文章目录
https://www.youtube.com/watch?v=Ew24Rac8eYE
传统图像数据是2维的
3D点云是3维的,可以表达更多信息





一般点云数据都是基于激光雷达扫描生成的。
初始的点云数据仅仅包含了每个点的坐标信息(x,y,z),这些对我们要完成的后续任务远远不够,我们还需要知道每个点和周围的点的关系甚至是每个点和全局的关系。
点云数据并不是定义在一个规则的网格上,空间上可以任意分布、数量也可以任意,是不规则数据。
一种解决方案:

这种方式的缺点:
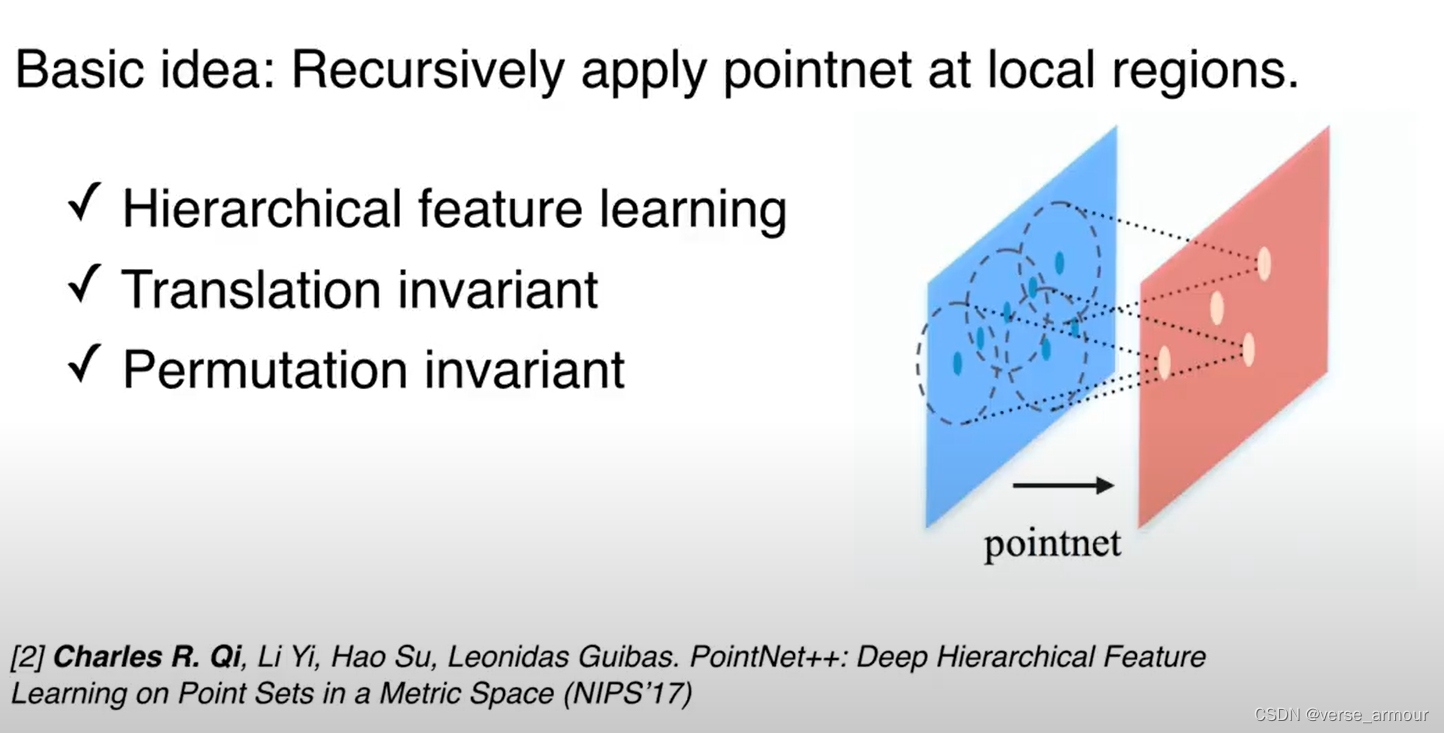
那么如何构造一个backbone来提取3D点云的这些特征呢?
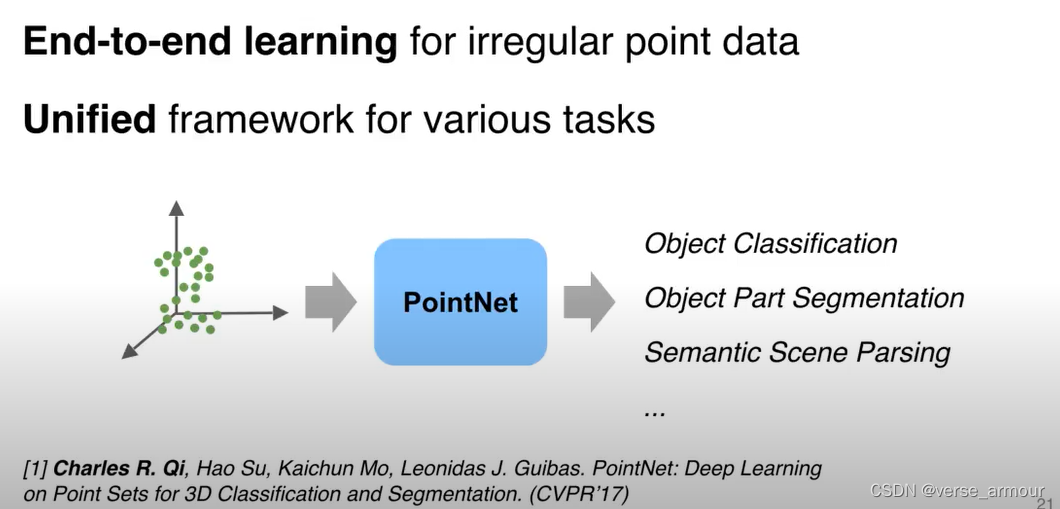

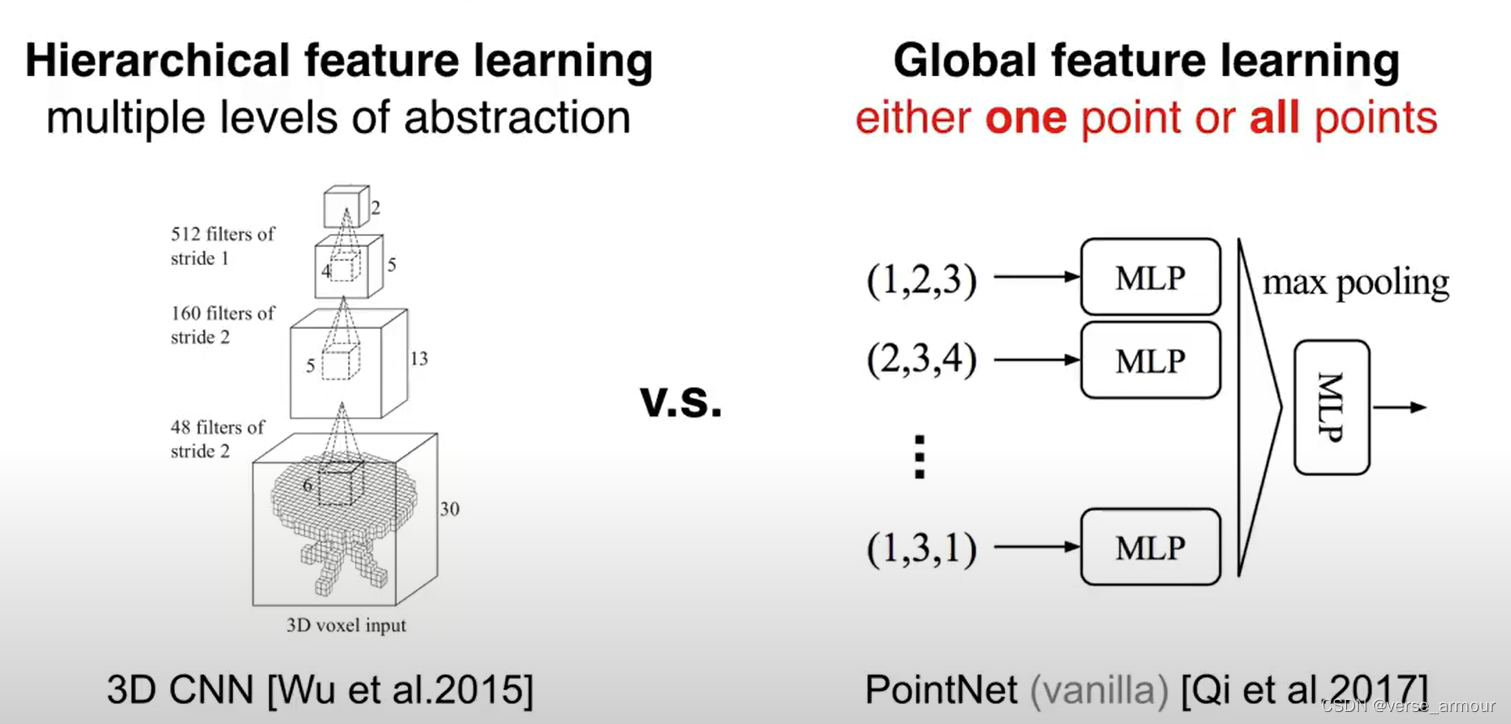
