目录
es是一款强大的开源搜索引擎,开源帮助我们从海量数据中快速找到需要的内容
elasticsearch是elastic stack(ELK)包含Kibana、Logstash、Beats

Lucene
Lucene是java语言的搜索引擎类库,apache公司顶级项目,1999年研发
优点易扩展,高性能(基于倒排索引),缺点只限于java语言,学习曲线陡峭,不支持水平扩展
Compass
2004是由shay banon基于Lucene开发的
elasticsearch
2010年Shay banon重写了Compass并取名为elasticsearch
比lucene的优点:支持分布式,可水平扩展。提供restful,可被任何语言调用
传统的正向索引:例如下面的图,会去从1开始一条条模糊匹配任何匹配的放到结果集返回了,如果有1000万条数据,就要扫描1000万次
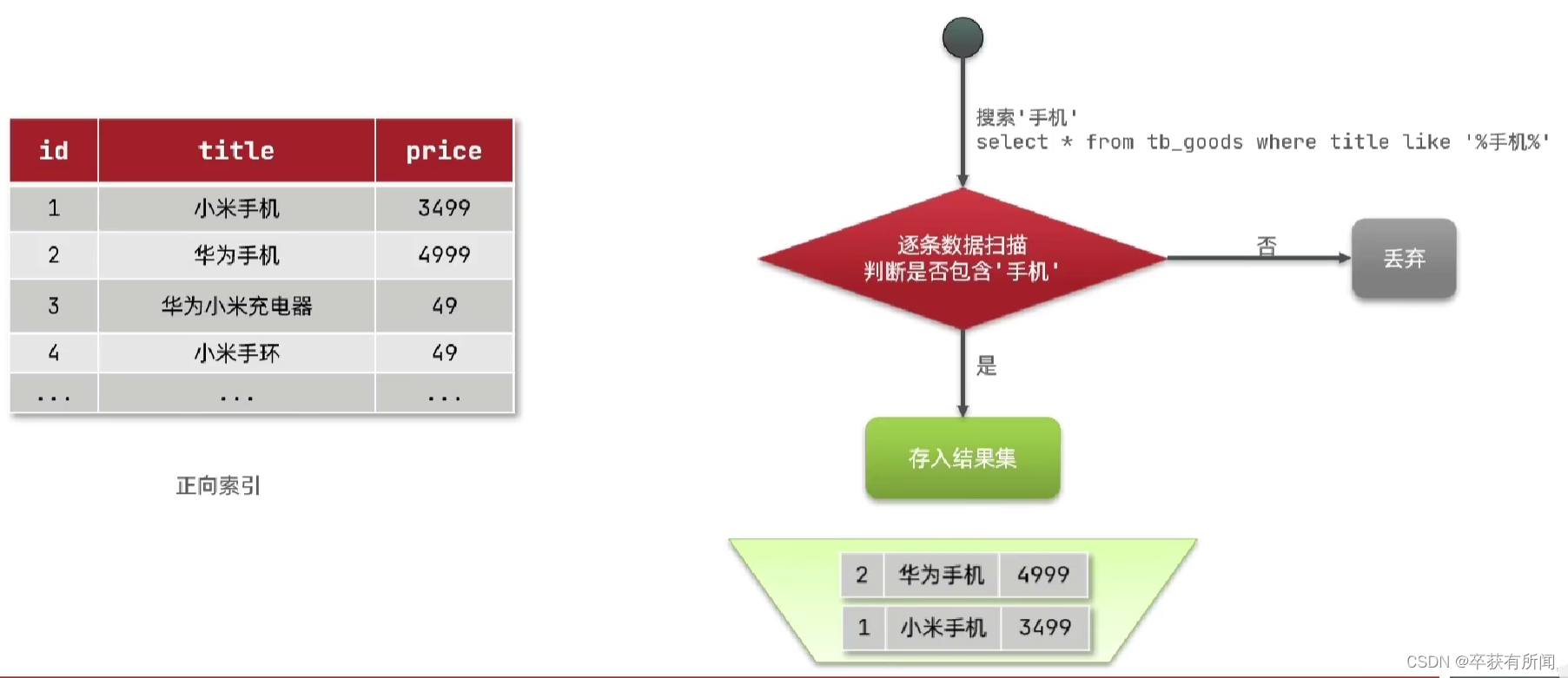
倒排索引:
文档(document):每个商品就是文档,
词条(term):文档按照语义分成的词语
就是把词语先分词提前存好,每个词语对应的id,当我们要搜索的时候就通过词语拿到所有匹配的id来返回,这种方式的效率就比原本正向的高很多。

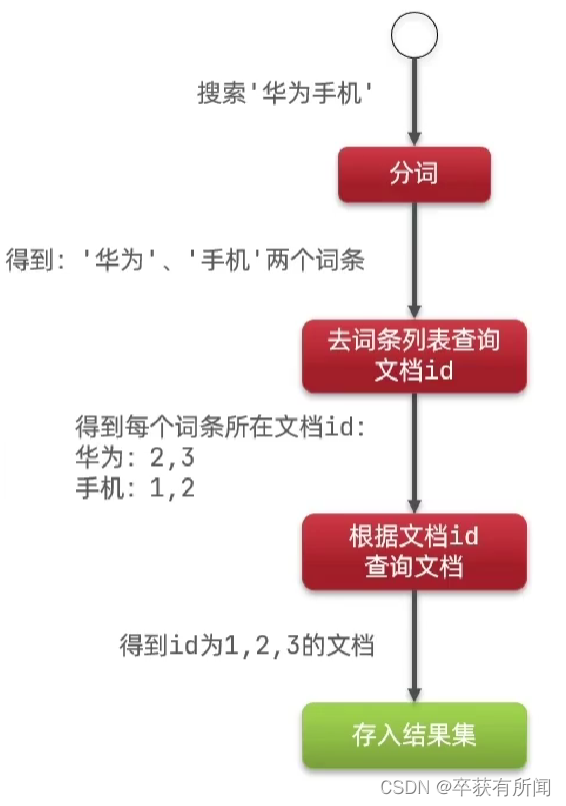
适用场景:更适合基于文档去搜索内容,比如搜索异常信息和局部的单词搜索等等。
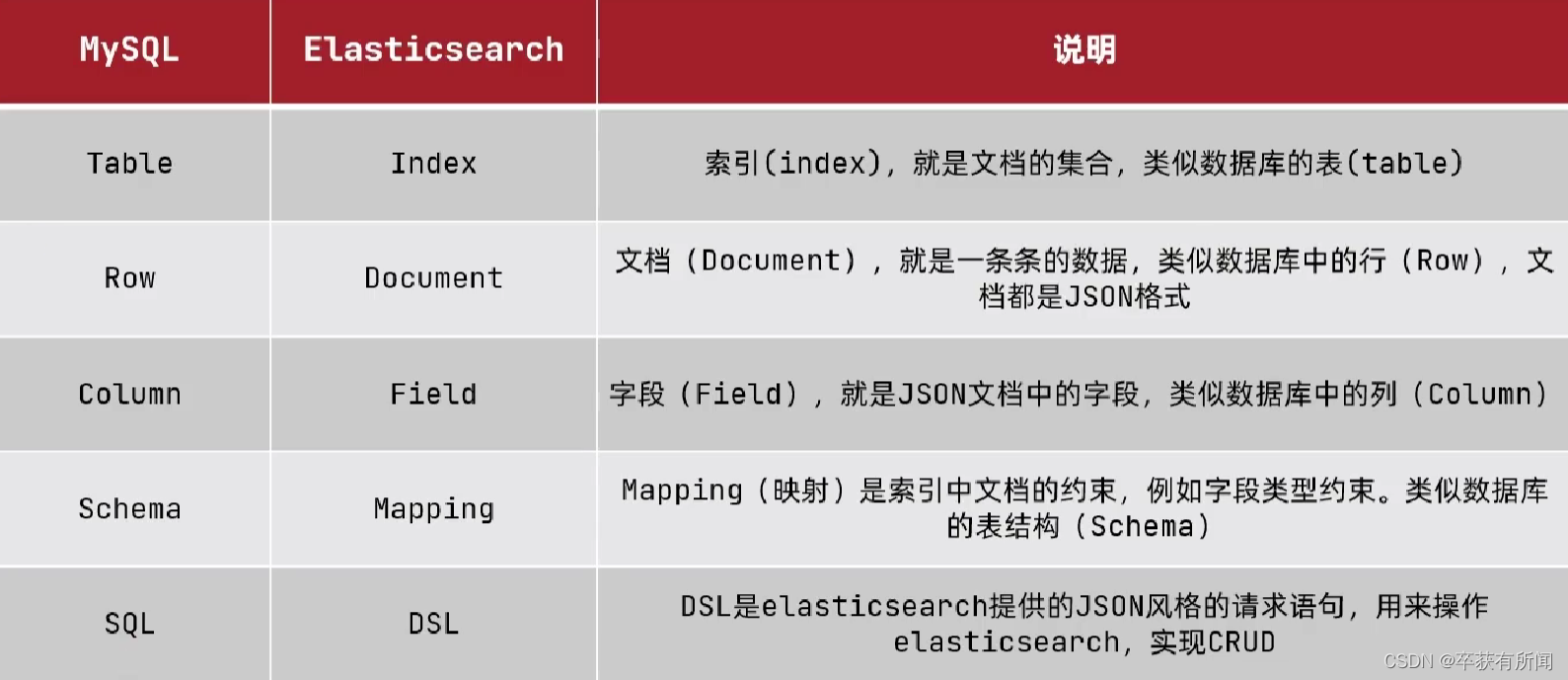
es是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息
文档数据会被序列化为json格式后存储在es中
相同类型的文档的集合
映射mapping:索引中文档的字段约束信息,类似表的结构约束

