网络爬虫——BeautifulSoup详讲与实战
前言: 📝📝此专栏文章是专门针对网络爬虫基础,欢迎免费订阅!
📝📝第一篇文章《1.认识网络爬虫》获得全站热搜第一,python领域热搜第一, 第四篇文章《4.网络爬虫—Post请求(实战演示)》全站热搜第八,欢迎阅读! 🎈🎈欢迎大家一起学习,一起成长!!
💕💕:悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。
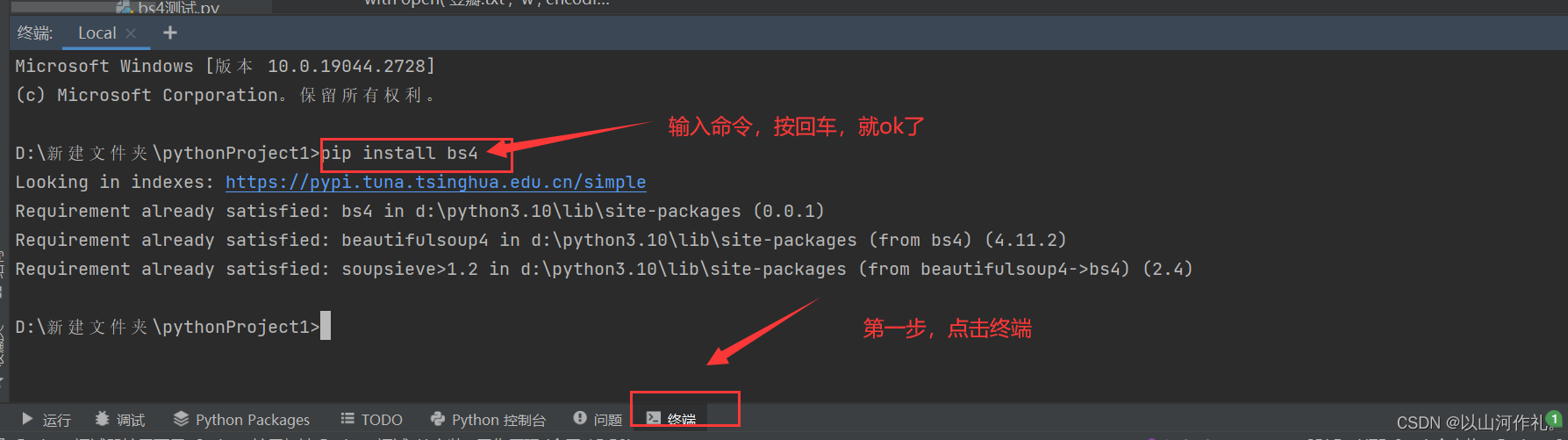
由于 Bautiful Soup 是第三方库,因此需要单独下载,下载方式非常简单,执行以下命令即可安装:
pip install bs4
BeautifulSoup4(BS4)对象是BeautifulSoup库解析HTML或XML文档并创建的Python对象。它是一个树形结构,其中包含了文档中的节点,例如标签、字符串和注释。BS4对象可以解析HTML和XML文档,并提供了许多方法来完成对节点的查找、筛选和修改的操作。
例如,可以使用
.find()方法查找包含特定文本的标签,使用.select()方法根据CSS选择器选择元素,使用.text
属性获取标签的文本内容等等。所有这些方法都是BS4对象中提供的。
创建 BS4 解析对象是万事开头的第一步,这非常地简单,语法格式如下所示:
#导入解析包
from bs4 import BeautifulSoup
#创建beautifulsoup解析对象
soup = BeautifulSoup(html_doc, 'html.parser') # html_doc 表示要解析的文档,而 html.parser 表示解析文档时所用的解析器,此处的解析器也可以是 'lxml' 或者 'html5lib'
#prettify()用于格式化输出html/xml文档
print(soup.prettify())
完整代码:
# 导入解析包
from bs4 import BeautifulSoup
import requests
url = 'https://movie.douban.com/subject/35457272/?from=showing'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
html = requests.get(url, headers=headers)