点云数据的特点
点云数据是一个inordered set,每个点出现的顺序不影响集合的本身

N表示点云中的有N个点,D代表每个点拥有D维的特征。D中可以包含点的坐标信息(x,y,z),也可以包含颜色、法向量…
因为点集是无序的,一共有N!种排列组合。这要求我们设计的backbone对所有置换都具有不变性。
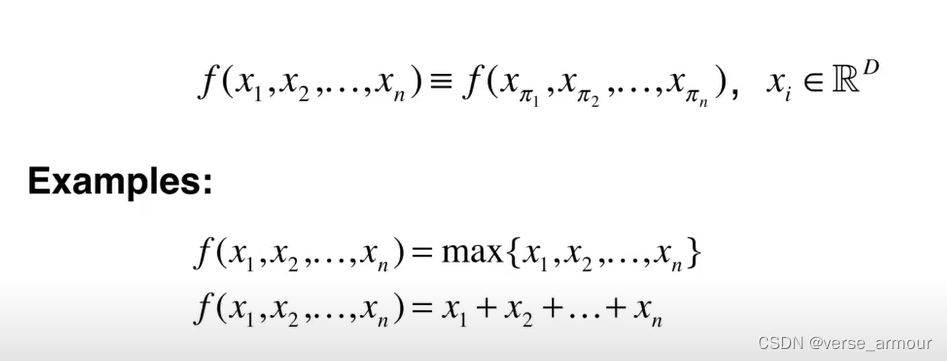

最简单的最大池化和平均池化函数虽然具有置换不变性,但是无疑会丢失有意义的几何信息。
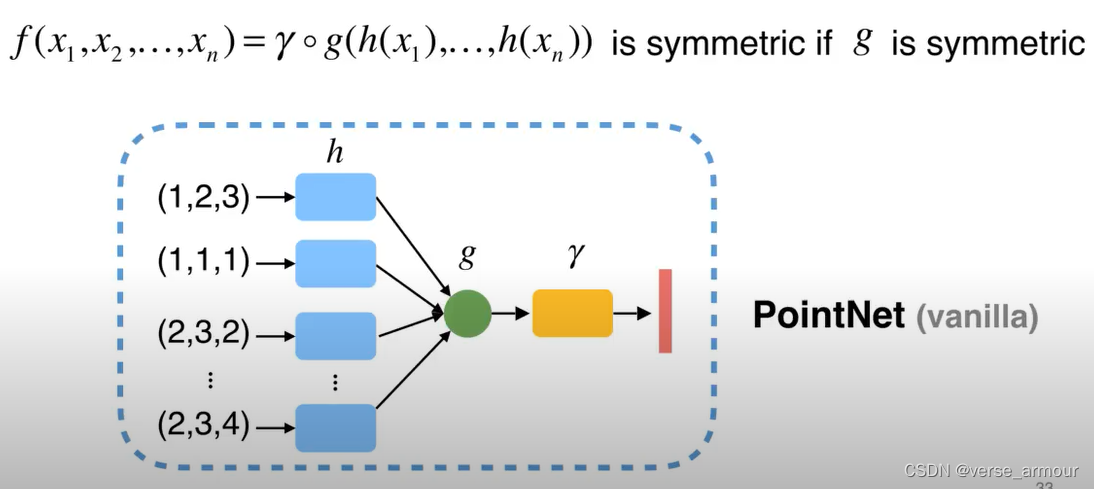

这是什么?不太理解。
比如说一辆车,在不同的角度观察,点云中的每个点的坐标会有所变化,但表示的都是同一辆车。
如何设计网络能使得网络能够适应这种视角的变化呢?
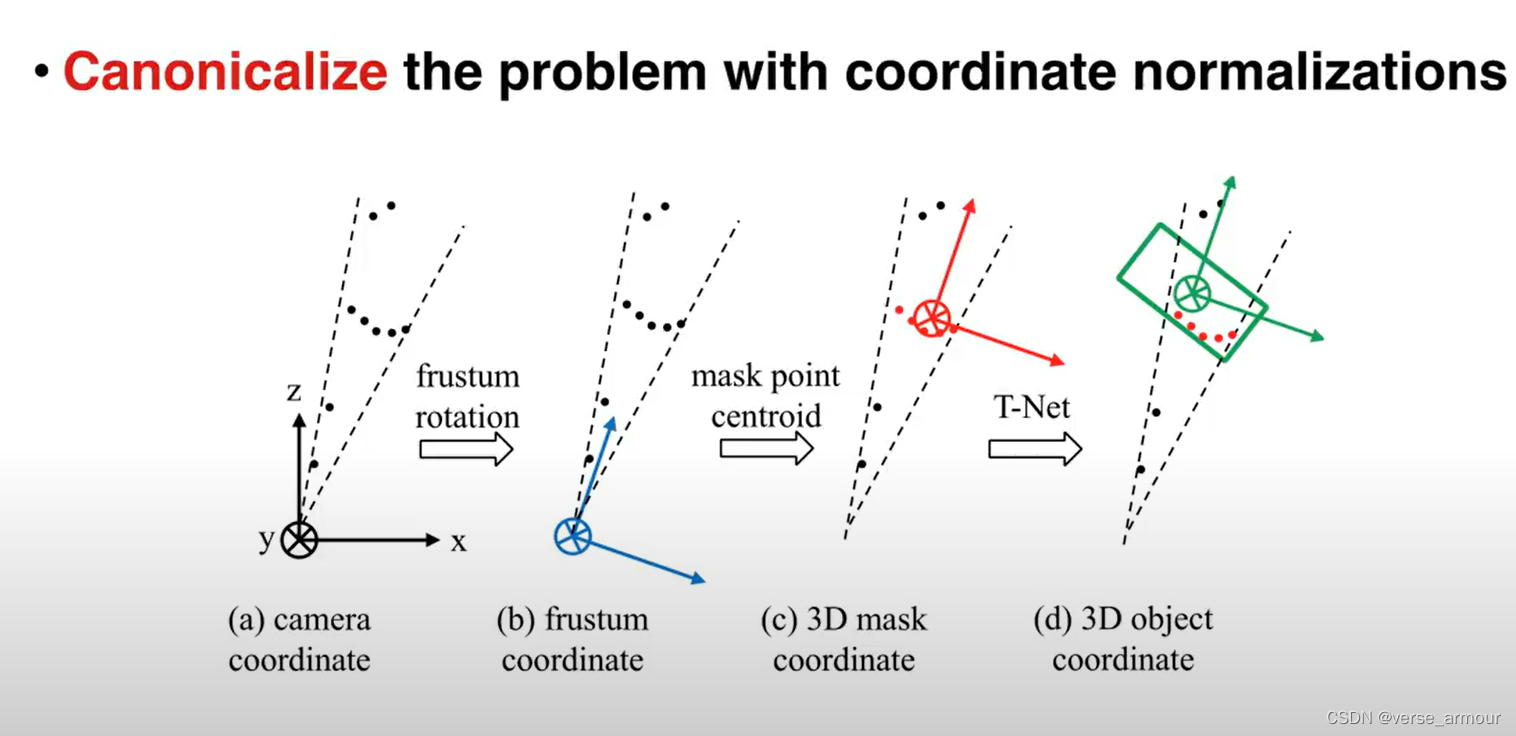
