来公司之后很长一段时间都在优化改造审核系统,现在审核系统稳定了,而且也可以快速接需求了。这时候被借到学院这边来做一些优化改造,其中视频分布式上传这个功能存在很多问题,急需改造处理
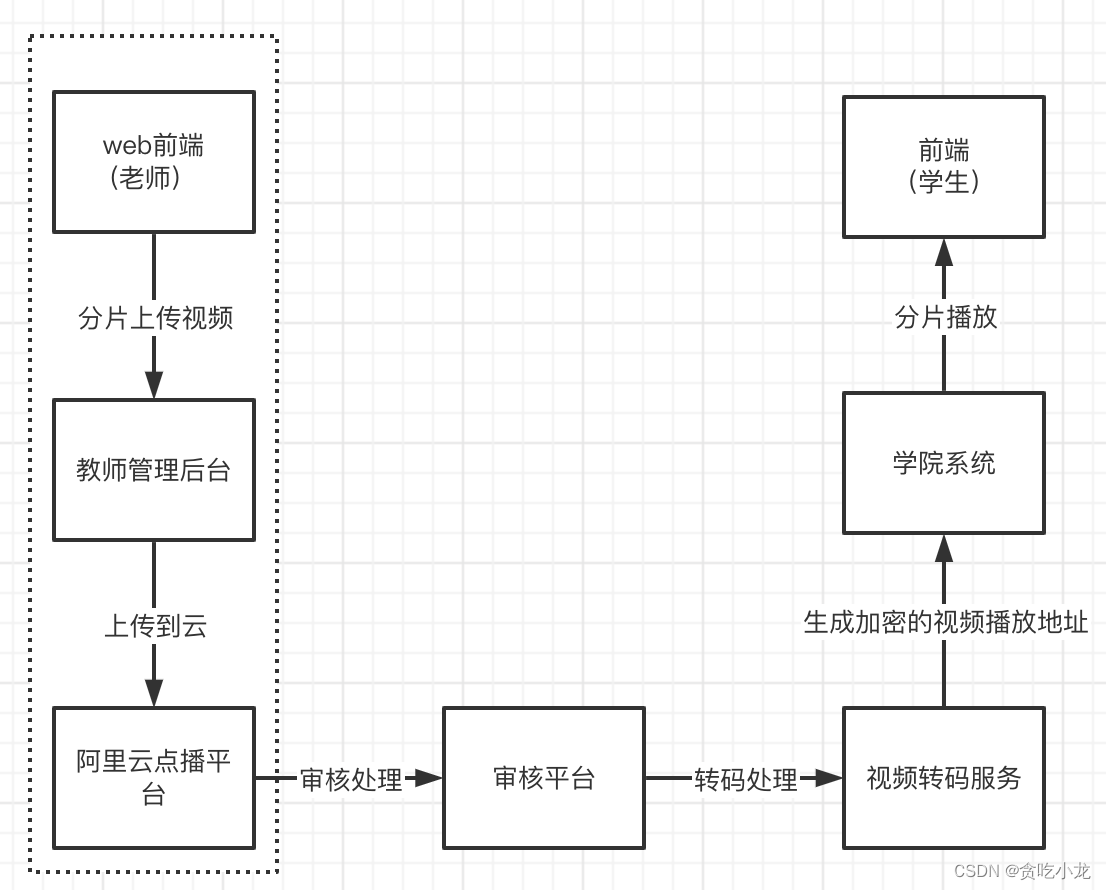
学院这边上传视频的大致步骤如下
因此上传视频的功能是非常重要的一环,它的服务对象是老师,在未改造之前的上传功能存在如下问题:
1. 由于历史原因,老的上传功能是 php 实现的、而现有的团队都是 java 程序员,这就导致出现问题无法进行维护
2. 老师上传的文件会出现花屏、丢帧等一些质量问题, 导致学院学生观看视频的时候客诉率很高
3. 老师上传的文件的原文件播放时长与学生看到播放时长存在不一致情况
4. 老师在管理后台上传的视频是成功状态,但是后端实际存储的状态是未上传成功的状态
5. 老师上传视频完成之后无法覆盖之前的视频
所以改造视频上传这块的功能就成了一个迫在眉睫的一个事情
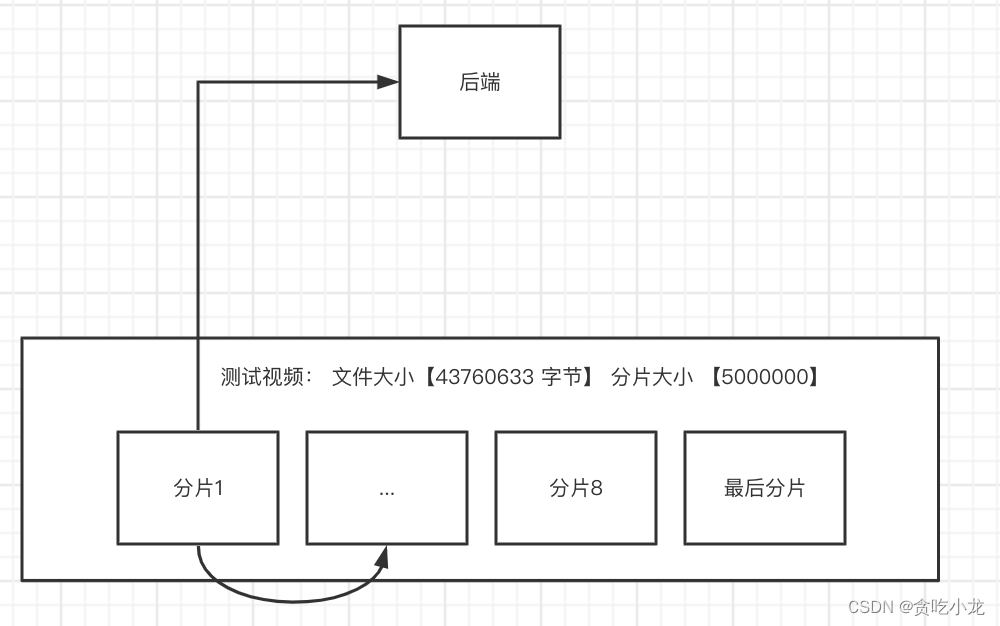
注: 这里的前端有个重要的约束条件,就是分片上传是一块一块上传的,且有先后顺序
// 视频文件上传
// 视频标题(必选)
String title = "测试标题";
// 1.本地文件上传和文件流上传时,文件名称为上传文件绝对路径,如:/User/sample/文件名称.mp4 (必选)
// 2.网络流上传时,文件名称为源文件名,如文件名称.mp4(必选)。
// 3.流式上传时,文件名称为源文件名,如文件名称.mp4(必选)。
// 任何上传方式文件名必须包含扩展名
String fileName = "/Users/test/video/test.mp4";
// 本地文件上传
testUploadVideo(accessKeyId, accessKeySecret, title, fileName);
// 待上传视频的网络流地址
String url = "http://test.aliyun.com/video/test.mp4";
// 2.网络流上传
// 文件扩展名,当url中不包含扩展名时,需要设置该参数
String fileExtension = "mp4";
testUploadURLStream(accessKeyId, accessKeySecret, title, url, fileExtension);
// 3.文件流上传
testUploadFileStream(accessKeyId, accessKeySecret, title, fileName);
