Kafka史上最详细原理总结
kafka系列
Kafka史上最详细原理总结(一)
kafka常用的shell命令(二)
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目。
当今社会各种应用系统诸如商业、社交、搜索、浏览等像信息工厂一样不断的生产出各种信息,在大数据时代,我们面临如下几个挑战:
以上几个挑战形成了一个业务需求模型,即生产者生产(produce)各种信息,消费者消费(consume)(处理分析)这些信息,而在生产者与消费者之间,需要一个沟通两者的桥梁-消息系统。从一个微观层面来说,这种需求也可理解为不同的系统之间如何传递消息。
Kafka诞生
Kafka由 linked-in 开源
kafka-即是解决上述这类问题的一个框架,它实现了生产者和消费者之间的无缝连接。
kafka-高产出的分布式消息系统(A high-throughput distributed messaging system)
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒
可扩展性:kafka集群支持热扩展
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
高并发:支持数千个客户端同时读写
日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
消息系统:解耦和生产者和消费者、缓存消息等。
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
流式处理:比如spark streaming和storm
事件源
Consumergroup:各个consumer可以组成一个组,每个消息只能被组中的一个consumer消费,如果一个消息可以被多个consumer消费的话,那么这些consumer必须在不同的组。
消息状态:在Kafka中,消息的状态被保存在consumer中,broker不会关心哪个消息被消费了被谁消费了,只记录一个offset值(指向partition中下一个要被消费的消息位置),这就意味着如果consumer处理不好的话,broker上的一个消息可能会被消费多次。
消息持久化:Kafka中会把消息持久化到本地文件系统中,并且保持极高的效率。
消息有效期:Kafka会长久保留其中的消息,以便consumer可以多次消费,当然其中很多细节是可配置的。
批量发送:Kafka支持以消息集合为单位进行批量发送,以提高push效率。
push-and-pull: Kafka中的Producer和consumer采用的是push-and-pull模式,即Producer只管向broker push消息,consumer只管从broker pull消息,两者对消息的生产和消费是异步的。