增加基于点云数据本身的变换函数模块:
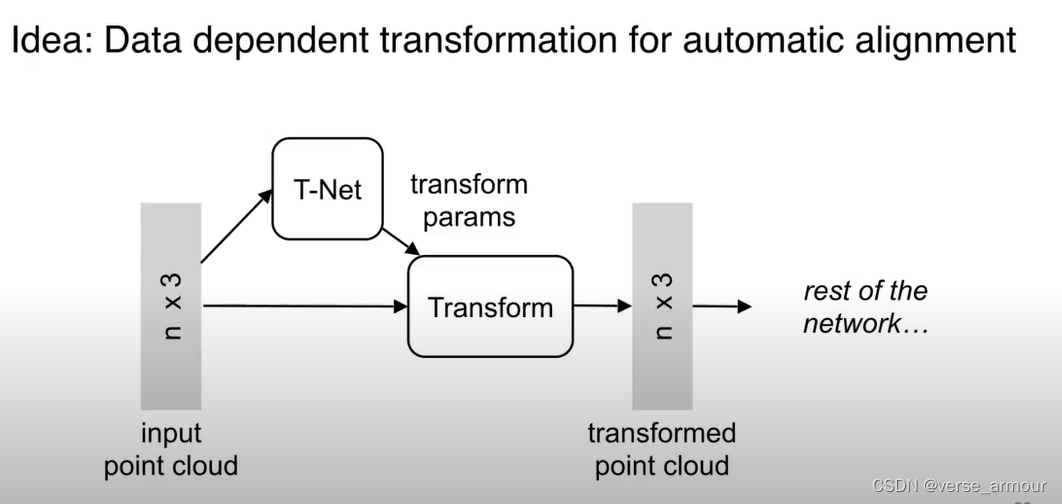

通过一个神经网络T-Net生成变换的参数,再用生成的变换函数对输入数据进行变换。使得这个变换函数能够自动对准对齐我们的输入,后面的网络能够适应不同角度的输入数据,处理任务变得更加简单。
对点云数据进行变换操作非常简单,只需要进行一个矩阵乘法。
做一些扩展:不仅可以对输入数据进行变换处理,也可以对点的中间特征进行特征空间的变换。
比如,一开始已经将点的特征变成K维,那么现在有一个N * K的矩阵。我们可以设计一个K * K的矩阵进行矩阵乘法对这些中间特征进行特征空间的变换。这样可以得到另一组特征。

对于以上涉及的这些高维的变换,优化的难度也更高,可能会需要一些regularization:比如会尽可能希望这个矩阵接近于正交矩阵。
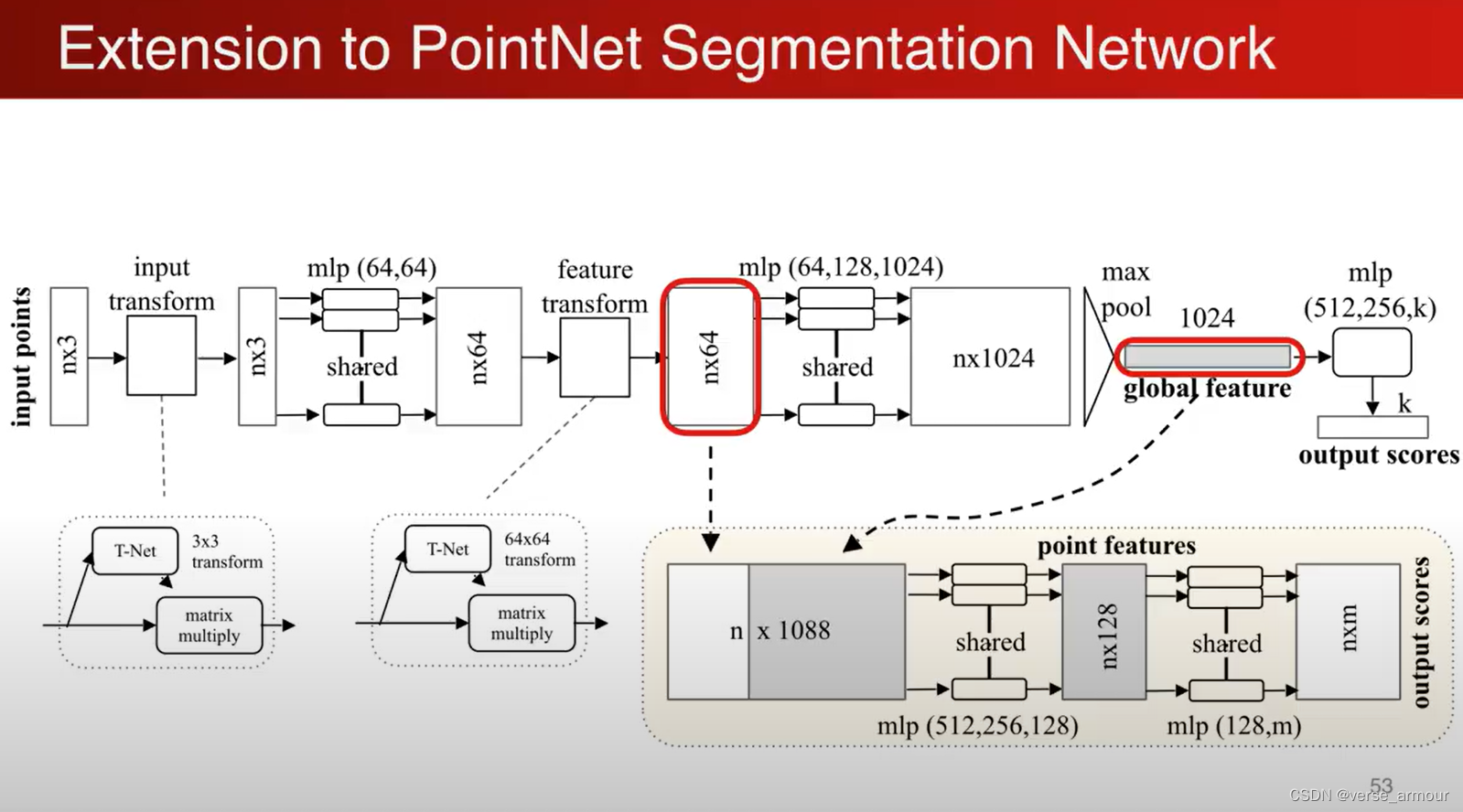