// 4.流式上传,如文件流和网络流
InputStream inputStream = null;
// 4.1 文件流
try {
inputStream = new FileInputStream(fileName);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
// 4.2 网络流
try {
inputStream = new URL(url).openStream();
} catch (IOException e) {
e.printStackTrace();
}
testUploadStream(accessKeyId, accessKeySecret, title, fileName, inputStream);
阿里云提供的 sdk 必需满足一个条件,就是上传的文件或者视频它是本地完整的文件或者流
这里是sdk使用方法:https://help.aliyun.com/document_detail/53406.html
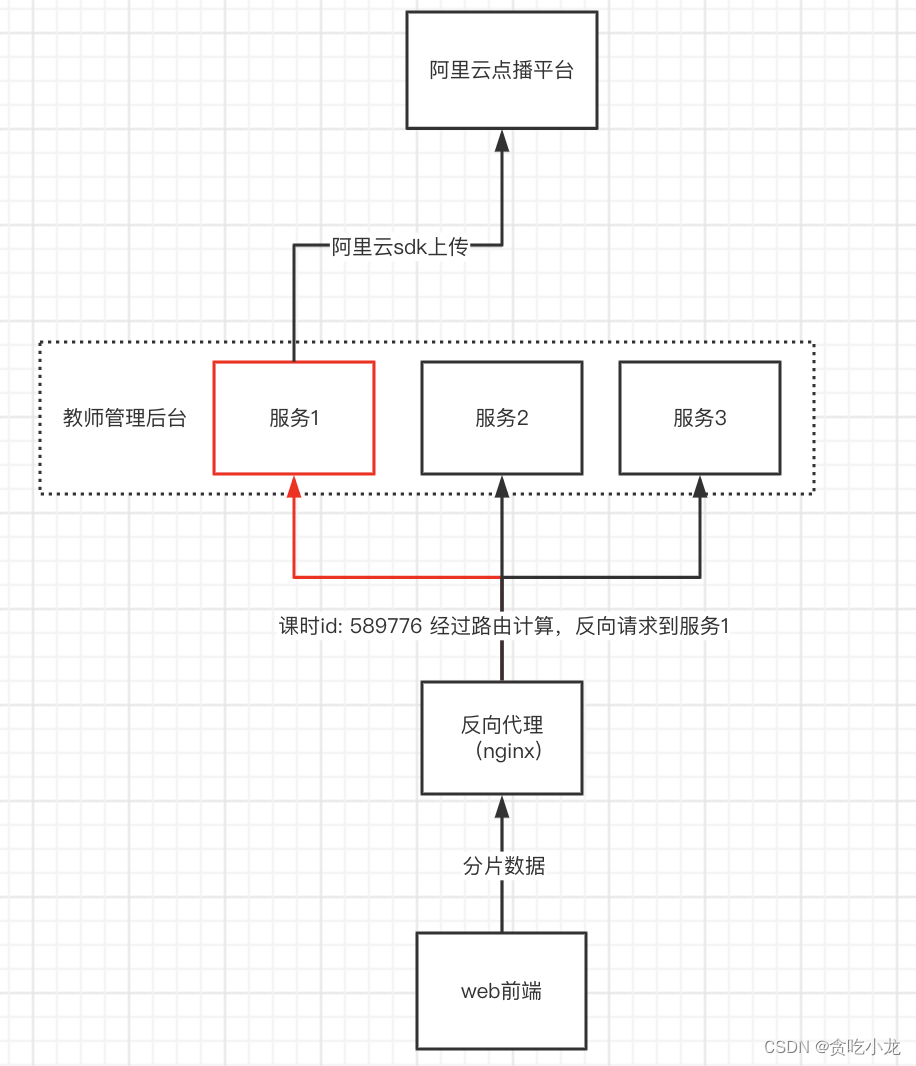
举个例子:
1. 需要额外的反向代理服务配置
2. 无法进行动态扩容缩容,尤其不适用容器的部署方式
3. 每台服务器都需要分配足够的磁盘空间大小,需要更多的磁盘资源
4. 很容器出现服务器倾斜的问题
5. 业务处理服务与上传存储服务耦合
1. 业务处理需要把上传文件的中间态保存下来
2. 业务端上传成功,实际并未真正上传成功
6. 需要保留很多文件中间状态,代码实现很繁杂
7. 上传失败之后无法提前告知用户
因为方案 1缺点太多了, 我们就自然而然想到下面的方案二,它能解决方案 一中的大部分问题
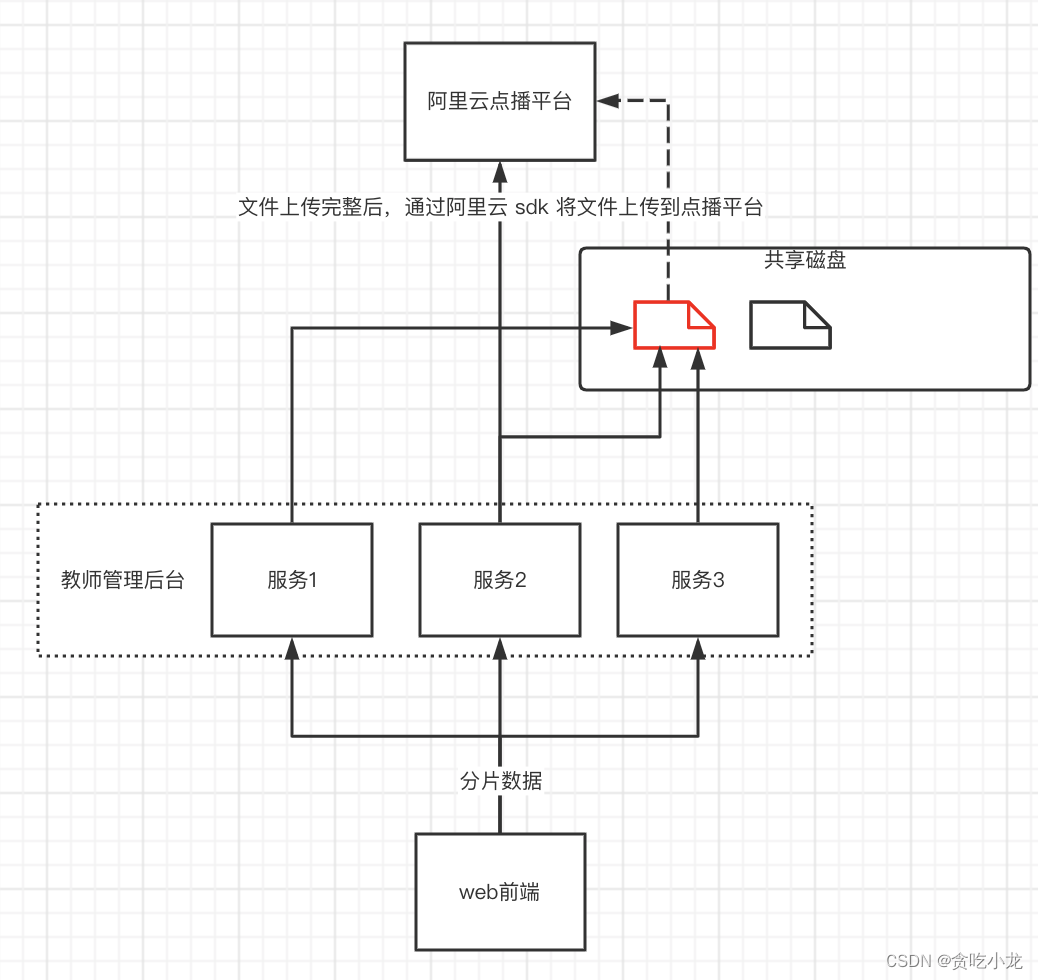
方案二的实现方式,比较简单,就是每个服务挂载一个共享磁盘,所有上传的分片文件都存储到这个共享磁盘当中,当所有分片上传完成之后,组合共享文件磁盘当中的分片为一个完整的文件,再上传到阿里云的点播平台
方案二解决了方案一中 1、2、3、4 点的问题
1. 需要配置额外的共享磁盘
2. 无论业务方分片上传,还是将文件发送到点播云,都需要经过从共享磁盘到业务服务器之间的网络传输,上传性能更差,更多的io意味着更多的不稳定性
3. 业务处理服务与上传存储服务耦合
1. 业务处理需要把上传文件的中间态保存下来
2. 业务端上传成功,实际并未真正上传成功
4. 也需要保留很多文件的中间状态,代码实现也会相对复杂
5. 上传失败之后无法提前告知用户
