之前项目有聚类的一些需求,现大致对一些聚类算法总结下:
聚类是对一系列事物根据其潜在特征按照某种度量函数归纳成一个个簇的动作,使得簇内数据间的相似度尽可能大,不同簇的数据相似度尽可能小。
通常聚类流程如下:数据获取-数据预处理-模型选型-模型聚类调参-输出结果。其中数据预处理、模型选型是流程中较为重要部分。数据预处理将杂乱无章的数据处理为具备某些共同点的特征,从而模型能更好地拟合数据,很经典的一句话:特征处理决定模型的上限。模型选型需要根据业务的具体需求及数据特性结合各聚类模型的特点进行选择。由于数据预处理需要根据具体数据及具体业务进行处理,本文仅介绍下各类聚类算法:
一、基于划分的聚类算法
K-means
经典K-means算法流程:
1. 随机地选择k个对象,每个对象初始地代表了一个簇的中心;
2. 对剩余的每个对象,根据其与各簇中心的距离,将它赋给最近的簇;
3. 重新计算每个簇的平均值,更新为新的簇中心;
4. 不断重复2、3,直到准则函数收敛

优点:
K-means算法简单快速;
当簇较为密集,呈现球状或团状时能有比较好的效果
缺点:
对K值敏感,聚类结果会受到K值很大的影响
对噪声点敏感,如当数据中只有2个簇,此时添加一个噪声点,则极大可能会导致噪声点分为一个簇,数据中的2个簇分为一个簇
只能聚凸的数据集
二、基于层次的聚类算法
该类主要有自下而上和自上而下两种思想。
以自下而上流程为例:
1. 将每个对象看作一类,计算两两之间的最小距离;
2. 将距离最小的两个类合并成一个新类;
3. 重新计算新类与所有类之间的距离;
4. 重复2、3,直到所有类最后合并成一类
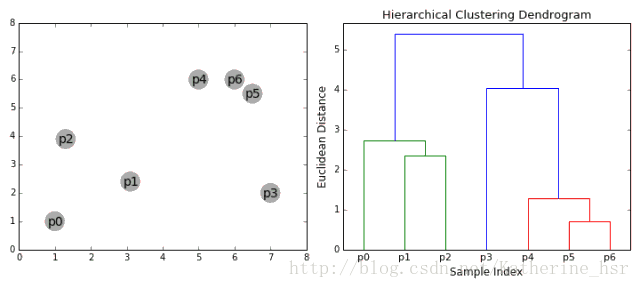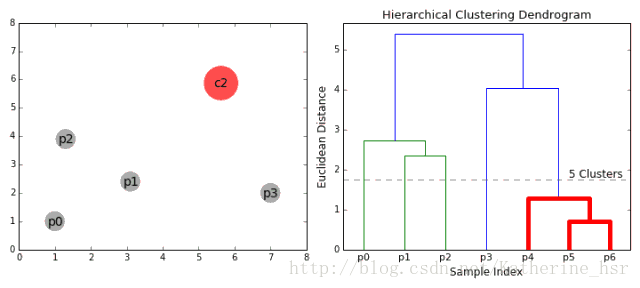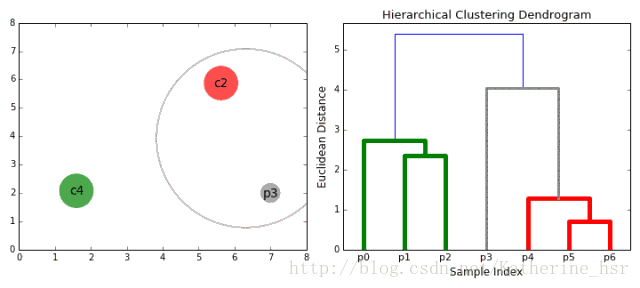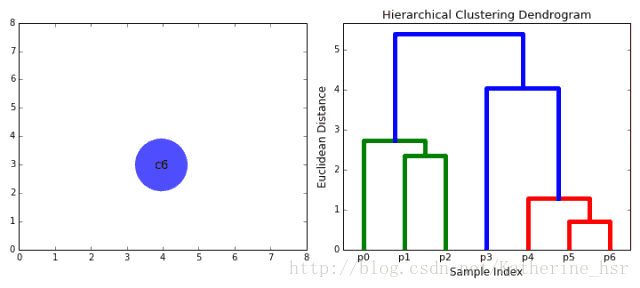
优点:
不需提前设置K值
可以发现层次关系
缺点:
计算复杂度高
奇异值有较大影响
三、基于密度的聚类算法
例如DBSCAN
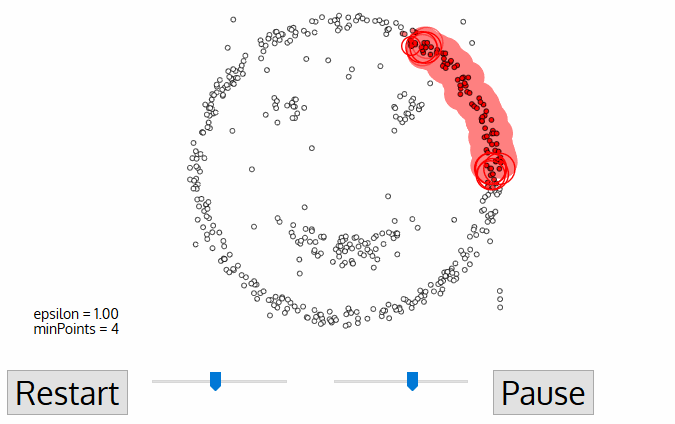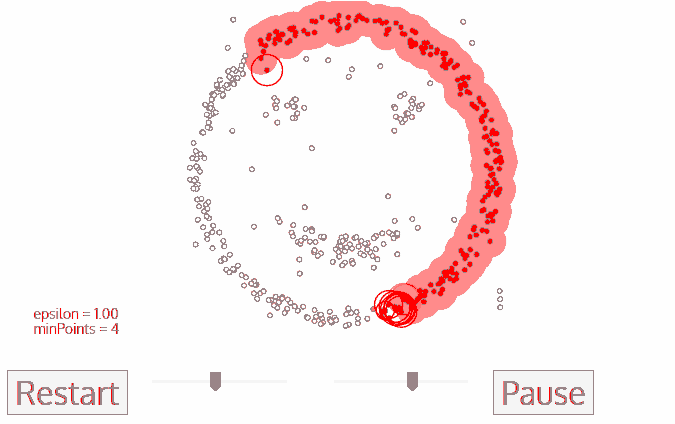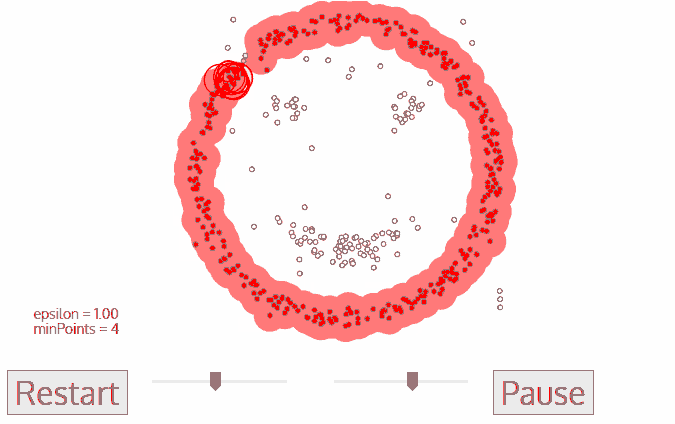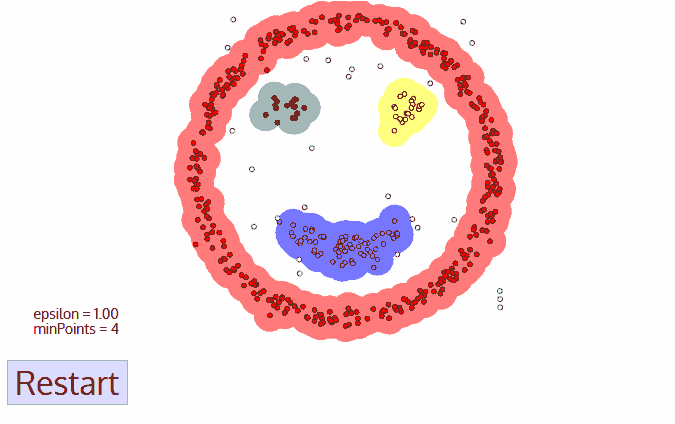
DBSCAN 算法是一种基于密度的聚类算法:
1.聚类的时候不需要预先指定簇的个数
2.最终的簇的个数不确定