# 创建beautifulsoup解析对象
soup = BeautifulSoup(html.text,
'html.parser') # html_doc 表示要解析的文档,而 html.parser 表示解析文档时所用的解析器,此处的解析器也可以是 'lxml' 或者 'html5lib'
# prettify()用于格式化输出html/xml文档
print(soup.prettify())
这段代码使用了Python中的BeautifulSoup库和requests库,对指定网页进行了请求并用BeautifulSoup解析了返回的HTML文档。最后使用prettify()方法格式化输出解析后的文档。
运行结果:
Beautiful Soup 将 HTML 文档转换成一个树形结构,该结构有利于快速地遍历和搜索 HTML 文档。下面使用树状结构来描述一段 HTML 文档:
<html>
<head>
<title>中文</title>
</head>
<body>
<h1>net</h1>
<p>
<b>编程</b>
</p>
</body>
</html>
树状图如下所示:
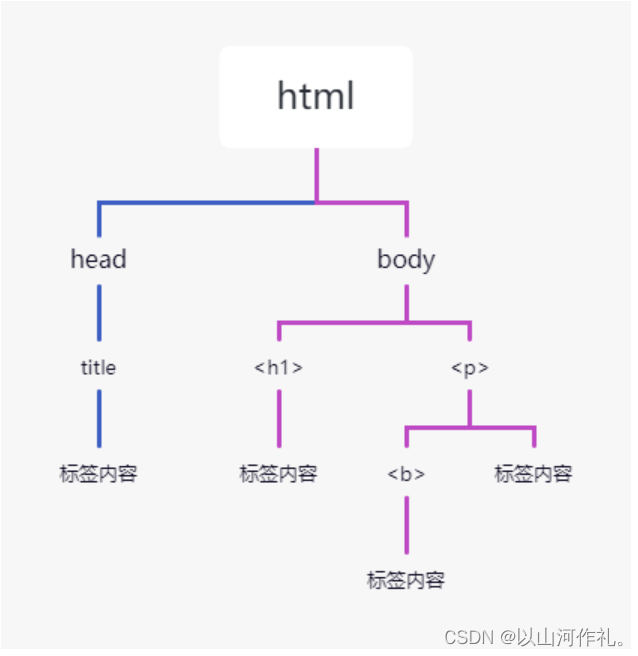
文档树中的每个节点都是 Python 对象,这些对象大致分为四类:Tag , NavigableString , BeautifulSoup
, Comment 。其中使用最多的是 Tag 和 NavigableString。
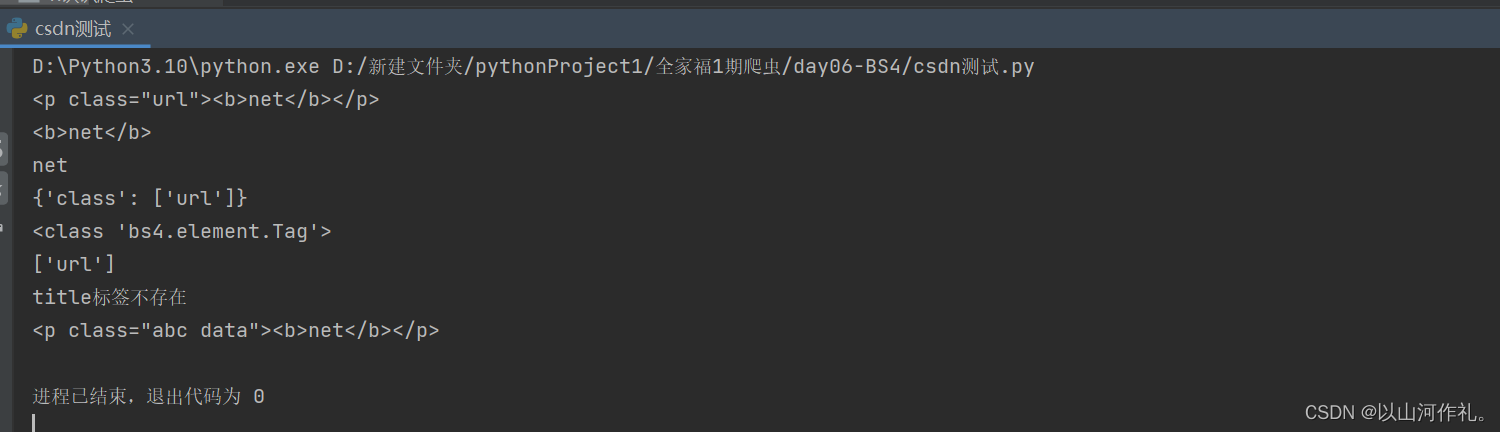
标签(Tag)是组成 HTML 文档的基本元素。在 BS4 中,通过标签名和标签属性可以提取出想要的内容。看一组简单的示例
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p class="url"><b>net</b></p>', 'html.parser')
# 获取第一个p标签的html代码
print(soup.p)
# 获取b标签
print(soup.p.b)
# 获取p标签内容,使用NavigableString类中的string、text、get_text()
print(soup.p.text)
# 返回一个字典,里面是多有属性和值
print(soup.p.attrs)