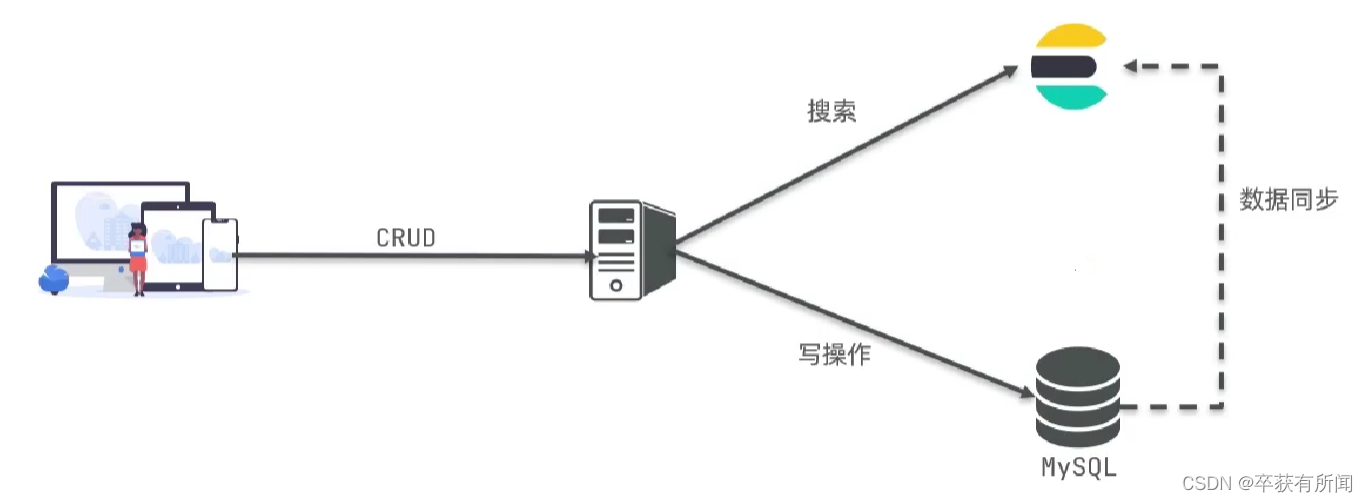
mysql擅长事务类型操作,可以保证数据安全和一致
es擅长海量数据的搜索、分析、计算
es在创建倒排索引时需要对文档分词,在搜索时,需要对用户输入内容分词,但默认分词规则对中文处理不好,中文会被分成一个个的字
处理中文分词,一般用IK分词器
安装IK分词器:找到数据局目录,然后把安装好的ik分词器,解压分词器安装包,放到es容器的插件数据卷中,重启容器。
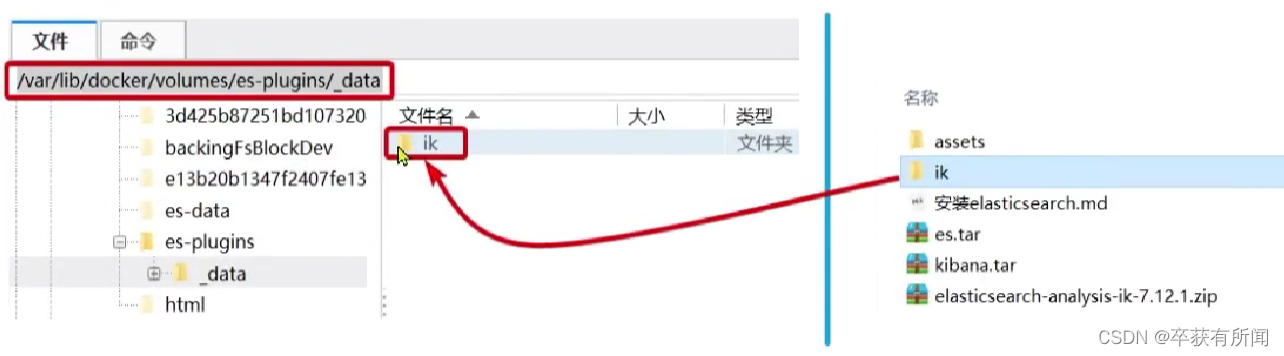

ik_smart:粗力度划分,分的词语不够多但是占用内存小
ik_max_word:细粒度划分,分的词语多匹配更加多,但是内存大
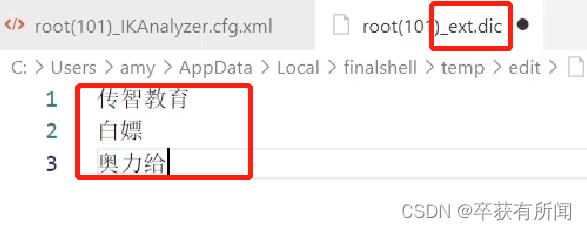
我们发现很多词语是没有的,不会自动分词,比如一些新的网络词汇,要扩展ik分词器,只需要修改ik分词器目录中config目录中的ikAnalyzer.cfg.xml文件,然后在里面写上文件

不仅仅可以扩展,还可以禁止一些词语,比如分的时候“的”字就是没有意义还占用内存,还有紧张搜索的敏感词汇也可以禁止了

mapping是对索引库中文档的约束,常见的mapping属性包括:
type:字段数据类型,常见的简单类型有:
(在es里面是没有数组这个概念的,可以有很多个同类型的数值)
index:是否创建索引,默认为true,如果true就会创建倒排索引,将来就能搜索了,实际上并不是所有字段都需要参与搜索的,所以要手动把一些设置成false
analyzer:使用那种分词器,结合字符串的text来使用的
properties:该字段的子字段(可以指定对象的子属性)

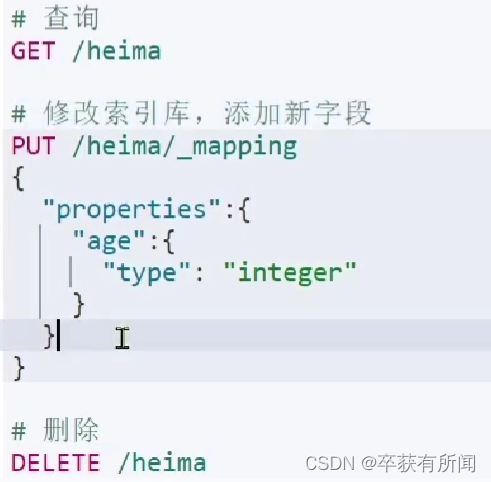
ES中通过restful请求操作索引库、文档。请求内容用DSL语句来表示,创建索引库和mapping的DSL语句如下:


查询用get,删除用delete,修改用put(es没有办法修改的其实,因为每次修改要查询维护倒排索引库非常麻烦,所以修改其实是在原本的索引库里面添加新字段)
新增文档的DSL语法



