一、选题的背景
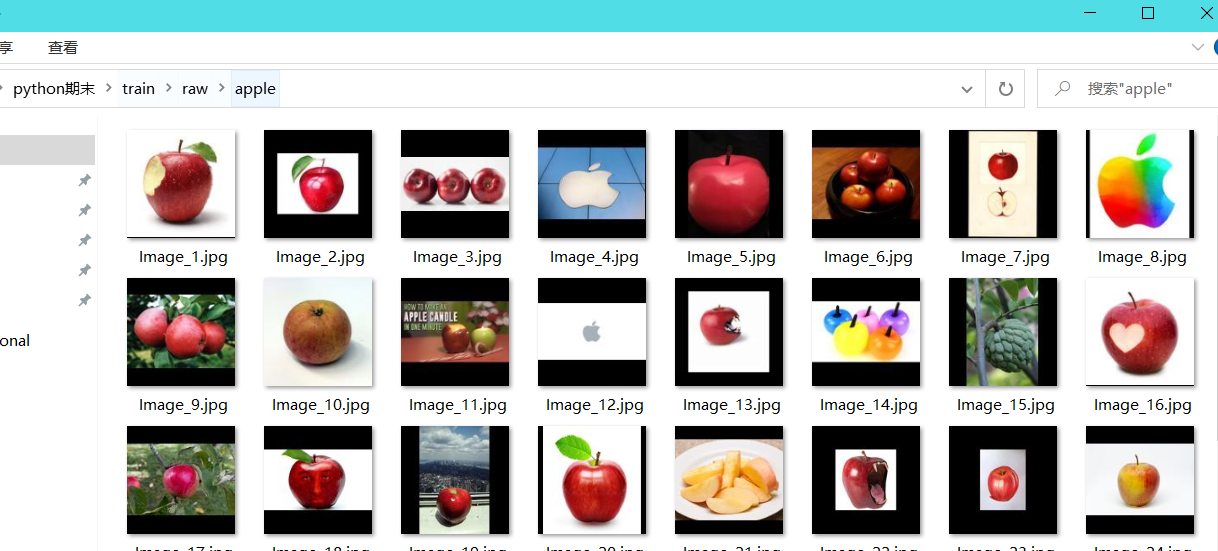
为了实现对水果和蔬菜的分类识别,收集了香蕉、苹果、梨、葡萄、橙子、猕猴桃、西瓜、石榴、菠萝、芒果、黄瓜、胡萝卜、辣椒、洋葱、马铃薯、柠檬、番茄、萝卜、甜菜根、卷心菜、生菜、菠菜、大豆、花椰菜、甜椒、辣椒、萝卜、玉米、甜玉米、红薯、辣椒粉、生姜、大蒜、豌豆、茄子共36种果蔬的图像。该项目使用resnet18网络进行分类。
二、机器学习案例设计方案
1.本选题采用的机器学习案例(训练集与测试集)的来源描述
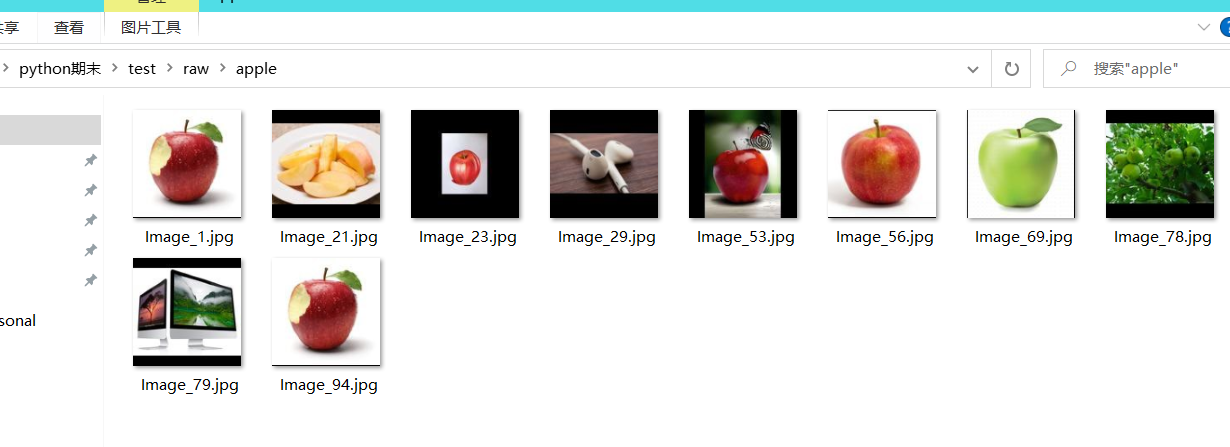
数据集来自百度AI studio平台(https://aistudio.baidu.com/aistudio/datasetdetail/119023/0),共包含36种果蔬,每一个类别包括100张训练图像,10张测试图像和10张验证图像。
2 采用的机器学习框架描述
本次使用的网络框架,主要用到了二维卷积、激活函数、最大池化、Dropout和全连接,下面将对搭建的网络模型进行解释。
首先是一个二维卷积层,输入通道数为3,输出通道数为100,卷积核大小是3*3,填充大小是1*1。输入通道数为3是因为这个是第一层卷积,输入的是RGB图像,具有三个通道,输出通道数量可以根据实际情况自定。填充是因为希望在卷积后,不要改变图像的尺寸。
在卷积层之后是一个RELU激活函数,如果不用激活函数,在这种情况下每一层输出都是上层输入的线性函数。容易验证,无论神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当。因此引入非线性函数作为激活函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入。
然后再跟一个二维卷积层,输入通道数应该和上一层卷积的输出通道数相同,所以设为100, 输出通道数同样根据实际情况设定,此处设为150,其他参数与第一层卷积相同。
后续每一个卷积层和全连接层后面都会跟一个RELU激活函数,所以后面不再叙述RELU激活函数层。
再之后添加一个2*2的最大池化层,该层用来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性。
再经过三次卷积后,使用Flatten将二维Tensor拉平,变为一维Tensor,然后使用全连接层,通过多个全连接层后,使用dropout层随机删除一些结点,该方法可以有效的避免网络过拟合,在最后一个全连接层的输出对应需要分类的个数。
3.涉及到的技术难点与解决思路
下载的数据集没有划分训练集、测试集和验证集,需要自己写代码完成划分。在刚开始写代码的时候对于文件路径没有搞清楚,导致总是读取不到图像,并且代码还没有报错误正常运行结束,但是查看划分后的文件夹里没有数据。通过debug发现文件的路径出现问题,具体是windows下的/和\混用,导致不能正确的对路径进行处理。在排除问题后统一使用\\,最终问题得到解决。
三、机器学习的实现步骤
(1)划分数据集并进行缩放
1 import os
2 import glob
3 import random
4 import shutil
5 from PIL import Image
6 #对所有图片进行RGB转化,并且统一调整到一致大小,但不让图片发生变形或扭曲,划分了训练集和测试集
7
8 if __name__ == '__main__':
9 test_split_ratio = 0.05 #百分之五的比例作为测试集
10 desired_size = 128 # 图片缩放后的统一大小
11 raw_path = './raw'
12
13 #把多少个类别算出来,包括目录也包括文件
14 dirs = glob.glob(os.path.join(raw_path, '*'))
15 #进行过滤,只保留目录,一共36个类别
16 dirs = [d for d in dirs if os.path.isdir(d)]
17
18 print(f'Totally {len(dirs)} classes: {dirs}')
19
20 for path in dirs:
21 # 对每个类别单独处理
22
23 #只保留类别名称
24 path = path.split('/')[-1]
25 print(path)
26 #创建文件夹
27 os.makedirs(f'train/{path}', exist_ok=True)
28 os.makedirs(f'test/{path}', exist_ok=True)
29
30 #原始文件夹当前类别的图片进行匹配
31 files = glob.glob(os.path.join( path, '*.jpg'))
32 # print(raw_path, path)
33
34 files += glob.glob(os.path.join( path, '*.JPG'))
35 files += glob.glob(os.path.join( path, '*.png'))
36
37 random.shuffle(files)#原地shuffle,因为要取出来验证集
38
39 boundary = int(len(files)*test_split_ratio) # 训练集和测试集的边界
40
41 for i, file in enumerate(files):