Kafka集群中broker之间的关系:不是主从关系,各个broker在集群中地位一样,我们可以随意的增加或删除任何一个broker节点。
负载均衡方面: Kafka提供了一个 metadata API来管理broker之间的负载(对Kafka0.8.x而言,对于0.7.x主要靠zookeeper来实现负载均衡)。
同步异步:Producer采用异步push方式,极大提高Kafka系统的吞吐率(可以通过参数控制是采用同步还是异步方式)。
分区机制partition:Kafka的broker端支持消息分区,Producer可以决定把消息发到哪个分区,在一个分区中消息的顺序就是Producer发送消息的顺序,一个主题中可以有多个分区,具体分区的数量是可配置的。分区的意义很重大,后面的内容会逐渐体现。
离线数据装载:Kafka由于对可拓展的数据持久化的支持,它也非常适合向Hadoop或者数据仓库中进行数据装载。
插件支持:现在不少活跃的社区已经开发出不少插件来拓展Kafka的功能,如用来配合Storm、Hadoop、flume相关的插件。
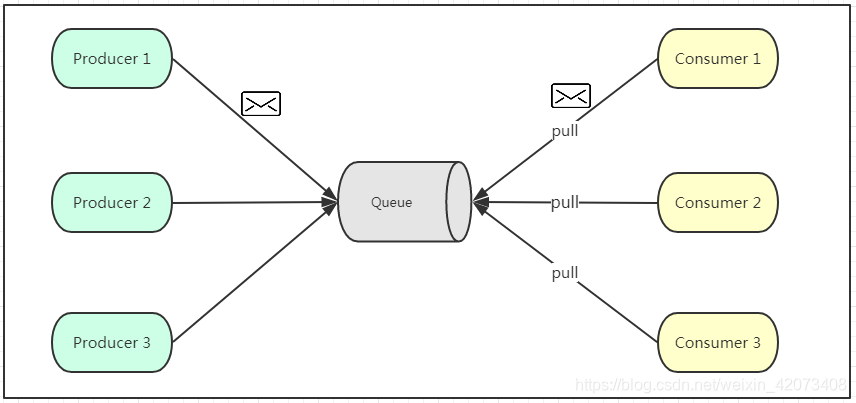
如上图所示,点对点模式通常是基于拉取或者轮询的消息传送模型,这个模型的特点是发送到队列的消息被一个且只有一个消费者进行处理。生产者将消息放入消息队列后,由消费者主动的去拉取消息进行消费。点对点模型的的优点是消费者拉取消息的频率可以由自己控制。但是消息队列是否有消息需要消费,在消费者端无法感知,所以在消费者端需要额外的线程去监控。
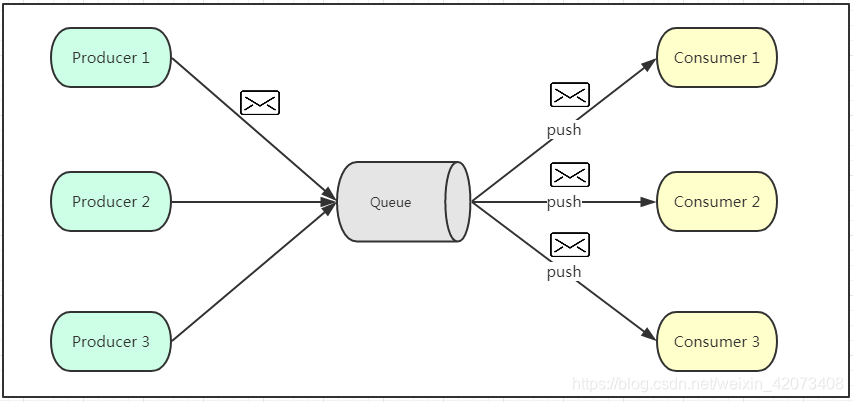
如上图所示,发布订阅模式是一个基于消息送的消息传送模型,改模型可以有多种不同的订阅者。生产者将消息放入消息队列后,队列会将消息推送给订阅过该类消息的消费者(类似微信公众号)。由于是消费者被动接收推送,所以无需感知消息队列是否有待消费的消息!但是consumer1、consumer2、consumer3由于机器性能不一样,所以处理消息的能力也会不一样,但消息队列却无法感知消费者消费的速度!所以推送的速度成了发布订阅模模式的一个问题!假设三个消费者处理速度分别是8M/s、5M/s、2M/s,如果队列推送的速度为5M/s,则consumer3无法承受!如果队列推送的速度为2M/s,则consumer1、consumer2会出现资源的极大浪费!
上面简单的介绍了为什么需要消息队列以及消息队列通信的两种模式,下面主角介绍Kafka。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据,具有高性能、持久化、多副本备份、横向扩展能力。。
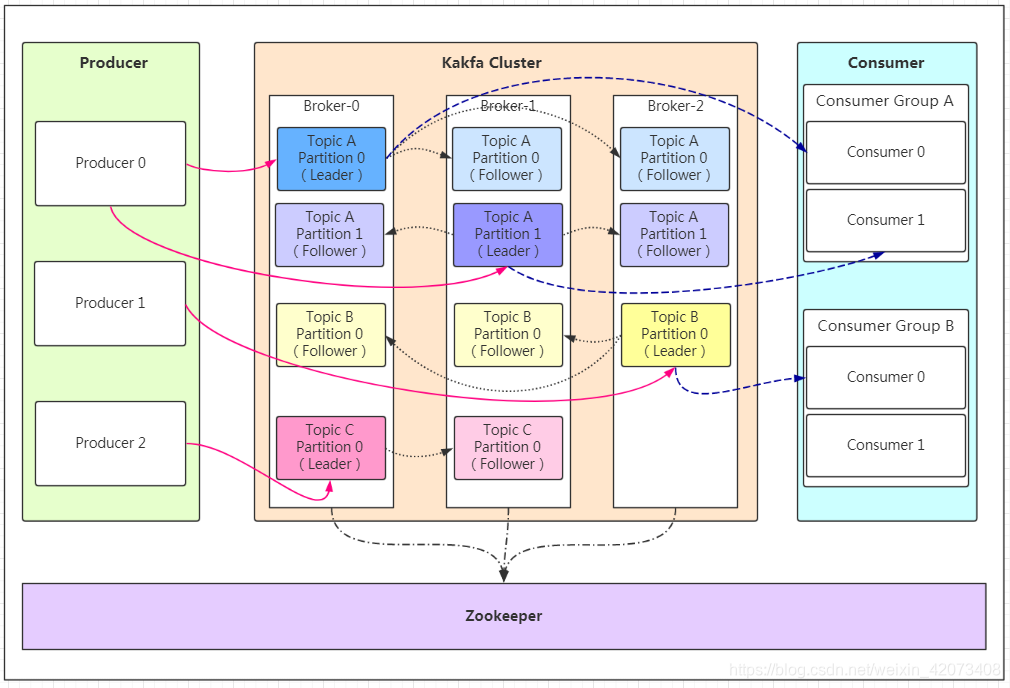