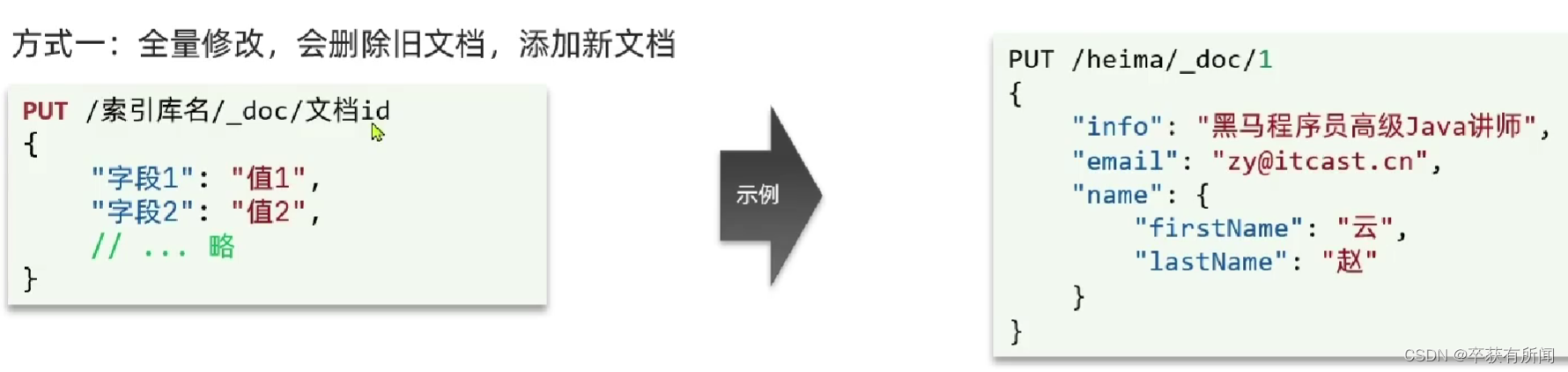 全量修改,请求方式是put,既能做修改,也能做新增,当id没有的时候就代表新增了,他是先删除逐个id然后再新增的,如果id没有就直接增了
全量修改,请求方式是put,既能做修改,也能做新增,当id没有的时候就代表新增了,他是先删除逐个id然后再新增的,如果id没有就直接增了

指定修改,就是修改指定的值,请求方式是post,中间的路径得改成_update
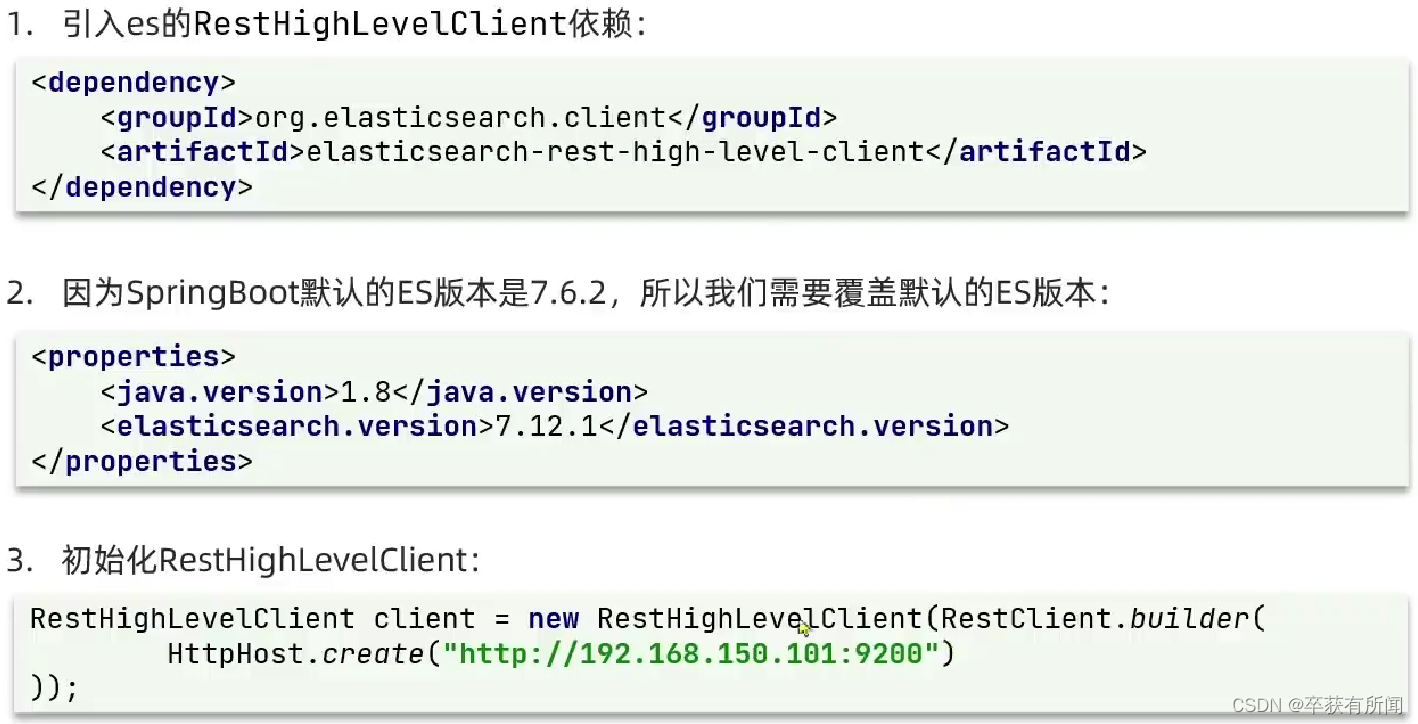
ES官方提供了各种语言的客户端,用来操作es,这些客户端用来组装DSL语句,通过HTTP请求发送给ES
先根据数据库的表建立对应es的mapping



在es里面经纬度比较特殊,要用geo_point
需求:现在想要根据多个字段来搜索,但是多个搜索没有根据一个来搜性能好?怎么办?
es提供了组合查询,类似联合索引的概念,可以单独提出一个字段叫all,把想加进去的属性加上copy_to:all
提示:字段拷贝可以使用copy_to属性将当前字段拷贝到指定字段