# 查看返回的数据类型
print(type(soup.p))
# 根据属性,获取标签的属性值,返回值为列表 不存在就报错
print(soup.p['class'])
# 获取具体属性 获取最近的第一个属性 不存在就返回None
if soup.title:
print(soup.title.get('class'))
else:
print('title标签不存在')
# 给class属性赋值,此时属性值由列表转换为字符串
soup.p['class'] = ['abc', 'data']
print(soup.p)
Tag 对象提供了许多遍历 tag 节点的属性,比如 contents、children 用来遍历子节点;parent 与 parents 用来遍历父节点;示例如下:
from bs4 import BeautifulSoup
import requests
url = 'https://movie.douban.com/subject/35457272/?from=showing'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text, 'html.parser')
# 查找第一个符合条件的标签
print(soup.find('span', class_='year'))
# 查找所有符合条件的标签
for item in soup.find_all('span', class_='rating_num'):
print(item.text)
# 使用CSS选择器查找标签
print(soup.select('#content > h1 > span:nth-child(1)'))
# 遍历所有文本内容
for string in soup.stripped_strings:
print(string)

上述代码中,我们首先使用requests库获取了指定网页的HTML文档,然后使用BeautifulSoup库解析HTML文档,并使用不同的方法遍历了节点,包括:
使用find()方法查找第一个符合条件的标签,其中class_参数用于指定class属性的值。
使用find_all()方法查找所有符合条件的标签,返回一个列表。
使用select()方法使用CSS选择器查找标签,返回一个列表。