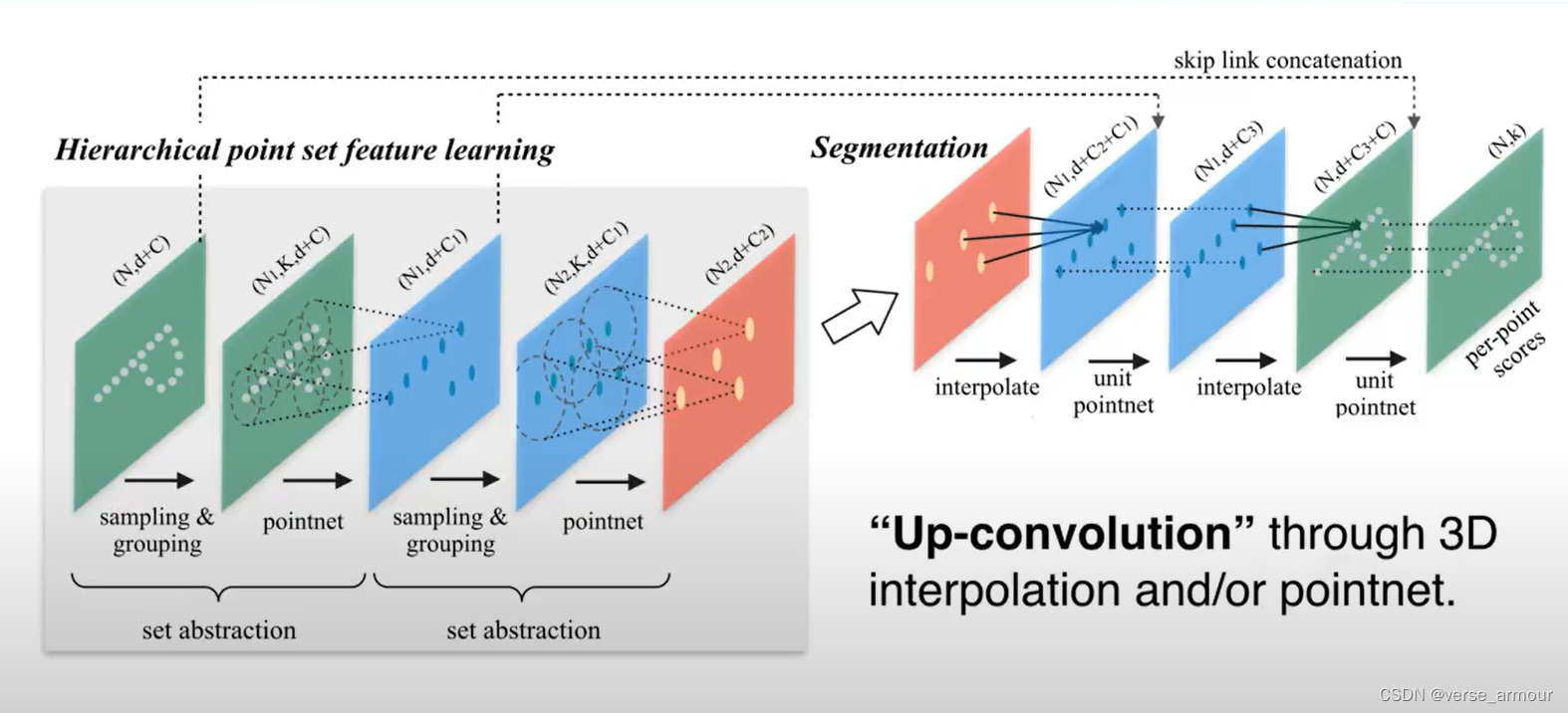
单个点的特征和全局的坐标结合起来实现分割的功能。
最简单的就是:将全局的特征重复n遍,每一个和原来的单个点的特征连接在一起,相当于单个点在全局特征中进行了一次检索,“我在全局特征中处于哪一个位置,我大概属于哪一个类”
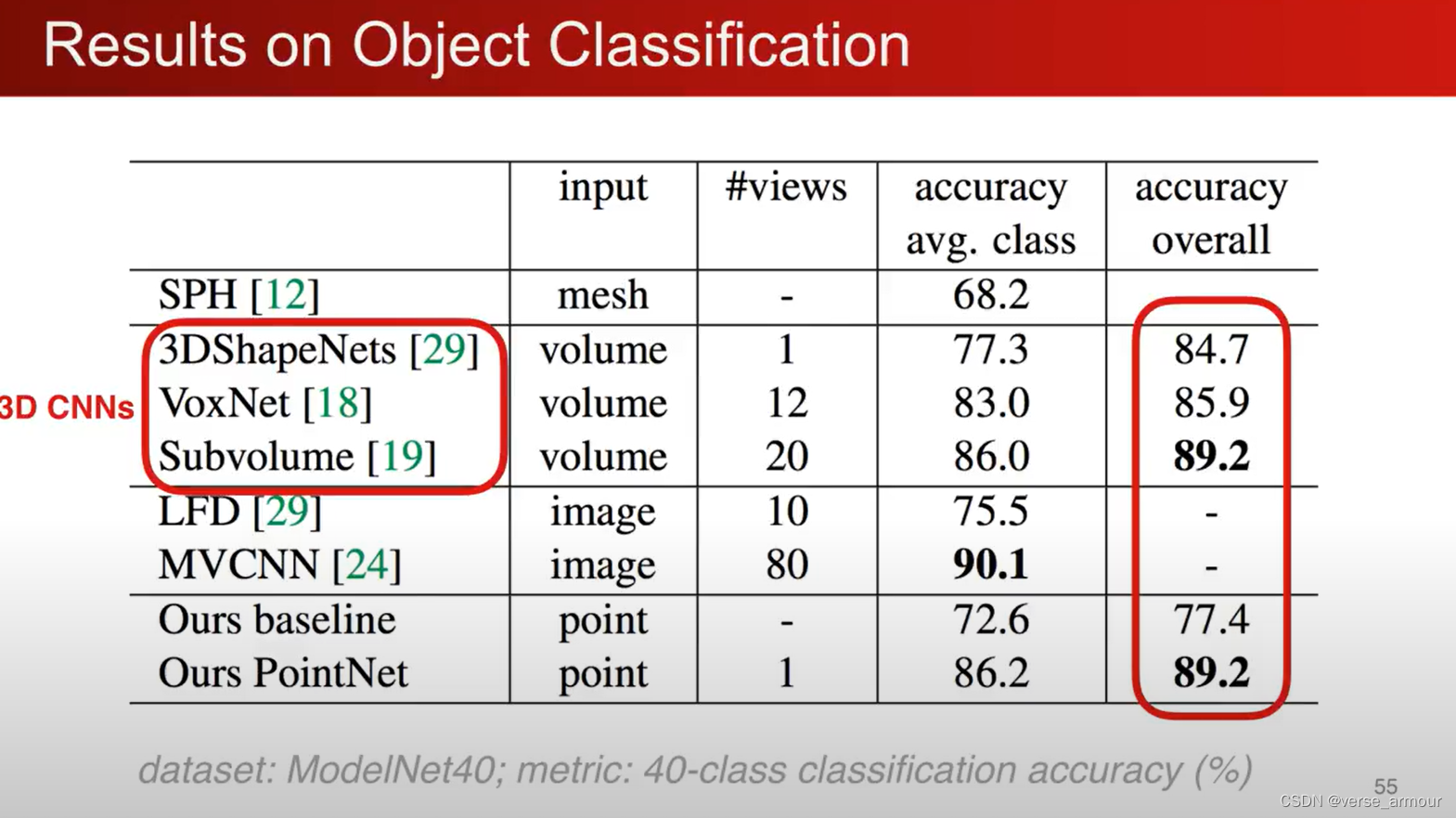

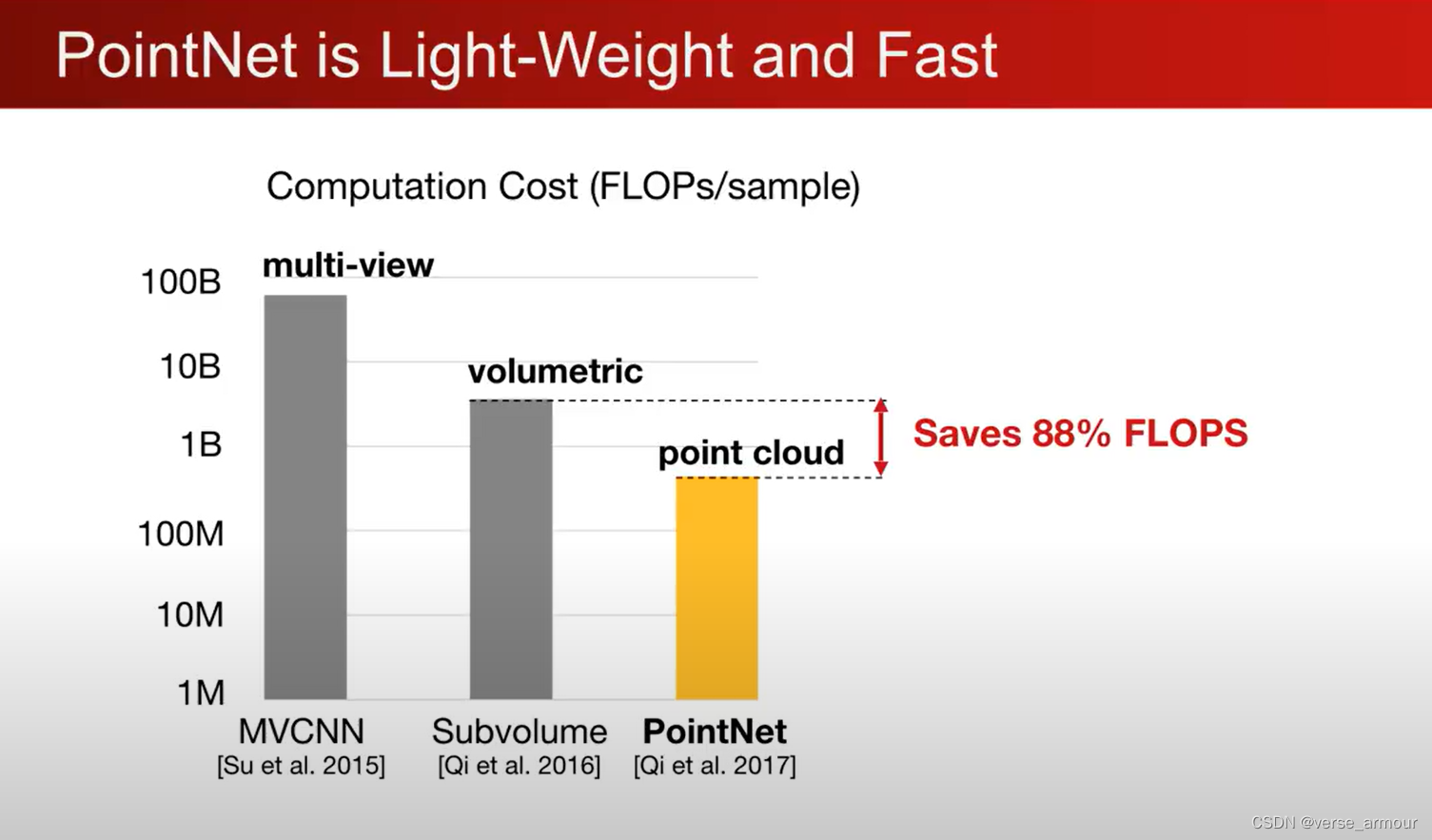
FLOPs:计算量,floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
因为PointNet的高效性,其非常适用于移动设备和可穿戴设备。
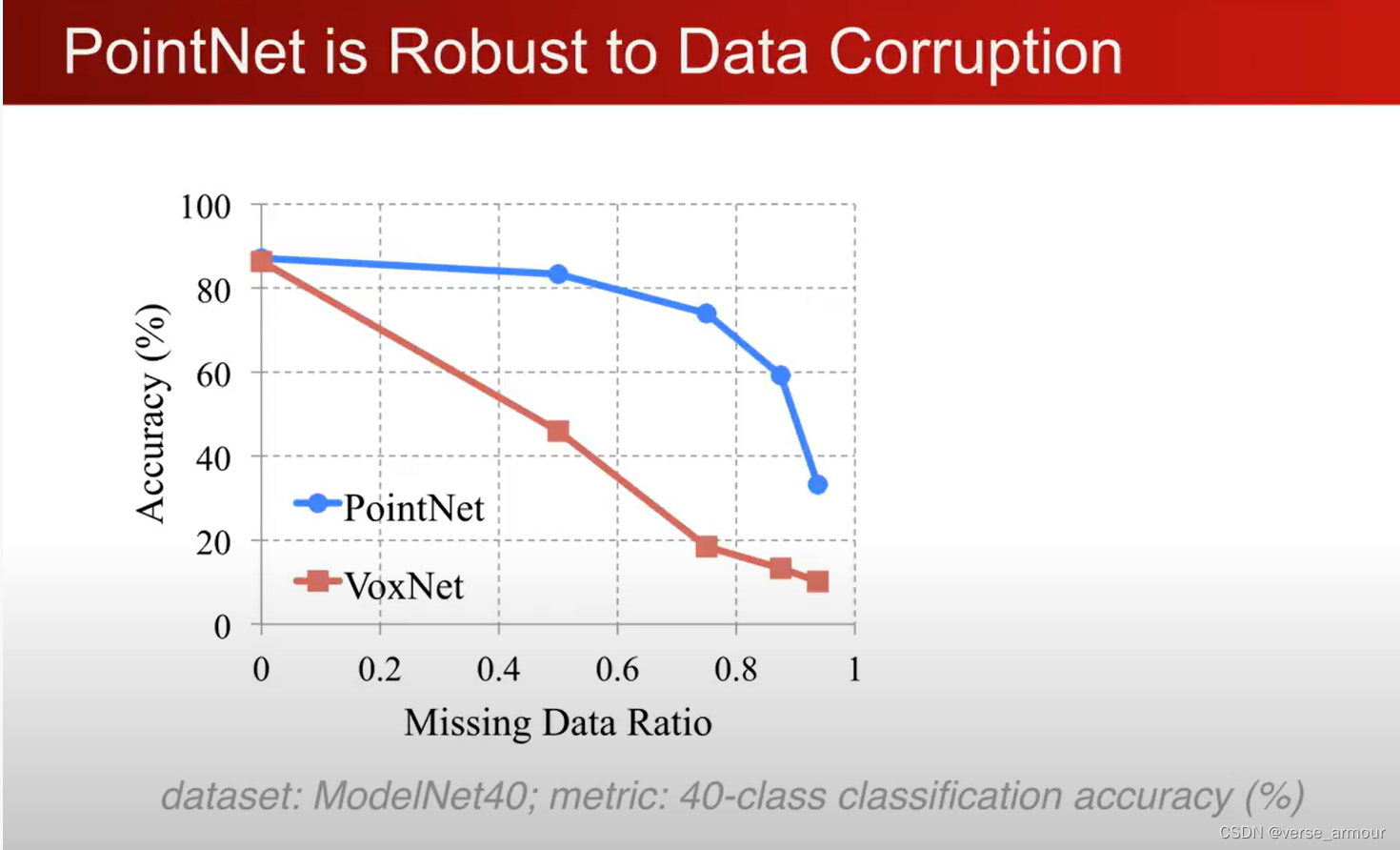
对数据的丢失都非常鲁棒
why?