42 img = Image.open(file).convert('RGB')
43
44 old_size = img.size
45
46 ratio = float(desired_size)/max(old_size)
47
48 new_size = tuple([int(x*ratio) for x in old_size])#等比例缩放
49
50 im = img.resize(new_size, Image.ANTIALIAS)#后面的方法不会造成模糊
51
52 new_im = Image.new("RGB", (desired_size, desired_size))
53
54 #new_im在某个尺寸上更大,我们将旧图片贴到上面
55 new_im.paste(im, ((desired_size-new_size[0])//2,
56 (desired_size-new_size[1])//2))
57
58 assert new_im.mode == 'RGB'
59
60 if i <= boundary:
61 new_im.save(os.path.join(f'test/{path}', file.split('\\')[-1].split('.')[0]+'.jpg'))
62 else:
63 new_im.save(os.path.join(f'train/{path}', file.split('\\')[-1].split('.')[0]+'.jpg'))
64
65 test_files = glob.glob(os.path.join('test', '*', '*.jpg'))
66 train_files = glob.glob(os.path.join('train', '*', '*.jpg'))
67
68 print(f'Totally {len(train_files)} files for training')
69 print(f'Totally {len(test_files)} files for test') 
(2)图像预处理
包括随即旋转、随机翻转、裁剪等,并进行归一化。
1 #图像预处理
2 train_dir = './train'
3 val_dir = './test'
4 test_dir = './test'
5 classes0 = os.listdir(train_dir)
6 classes=sorted(classes0)
7 print(classes)
8 train_transform=transforms.Compose([
9 transforms.RandomRotation(10), # 旋转+/-10度
10 transforms.RandomHorizontalFlip(), # 反转50%的图像
11 transforms.Resize(40), # 调整最短边的大小
12 transforms.CenterCrop(40), # 作物最长边
13 transforms.ToTensor(),
14 transforms.Normalize([0.485, 0.456, 0.406],
15 [0.229, 0.224, 0.225])
16 ])
1 #显示图像
2 def show_image(img,label):
3 print('Label: ', trainset.classes[label], "("+str(label)+")")
4 plt.imshow(img.permute(1,2,0))
5 plt.show()
6
7 show_image(*trainset[10])
8 show_image(*trainset[20])
(3)读取数据
1 batch_size = 64
2 train_loader = DataLoader(train_ds, batch_size, shuffle=True, num_workers=4, pin_memory=True)
3 val_loader = DataLoader(val_ds, batch_size*2, num_workers=4, pin_memory=True)
4 test_loader = DataLoader(test_ds, batch_size*2, num_workers=4, pin_memory=True)(4)构建CNN模型
#构建CNN模型
1 #构建CNN模型
2 class CnnModel(ImageClassificationBase):
3 def __init__(self):
4 super().__init__()
5 #cnn提取特征
6 self.network = nn.Sequential(
7 nn.Conv2d(3, 100, kernel_size=3, padding=1),#Conv2D层
8 nn.ReLU(),
9 nn.Conv2d(100, 150, kernel_size=3, stride=1, padding=1),
10 nn.ReLU(),
11 nn.MaxPool2d(2, 2), #池化层
12
13 nn.Conv2d(150, 200, kernel_size=3, stride=1, padding=1),
14 nn.ReLU(),
15 nn.Conv2d(200, 200, kernel_size=3, stride=1, padding=1),