但是方案二依然存在方案1中的第5,6,7点的问题
于是我们就想到了下面的方案三,方案三的话就是我们实现一个代理的点播平台,这个代理的点播平台无论是我们后面实现自己的点播平台,还是采购阿里云的点播平台或者百度的,对于我们业务方来说,无需关心,代理的点播平台支持接收分片数据,同时由业务方来告诉代理点播平台哪些分片数据是一个完整的文件,代理点播平台收到组装文件请求之后,完成后续一些列的操作处理
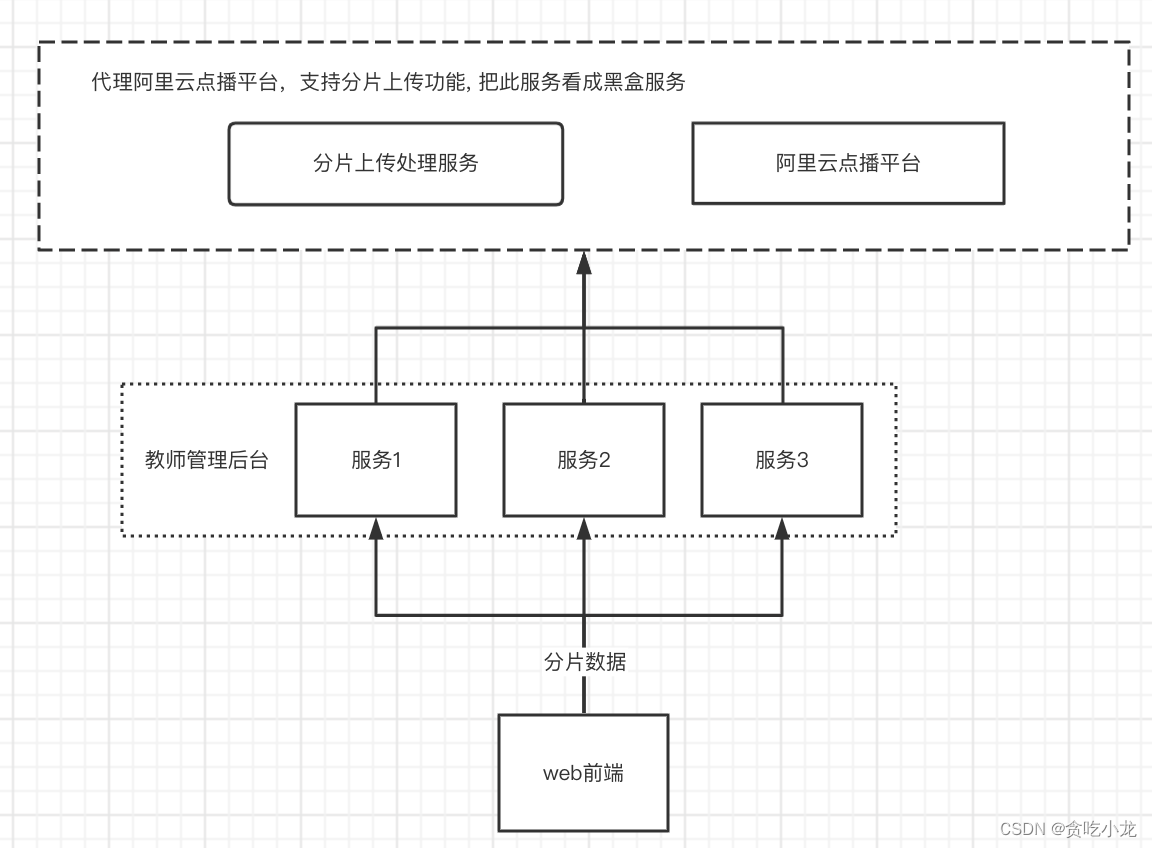
注意:
1. 解决了方案1,2中的所有问题
2. 扩展性非常好,后期切换到其他云点播服务平台会很简单
3. 业务方无需再关系上传等问题,由代理点播平台来进行保障处理,业务方只需要进行分片转发即可,业务方代码会非常简单
有了方案三之后,我们找到了一条明确的道路,也就说尽可能让业务方实现分片上传简单,最好就是业务方只做分片转发处理,通知合并分片文件即可,于是就想到了方案四
有了方案3之后,就会想到为啥要自己实现一个代理的点播服务了,如果说阿里云点播平台自身支持按分片上传,那是不是可以改造和扩展 api,来实现分布式分片上传
通过查看其官方的sdk 例子,发现两个重点的配置参数
private static void testUploadVideo(String accessKeyId, String accessKeySecret, String title, String fileName) {
UploadVideoRequest request = new UploadVideoRequest(accessKeyId, accessKeySecret, title, fileName);
/* 重点:可指定分片上传时每个分片的大小,默认为2M字节 */
request.setPartSize(2 * 1024 * 1024L);
/* 重点:可指定分片上传时的并发线程数,默认为1,(注:该配置会占用服务器CPU资源,需根据服务器情况指定)*/
request.setTaskNum(1); //
UploadVideoImpl uploader = new UploadVideoImpl();
UploadVideoResponse response = uploader.uploadVideo(request);
System.out.print("RequestId=" + response.getRequestId() + "\n"); //请求视频点播服务的请求ID
if (response.isSuccess()) {