我们看上面的架构图中,producer就是生产者,是数据的入口。注意看图中的红色箭头,Producer在写入数据的时候永远的找leader,不会直接将数据写入follower!那leader怎么找呢?写入的流程又是什么样的呢?我们看下图:
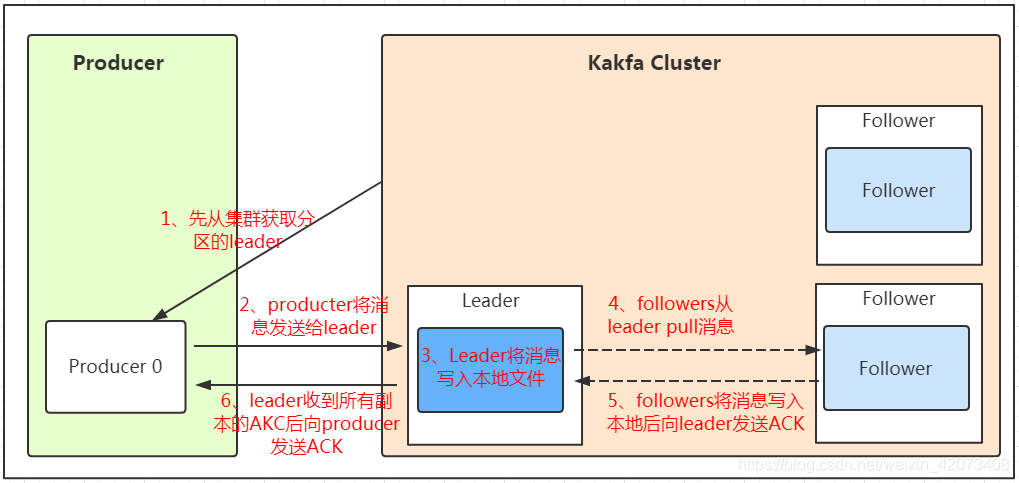
发送的流程就在图中已经说明了,就不单独在文字列出来了!需要注意的一点是,消息写入leader后,follower是主动的去leader进行同步的!producer采用push模式将数据发布到broker,每条消息追加到分区中,顺序写入磁盘,所以保证同一分区内的数据是有序的!写入示意图如下:

上面说到数据会写入到不同的分区,那kafka为什么要做分区呢?相信大家应该也能猜到,分区的主要目的是:
熟悉负载均衡的朋友应该知道,当我们向某个服务器发送请求的时候,服务端可能会对请求做一个负载,将流量分发到不同的服务器,那在kafka中,如果某个topic有多个partition,producer又怎么知道该将数据发往哪个partition呢?kafka中有几个原则:
Producer将数据写入kafka后,集群就需要对数据进行保存了!kafka将数据保存在磁盘,可能在我们的一般的认知里,写入磁盘是比较耗时的操作,不适合这种高并发的组件。Kafka初始会单独开辟一块磁盘空间,顺序写入数据(效率比随机写入高)。
(1)Partition 结构
前面说过了每个topic都可以分为一个或多个partition,如果你觉得topic比较抽象,那partition就是比较具体的东西了!Partition在服务器上的表现形式就是一个一个的文件夹,每个partition的文件夹下面会有多组segment文件,每组segment文件又包含.index文件、.log文件、.timeindex文件(早期版本中没有)三个文件, log文件就实际是存储message的地方,而index和timeindex文件为索引文件,用于检索消息。

如上图,这个partition有三组segment文件,每个log文件的大小是一样的,但是存储的message数量是不一定相等的(每条的message大小不一致)。文件的命名是以该segment最小offset来命名的,如000.index存储offset为0~368795的消息,kafka就是利用分段+索引的方式来解决查找效率的问题。
(2)Message结构
上面说到log文件就实际是存储message的地方,我们在producer往kafka写入的也是一条一条的message,那存储在log中的message是什么样子的呢?消息主要包含消息体、消息大小、offset、压缩类型……等等!我们重点需要知道的是下面三个:
(3)存储策略
无论消息是否被消费,kafka都会保存所有的消息。那对于旧数据有什么删除策略呢?