使用stripped_strings属性遍历所有文本内容,返回一个生成器。需要注意的是,stripped_strings返回的是去除空白字符后的文本内容。
find_all()与find()都是BeautifulSoup对象的方法,用于在HTML文档中查找符合条件的标签。
find_all():返回所有符合条件的标签,结果是一个列表。如果没有符合条件的标签,则返回空列表。
find_all()是BeautifulSoup对象的方法,用于在HTML文档中查找符合条件的标签。
该方法的语法格式为:soup.find_all(name, attrs, recursive, string, limit,
**kwargs),其中各参数的含义如下:
下面是一个示例代码,演示如何使用find_all()方法查找符合条件的标签:
from bs4 import BeautifulSoup
html_doc = """
<html>
<head>
<title>电影列表</title>
</head>
<body>
<h1>电影列表</h1>
<div class="movie">
<h2>黑白迷宫</h2>
<p>导演:张艺谋</p>
<p>主演:李连杰、章子怡</p>
<p>评分:<span class="rating">8.9</span></p>
</div>
<div class="movie">
<h2>西游记之大圣归来</h2>
<p>导演:田晓鹏</p>
<p>主演:张磊、石磊、杨晓婧</p>
<p>评分:<span class="rating">9.2</span></p>
</div>
</body>
</html>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
# 查找所有div标签
div_list = soup.find_all('div')
print(div_list)
# 查找class属性值为"movie"的div标签
movie_list = soup.find_all('div', class_='movie')
print(movie_list)
# 查找评分大于9.0的电影
rating_list = soup.find_all('span', class_='rating', string=lambda x: float(x) > 9.0)
print(rating_list)