System.out.print("VideoId=" + response.getVideoId() + "\n");
}
...
}
重点参数:
partSize: 分片大小,这不就是前端分片后的分片大小
taskNum: 一个线程其实可以想象为一个后台服务
那我们可以来分析下阿里云的分片上传 sdk 是如何做的,这样就可以对它进行一些扩展了
下面阿里云分片上传的一个简化流程,这里忽略了一些 checkpoint 等的一些处理,主要关注主流程
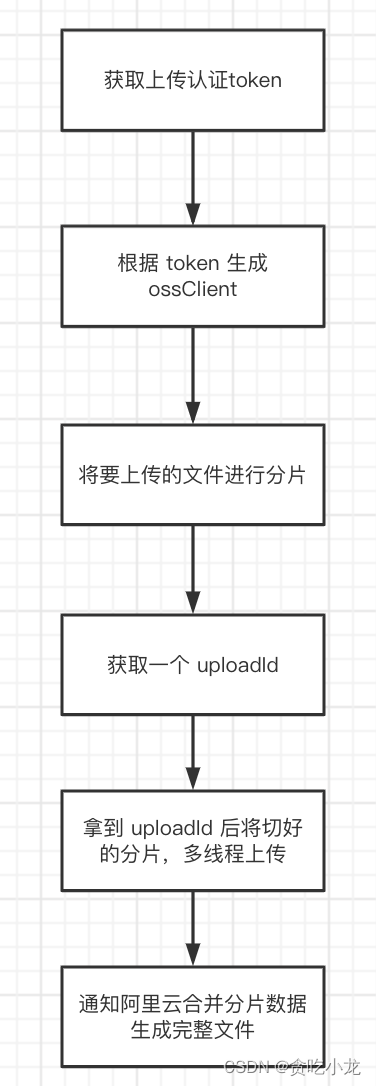
下面是分析源代码的过程
try {
DefaultAcsClient vodClient = this.initVodClient(request.getApiRegionId(), request.getAccessKeyId(), request.getAccessKeySecret(), request.getSecurityToken());
createUploadVideoResponse = (CreateUploadVideoResponse)vodClient.getAcsResponse(createUploadVideoRequest);
} catch (ClientException var14) {
response.setCode(var14.getErrCode());
response.setMessage(var14.getErrMsg());
response.setRequestId(createUploadVideoResponse.getRequestId());
return;
}
首先通过 ak, sk 等阿里云配置信息,获取到上传文件时会用到的 token 信息
ossClient = this.initOSSClient(uploadTokenDTO.getEndpoint(), uploadTokenDTO.getAccessKeyId(), uploadTokenDTO.getAccessKeySecret(), uploadTokenDTO.getSecurityToken(), request.getCrcCheckEnabled(), request.getOssConfig());
private ArrayList<OSSUploadOperation.UploadPart> splitFile(long fileSize, long partSize) {