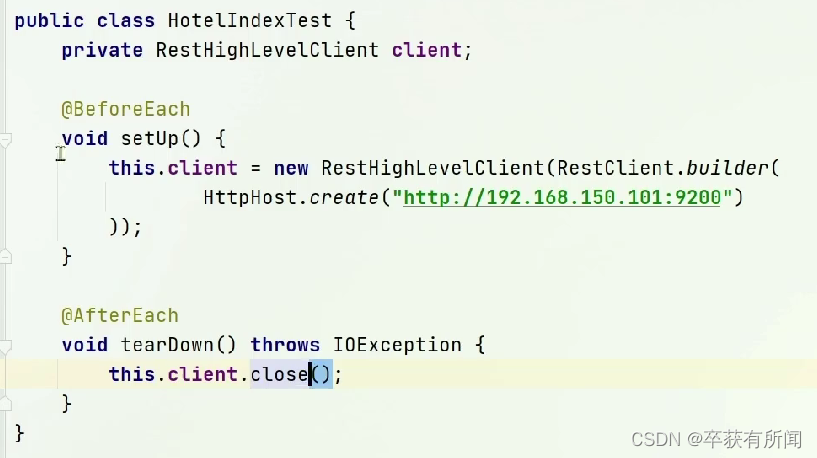
@BeforeEach是在测试方法@Test前执行,@AfterEach是在测试方法后执行,都是junit的注解
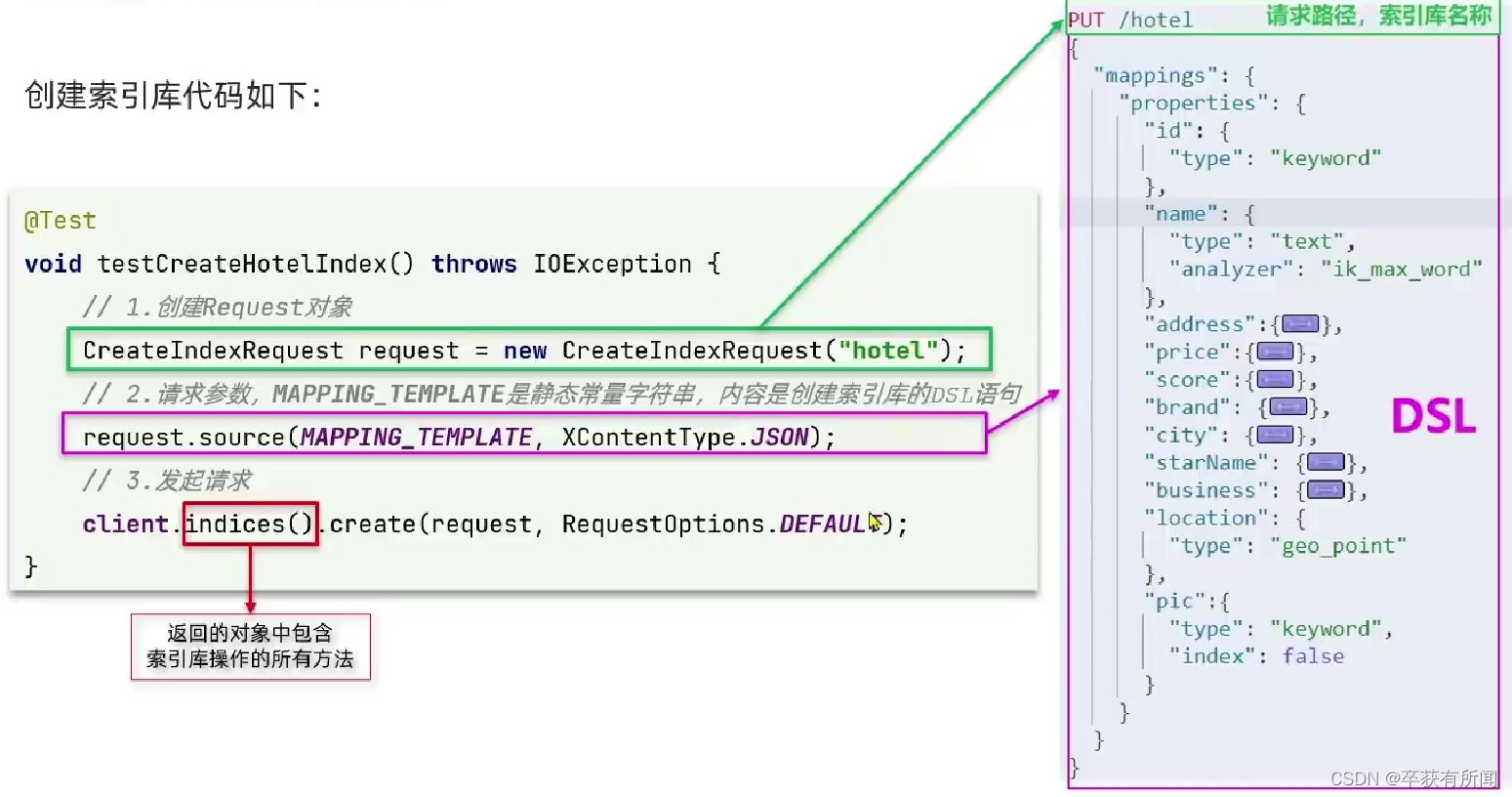
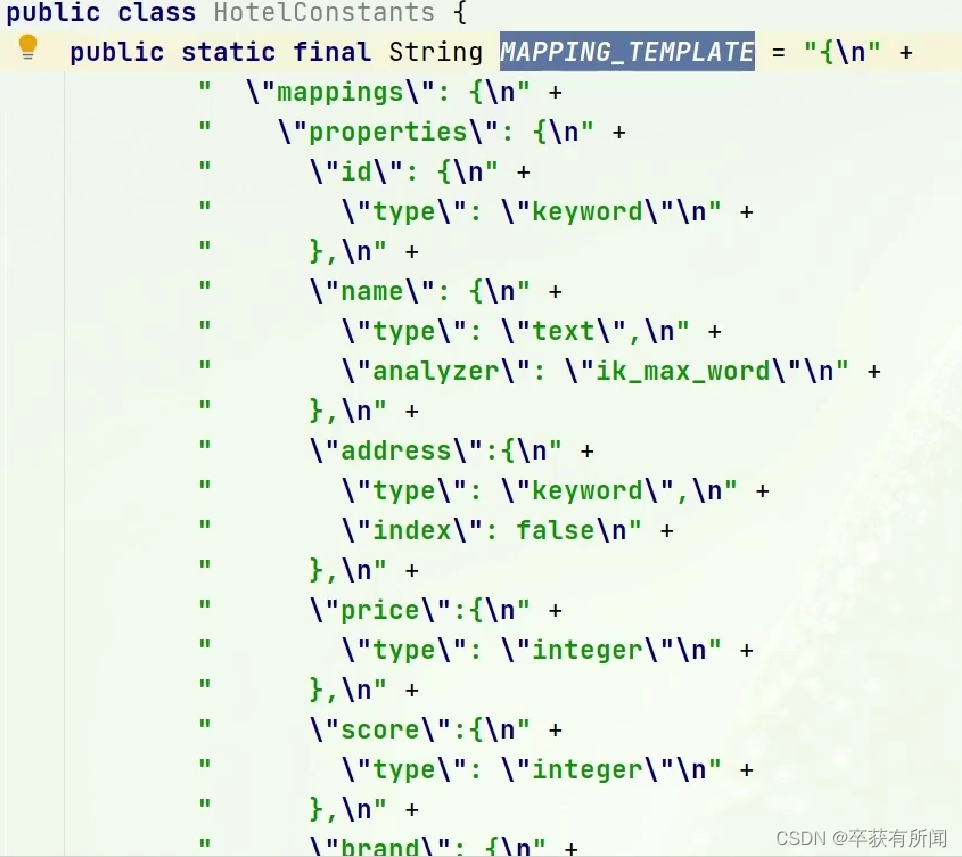
常量里面直接写json对象就行

索引库操作的基本步骤:
新增
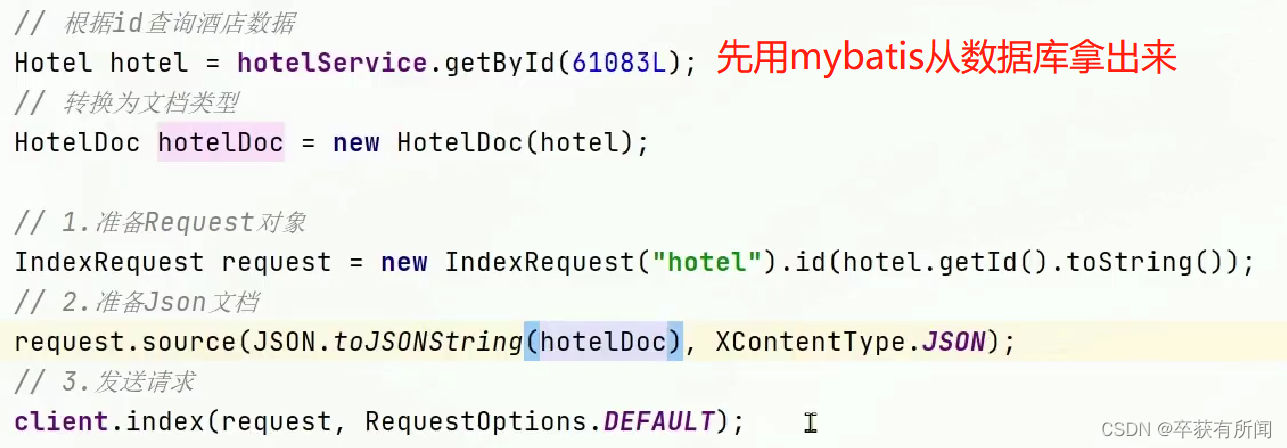
要用过fastJson工具类把对象序列化为json对象存到es
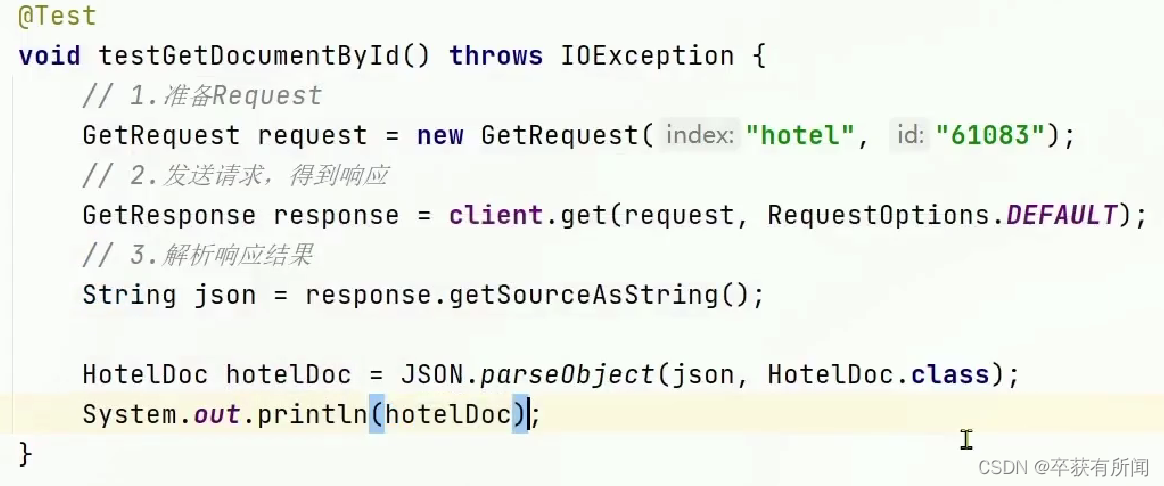
查询
修改