需要注意的是,kafka读取特定消息的时间复杂度是O(1),所以这里删除过期的文件并不会提高kafka的性能!
消息存储在log文件后,消费者就可以进行消费了。在讲消息队列通信的两种模式的时候讲到过点对点模式和发布订阅模式。Kafka采用的是发布订阅模式,消费者主动的去kafka集群拉取消息,与producer相同的是,消费者在拉取消息的时候也是找leader去拉取。
多个消费者可以组成一个消费者组(consumer group),每个消费者组都有一个组id!同一个消费组者的消费者可以消费同一topic下不同分区的数据,但是不会组内多个消费者消费同一分区的数据!!!我们看下图:
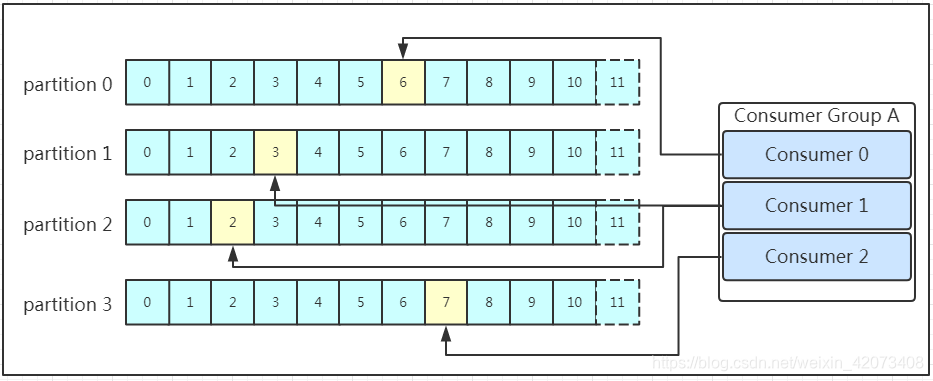
图示是消费者组内的消费者小于partition数量的情况,所以会出现某个消费者消费多个partition数据的情况,消费的速度也就不及只处理一个partition的消费者的处理速度!如果是消费者组的消费者多于partition的数量,那会不会出现多个消费者消费同一个partition的数据呢?上面已经提到过不会出现这种情况!多出来的消费者不消费任何partition的数据。所以在实际的应用中,建议消费者组的consumer的数量与partition的数量一致!
在保存数据的小节里面,我们聊到了partition划分为多组segment,每个segment又包含.log、.index、.timeindex文件,存放的每条message包含offset、消息大小、消息体……我们多次提到segment和offset,查找消息的时候是怎么利用segment+offset配合查找的呢?假如现在需要查找一个offset为368801的message是什么样的过程呢?我们先看看下面的图:
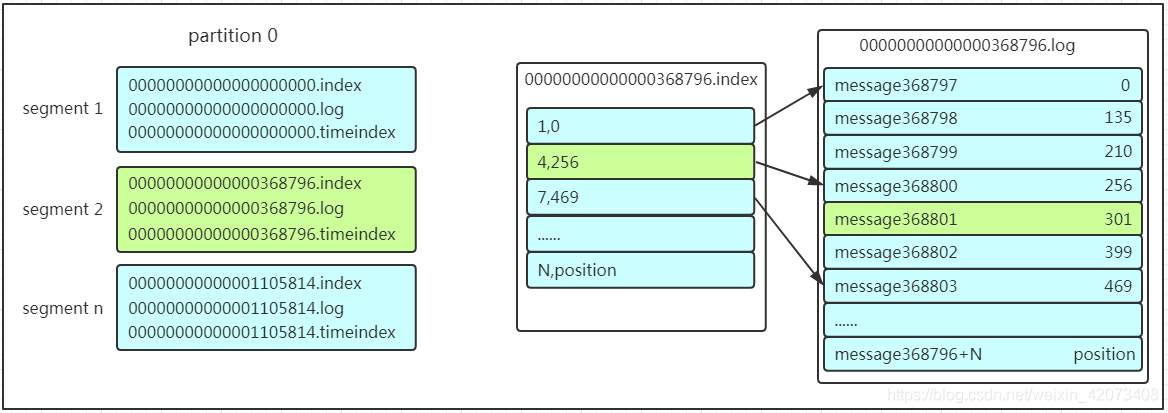
这套机制是建立在offset为有序的基础上,利用segment+有序offset+稀疏索引+二分查找+顺序查找等多种手段来高效的查找数据!至此,消费者就能拿到需要处理的数据进行处理了。那每个消费者又是怎么记录自己消费的位置呢?在早期的版本中,消费者将消费到的offset维护zookeeper中,consumer每间隔一段时间上报一次,这里容易导致重复消费,且性能不好!在新的版本中消费者消费到的offset已经直接维护在kafk集群的__consumer_offsets这个topic中!