16 nn.ReLU(),
17 nn.MaxPool2d(2, 2),
18
19 nn.Conv2d(200, 250, kernel_size=3, stride=1, padding=1),
20 nn.ReLU(),
21 nn.Conv2d(250, 250, kernel_size=3, stride=1, padding=1),
22 nn.ReLU(),
23 nn.MaxPool2d(2, 2),
24
25 #全连接
26 nn.Flatten(),
27 nn.Linear(6250, 256),
28 nn.ReLU(),
29 nn.Linear(256, 128),
30 nn.ReLU(),
31 nn.Linear(128, 64),
32 nn.ReLU(),
33 nn.Linear(64, 32),
34 nn.ReLU(),
35 nn.Dropout(0.25),
36 nn.Linear(32, len(classes)))
37
38 def forward(self, xb):
39 return self.network(xb)(5)训练网络
#训练网络
1 #训练网络
2 @torch.no_grad()
3 def evaluate(model, val_loader):
4 model.eval()
5 outputs = [model.validation_step(batch) for batch in val_loader]
6 return model.validation_epoch_end(outputs)
7
8 def fit(epochs, lr, model, train_loader, val_loader, opt_func=torch.optim.SGD):
9 history = []
10 optimizer = opt_func(model.parameters(), lr)
11 for epoch in range(epochs):
12 # 训练阶段
13 model.train()
14 train_losses = []
15 for batch in tqdm(train_loader,disable=True):
16 loss = model.training_step(batch)
17 train_losses.append(loss)
18 loss.backward()
19 optimizer.step()
20 optimizer.zero_grad()
21 # 验证阶段
22 result = evaluate(model, val_loader)
23 result['train_loss'] = torch.stack(train_losses).mean().item()
24 model.epoch_end(epoch, result)
25 history.append(result)
26 return history
27
28 model = to_device(CnnModel(), device)
29
30 history=[evaluate(model, val_loader)]
31
32 num_epochs = 100
33 opt_func = torch.optim.Adam
34 lr = 0.001
35
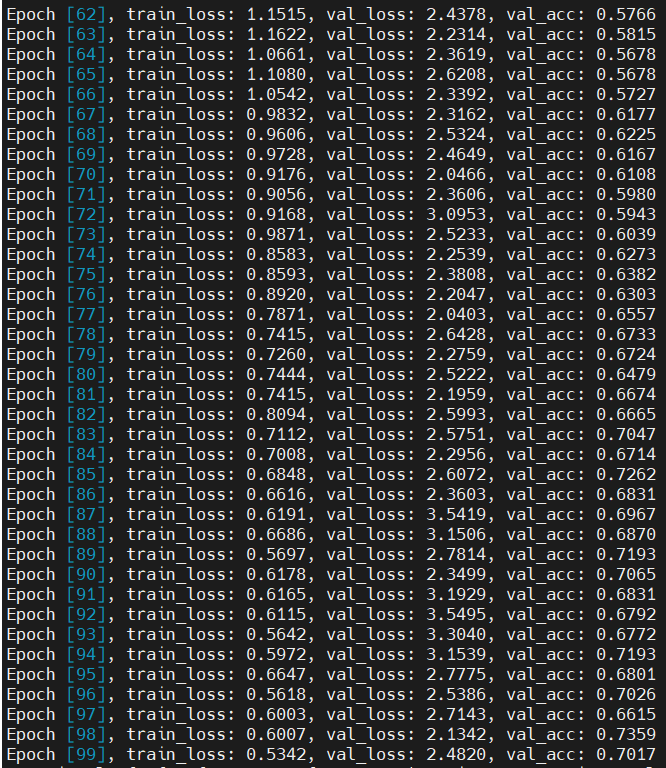
36 history+= fit(num_epochs, lr, model, train_dl, val_dl, opt_func)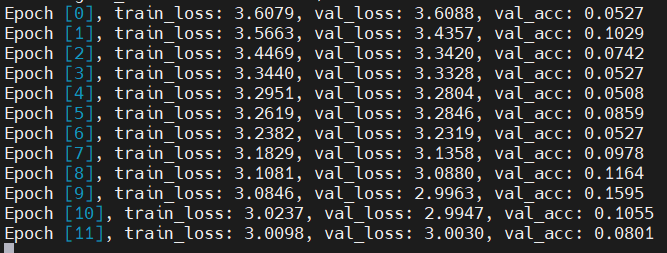
(6)绘制损失函数和准确率图
1 def plot_accuracies(history):
2 accuracies = [x['val_acc'] for x in history]
3 plt.plot(accuracies, '-x')
4 plt.xlabel('epoch')
5 plt.ylabel('accuracy')
6 plt.title('Accuracy vs. No. of epochs')
7 plt.show()
8
9 def plot_losses(history):
10 train_losses = [x.get('train_loss') for x in history]
11 val_losses = [x['val_loss'] for x in history]
12 plt.plot(train_losses, '-bx')
13 plt.plot(val_losses, '-rx')
14 plt.xlabel('epoch')
15 plt.ylabel('loss')
16 plt.legend(['Training', 'Validation'])
17 plt.title('Loss vs. No. of epochs')
18 plt.show()
19
20 plot_accuracies(history)
21 plot_losses(history)
22
23 evaluate(model, test_loader)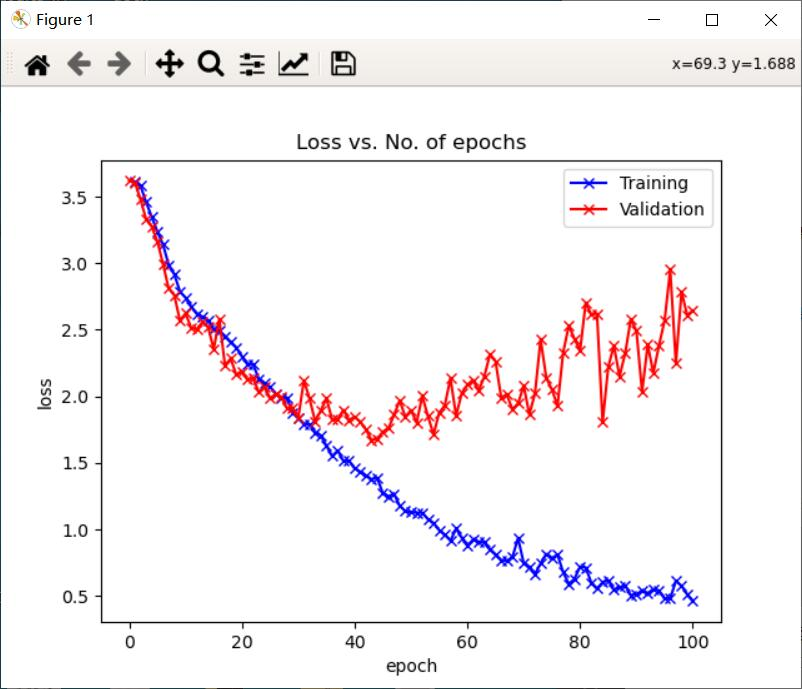
(7)读取图片测试
1 import numpy as np
2 from PIL import Image