解释这个可以通过一个可视化去理解:

最大池化使得模型只去关注critical points,这也使得模型对点的丢失具有较好的鲁棒性。
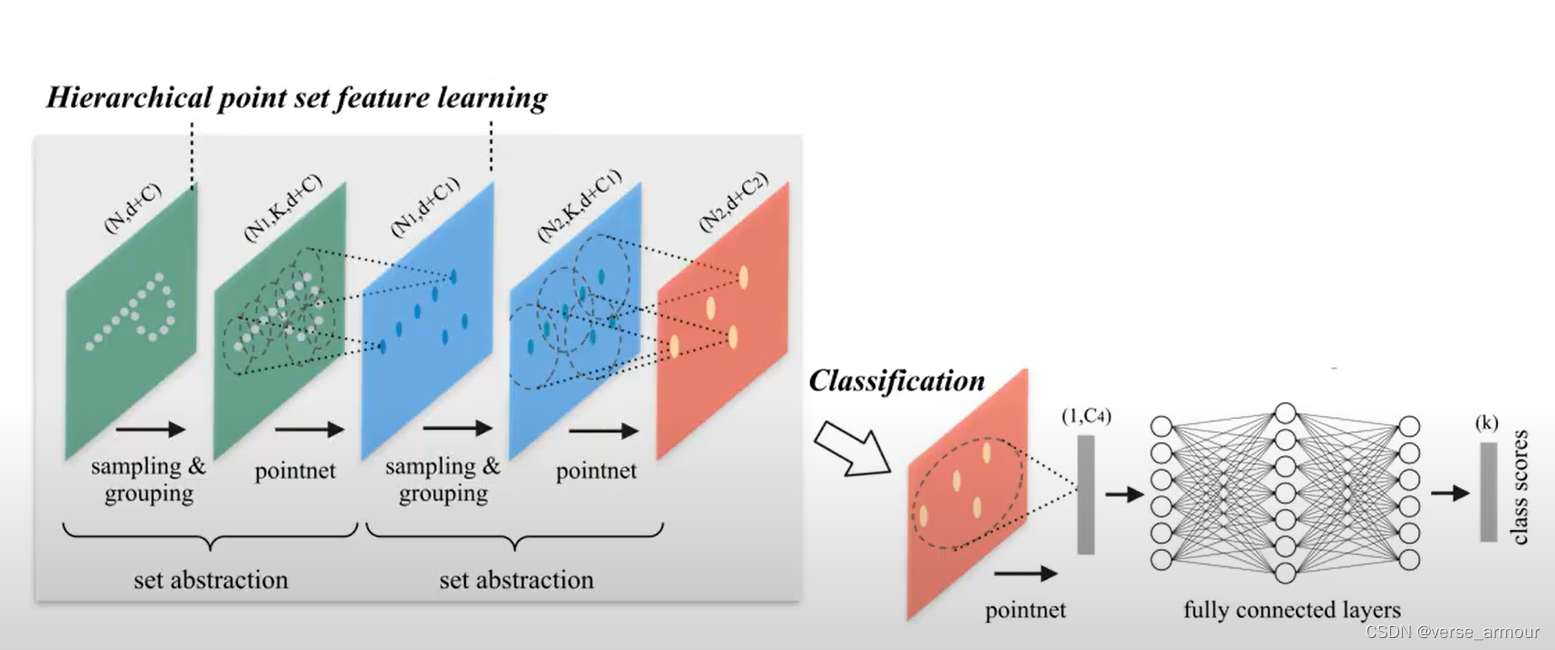
在PointNet中,先对每一个点通过MLP做一个从低维到高维的映射,再对高位的特征通过MLP结合到一起。所以PointNet要么是对一个点做操作,要么是对所有点全局的特征在做操作。所以PointNet和3D卷积相比缺少了一个局部的概念,比较难对一些精细的特征进行学习。此外,在平移不变性上也有一定的缺陷,如果对点云的每一个点进行一个平移操作,那么经过PointNet学习的特征也会完全不一样。

也可以通过一种“up-convolution”的方式将pointnet提取的特征点复原回去。
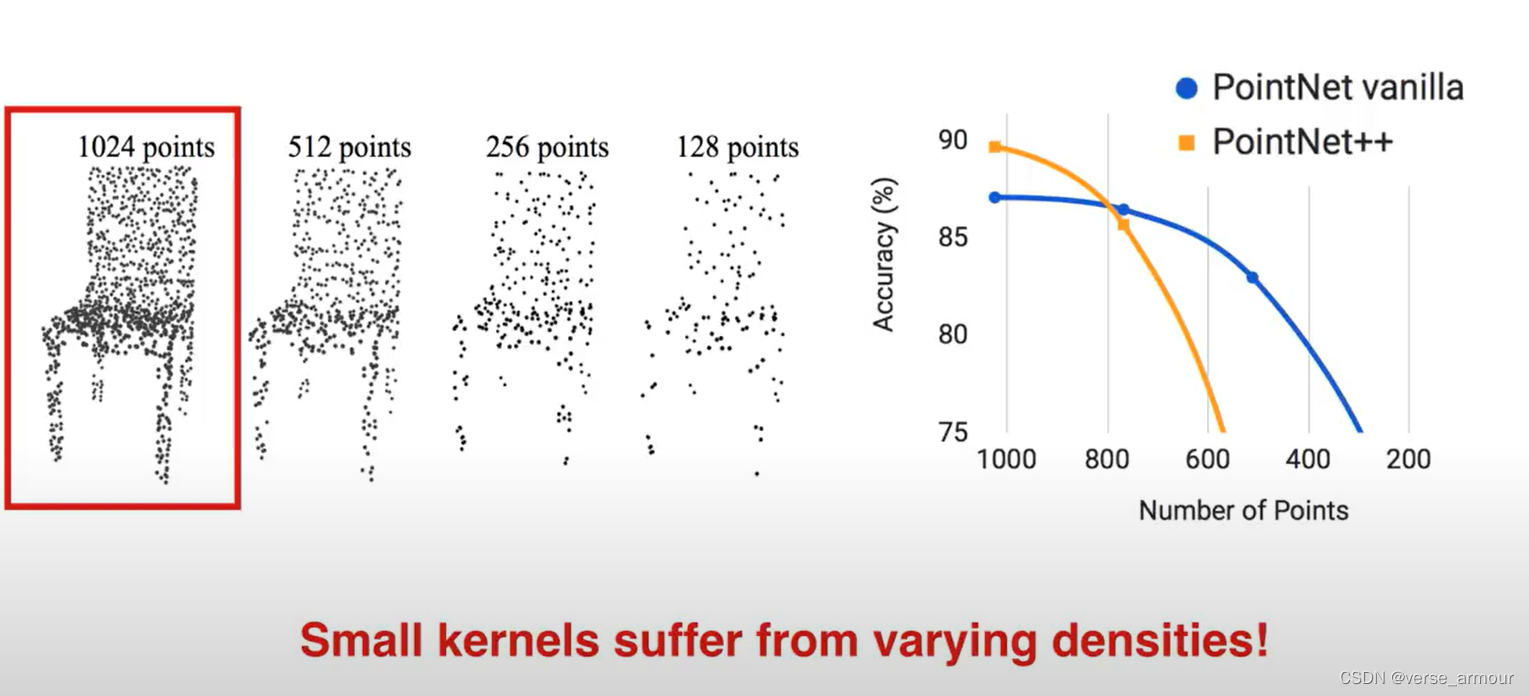
在CNN中现在越来越流行选择非常小的kernel,比如在VGG中大量应用3*3的kernel。
那么在PointNet++中是不是这样呢?其实这是不一定的。
在point cloud中非常常见的一种情况是采样率非常不均匀。比如一个depth camera采样到的point cloud,近的点会非常密集,远的点会非常稀疏。那么对于PointNet++的学习就会在稀疏的地方产生很大的问题。比如在某个地方我们的划定的作用区域中只有一个点,那么在那个区域中学到的特征就会非常不稳定。这是我们很想避免的。
为了量化这个问题,我们做了一个控制变量的实验,验证了点的疏密对PointNet++网络精确度的影响:小的kernel会受采样率不均匀影响较大。
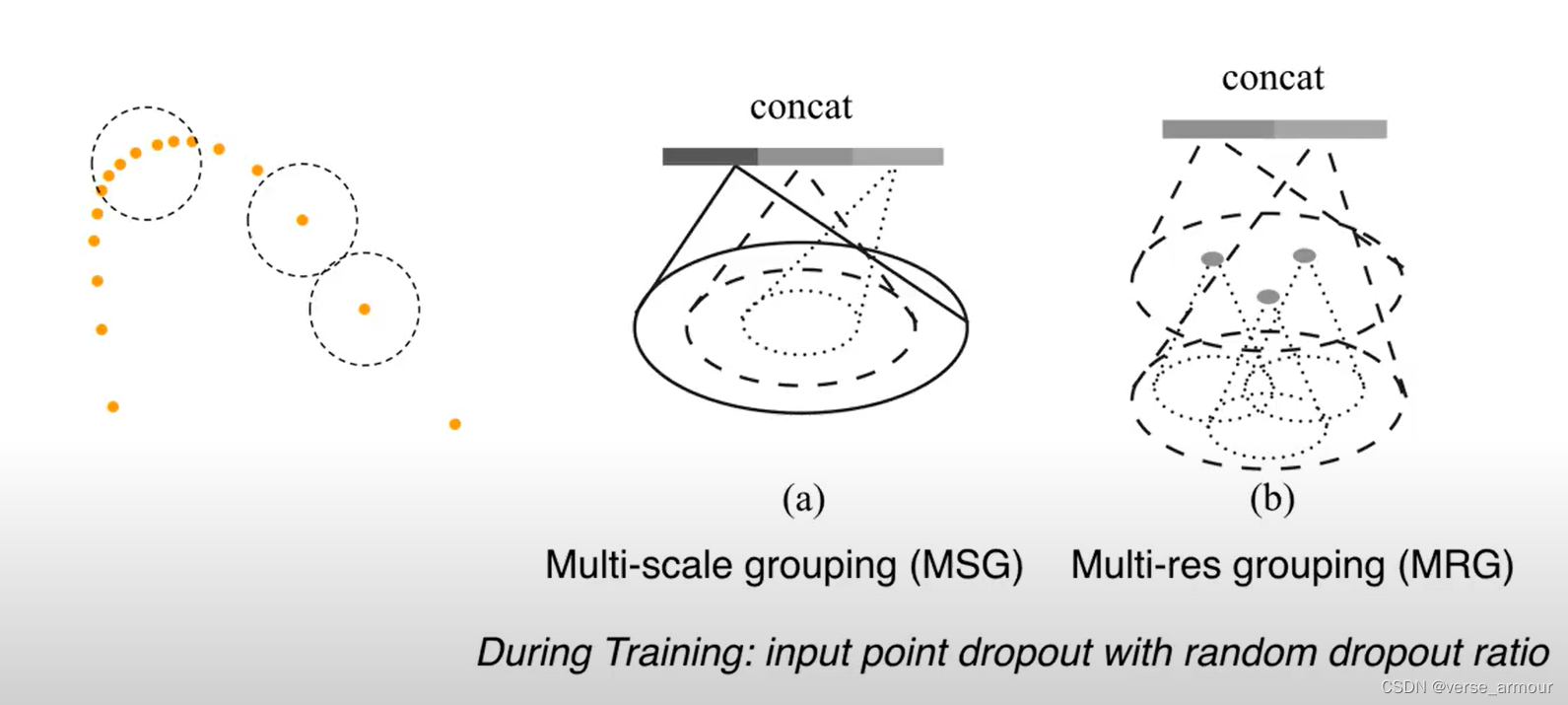