删除

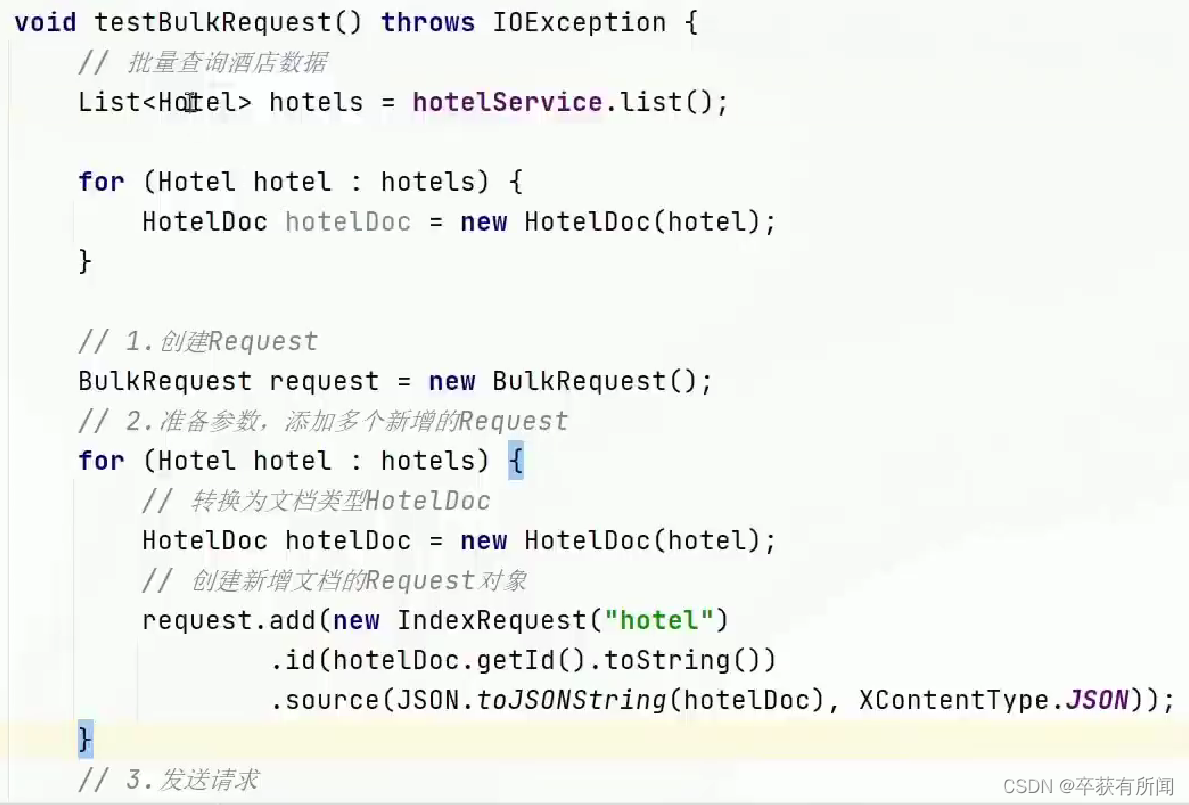
批量导入
文档操作的基本步骤
DSL是基于restful风格的查询语句,用来查询es的
查询语句分类:

由于查询所有并不需要指定条件,所以条件值不用写

我们搜索的时候尽量使用match搜一个字段,然后用all就可以把多个属性放到一个字段来搜索,这样效率比直接搜多个字段快
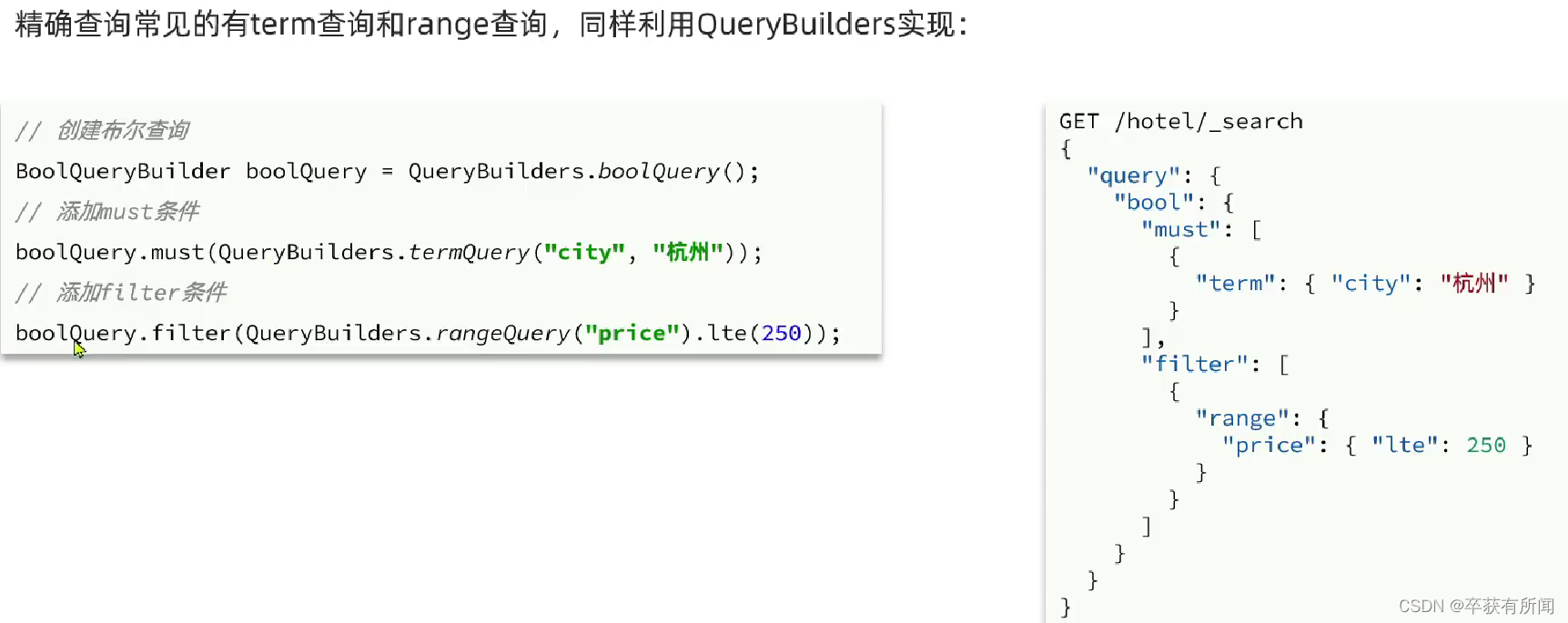
精确查询一般查询keyword、数值、日期、boolean等类型字段,所以不会对搜索条件进行分词。

