目录
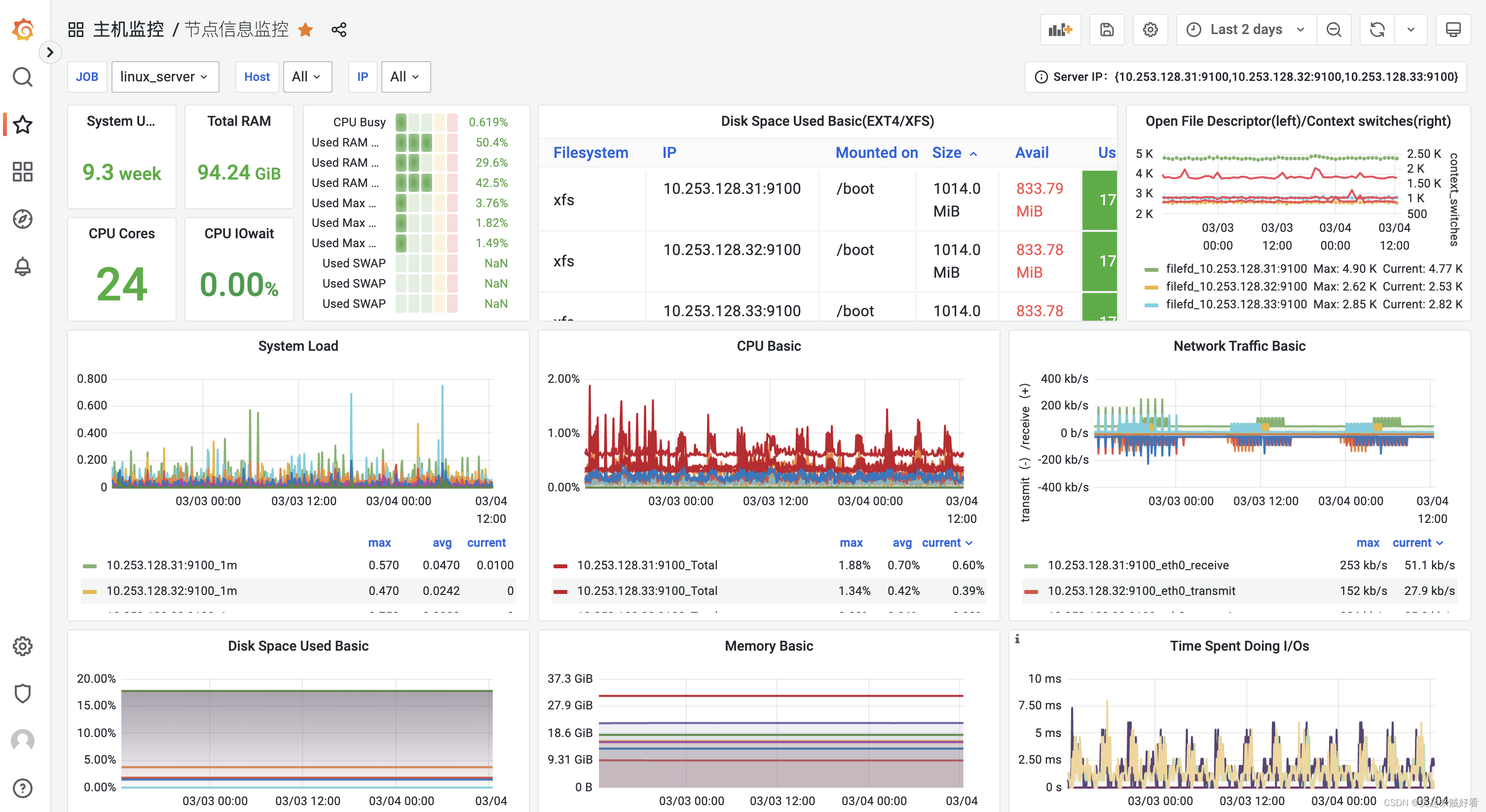
Grafana 是一款开源的数据可视化工具,使用 Grafana 可以非常轻松的将数据转成图表(如下图)的展现形式来做到数据监控以及数据统计。
wget https://dl.grafana.com/enterprise/release/grafana-enterprise-9.1.6.linux-amd64.tar.gz
解压
tar -xvzf grafana-enterprise-9.1.6.linux-arm64.tar.gz
mv grafana-9.1.6 /data/apps/
cd /data/apps/grafana-9.1.6/conf
cp sample.ini grafana.ini
vim grafana.ini
[paths]
# Path to where grafana can store temp files, sessions, and the sqlite3 db (if that is used)
;data = /var/lib/grafana
data = /data/apps/grafana-9.1.6/data
logs = /data/apps/grafana-9.1.6/logs
plugins = /data/apps/grafana-9.1.6/plugins
[log]
mode = file
level = warn
groupadd -g 9100 monitor
useradd -g 9100 -u 9100 -s /sbin/nologin -M monitor
mkdir data && mkdir logs && mkdir plugins
chown -R monitor:monitor grafana-9.1.6
vim /usr/lib/systemd/system/grafana.service
[Unit]
Description=grafana service
After=network.target
[Service]
User=monitor
Group=monitor
KillMode=control-group
Restart=on-failure
RestartSec=60
ExecStart=/data/apps/grafana-9.1.6/bin/grafana-server -config /data/apps/grafana-9.1.6/conf/grafana.ini -pidfile /data/apps/grafana-9.1.6/grafana.pid -homepath /data/apps/grafana-9.1.6
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl restart grafana.service
systemctl enable grafana.service
systemctl status grafana
配置 mapping 文件
cd /usr/local/graphite_exporter
vim graphite_exporter_mapping
graphite_exportergraphite_exportengs:
- match: '*.*.executor.filesystem.*.*'
name: spark_app_filesystem_usage
labels:
application: $1
executor_id: $2
fs_type: $3
qty: $4
- match: '*.*.jvm.*.*'
name: spark_app_jvm_memory_usage
labels:
application: $1
executor_id: $2
mem_type: $3
qty: $4
- match: '*.*.executor.jvmGCTime.count'
name: spark_app_jvm_gcTime_count
labels:
application: $1
executor_id: $2
- match: '*.*.jvm.pools.*.*'
name: spark_app_jvm_memory_pools
labels:
application: $1
executor_id: $2
mem_type: $3
qty: $4
- match: '*.*.executor.threadpool.*'
name: spark_app_executor_tasks
labels:
application: $1
executor_id: $2
qty: $3
- match: '*.*.BlockManager.*.*'
name: spark_app_block_manager
labels:
application: $1
executor_id: $2
type: $3
qty: $4
- match: '*.*.DAGScheduler.*.*'
name: spark_app_dag_scheduler
labels:
application: $1
executor_id: $2
type: $3
qty: $4
- match: '*.*.CodeGenerator.*.*'
name: spark_app_code_generator
labels:
application: $1
executor_id: $2
type: $3
qty: $4
- match: '*.*.HiveExternalCatalog.*.*'
name: spark_app_hive_external_catalog