DBSCAN算法将数据点分为三类:
1.核心点:在半径Eps内含有超过MinPts数目的点。
2.边界点:在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内的点。
3.噪音点:既不是核心点也不是边界点的点。
DBSCAN流程:
1.将所有点标记为核心点、边界点或噪声点;
2.删除噪声点;
3.为距离在Eps之内的所有核心点之间赋予一条边;
4.每组连通的核心点形成一个簇;
5.将每个边界点指派到一个与之关联的核心点的簇中(哪一个核心点的半径范围之内)。
优点:
自适应的聚类,不需提前设置K值
对噪声不敏感
能发现任意形状的簇
缺点:
对两个参数圈的半径、阈值敏感
数据集越大,花费时间越长
四、基于滑动窗口的聚类算法
例如均值聚类漂移
均值聚类漂移算法流程:
1.我们从一个以 C 点(随机选择)为中心,以半径 r 为核心的圆形滑动窗口开始。均值漂移是一种爬山算法,它包括在每一步中迭代地向更高密度区域移动,直到收敛。
2.在每次迭代中,滑动窗口通过将中心点移向窗口内点的均值来移向更高密度区域。滑动窗口内的密度与其内部点的数量成正比。自然地,通过向窗口内点的均值移动,它会逐渐移向点密度更高的区域。
3.我们继续按照均值移动滑动窗口直到没有方向在核内可以容纳更多的点。
4.步骤 1 到 3 的过程是通过许多滑动窗口完成的,直到所有的点位于一个窗口内。当多个滑动窗口重叠时,保留包含最多点的窗口。然后根据数据点所在的滑动窗口进行聚类

优点:
不需提前设置K值
可以处理任意形状的簇类
缺点:
窗口半径有可能是不重要的
对于较大的特征空间,计算量较大
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
我想使用部分字符串搜索数组,然后获取找到该字符串的索引。例如:a=["Thisisline1","Wehaveline2here","andfinallyline3","potato"]a.index("potato")#thisreturns3a.index("Wehave")#thisreturnsnil使用a.grep将返回完整的字符串,使用a.any?将返回正确的true/false语句,但都不会返回匹配的索引找到了,或者至少我不知道该怎么做。我正在编写一段代码,该代码读取文件、查找特定header,然后返回该header的索引,以便它可以将其用作future搜索的偏移量。如果
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