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
文章目录一、项目场景二、基本模块原理与调试方法分析——信源部分:三、信号处理部分和显示部分:四、基本的通信链路搭建:四、特殊模块:interpretedMATLABfunction:五、总结和坑点提醒一、项目场景 最近一个任务是使用simulink搭建一个MIMO串扰消除的链路,并用实际收到的数据进行测试,在搭建的过程中也遇到了不少的问题(当然这比vivado里面的debug好不知道多少倍)。准备趁着这个机会,先以一个很基本的通信链路对simulink基础和相关的debug方法进行总结。 在本篇中,主要记录simulink的基本原理和基本的SISO通信传输链路(QPSK方式),计划在下篇记
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式
目录一、安装包链接二、安装详细步骤1.安装Wireshark和WinPcap2.安装OracleVMVirtualBox3.安装ensp三、安装后注册四、启动路由器出现40错误怎么解决一、安装包链接二、安装详细步骤链接:https://pan.baidu.com/s/1QbUUYMOMIV2oeIKHWP1SpA?pwd=xftx提取码:xftx1.安装Wireshark和WinPcap找到Wireshark安装包所在文件夹,双击它,按照以下步骤安装。2.安装OracleVMVirtualBox找到OracleVMVirtualBox安装包所在文件夹,双击它,按照以下步骤安装。注:可自定义安装
文章目录认识unity打包目录结构游戏逆向流程Unity游戏攻击面可被攻击原因mono的打包建议方案锁血飞天无限金币攻击力翻倍以上统称内存挂透视自瞄压枪瞬移内购破解Unity游戏防御开发时注意数据安全接入第三方反作弊系统外挂检测思路狠人自爆实战查看目录结构用il2cppdumper例子2-森林whoishe后记认识unity打包目录结构dll一般很大,因为里面是所有的游戏功能编译成的二进制码游戏逆向流程开发人员代码被编译打包到GameAssembly.dll中使用il2ppDumper工具,并借助游戏名_Data\il2cpp_data\Metadata\global-metadata.dat
Nginx安装1.官网下载Nginx2.使用XShell和Xftp将压缩包上传到Linux虚拟机中3.解压文件nginx-1.20.2.tar.gz4.配置nginx5.启动nginx6.拓展(修改端口和常用命令)(一)修改nginx端口(二)常用命令1.官网下载Nginxhttp://nginx.org/en/download.html这里我下载的是1.20.2版本,大家按需下载对应稳定版即可2.使用XShell和Xftp将压缩包上传到Linux虚拟机中没有XShell可以参考《Linux操作系统CentOS7连接XShell》3.解压文件nginx-1.20.2.tar.gz1)检查是否存
因学习需要用到keras,通过查找较多资料最终完成Anaconda、TensorFlow和Keras的简单安装。因为网上的相关资料较多但大部分不够全面,查找起来不太方便,因此自己记录一下成功下载安装的详细过程,顺便推荐一下借鉴的写的很好的相关教程文章。keras需要在TensorFlow之上才能运行,所以要先安装TensorFlow,而TensorFlow只能在3.7以前的python版本中运行,所以需要先创建一个基于python3.6的虚拟环境,因此便需要先下载Anaconda。一、Anaconda3下载和安装Anaconda下载安装教程原文链接:https://blog.csdn.net/
【动态规划】一、背包问题1.背包问题总结1)动规四部曲:2)递推公式总结:3)遍历顺序总结:2.01背包1)二维dp数组代码实现2)一维dp数组代码实现3.完全背包代码实现4.多重背包代码实现一、背包问题1.背包问题总结暴力的解法是指数级别的时间复杂度。进而才需要动态规划的解法来进行优化!背包问题是动态规划(DynamicPlanning)里的非常重要的一部分,关于几种常见的背包,其关系如下:在解决背包问题的时候,我们通常都是按照如下五部来逐步分析,把这五部都搞透了,算是对动规来理解深入了。1)动规四部曲:(1)确定dp数组及其下标的含义(2)确定递推公式(3)dp数组的初始化(4)确定遍历顺