针对这个问题,可以设计一些新的网络结构来避免这个问题。
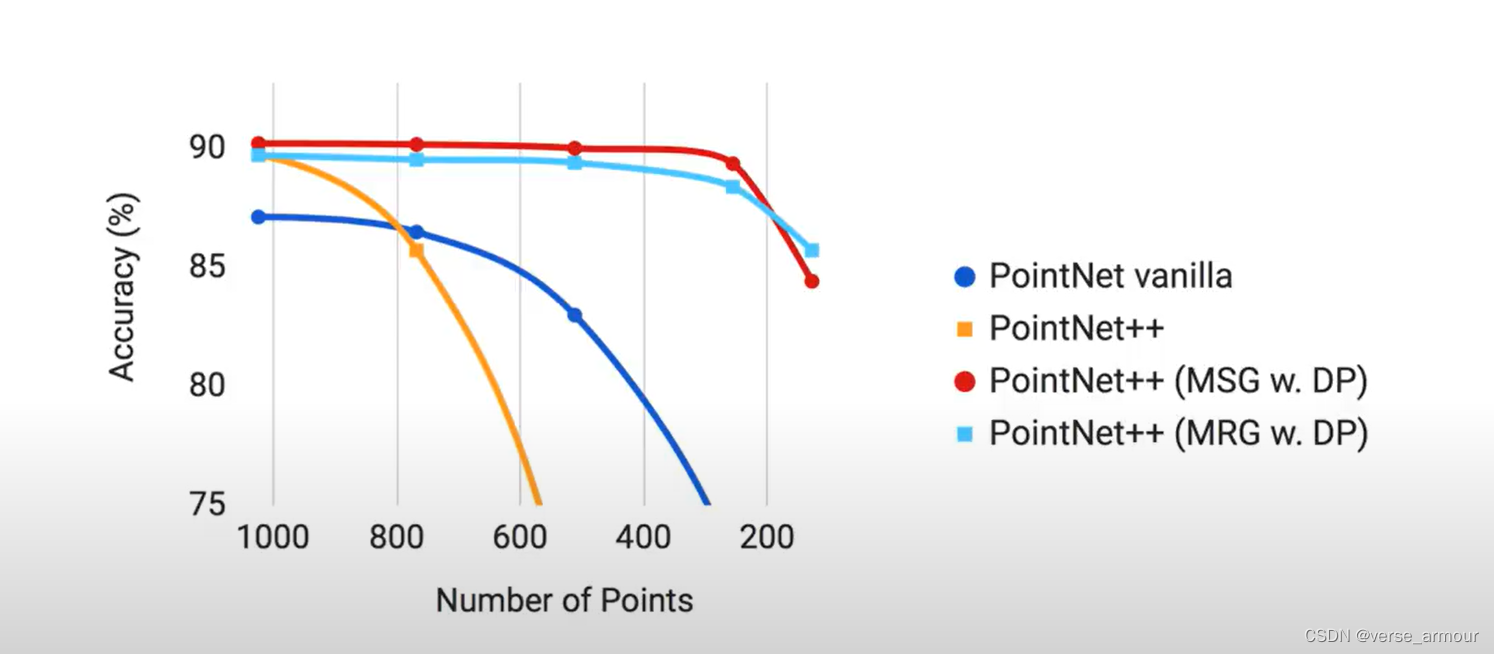
效果对比:



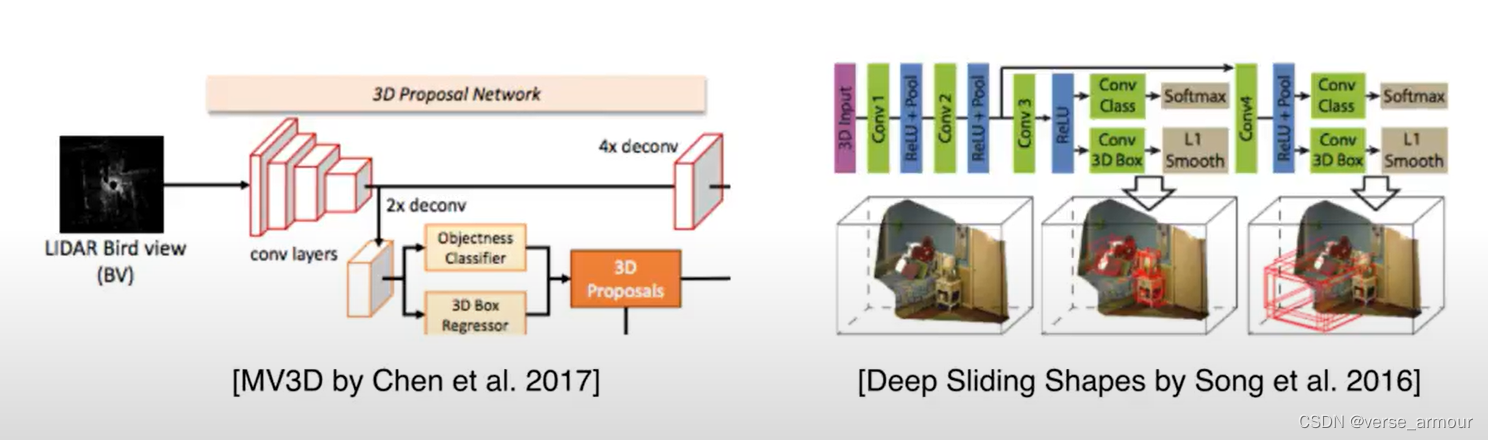
缺点:
- 3D空间的搜索量非常大,计算量也非常大。
- 点云的分辨率有限,比较难发现比较小的物体。
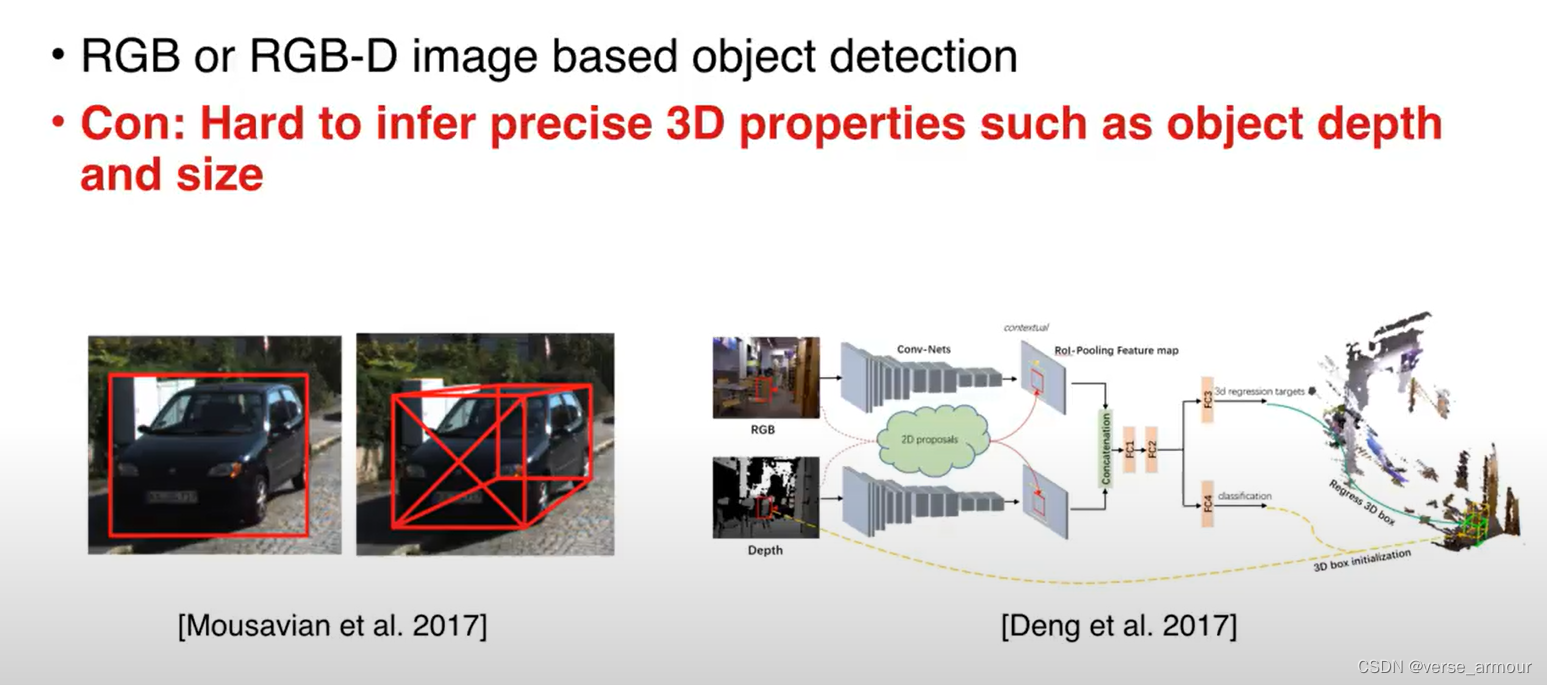
缺点:
RGB图像:依赖物体大小的先验知识,很难估计物体的精确位置。
RGB-D图像:两个实际距离很远的点投影到图像上的距离有可能非常近。
在图片这种表达形式下,用2D的CNN还是受到了很大的局限性。
很难精确地估计物体的深度和大小
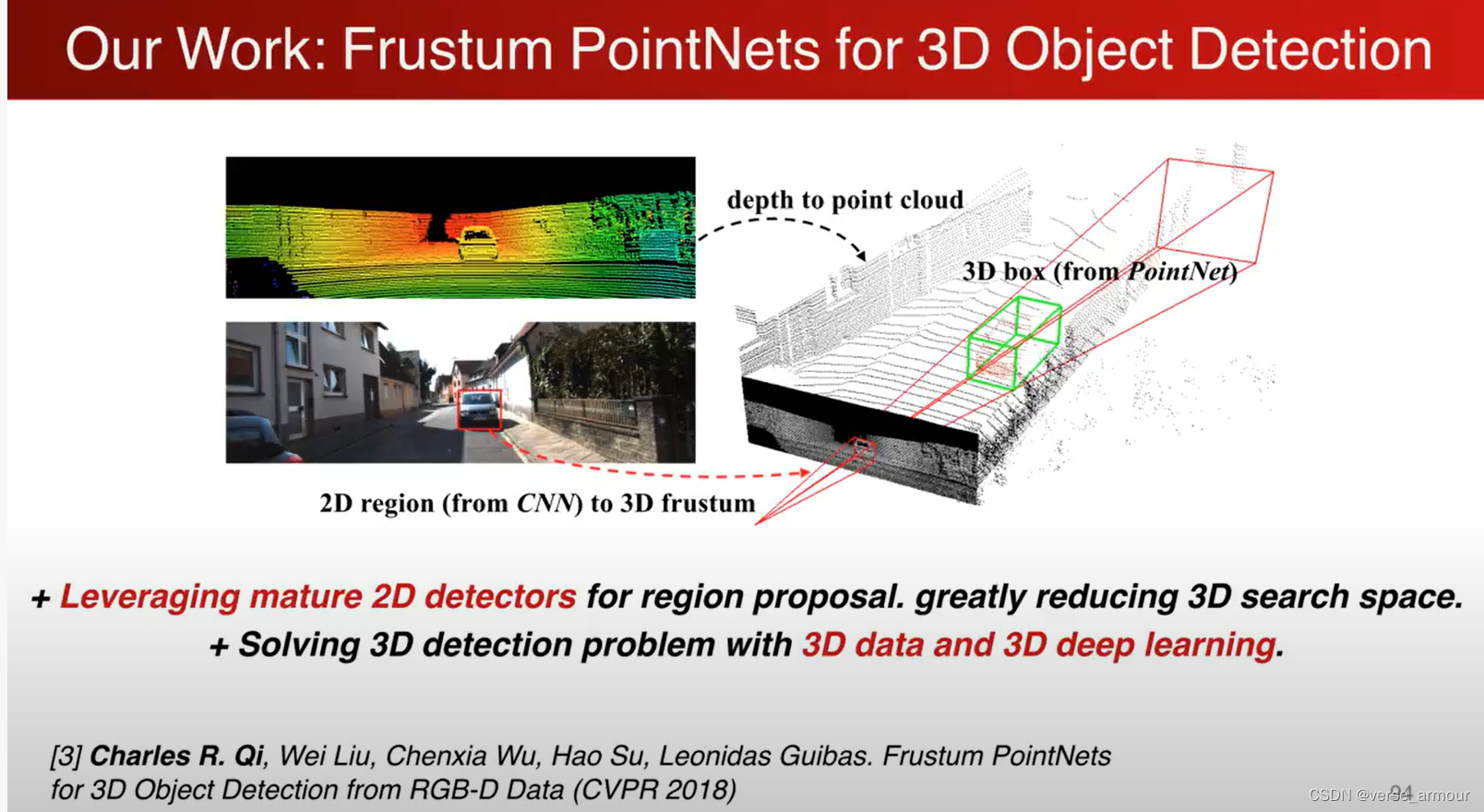
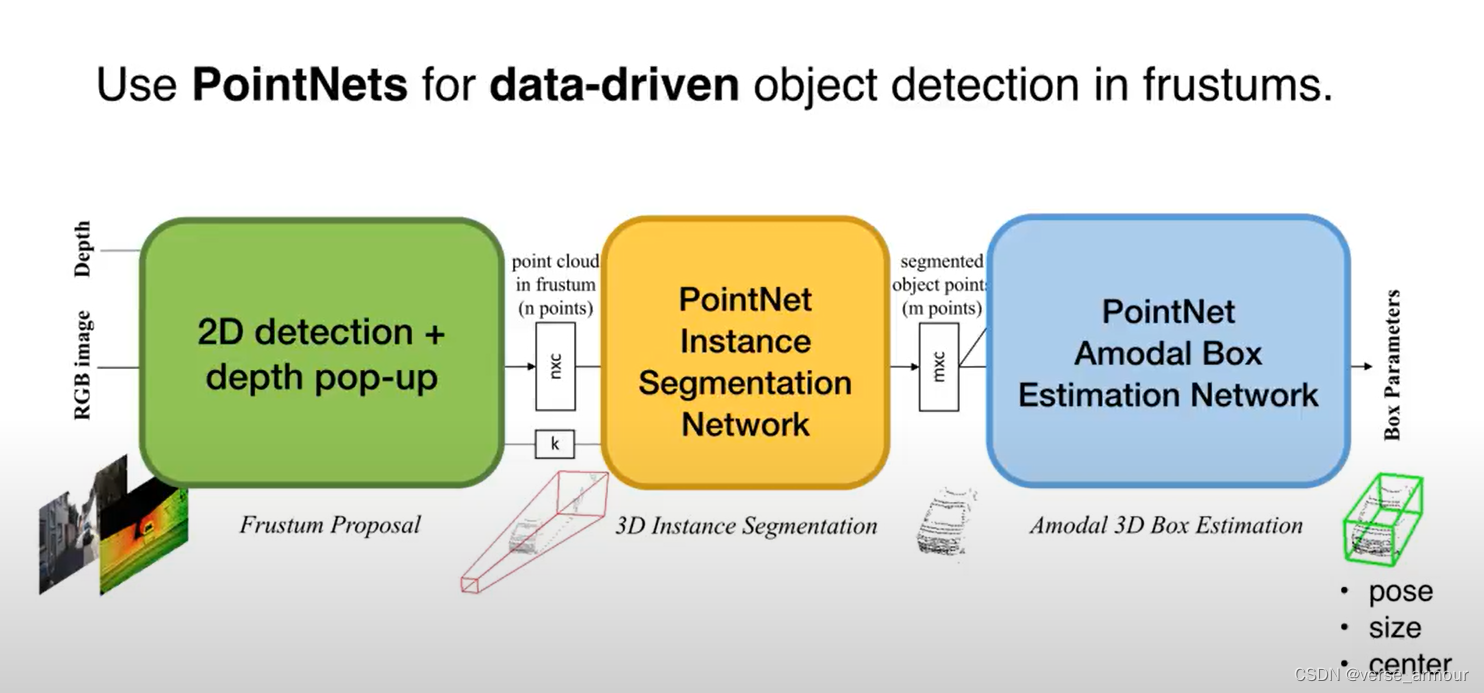
2D detectors for region proposal + 3D frustum + PointNets
整体思想:
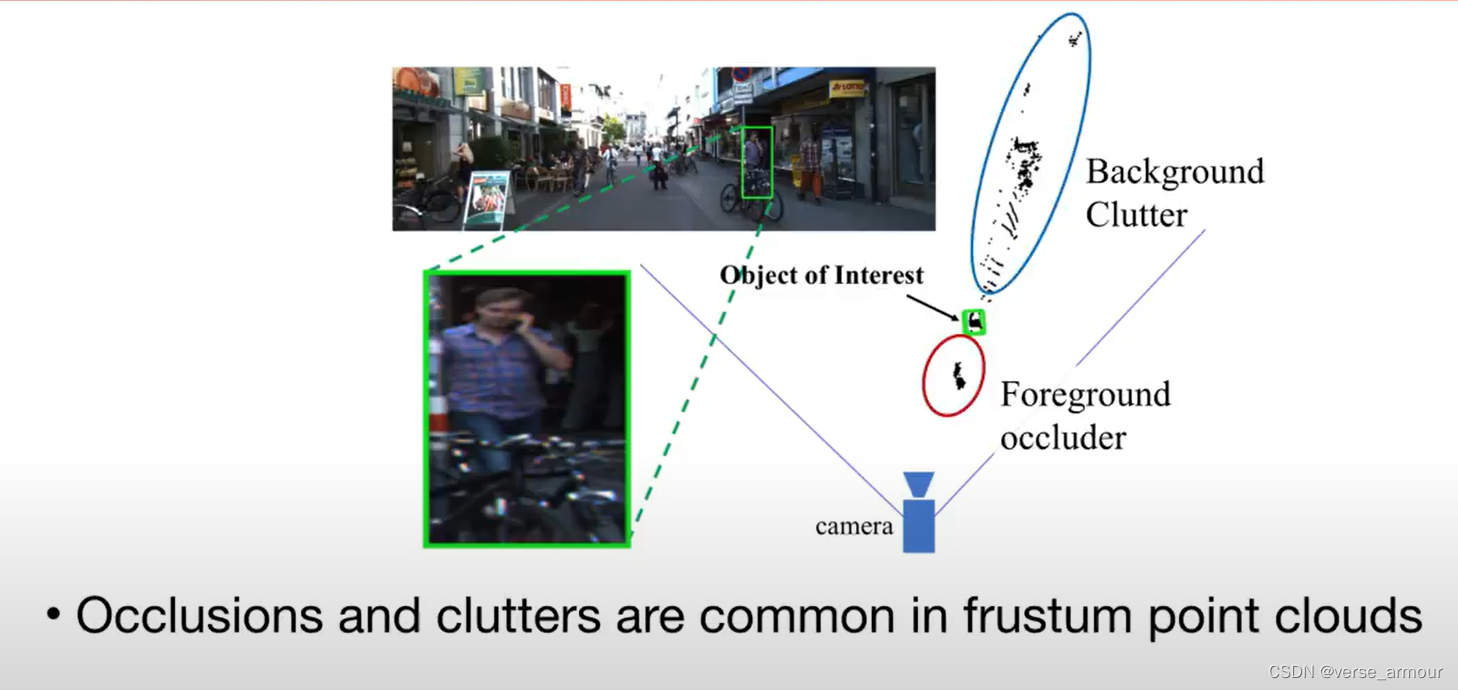
缺点:
occlusions and clutters are common in frustum point clouds
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
Unity自动旋转动画1.开门需要门把手先动,门再动2.关门需要门先动,门把手再动3.中途播放过程中不可以再次进行操作觉得太复杂?