3 import matplotlib.pyplot as plt
4 import torchvision.transforms as transforms
5
6 def predict(img_path):
7 img = Image.open(img_path)
8 plt.imshow(img)
9 plt.show()
10 img = img.resize((32,32))
11 img = transforms.ToTensor()(img)
12 img = img.unsqueeze(0)
13 img = img.to(device)
14 pred = model(img).argmax(dim=1)
15 print('预测结果为:',classes[pred.item()])
16 return classes[pred.item()]
17
18 predict('./raw/apple/Image_1.jpg')

四、总结
在本次课程设计中,使用深度学习的方法实现了果蔬的36分类,相对来说分类数量是比较多的,在训练了100个epoch以后,分类的准确率可以达到74.3%。通过对果蔬的分类,我明白了当训练集的图像数量较少时,可以采用数据增强对原始图像进行处理,获得更多的数据来增强网络的泛化能力,避免网络过拟合。数据增强的方法一般有随机翻转、随即旋转、随即裁剪、明暗变化、高斯噪声、椒盐噪声等。除此之外,对整个深度学习中图像分类的流程也有了一定的了解,从收集数据、对数据进行预处理、自己构建网络模型、训练网络到最后的预测结果,加深了对图像分类过程的理解。希望在以后的学习中,可以学习更多深度学习的方法和应用。
五、全部代码
1 import os
2 import glob
3 import random
4 import shutil
5 from PIL import Image
6 #对所有图片进行RGB转化,并且统一调整到一致大小,但不让图片发生变形或扭曲,划分了训练集和测试集
7
8 if __name__ == '__main__':
9 test_split_ratio = 0.05 #百分之五的比例作为测试集
10 desired_size = 128 # 图片缩放后的统一大小
11 raw_path = './raw'
12
13 #把多少个类别算出来,包括目录也包括文件
14 dirs = glob.glob(os.path.join(raw_path, '*'))
15 #进行过滤,只保留目录,一共36个类别
16 dirs = [d for d in dirs if os.path.isdir(d)]
17
18 print(f'Totally {len(dirs)} classes: {dirs}')
19
20 for path in dirs:
21 # 对每个类别单独处理
22
23 #只保留类别名称
24 path = path.split('/')[-1]
25 print(path)
26 #创建文件夹
27 os.makedirs(f'train/{path}', exist_ok=True)
28 os.makedirs(f'test/{path}', exist_ok=True)
29
30 #原始文件夹当前类别的图片进行匹配
31 files = glob.glob(os.path.join(raw_path, path, '*.jpg'))
32 # print(raw_path, path)
33
34 files += glob.glob(os.path.join(raw_path, path, '*.JPG'))
35 files += glob.glob(os.path.join(raw_path, path, '*.png'))
36
37 random.shuffle(files)#原地shuffle,因为要取出来验证集
38
39 boundary = int(len(files)*test_split_ratio) # 训练集和测试集的边界
40
41 for i, file in enumerate(files):
42 img = Image.open(file).convert('RGB')
43
44 old_size = img.size
45
46 ratio = float(desired_size)/max(old_size)
47
48 new_size = tuple([int(x*ratio) for x in old_size])#等比例缩放
49
50 im = img.resize(new_size, Image.ANTIALIAS)#后面的方法不会造成模糊
51
52 new_im = Image.new("RGB", (desired_size, desired_size))
53
54 #new_im在某个尺寸上更大,我们将旧图片贴到上面
55 new_im.paste(im, ((desired_size-new_size[0])//2,
56 (desired_size-new_size[1])//2))
57
58 assert new_im.mode == 'RGB'
59
60 if i <= boundary:
61 new_im.save(os.path.join(f'test/{path}', file.split('/')[-1].split('.')[0]+'.jpg'))
62 else:
63 new_im.save(os.path.join(f'train/{path}', file.split('/')[-1].split('.')[0]+'.jpg'))
64
65 test_files = glob.glob(os.path.join('test', '*', '*.jpg'))
66 train_files = glob.glob(os.path.join('train', '*', '*.jpg'))
67
68
69 print(f'Totally {len(train_files)} files for training')
70 print(f'Totally {len(test_files)} files for test')
71
72
73 import os
74 import random
75 import numpy as np
76 import pandas as pd
77 import torch
78 import torch.nn as nn
79 import torch.nn.functional as F
80 from tqdm.notebook import tqdm
81 from torchvision import datasets, transforms, models
82 from torchvision.datasets import ImageFolder
83 from torchvision.transforms import ToTensor
84 from torchvision.utils import make_grid
85 from torch.utils.data import random_split
86 from torch.utils.data.dataloader import DataLoader
87 import matplotlib.pyplot as plt
88
89 if __name__ == '__main__':
90 # 使用第2个GPU
91 os.environ["CUDA_VISIBLE_DEVICES"] = "1"
92
93 #图像预处理
94 train_dir = './train'
95 val_dir = './test'
96 test_dir = './test'
97 classes0 = os.listdir(train_dir)
98 classes=sorted(classes0)
99 # print(classes)
100 train_transform=transforms.Compose([
101 transforms.RandomRotation(10), # 旋转+/-10度
102 transforms.RandomHorizontalFlip(), # 反转50%的图像
103 transforms.Resize(40), # 调整最短边的大小
104 transforms.CenterCrop(40), # 作物最长边
105 transforms.ToTensor(),
106 transforms.Normalize([0.485, 0.456, 0.406],
107 [0.229, 0.224, 0.225])
108 ])
109
110 trainset = ImageFolder(train_dir, transform=train_transform)
111 valset = ImageFolder(val_dir, transform=train_transform)
112 testset = ImageFolder(test_dir, transform=train_transform)
113 # print(len(trainset))
114
115 #查看数据集的一个图像形状
116 img, label = trainset[10]
117 # print(img.shape)
118
119 #显示图像
120 def show_image(img,label):
121 print('Label: ', trainset.classes[label], "("+str(label)+")")
122 plt.imshow(img.permute(1,2,0))
123 plt.show()
124
125 # show_image(*trainset[10])
126 # show_image(*trainset[20])
127
128 torch.manual_seed(10)
129 train_size = len(trainset)
130 val_size = len(valset)
131 test_size = len(testset)
132
133 train_ds=trainset
134 val_ds=valset
135 test_ds=testset
136 len(train_ds), len(val_ds), len(test_ds)
137
138 #读取数据
139 batch_size = 64
140 train_loader = DataLoader(train_ds, batch_size, shuffle=True, num_workers=4, pin_memory=True)
141 val_loader = DataLoader(val_ds, batch_size*2, num_workers=4, pin_memory=True)