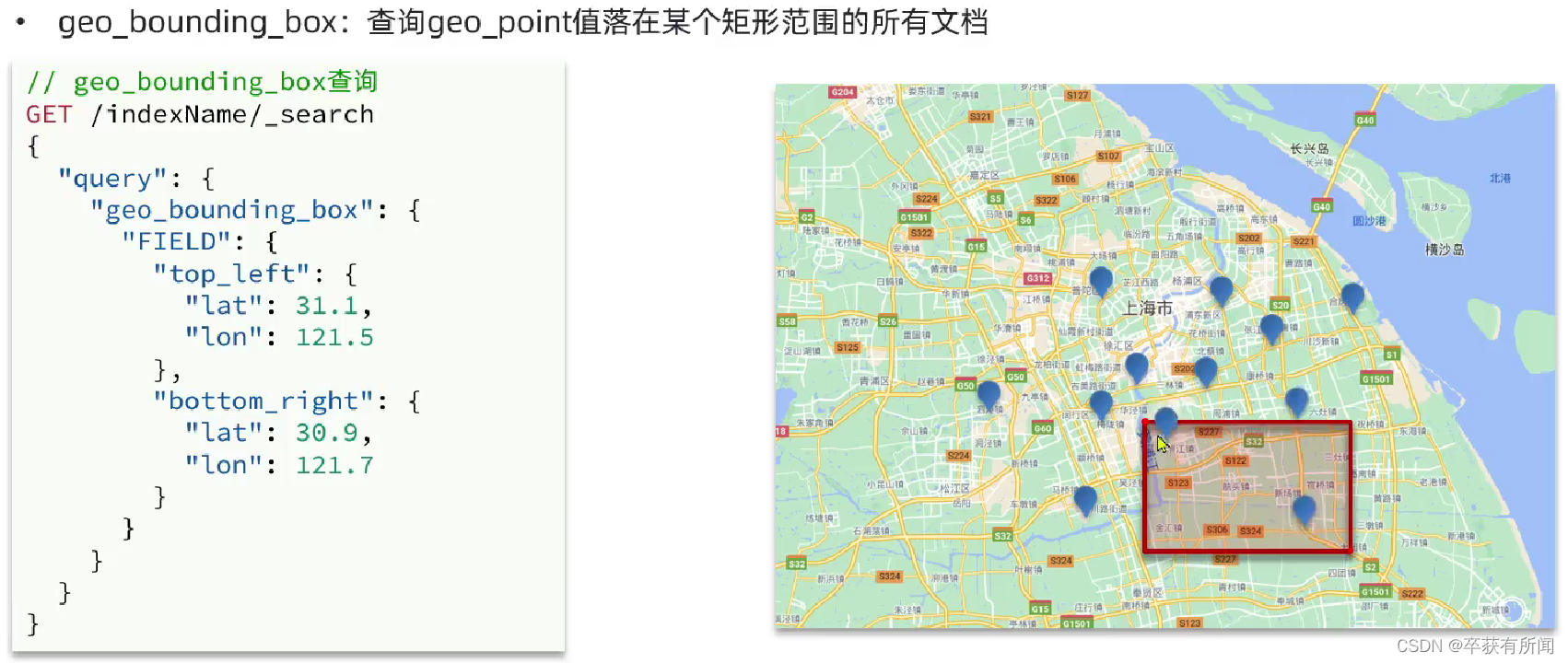
根据经纬度查询,官方文档,例如:
geo_bounding_box:适合查询一定范围内所有的信息。
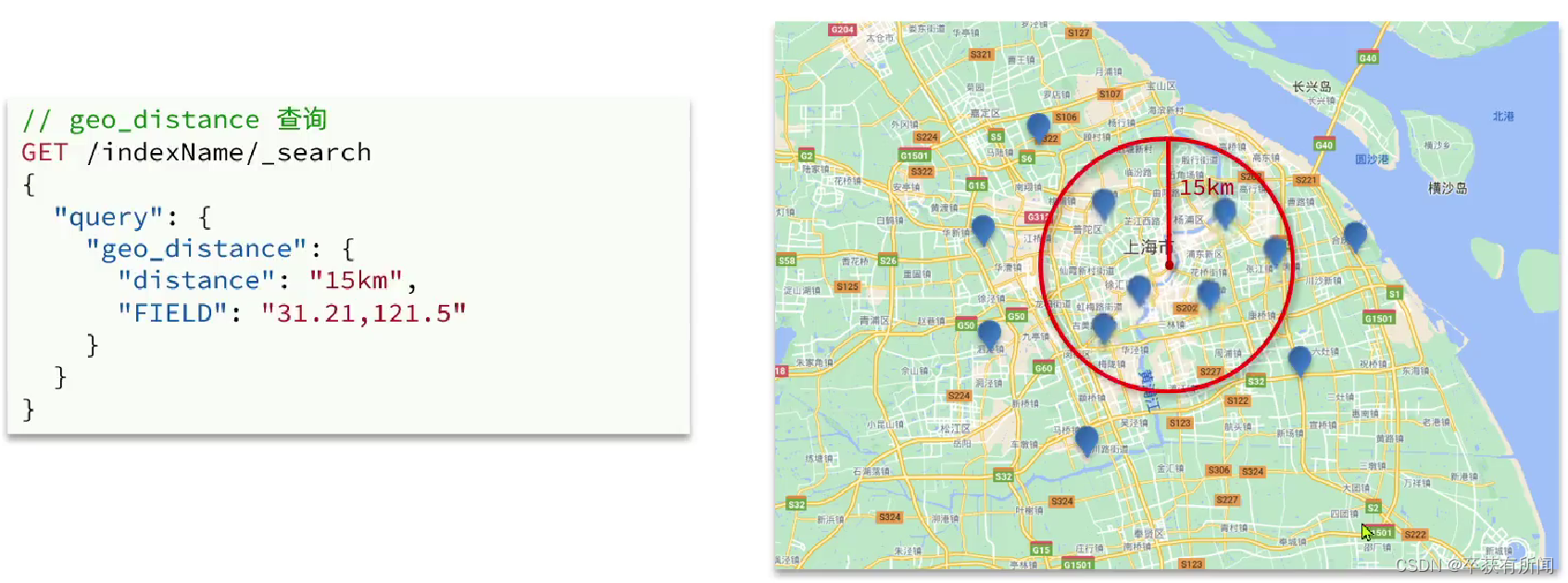
 geo_distance:查询到指定中心店小于某个距离值的所有文档,适合做附近的人
geo_distance:查询到指定中心店小于某个距离值的所有文档,适合做附近的人
复合查询:复合查询可以将其他简单查询组合起来,实现更复杂的搜索逻辑
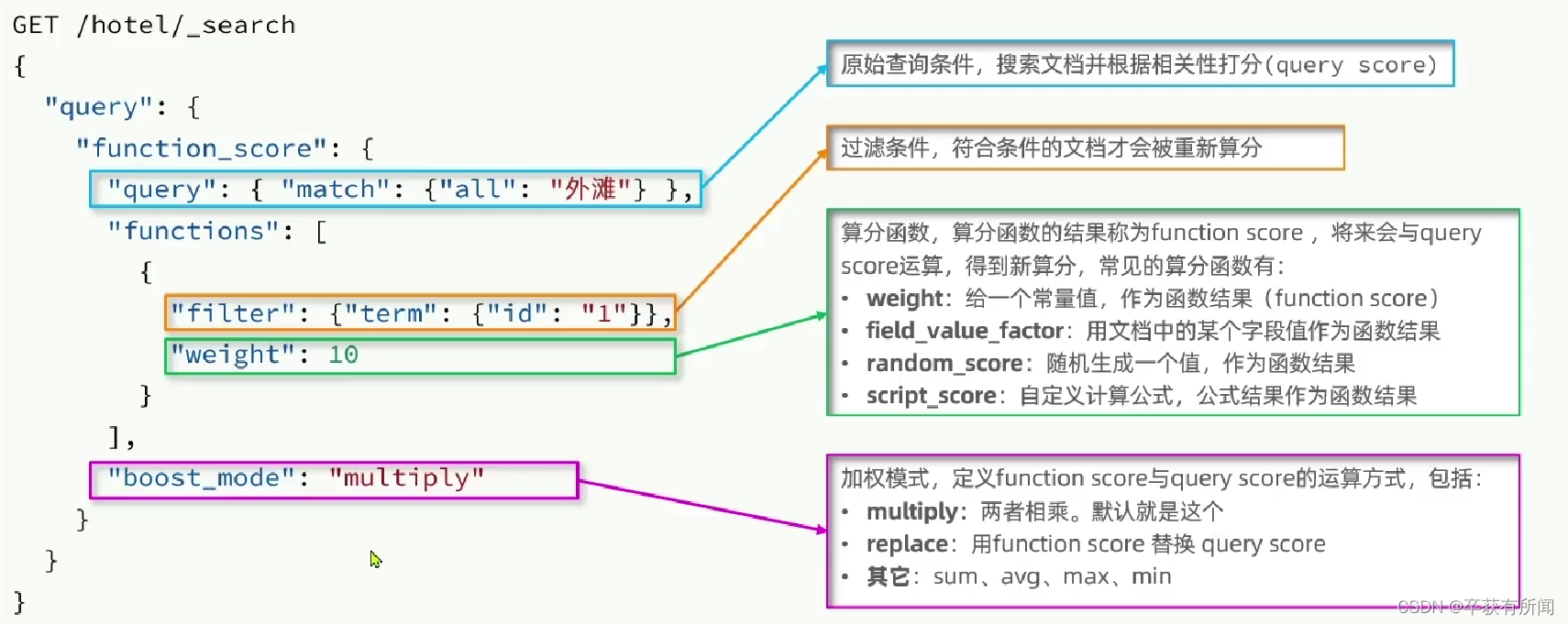
fuction score:算分函数查询,可以控制文档相关性算法,控制文档排名
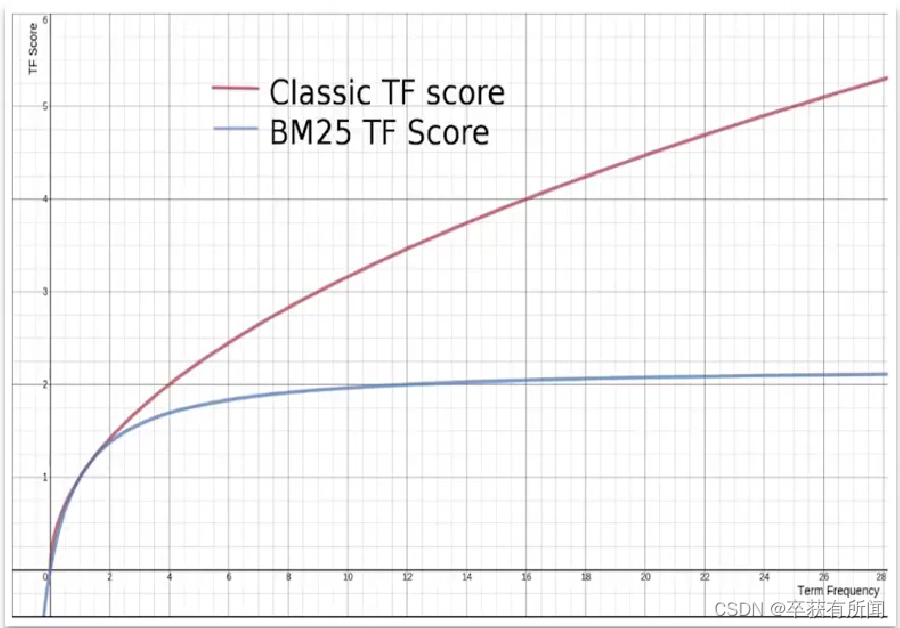
es中相关打分算法:
TF-IDF:es5.0之前,会虽则词频增大而越来越大
BM25:在es5.0之后,词频增大,但增长曲线会趋于水平