# 查找第一个电影的导演名
director = soup.find('div', class_='movie').find('p').next_sibling.string
print(director)
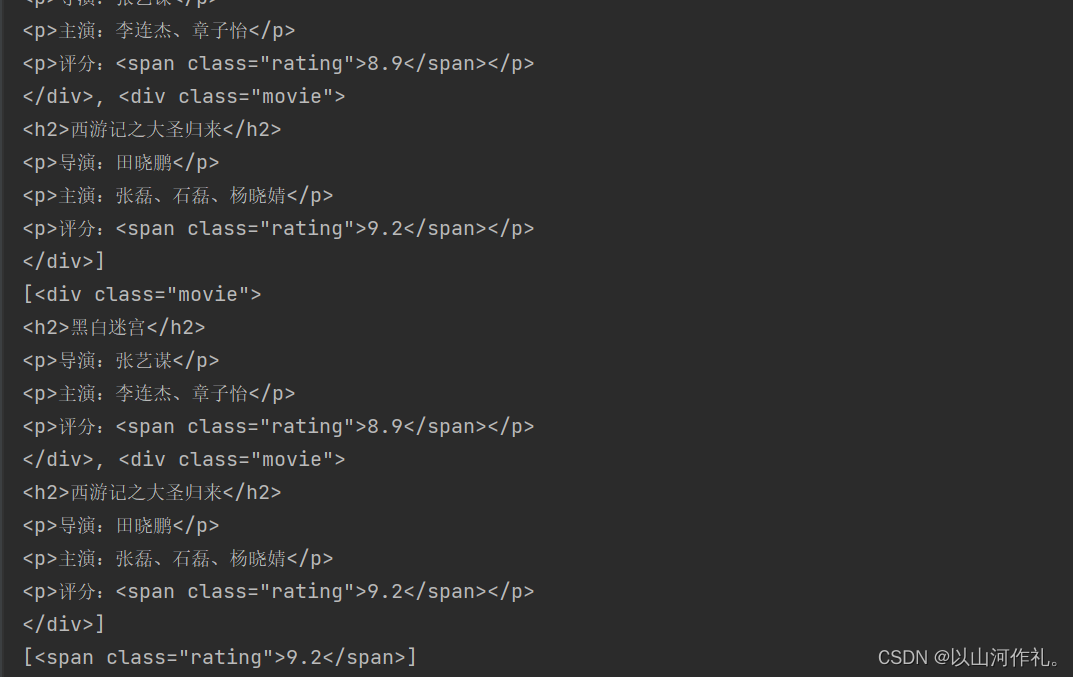
上述代码中,我们首先定义了一个HTML文档字符串,然后使用BeautifulSoup库解析HTML文档,并使用find_all()方法查找了符合条件的标签。
具体来说:
find_all('div')方法查找所有div标签,并将结果存储在div_list列表中。find_all('div',class_='movie')方法查找所有class属性值为"movie"的div标签,并将结果存储在movie_list列表中。find_all('span', class_='rating', string=lambda x: float(x) > 9.0)方法查找所有class属性值为"rating"且文本内容大于9.0的span标签,并将结果存储在rating_list列表中。注意这里使用了lambda表达式作为string参数的值,表示只返回文本内容大于9.0的标签。find('div',class_='movie').find('p').next_sibling.string方法查找第一个class属性值为"movie"的div标签中第一个p标签的下一个兄弟节点的文本内容,即导演名。需要注意的是,next_sibling属性返回下一个兄弟节点,可能是空白字符节点,因此需要使用string属性获取文本内容。find():返回第一个符合条件的标签,结果是一个Tag对象。如果没有符合条件的标签,则返回None。
find()是BeautifulSoup对象的方法,用于在HTML文档中查找第一个符合条件的标签。
该方法的语法格式为:soup.find(name, attrs, recursive, string,
**kwargs),其中各参数的含义与find_all()方法相同。与find_all()方法不同的是,find()只返回第一个符合条件的标签,并且返回的是一个Tag对象,而不是一个列表。如果没有找到符合条件的标签,则返回None。
下面是一个示例代码,演示如何使用find()方法查找符合条件的标签:
from bs4 import BeautifulSoup
html_doc = """
<html>