142 test_loader = DataLoader(test_ds, batch_size*2, num_workers=4, pin_memory=True)
143
144
145 if __name__ == '__main__':
146 for images, labels in train_loader:
147 fig, ax = plt.subplots(figsize=(18,10))
148 ax.set_xticks([])
149 ax.set_yticks([])
150 ax.imshow(make_grid(images,nrow=16).permute(1,2,0))
151 break
152
153
154
155 torch.cuda.is_available()
156
157
158 #选择GPU或CPU
159 def get_default_device():
160 if torch.cuda.is_available():
161 return torch.device('cuda')
162 else:
163 return torch.device('cpu')
164
165 #移动到所选的设备
166 def to_device(data, device):
167 if isinstance(data, (list,tuple)):
168 return [to_device(x, device) for x in data]
169 return data.to(device, non_blocking=True)
170
171 class DeviceDataLoader():
172 #包装数据加载器以将数据移动到设备
173 def __init__(self, dl, device):
174 self.dl = dl
175 self.device = device
176
177 def __iter__(self):
178 #将数据移动到设备后生成一批数据
179 for b in self.dl:
180 yield to_device(b, self.device)
181
182 def __len__(self):
183 #分批次
184 return len(self.dl)
185
186 device = get_default_device()
187
188
189 train_loader = DeviceDataLoader(train_loader, device)
190 val_loader = DeviceDataLoader(val_loader, device)
191 test_loader = DeviceDataLoader(test_loader, device)
192
193 input_size = 3*40*40
194 output_size = 3
195
196
197
198 def accuracy(outputs, labels):
199 _, preds = torch.max(outputs, dim=1)
200 return torch.tensor(torch.sum(preds == labels).item() / len(preds))
201
202 #图像分类
203 class ImageClassificationBase(nn.Module):
204 def training_step(self, batch):
205 images, labels = batch
206 out = self(images) # 生成预测
207 loss = F.cross_entropy(out, labels) # 计算损失
208 return loss
209
210 def validation_step(self, batch):
211 images, labels = batch
212 out = self(images) # 生成预测
213 loss = F.cross_entropy(out, labels) # 计算损失
214 acc = accuracy(out, labels) # 计算精度
215 return {'val_loss': loss.detach(), 'val_acc': acc}
216
217 def validation_epoch_end(self, outputs):
218 batch_losses = [x['val_loss'] for x in outputs]
219 epoch_loss = torch.stack(batch_losses).mean() # 合并损失
220 batch_accs = [x['val_acc'] for x in outputs]
221 epoch_acc = torch.stack(batch_accs).mean() # 结合精度
222 return {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}
223
224 def epoch_end(self, epoch, result):
225 print("Epoch [{}], train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}".format(
