饰。不会有嵌套,但转义反引号或转义反斜杠可能出现在任何地方。
我有一个驼峰式字符串,例如:JustAString。我想按照以下规则形成长度为4的字符串:抓取所有大写字母;如果超过4个大写字母,只保留前4个;如果少于4个大写字母,则将最后大写字母后的字母大写并添加字母,直到长度变为4。以下是可能发生的3种情况:ThisIsMyString将产生TIMS(大写字母);ThisIsOneVeryLongString将产生TIOV(前4个大写字母);MyString将生成MSTR(大写字母+tr大写)。我设法用这个片段解决了前两种情况:str.scan(/[A-Z]/).first(4).join但是,我不太确定如何最好地修改上面的代码片段以处理最后一种
我真的为这个而疯狂。我一直在搜索答案并尝试我找到的所有内容,包括相关问题和stackoverflow上的答案,但仍然无法正常工作。我正在使用嵌套资源,但无法使表单正常工作。我总是遇到错误,例如没有路线匹配[PUT]"/galleries/1/photos"表格在这里:/galleries/1/photos/1/edit路线.rbresources:galleriesdoresources:photosendresources:galleriesresources:photos照片Controller.rbdefnew@gallery=Gallery.find(params[:galle
我已经在mountainlion上成功安装了rbenv和rubybuild。运行rbenvinstall1.9.3-p392结束于:校验和不匹配:ruby-1.9.3-p392.tar.gz(文件已损坏)预期f689a7b61379f83cbbed3c7077d83859,得到1cfc2ff433dbe80f8ff1a9dba2fd5636它正在下载的文件看起来没问题,如果我使用curl手动下载文件,我会得到同样不正确的校验和。有没有人遇到过这个?他们是如何解决的? 最佳答案 tl:博士;使用浏览器从http://ftp.rub
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
@raw_array[i]=~/[\W]/非常简单的正则表达式。当我用一些非拉丁字母(具体来说是俄语)尝试时,条件是错误的。我能用它做什么? 最佳答案 @raw_array[i]=~/[\p{L}]/使用西里尔字符进行测试。引用:http://www.regular-expressions.info/unicode.html#prop 关于ruby-正则表达式将非英文字母匹配为非单词字符,我们在StackOverflow上找到一个类似的问题: https://
前言一般来说,前端根据后台返回code码展示对应内容只需要在前台判断code值展示对应的内容即可,但要是匹配的code码比较多或者多个页面用到时,为了便于后期维护,后台就会使用字典表让前端匹配,下面我将在微信小程序中通过wxs的方法实现这个操作。为什么要使用wxs?{{method(a,b)}}可以看到,上述代码是一个调用方法传值的操作,在vue中很常见,多用于数据之间的转换,但由于微信小程序诸多限制的原因,你并不能优雅的这样操作,可能有人会说,为什么不用if判断实现呢?但是if判断的局限性在于如果存在数据量过大时,大量重复性操作和if判断会让你的代码显得异常冗余。wxswxs相当于是一个独立