Function Score Query
Boolean Query
布尔查询是一个或多个查询子句的组合,子查询的组合方式有:
must:必须匹配每个子查询,类似与
should:选择性匹配子查询,类似或
must_not:必须不匹配,不参与算分,类似非
filter:必须匹配,不参与算分
下面这些就固定的不参与算分,可以提高搜索效率,而且这种不参与算分的往往会放到缓存里,进一步提高效率,参与算分条件越多,查询的性能越差

图中:must_not来查询价格,小于500的,就是要查实际上大于500的,之所以用这个反着查就是为了提高效率,因为不用参与算法,而且这个价格的权重也不重要,所有这样效率最高,项目filter搜分大于45也是如此,关键词才需要参与算分的,不参与算分全部放到must_not和filter里面
es支持对结果进行排序,默认是根据分值排序,可以排序的字段类型:keyword类型、数值类型、地理坐标类型、日期类型等


es默认情况只返回top10的数据,而如果要查询更多数据就需要修改分页参数了
es中通过from、size参数来控制要返回的分页结果:

ES是分布式的,所有会面临深度分页问题,例如按price排序后,获取from=990,size为10的数据
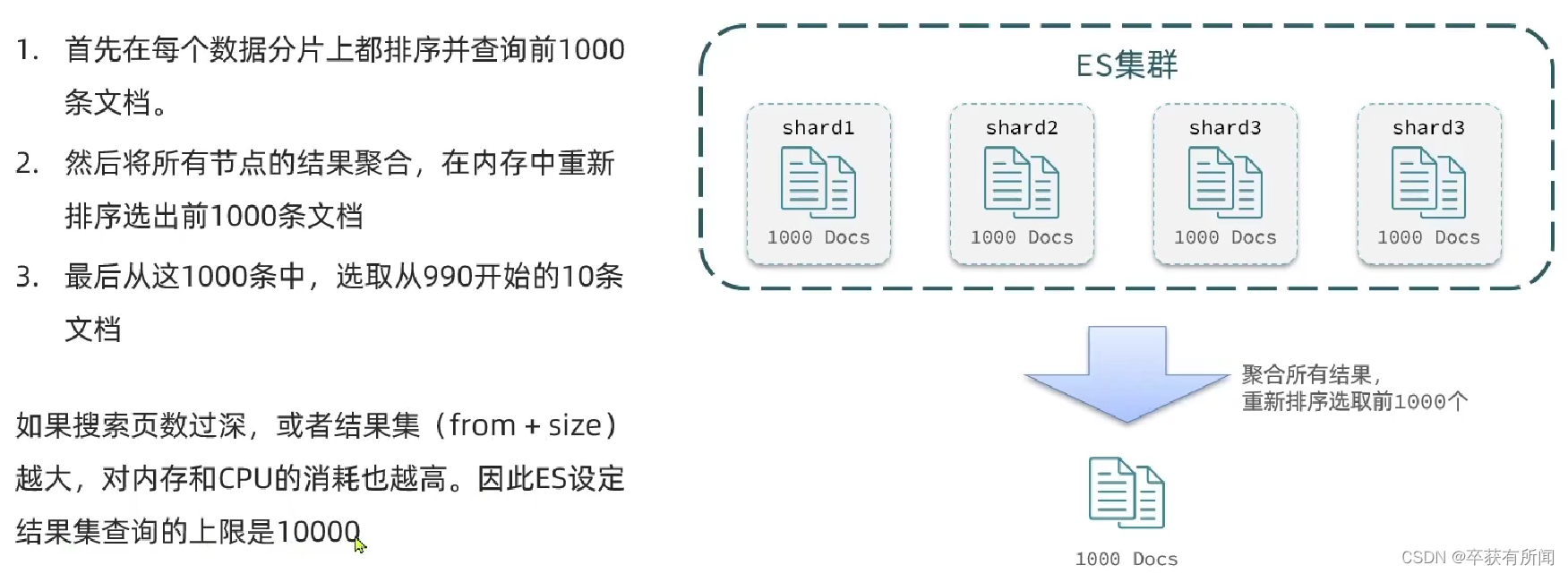
深度分页解决方案
针对深度分页,es提供两种解决方案
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式
scroll:原理将排序数据形成快照,保存在内存,官方已经不推荐使用。(内存消费非常大,而且将来es一更新快照还是旧的数据)

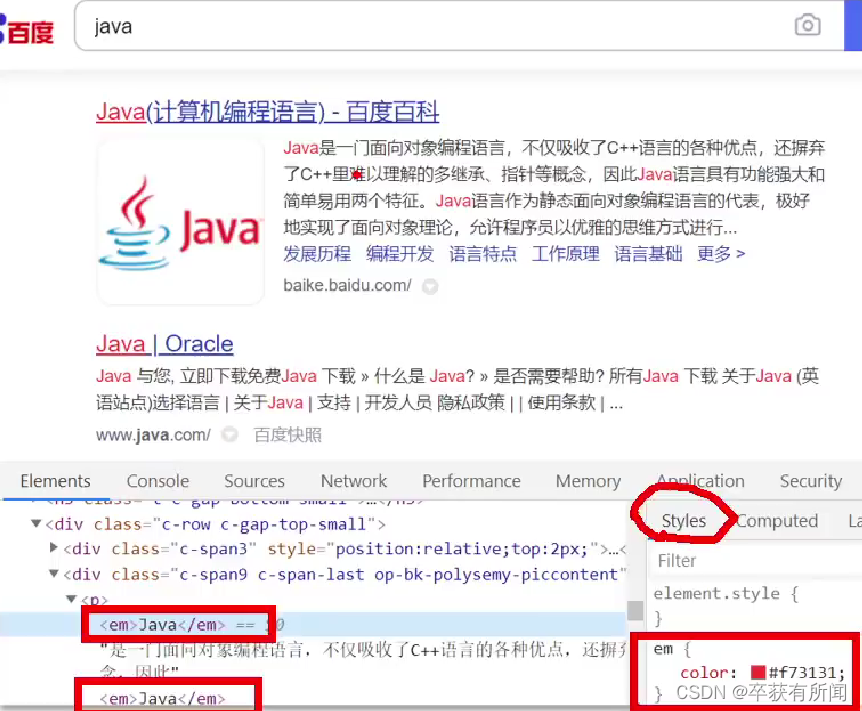
如图我们可以观察到,搜索出来的结果会高亮,其实加了标签,是谁加的呢?其实是es服务端加的,他给关键字加了标签,然后返回给前端。