226 epoch, result['train_loss'], result['val_loss'], result['val_acc']))
227
228 #构建CNN模型
229 class CnnModel(ImageClassificationBase):
230 def __init__(self):
231 super().__init__()
232 #cnn提取特征
233 self.network = nn.Sequential(
234 nn.Conv2d(3, 100, kernel_size=3, padding=1),#Conv2D层
235 nn.ReLU(),
236 nn.Conv2d(100, 150, kernel_size=3, stride=1, padding=1),
237 nn.ReLU(),
238 nn.MaxPool2d(2, 2), #池化层
239
240 nn.Conv2d(150, 200, kernel_size=3, stride=1, padding=1),
241 nn.ReLU(),
242 nn.Conv2d(200, 200, kernel_size=3, stride=1, padding=1),
243 nn.ReLU(),
244 nn.MaxPool2d(2, 2),
245
246 nn.Conv2d(200, 250, kernel_size=3, stride=1, padding=1),
247 nn.ReLU(),
248 nn.Conv2d(250, 250, kernel_size=3, stride=1, padding=1),
249 nn.ReLU(),
250 nn.MaxPool2d(2, 2),
251
252 #全连接
253 nn.Flatten(),
254 nn.Linear(6250, 256),
255 nn.ReLU(),
256 nn.Linear(256, 128),
257 nn.ReLU(),
258 nn.Linear(128, 64),
259 nn.ReLU(),
260 nn.Linear(64, 32),
261 nn.ReLU(),
262 nn.Dropout(0.25),
263 nn.Linear(32, len(classes)))
264
265 def forward(self, xb):
266 return self.network(xb)
267
268 # 将模型加载到GPU上去
269 model = CnnModel()
270
271 # model.cuda()
272
273 if __name__ == '__main__':
274 for images, labels in train_loader:
275 out = model(images)
276 print('images.shape:', images.shape)
277 print('out.shape:', out.shape)
278 print('out[0]:', out[0])
279 break
280
281 device = get_default_device()
282
283 train_dl = DeviceDataLoader(train_loader, device)
284 val_dl = DeviceDataLoader(val_loader, device)
285 test_dl = DeviceDataLoader(test_loader, device)
286 to_device(model, device)
287
288
289 #训练网络
290 def evaluate(model, val_loader):
291 model.eval()
292 outputs = [model.validation_step(batch) for batch in val_loader]
293 return model.validation_epoch_end(outputs)
294
295 def fit(epochs, lr, model, train_loader, val_loader, opt_func=torch.optim.SGD):
296 history = []
297 optimizer = opt_func(model.parameters(), lr)
298 for epoch in range(epochs):
299 # 训练阶段
300 model.train()
301 train_losses = []
302 for batch in tqdm(train_loader,disable=True):
303 loss = model.training_step(batch)
304 train_losses.append(loss)
305 loss.backward()
306 optimizer.step()
307 optimizer.zero_grad()
308 # 验证阶段
309 result = evaluate(model, val_loader)
310 result['train_loss'] = torch.stack(train_losses).mean().item()
311 model.epoch_end(epoch, result)