<head>
<title>电影列表</title>
</head>
<body>
<h1>电影列表</h1>
<div class="movie">
<h2>黑白迷宫</h2>
<p>导演:张艺谋</p>
<p>主演:李连杰、章子怡</p>
<p>评分:<span class="rating">8.9</span></p>
</div>
<div class="movie">
<h2>西游记之大圣归来</h2>
<p>导演:田晓鹏</p>
<p>主演:张磊、石磊、杨晓婧</p>
<p>评分:<span class="rating">9.2</span></p>
</div>
</body>
</html>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
# 查找第一个div标签
div = soup.find('div')
print(div)
# 查找class属性值为"movie"的第一个div标签
movie = soup.find('div', class_='movie')
print(movie)
# 查找评分大于9.0的第一个电影
rating = soup.find('span', class_='rating', string=lambda x: float(x) > 9.0)
print(rating)
# 查找第一个电影的导演名
director = soup.find('div', class_='movie').find('p').next_sibling.string
print(director)
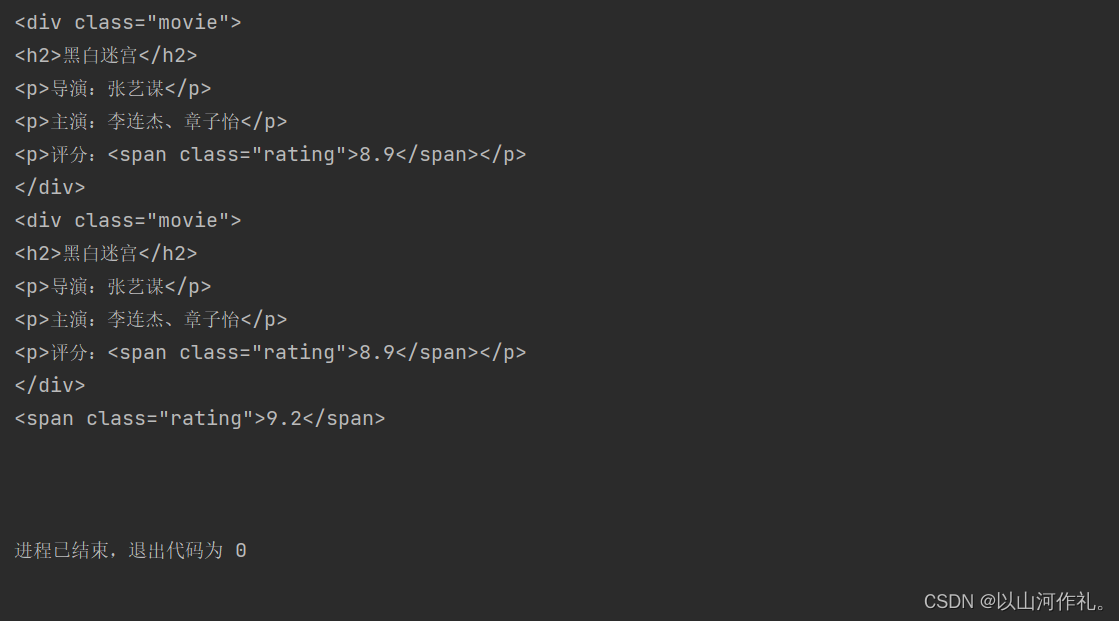
上述代码中,我们使用find()方法查找了符合条件的标签,并返回了一个Tag对象。
具体来说:
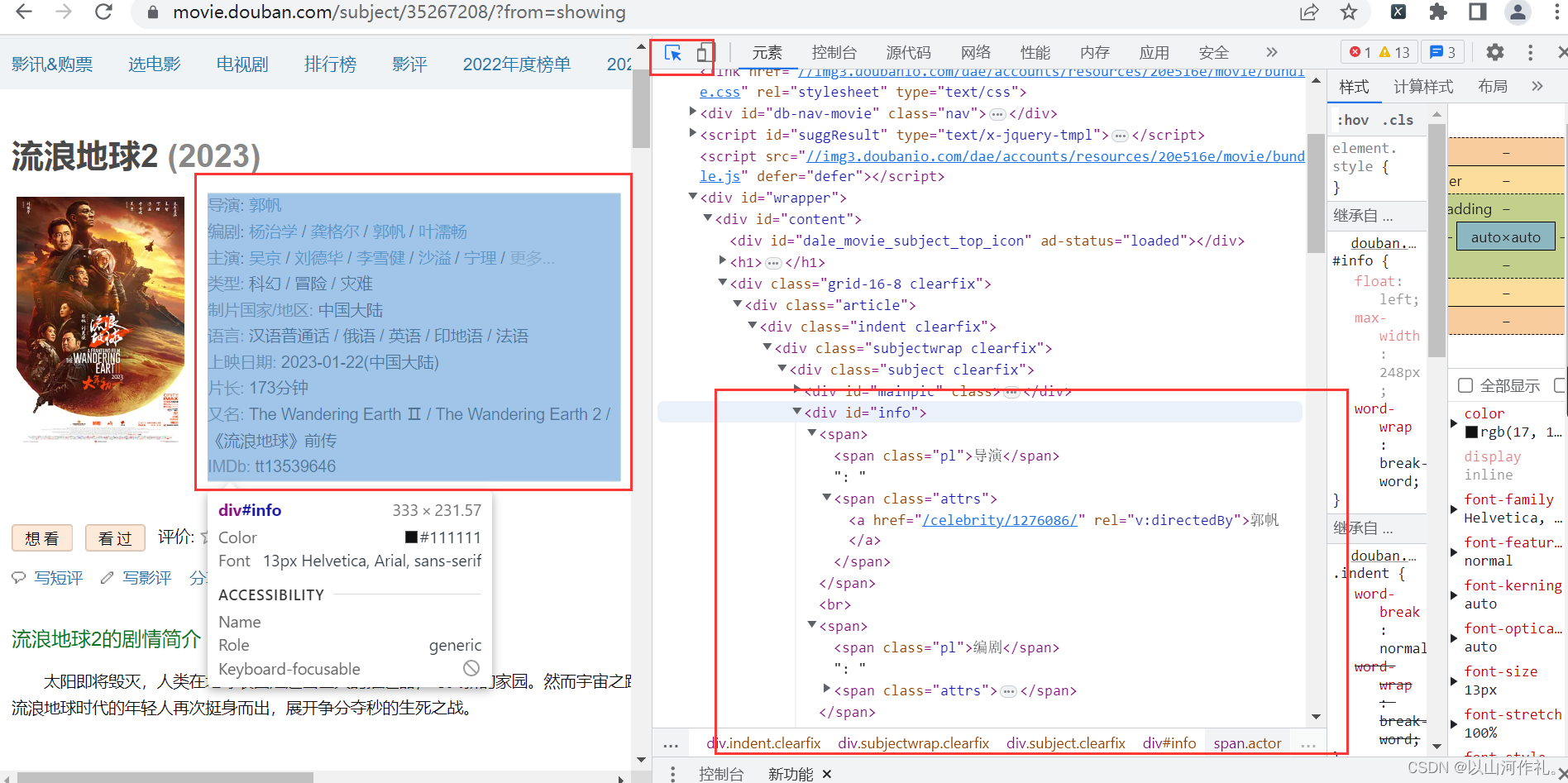
find('div')方法查找第一个div标签,并将结果存储在div变量中。find('div', class_='movie')方法查找第一个class属性值为"movie"的div标签,并将结果存储在movie变量中。find('span', class_='rating', string=lambda x: float(x) > 9.0)方法查找class属性值为"rating"且文本内容大于9.0的第一个span标签,并将结果存储在rating变量中。