ArrayList<OSSUploadOperation.UploadPart> parts = new ArrayList();
long partNum = fileSize / partSize;
if (partNum >= 10000L) {
partSize = fileSize / 9999L;
partNum = fileSize / partSize;
}
for(long i = 0L; i < partNum; ++i) {
OSSUploadOperation.UploadPart part = new OSSUploadOperation.UploadPart();
part.number = (int)(i + 1L);
part.offset = i * partSize;
part.size = partSize;
part.isCompleted = false;
parts.add(part);
}
if (fileSize % partSize > 0L) {
OSSUploadOperation.UploadPart part = new OSSUploadOperation.UploadPart();
part.number = parts.size() + 1;
part.offset = (long)parts.size() * partSize;
part.size = fileSize % partSize;
part.isCompleted = false;
parts.add(part);
}
return parts;
}
InitiateMultipartUploadRequest initiateUploadRequest = new InitiateMultipartUploadRequest(uploadFileRequest.getBucketName(), uploadFileRequest.getKey(), metadata);
InitiateMultipartUploadResult initiateUploadResult = this.multipartOperation.initiateMultipartUpload(initiateUploadRequest);
private ArrayList<OSSUploadOperation.PartResult> upload(OSSUploadOperation.UploadCheckPoint uploadCheckPoint, VoDUploadFileRequest uploadFileRequest) throws Throwable {