labels:
application: $1
executor_id: $2
type: $3
qty: $4
- match: '*.*.*.StreamingMetrics.*.*'
name: spark_app_streaming_metrics
labels:
application: $1
executor_id: $2
app_name: $3
type: $4
qty: $5
修改spark的metrics.properties配置文件,让其推送metrics到Graphite_exporter
*.sink.graphite.class=org.apache.spark.metrics.sink.GraphiteSink
*.sink.graphite.host=10.253.128.31
*.sink.graphite.port=9108
*.sink.graphite.period=10
*.sink.graphite.unit=seconds
#*.sink.graphite.prefix=<optional_value>
namenode.yaml
---
startDelaySeconds: 0
hostPort: localhost:1234 #master为本机IP(一般可设置为localhost);1234为想设置的jmx端口
#jmxUrl: service:jmx:rmi:///jndi/rmi://127.0.0.1:1234/jmxrmi
ssl: false
lowercaseOutputName: false
lowercaseOutputLabelNames: false
datanode.yaml
---
startDelaySeconds: 0
hostPort: localhost:1244 #master为本机IP(一般可设置为localhost);1244为想设置的jmx端口(可设置为未被占用的端口)
#jmxUrl: service:jmx:rmi:///jndi/rmi://127.0.0.1:1234/jmxrmi
ssl: false
lowercaseOutputName: false
lowercaseOutputLabelNames: false
配置 hadoop-env.sh
export HADOOP_NAMENODE_JMX_OPTS="-Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.port=1234 -javaagent:/jmx_prometheus_javaagent-0.8.jar=9211:/namenode.yaml"
export HADOOP_DATANODE_JMX_OPTS="-Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.port=1244 -javaagent:/jmx_prometheus_javaagent-0.8.jar=9212:/datanode.yaml"
yarn.yaml
---
startDelaySeconds: 0
hostPort: localhost:2111 #master为本机IP(一般可设置为localhost);1234为想设置的jmx端口
#jmxUrl: service:jmx:rmi:///jndi/rmi://127.0.0.1:1234/jmxrmi
ssl: false
lowercaseOutputName: false
lowercaseOutputLabelNames: false
配置 yarn-env.sh
export YARN_JMX_OPTS="-Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.port=2111 -javaagent:/jmx_prometheus_javaagent-0.8.jar=9323:/yarn.yaml"
master.yaml
---
startDelaySeconds: 0
hostPort: IP:1254 #master为本机IP(一般可设置为localhost);1234为想设置的jmx端口(可设
#jmxUrl: service:jmx:rmi:///jndi/rmi://127.0.0.1:1234/jmxrmi
ssl: false
lowercaseOutputName: false
lowercaseOutputLabelNames: false
regionserver.yaml
---
startDelaySeconds: 0
hostPort: IP:1255 #master为本机IP(一般可设置为localhost);1234为想设置的jmx端口
#jmxUrl: service:jmx:rmi:///jndi/rmi://127.0.0.1:1234/jmxrmi
ssl: false
lowercaseOutputName: false
lowercaseOutputLabelNames: false
配置 hbase-env.sh
HBASE_M_JMX_OPTS="-Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmx remote.port=1254 -javaagent:/jmx_prometheus_javaagent-0.8.jar=9523:/hbasem.yaml"
#======================================= prometheus jmx export start===================================