查看我的文章开关门简易进阶版效果:如果这个门可以直接打开的话,就不需要放置"门把手"如果门把手还有钥匙需要旋转,那就可以把钥匙放在门把手的"门把手",理论上是可以无限套娃的可调整参数有:角度,反向,轴向,速度运行时点击Test进行测试自己写的代码比较垃圾,命名与结构比较拉,高手轻点喷,新手有类似的需求可以拿去做参考上代码usingSystem.Collections;usingSystem.Collections.Generic;usingUnityEngine;u
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于StackOverflow来说是偏离主题的,因为它们往往会吸引自以为是的答案和垃圾邮件。相反,describetheproblem以及迄今为止为解决该问题所做的工作。关闭9年前。Improvethisquestion是否有适用于这些的3d游戏引擎?
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3
目录一、世界坐标系与本地坐标系二、srcGameObject.transform.TransformPoint(Vector3 vec)三、srcGameObject.transform.TransformVector(Vector3 vec)四、srcGameObject.transform.TransformDirection(Vector3 vec)五:示例一、世界坐标系与本地坐标系 世界坐标很好理解,就是模型的transform.position,通常在无父物体的情况下,创建出来的模型默认位置就是世界坐标系的原点。 每个物体都有自身的坐标系,此坐标系就是本地坐标系。本地坐标