ArrayList<OSSUploadOperation.PartResult> taskResults = new ArrayList();
ExecutorService service = Executors.newFixedThreadPool(uploadFileRequest.getTaskNum());
ArrayList<Future<OSSUploadOperation.PartResult>> futures = new ArrayList();
ProgressListener listener = uploadFileRequest.getProgressListener();
long contentLength = 0L;
int i;
for(i = 0; i < uploadCheckPoint.uploadParts.size(); ++i) {
if (!((OSSUploadOperation.UploadPart)uploadCheckPoint.uploadParts.get(i)).isCompleted) {
contentLength += ((OSSUploadOperation.UploadPart)uploadCheckPoint.uploadParts.get(i)).size;
}
}
...
for(i = 0; i < uploadCheckPoint.uploadParts.size(); ++i) {
if (!((OSSUploadOperation.UploadPart)uploadCheckPoint.uploadParts.get(i)).isCompleted) {
futures.add(service.submit(new OSSUploadOperation.Task(i, "upload-" + i, uploadCheckPoint, i, uploadFileRequest, this.multipartOperation, listener)));
...
taskResults.add(new OSSUploadOperation.PartResult(i + 1, ((OSSUploadOperation.UploadPart)uploadCheckPoint.uploadParts.get(i)).offset, ((OSSUploadOperation.UploadPart)uploadCheckPoint.uploadParts.get(i)).size));
}
}
...