注意这里使用了lambda表达式作为string参数的值,表示只返回文本内容大于9.0的标签。find('div',class_='movie').find('p').next_sibling.string方法查找第一个class属性值为"movie"的div标签中第一个p标签的下一个兄弟节点的文本内容,即导演名。本次实战目的是获取方框内内容,使用学过的bs4来操作
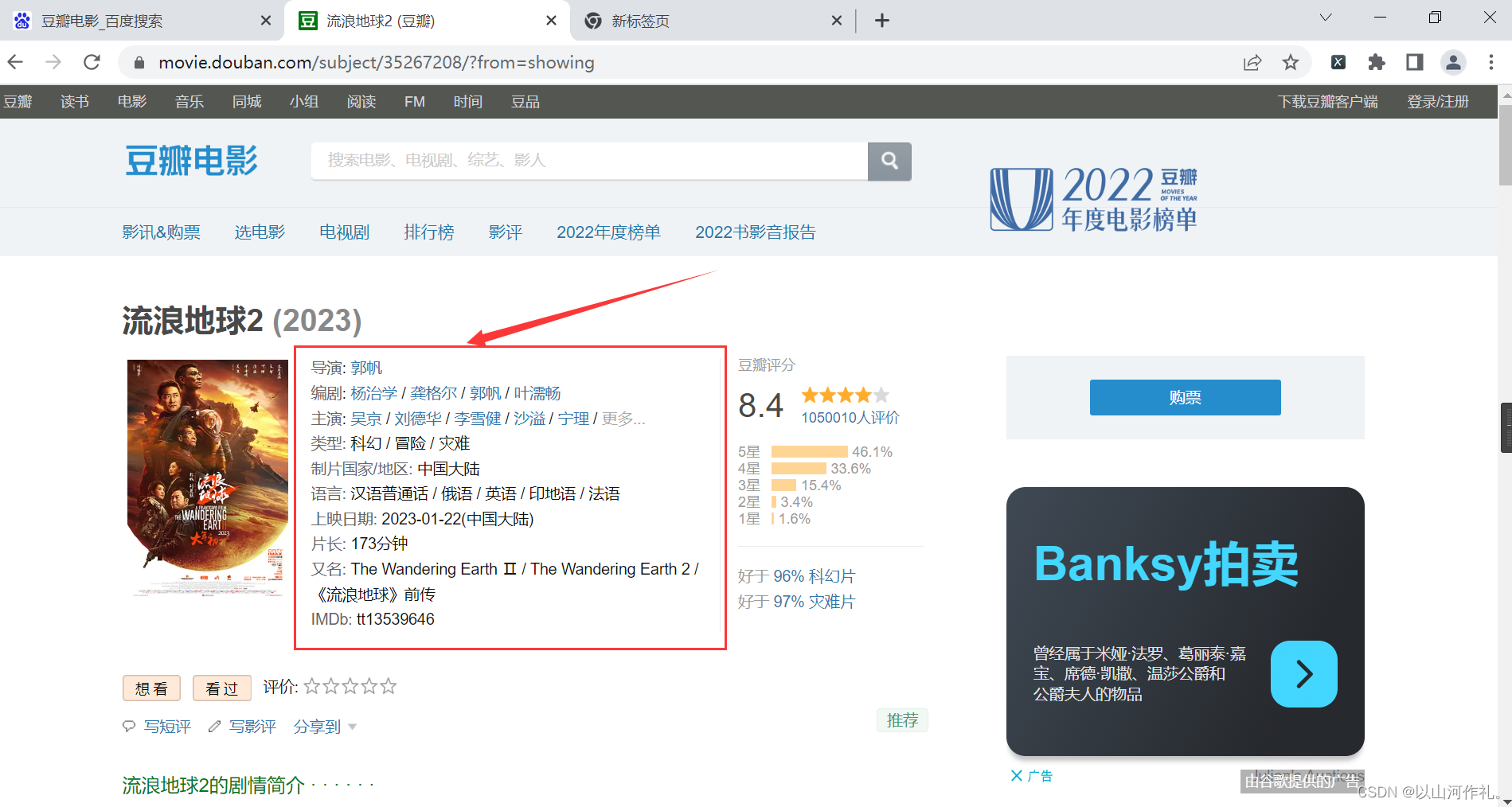
首先点击检查,鼠标附魔,查看数据是否在代码中。
通过附魔后,查看代码,发现数据在代码中,接下来我们通过get请求获取网页全部代码:
import requests
from bs4 import BeautifulSoup
url = 'https://movie.douban.com/subject/35457272/?from=showing'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
html = requests.get(url, headers=headers)
print(html.text)
接下来使用BS4来解析数据,并把它提取出来,放在txt文件夹里面。
import requests
from bs4 import BeautifulSoup
url = 'https://movie.douban.com/subject/35457272/?from=showing'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
html = requests.get(url, headers=headers)
print(html.text)
data = BeautifulSoup(html.text, 'lxml') # 第一个参数是要解析的html文本,第二个参数是使用那种解析器
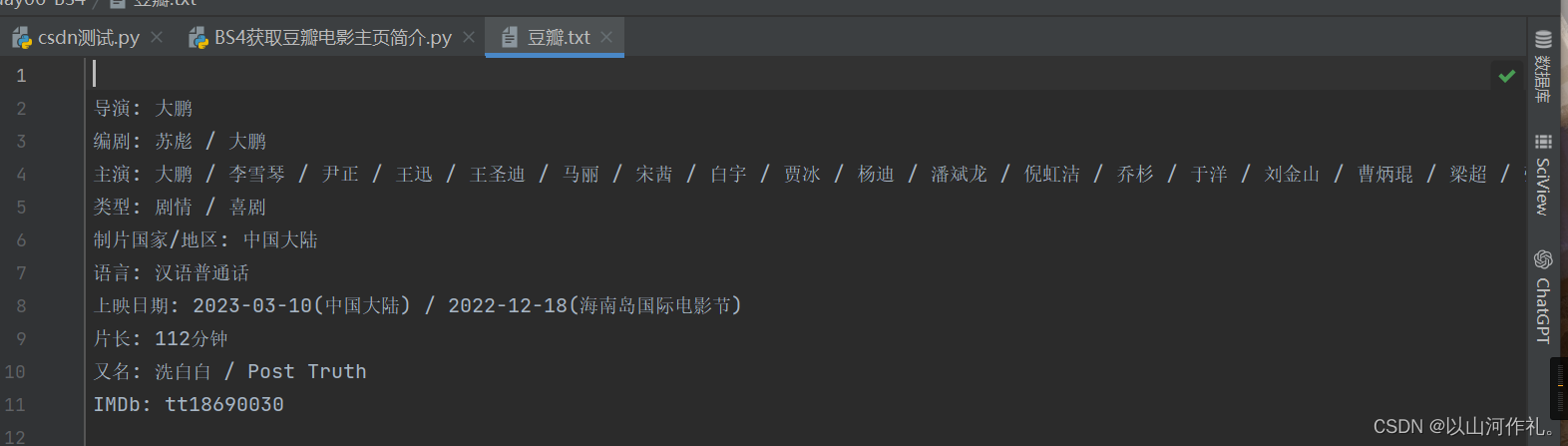
obj = data.find(id="info")
print(obj.get_text())
with open('豆瓣.txt', 'w', encoding='utf-8') as f:
f.write(obj.get_text())

任务完成!!!