我正在寻找用于开发ruby游戏的3D引擎。我找到了一些类似G3Druby或ogreb的东西。哪个更好用,功能更好?还有比这些更好的引擎吗? 最佳答案 两者似乎都是G3D和Ogre的包装器,因此您实际上应该比较G3D或Ogre是否更适合您的需求。通过包装器的大部分ruby外访问将在设置场景时进行,因此繁重的工作(每一帧)仍然在C/C++库和图形硬件上完成。因此,您应该比较这两个库。我不知道G3D,但它似乎提供了Ogre所缺乏的离线渲染功能。如果您需要专业游戏渲染引擎的广泛功能,Ogre通常是首选,并且您会发现几乎所有您会遇到的
2021年,游戏圈上演了一场精彩绝伦的抢人大战。在上海游戏圈,年薪百万的人越来越多了。据多名HR估算,在上海,过去一年TA、引擎、美术等稀缺岗位拟的薪资涨幅大概在20%-30%左右。某位圈内知名资深游戏猎头对此发出感叹:“50K的数值策划、角色原画;70K的技术美术;80K的技术总监...他们的年薪总包都接近百万,就连应届生入行的薪资也水涨船高,这要是放在以往都是不敢想象的”。以往含年薪、期权等的年总包收入上百万元,起码得是总监级别。如今工作五六年的人从广深跳到上海游戏公司,年薪能从50-70万跃上100万元,拿百万年薪的游戏从业者越来越多了上海游戏圈近年发展迅速,既有颇具发展潜力的中生代F4
关注公众号,发现CV技术之美最近在学习open3d的相关应用,然后遇到了一个很有趣的问题。给定多个mesh,我们可能会需要把他们全部合并到一个文件并使用。但是这并不好实现,因为open3d自己不支持这样的操作。相比之下,其他一些集成度非常高的软件,是可以实现这样的操作的,例如meshlab通过交互栏中的“flattenvisiblelayer”指令来实现。唯一的缺点是,你每次都需要手动操作才行,这对于需要高度自动化的使用场景,就不是很合适了。因此,如何可以实现一个自动化的脚本,支持直接合并多个可染色的mesh,并输出带有纹理的最终结果,是一个非常重要的功能。遗憾的是度娘和谷歌目前没有相关的教程