return taskResults;
}
}
有了前面建立 ossClient 连接以及 uploadId, 就可以上传分片数据了, 由于每个分片有分片编号,因此可以用多线程的方式进行分片上传,加快上传速度
private CompleteMultipartUploadResult complete(OSSUploadOperation.UploadCheckPoint uploadCheckPoint, UploadFileRequest uploadFileRequest) {
Collections.sort(uploadCheckPoint.partETags, new Comparator<PartETag>() {
public int compare(PartETag p1, PartETag p2) {
return p1.getPartNumber() - p2.getPartNumber();
}
});
CompleteMultipartUploadRequest completeUploadRequest = new CompleteMultipartUploadRequest(uploadFileRequest.getBucketName(), uploadFileRequest.getKey(), uploadCheckPoint.uploadID, uploadCheckPoint.partETags);
...
return this.multipartOperation.completeMultipartUpload(completeUploadRequest);
}
有了前面分析阿里云分片上传的流程,我们就可以有下面的方案四
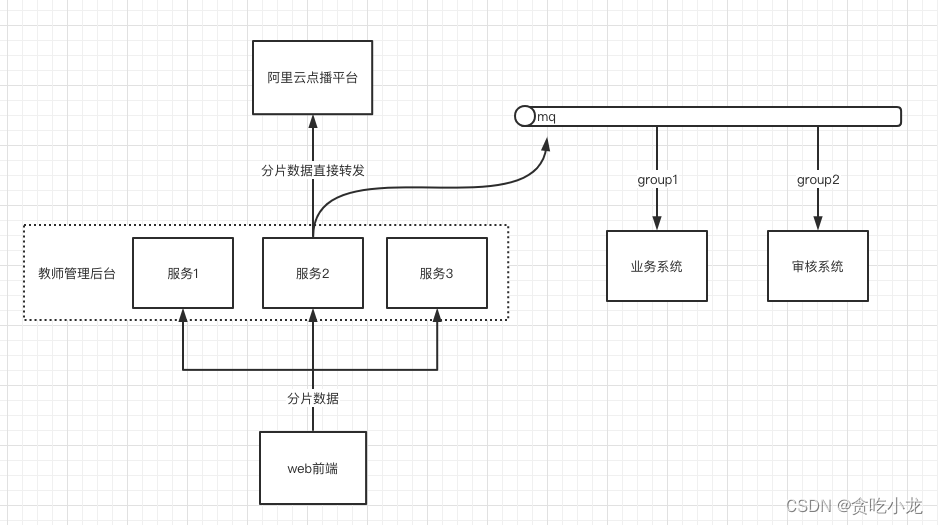
教师管理后端,将分片数据通过扩展的 sdk 转发到阿里云点播平台, 最后所有分片上传完成之后,告诉阿里云点播平台进行分片合并处理,分片合并完成将上传成功的消息通过 mq 发送出去
然后经过不同的消费组去做不同的处理,比如业务方需要根据上传的信息去设置上传 video id, 生成转码,加密播放链接等,而审核系统负责将上传的视频数据推送给审核人员进行审核处理
由于之前在分析阿里云 sdk 时,发现阿里云都是在本地处理,但是我们的服务是多个的,这时候需要考虑到上传的性能问题,比如 ossClient 已经创建成功,那么一个服务的同一个视频的不同分片就不需要再进行重复建立 oss 链接了,我们可以把建立的链接缓存起来,其他的 uploadId, token 等信息,可以供多个服务共享,因此可以把它们缓存到 redis 中
下面是整个分片上传的过程图
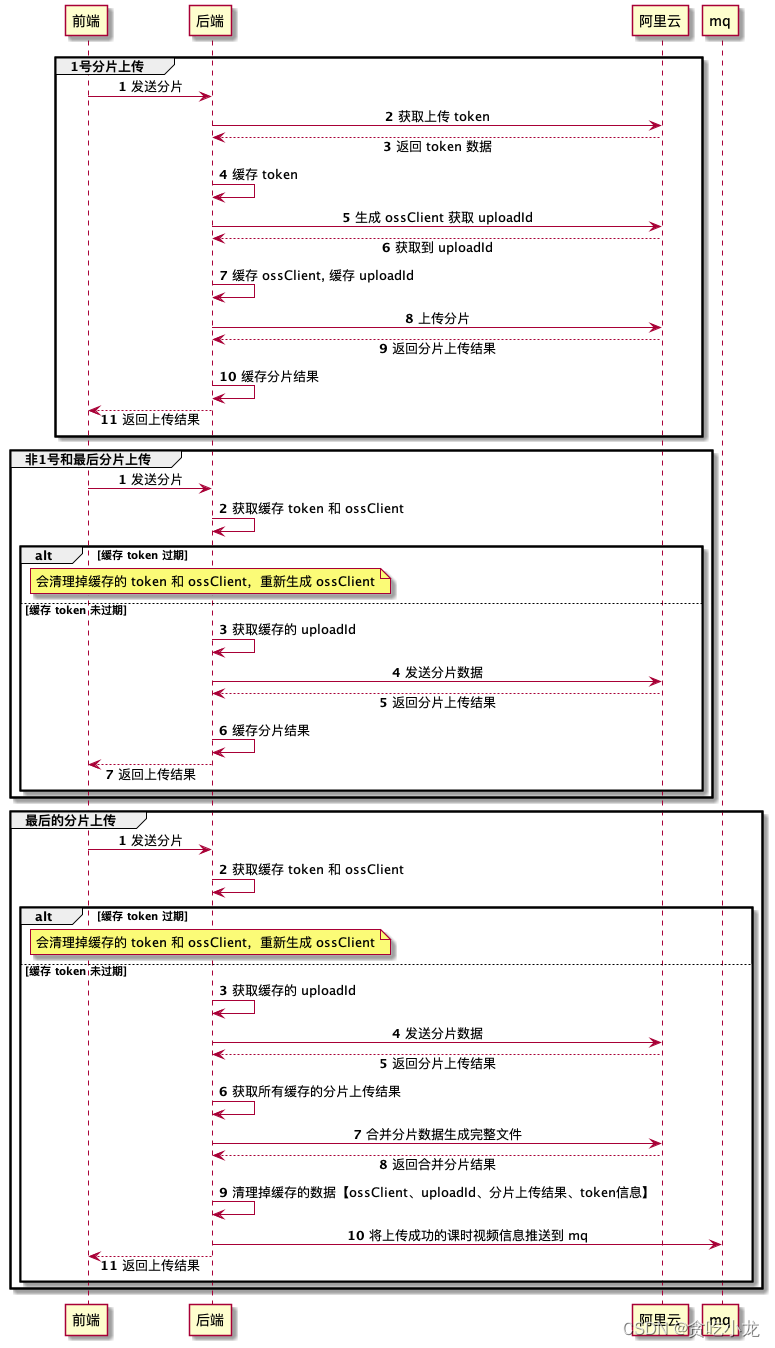
需要注意的点
方案4的缺点:
优点:
经过四个方案的对比,最终实现的方案采用方案四
总结:
需要看源代码的同志可以在评论里留言!!!