一、机器人介绍 此处是基于MATLABRVC工具箱,对ABB-IRB-1200型号的微型机械臂进行正逆向运动学分析,并利Simulink工具实现对机械臂进行具有动力学参数的末端轨迹规划仿真,最后根据机械模型设计Simulink-Adams联合仿真。 图1.ABBIRB 1200尺寸参数示意图ABBIRB 1200提供的两种型号广泛适用于各作业,且两者间零部件通用,两种型号的工作范围分别为700 mm 和 900 mm,大有效负载分别为 7 kg 和5 kg。 IRB 1200 能够在狭小空间内能发挥其工作范围与性能优势,具有全新的设计、小型化的体积、高效的性能、易于集成、便捷的接
目录一.大致如下常见问题:(1)找不到程序所依赖的Qt库version`Qt_5'notfound(requiredby(2)CouldnotLoadtheQtplatformplugin"xcb"in""eventhoughitwasfound(3)打包到在不同的linux系统下,或者打包到高版本的相同系统下,运行程序时,直接提示段错误即segmentationfault,或者Illegalinstruction(coredumped)非法指令(4)ldd应用程序或者库,查看运行所依赖的库时,直接报段错误二.问题逐个分析,得出解决方法:(1)找不到程序所依赖的Qt库version`Qt_5'
K伙计们,所以我创建了这个赞成/反对的投票脚本(基本上就像stackoverflow上的那个),我试图向其中添加一些Ajax,这样页面就不会在您每次投票时都重新加载。我有两个Controller,一个叫grinder,一个叫votes。(磨床基本都是帖子)所以这是所有研磨机的索引(看起来像这样)这是该页面的代码。Listinggrinders"grinders/grinders")%>这就是我在views/grinders/_grinders.erb中的内容true)do|u|%>grinder.id%>"up"%>'create')%>true)do|d|%>grinder.id%>
我一直在尝试用Ruby实现Luhn算法。我一直在执行以下步骤:该公式根据其包含的校验位验证数字,该校验位通常附加到部分帐号以生成完整帐号。此帐号必须通过以下测试:从最右边的校验位开始向左移动,每第二个数字的值加倍。将乘积的数字(例如,10=1+0=1、14=1+4=5)与原始数字的未加倍数字相加。如果总模10等于0(如果总和以零结尾),则根据Luhn公式该数字有效;否则无效。http://en.wikipedia.org/wiki/Luhn_algorithm这是我想出的:defvalidCreditCard(cardNumber)sum=0nums=cardNumber.to_s.s