🍁 🍁今日学习笔记到此结束,感谢你的阅读,如有疑问或者问题欢迎私信,我会帮忙解决,如果没有回,那我就是在教室上课,抱歉。
🍂🍂🍂🍂
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
是否可以在不实际下载文件的情况下检查文件是否存在?我有这么大的(~40mb)文件,例如:http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm这与ruby不严格相关,但如果发件人可以设置内容长度就好了。RestClient.get"http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm",headers:{"Content-Length"=>100} 最佳答案
我在这方面尝试了很多URL,在我遇到这个特定的之前,它们似乎都很好:require'rubygems'require'nokogiri'require'open-uri'doc=Nokogiri::HTML(open("http://www.moxyst.com/fashion/men-clothing/underwear.html"))putsdoc这是结果:/Users/macbookair/.rvm/rubies/ruby-2.0.0-p481/lib/ruby/2.0.0/open-uri.rb:353:in`open_http':404NotFound(OpenURI::HT
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
(本文是网络的宏观的概念铺垫)目录计算机网络背景网络发展认识"协议"网络协议初识协议分层OSI七层模型TCP/IP五层(或四层)模型报头以太网碰撞路由器IP地址和MAC地址IP地址与MAC地址总结IP地址MAC地址计算机网络背景网络发展 是最开始先有的计算机,计算机后来因为多项技术的水平升高,逐渐的计算机变的小型化、高效化。后来因为计算机其本身的计算能力比较的快速:独立模式:计算机之间相互独立。 如:有三个人,每个人做的不同的事物,但是是需要协作的完成。 而这三个人所做的事是需要进行协作的,然而刚开始因为每一台计算机之间都是互相独立的。所以前面的人处理完了就需要将数据
安全产品安全网关类防火墙Firewall防火墙防火墙主要用于边界安全防护的权限控制和安全域的划分。防火墙•信息安全的防护系统,依照特定的规则,允许或是限制传输的数据通过。防火墙是一个由软件和硬件设备组合而成,在内外网之间、专网与公网之间的界面上构成的保护屏障。下一代防火墙•下一代防火墙,NextGenerationFirewall,简称NGFirewall,是一款可以全面应对应用层威胁的高性能防火墙,提供网络层应用层一体化安全防护。生产厂家•联想网御、CheckPoint、深信服、网康、天融信、华为、H3C等防火墙部署部署于内、外网编辑额,用于权限访问控制和安全域划分。UTM统一威胁管理(Un
Linux操作系统——网络配置与SSH远程安装完VMware与系统后,需要进行网络配置。第一个目标为进行SSH连接,可以从本机到VMware进行文件传送,首先需要进行网络配置。1.下载远程软件首先需要先下载安装一款远程软件:FinalShell或者xhell7FinalShellxhell7FinalShell下载:Windows下载http://www.hostbuf.com/downloads/finalshell_install.exemacOS下载http://www.hostbuf.com/downloads/finalshell_install.pkg2.配置CentOS网络安装好
在神经网络方面,我完全是个初学者。我整天都在与ruby-fann和ai4r搏斗,不幸的是我没有任何东西可以展示,所以我想我会来到StackOverflow并询问这里的知识渊博的人。我有一组样本——每天都有一个数据点,但它们不符合我能够找出的任何明确模式(我尝试了几次回归)。不过,我认为看看是否有任何方法可以仅从日期预测future的数据会很好,而且我认为神经网络将是生成希望表达这种关系的函数的好方法.日期是DateTime对象,数据点是十进制数,例如7.68。我一直在将DateTime对象转换为float,然后除以10,000,000,000得到一个介于0和1之间的数字,我一直在将