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我有带有Logo图像的公司模型has_attached_file:logo我用他们的Logo创建了许多公司。现在,我需要添加新样式has_attached_file:logo,:styles=>{:small=>"30x15>",:medium=>"155x85>"}我是否应该重新上传所有旧数据以重新生成新样式?我不这么认为……或者有什么rake任务可以重新生成样式吗? 最佳答案 参见Thumbnail-Generation.如果rake任务不适合你,你应该能够在控制台中使用一个片段来调用重新处理!关于相关公司
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
我在Rails应用程序中使用CarrierWave/Fog将视频上传到AmazonS3。有没有办法判断上传的进度,让我可以显示上传进度如何? 最佳答案 CarrierWave和Fog本身没有这种功能;你需要一个前端uploader来显示进度。当我不得不解决这个问题时,我使用了jQueryfileupload因为我的堆栈中已经有jQuery。甚至还有apostonCarrierWaveintegration因此您只需按照那里的说明操作即可获得适用于您的应用的进度条。 关于ruby-on-r
文章目录1.开发板选择*用到的资源2.串口通信(个人理解)3.代码分析(注释比较详细)1.主函数2.串口1配置3.串口2配置以及中断函数4.注意问题5.源码链接1.开发板选择我用的是STM32F103RCT6的板子,不过代码大概在F103系列的板子上都可以运行,我试过在野火103的霸道板上也可以,主要看一下串口对应的引脚一不一样就行了,不一样的就更改一下。*用到的资源keil5软件这里用到了两个串口资源,采集数据一个,串口通信一个,板子对应引脚如下:串口1,TX:PA9,RX:PA10串口2,TX:PA2,RX:PA32.串口通信(个人理解)我就从串口采集传感器数据这个过程说一下我自己的理解,
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
默认情况下:回形针gem将所有附件存储在公共(public)目录中。出于安全原因,我不想将附件存储在公共(public)目录中,所以我将它们保存在应用程序根目录的uploads目录中:classPost我没有指定url选项,因为我不希望每个图像附件都有一个url。如果指定了url:那么拥有该url的任何人都可以访问该图像。这是不安全的。在user#show页面中:我想实际显示图像。如果我使用所有回形针默认设置,那么我可以这样做,因为图像将在公共(public)目录中并且图像将具有一个url:Someimage:看来,如果我将图像附件保存在公共(public)目录之外并且不指定url(同