312 history.append(result)
313 return history
314
315 model = to_device(CnnModel(), device)
316
317
318 history=[evaluate(model, val_loader)]
319 num_epochs = 5
320 opt_func = torch.optim.Adam
321 lr = 0.001
322
323 history+= fit(num_epochs, lr, model, train_dl, val_dl, opt_func)
324
325
326 # # 绘制损失函数和准确率图
327
328 def plot_accuracies(history):
329 accuracies = [x['val_acc'] for x in history]
330 plt.plot(accuracies, '-x')
331 plt.xlabel('epoch')
332 plt.ylabel('accuracy')
333 plt.title('Accuracy vs. No. of epochs')
334 plt.show()
335
336 def plot_losses(history):
337 train_losses = [x.get('train_loss') for x in history]
338 val_losses = [x['val_loss'] for x in history]
339 plt.plot(train_losses, '-bx')
340 plt.plot(val_losses, '-rx')
341 plt.xlabel('epoch')
342 plt.ylabel('loss')
343 plt.legend(['Training', 'Validation'])
344 plt.title('Loss vs. No. of epochs')
345 plt.show()
346
347 plot_accuracies(history)
348 plot_losses(history)
349
350 evaluate(model, test_loader)
351
352
353 #预测分类
354 y_true=[]
355 y_pred=[]
356 with torch.no_grad():
357 for test_data in test_loader:
358 test_images, test_labels = test_data[0].to(device), test_data[1].to(device)
359 pred = model(test_images).argmax(dim=1)
360 for i in range(len(pred)):
361 y_true.append(test_labels[i].item())
362 y_pred.append(pred[i].item())
363
364 from sklearn.metrics import classification_report
365 print(classification_report(y_true,y_pred,target_names=classes,digits=4))
366
367 # 读取图片进行预测
368 import numpy as np
369 from PIL import Image
370 import matplotlib.pyplot as plt
371 import torchvision.transforms as transforms
372
373 def predict(img_path):
374 img = Image.open(img_path)
375 plt.imshow(img)
376 plt.show()
377 img = img.resize((32,32))
378 img = transforms.ToTensor()(img)
379 img = img.unsqueeze(0)
380 img = img.to(device)
381 pred = model(img).argmax(dim=1)
382 print('预测结果为:',classes[pred.item()])
383 return classes[pred.item()]
384
385 predict('./raw/apple/Image_1.jpg')
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
require"socket"server="irc.rizon.net"port="6667"nick="RubyIRCBot"channel="#0x40"s=TCPSocket.open(server,port)s.print("USERTesting",0)s.print("NICK#{nick}",0)s.print("JOIN#{channel}",0)这个IRC机器人没有连接到IRC服务器,我做错了什么? 最佳答案 失败并显示此消息::irc.shakeababy.net461*USER:Notenoughparame
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标