HBASE_JMX_OPTS="-Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxre mote.port=1255 -javaagent:/jmx_prometheus_javaagent-0.8.jar=9522:/hbase.yaml"
#======================================= prometheus jmx export end ===================================
希望对正在查看文章的您有所帮助,记得关注、评论、收藏,谢谢您
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
如果使用Marshal.dump写入文件,我有一个Ruby散列达到大约10兆字节。gzip压缩后约为500KB。在ruby中迭代和改变这个散列是非常快的(几分之一毫秒)。即使复制它也非常快。问题是我需要在RubyonRails进程之间共享此散列中的数据。为了使用Rails缓存(file_store或memcached)执行此操作,我需要先Marshal.dump文件,但这会在序列化文件时产生1000毫秒的延迟,在序列化文件时产生400毫秒的延迟。理想情况下,我希望能够在100毫秒内从每个进程保存和加载此哈希。一个想法是生成一个新的Ruby进程来保存这个散列,该散列为其他进程提供AP
文章目录概述背景为何要存算分离优势**应用场景**存算分离产品技术流派华为JuiceFSHashDataXSKY概述背景Hadoop一出生就是奔存算一体设计,当时设计思想就是存储不动而计算(code也即是代码程序)动,负责调度Yarn会把计算任务尽量发到要处理数据所在的实例上,这也是与传统集中式存储最大的不同。为何当时Hadoop设计存算一体的耦合?要知道2006年服务器带宽只有100Mb/s~1Gb/s,但是HDD也即是磁盘吞吐量有50MB/s,这样带宽远远不够传输数据,网络瓶颈尤为明显,无奈之举只好把计算任务发到数据所在的位置。众观历史常言道天下分久必合合久必分,随着云计算技术的发展,数据
目录:一、简介二、HQL的执行流程三、索引四、索引案例五、Hive常用DDL操作六、Hive常用DML操作七、查询结果插入到表八、更新和删除操作九、查询结果写出到文件系统十、HiveCLI和Beeline命令行的基本使用十一、Hive配置一、简介Hive是一个构建在Hadoop之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类SQL查询功能,用于查询的SQL语句会被转化为MapReduce作业,然后提交到Hadoop上运行。特点:简单、容易上手(提供了类似sql的查询语言hql),使得精通sql但是不了解Java编程的人也能很好地进行大数据分析;灵活性高,可以自定义用户函数(UDF)和
是否可以在我的服务器上运行任何工具来监控多个Rails应用程序?我需要监控每个应用程序收到的请求数、每个应用程序使用了多少内存、使用了多少CPU以及其他类似的统计信息。我需要查看每个单独的Rails应用程序的统计信息。 最佳答案 我建议你试试NewRelicRPM.免费版:RPMLiteisthemostwidelyusedsolutionforbasicwebapplicationmonitoring.RPMLiteprovidesapplicationmonitoringforunlimitedJava,RubyorJRubya
我正在寻找一种方法来监视流上的事件,以便我可以确定是否有任何内容通过流。如果有,我将开始使用rtmpdump进行录制。我想象这是通过运行一个每60秒检查一次流的cron任务来实现的。如果它确定流正在通过,则调用rtmpdump开始记录它。如果没有,则什么都不做,并在60秒后再次检查。由于rtmpdump只是在没有流数据时出现错误,因此尝试使用它来监视流似乎不是一个好主意,但也许我错了。如果我在逐个案例的基础上手动执行此操作会很容易,但我正在尝试自动执行自动录制流的任务(如果它们可用)。有没有人遇到过这样做的方法?也许我可以在命令行(linux)中使用其他一些工具?如果有帮助,我正在使用
我有以下场景:我需要在一个非常大的集合中找出唯一的ID列表。例如,我有6000个id数组(关注者列表),每个数组的大小范围在1到25000(他们的关注者列表)之间。我想获得所有这些ID数组中的唯一ID列表(关注者的唯一关注者)。完成后,我需要减去另一个ID列表(另一个人的关注者列表)并获得最终计数。最后一组唯一ID增长到大约60,000,000条记录。在ruby中,将数组添加到大数组时,它开始变得非常慢,大约几百万。添加到集合中一开始需要0.1秒,然后增长到200万时需要超过4秒(离我需要去的地方不远)。我用java编写了一个测试程序,它在不到一分钟的时间内完成了整个过程。也许我在
人类生活在充满多样性的世界里。长久以来的研究发现,人类的脑与行为受到基因、环境和文化及其相互作用的塑造,然而这种影响发生的机制始终缺乏系统性探索与研究。近年来,前沿神经影像技术方法飞速进步,推动着多模态脑成像大数据集的产生和融合性探索,并让学界得以深入探究人脑宏观结构与功能连接组架构,为包括上述主题在内的许多有趣而重要的科学问题带来了新的启发和思路。2022年12月20日,北京大学物理学院、IDG麦戈文脑科学研究所高家红团队在《NatureNeuroscience》在线发表了题为“IncreasingdiversityinconnectomicswiththeChineseHumanConne