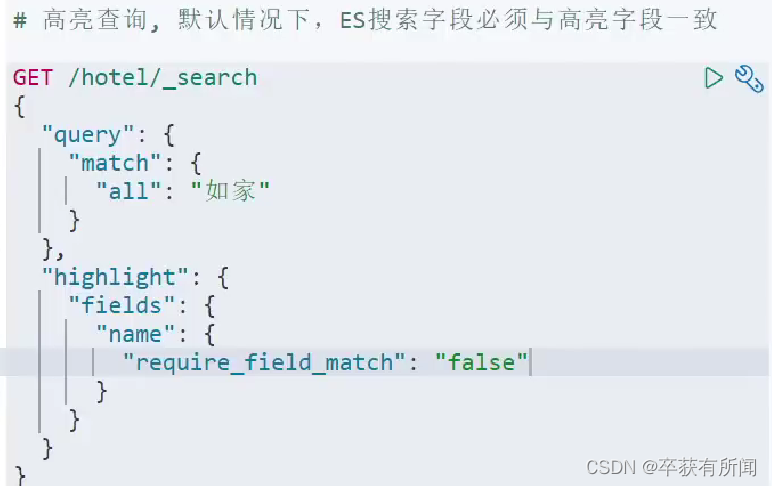
require_field_match为false代表搜索的属性不一定要匹配,用all来搜可以高亮name的
搜索全部
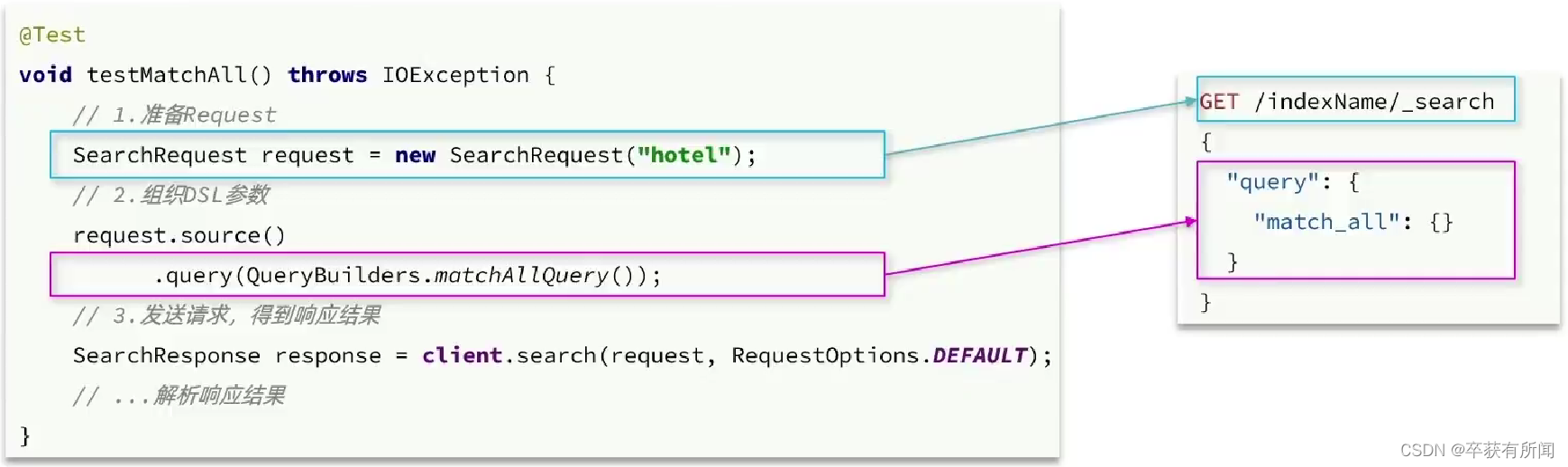
解析对象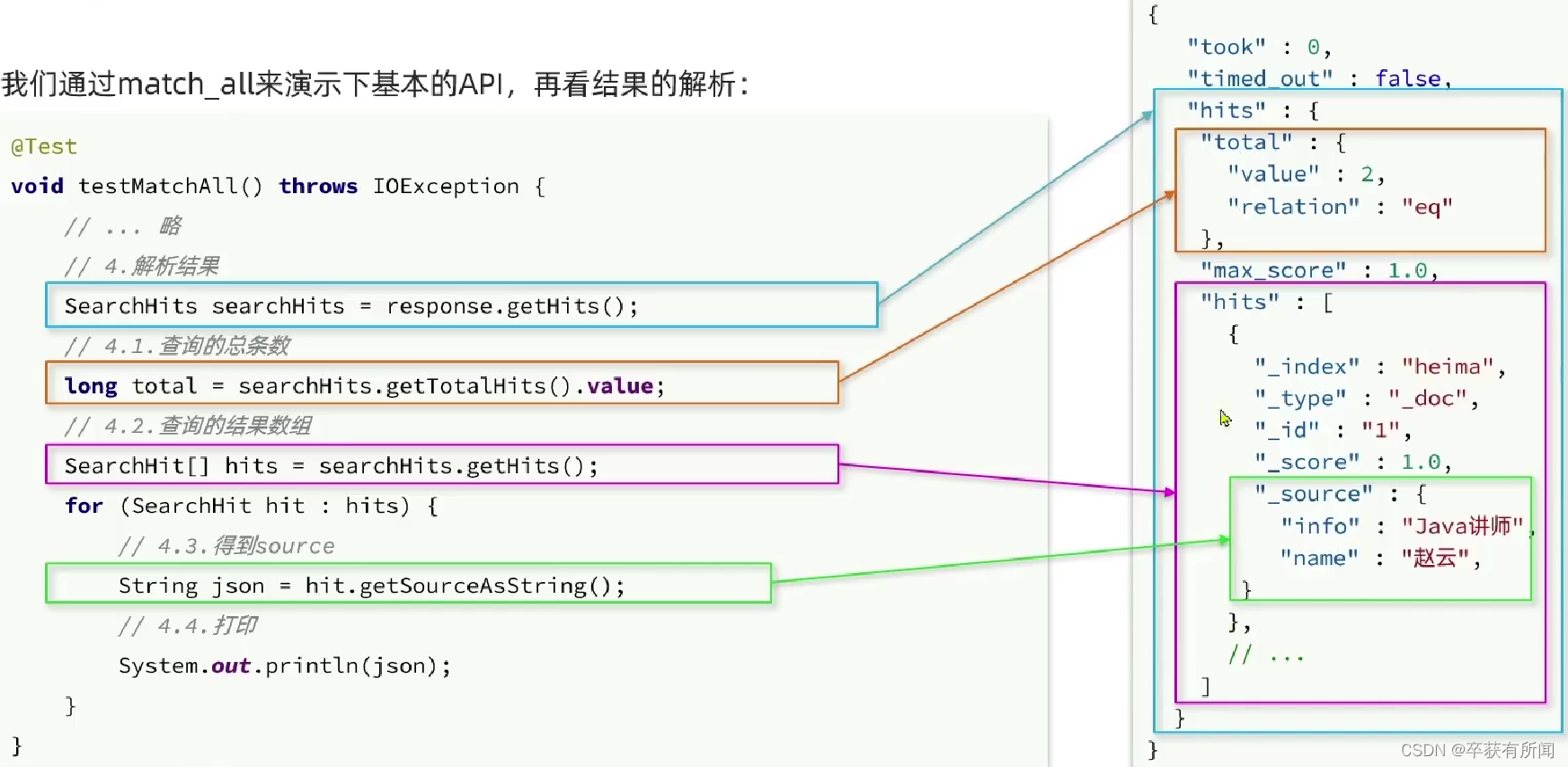
全文检索查询

精确查询

boolean查询
排序和分页

高亮
先看看请求的DSL构建

高亮结果处理

总结
所有的DSL构建,都是用SearchRequest的source()方法
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>