推荐场景下需要使用上述指标评估离、在线模型效果,下面对各个指标做简单说明并通过 spark 程序全部搞定。
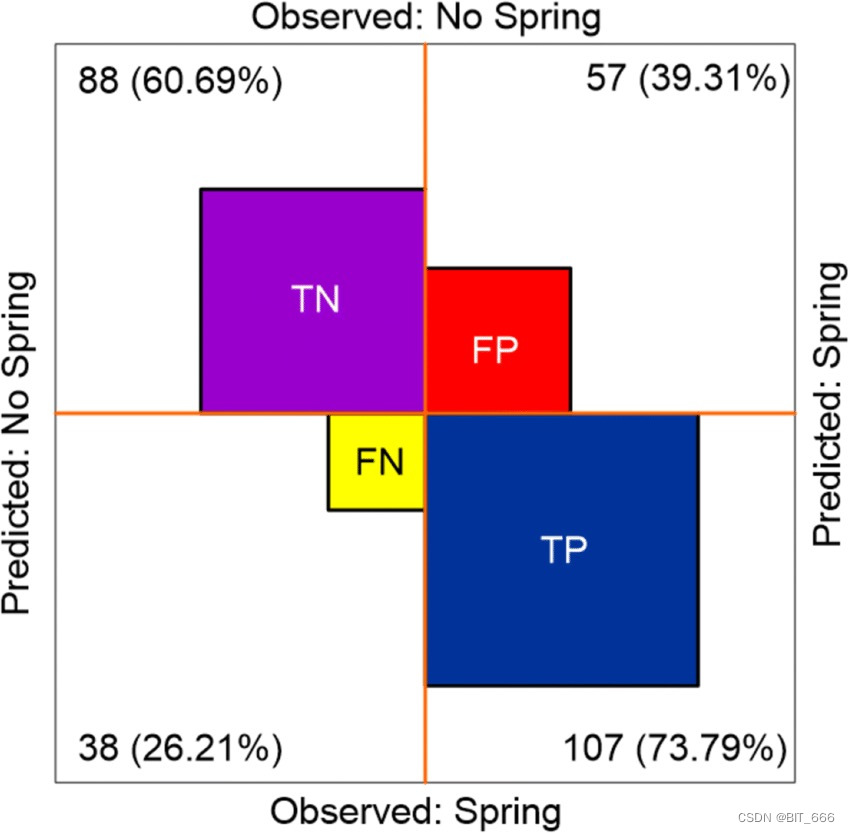
搜广推场景下最常见的就是 Ctr 2 分类场景,对于真实值 real 和预测值 pre 分别有 0 和 1 两种可能,从而最终 2x2 产生 4 种可能性:
- TP 真正率 对的预测对,即 1 预测为 1,在图中体现为观察与预测均为 Spring
- FP 假正率 错的预测对,即 0 预测为 1,在图中体现为 NoSpring 预测为 Spring
- FN 假负率 对的预测错,即 1 预测为 0,在图中体现为 Spring 预测为 NoSpring
- TN 真阴率 错的预测错,即 0 预测为 0,在图中体现为 NoSpring 预测为 NoSpring
整理后如下图所示:

根据上面提到的 TP、TN、FP、FN,有了上述几个指标的定义:
- Accuracy 准确率
即不管是0还是1,预测正确即可
- Precision 精度
即预测为1的样本中确实为1的样本比例,该指标只管预测为1的样本
- Recall 召回率
即样本中正样本有多少预测为正,该指标只管真实为1的样本
- F1-Score
平衡分数,用于定义 Precision 与 Recall 的调和平均数
- Fβ-Score
平衡分数,相比于 F1 更加灵活的调和平均数
通过调节 β 参数,可以使指标更偏向于不同的 metrics,β>1 例如 F2-Score 时,Recall 的权重高于 Precision,相反如果 β < 1例如 F0.5-Score 则 Precision 权重高于 Recall,这个把分子拆分开即可轻松得出结论。
AUC(Area Under Curve)被定义为ROC曲线下的面积,针对给定的一批对正负样本,用分类器分别预测一对正负样本,正样本预测概率大于负样本预测概率的概率即对应面积大小。
假定这批样本中存在 M 个正样本,N 个负样本,分类器为 Tk,则 AUC 计算公式如下:
其中 P 的计算根据学习器 Tk:
I 为示性函数:
上面是基础的 AUC 计算公式,由于需要对每一对正负样本预测概率进行比对,而实际场景下 M 与 N 都非常大从而造成运行速度缓慢的问题,优化后公式如下:
简单约分下:
这个公式也比较好理解,由于 AUC 并不关注分数而是关注正负样本的序,因此我们将全部预测样本排序,针对每个正样本,其序就代表了它超过了多少个样本的预测值,针对每个正样本可以得到总的序为:
但是由于每一次序的排列中,除了负样本外还有正样本,针对 rank 最高的正样本,其下有 M-1 个正样本,rank 第二高的,其下有 M-2 个正样本,依次类推,共有:
所以需要在 ∑ rank 的基础上再减去 (M-1)·M / 2,至于为什么有公式是 M·(M+1) 有的是 (M-1)·M,这个其实和你计算的序即 rank 是从 0 开始还是从 1 开始,如果从 1 开始,则等差数列求和公式结果就是 M·(M+1) 反之即为 (M-1)·M。

按照 M-1 即从 0 开始的 rank 计算:
按照 M+1 即从 1 开始的 rank 计算:
最后用最原始的方法计算一下,即将所有组合进行遍历:
这里 I 为上面提到的示性函数。
Tips:
这里还有一种特殊情况即有多个正负样本分值相同,此时排序后其 rank 值可以取所有相同分数的 rank 值平均代表其 rank,不过在大数据且 CTR 精度较高条件下,这个 rank 带来的影响可以近似忽略。
val rankResult = inputRdd.map { case (realLabel, preLabel, preScore) => {
// val preLabel = if (preScore > 0.5) "1" else "-1"
(realLabel, preLabel, preScore)
}
}.filter(_._3 >= 0)
rankResult.persist(StorageLevel.MEMORY_AND_DISK_SER_2)原始数据格式为 realLabel 和 preScore,这里可以通过 preScore + 阈值进行推理推断出 preLabel,即可得到三列元组的 RDD。实际计算过程中,你的 RDD 元祖只要有:
- Real Label 真实标签
- Predict Score 模型预测分
两个元素即可。
/*
计算相关数值
TP: 真正率 对的预测对
FP: 假正率 错的预测对
FN: 假负率 对的预测错
TN: 真阴率 错的预测错
*/
val threshold = 0.5
val dataTP = rankResult.filter(x => x._1 == 1 && x._3 >= threshold).cache()
val dataFP = rankResult.filter(x => x._1 != 1 && x._3 >= threshold).cache()
val dataFN = rankResult.filter(x => x._1 == 1 && x._3 < threshold).cache()
val dataTN = rankResult.filter(x => x._1 != 1 && x._3 < threshold).cache()
val TP = dataTP.count()
val FP = dataFP.count()
val FN = dataFN.count()
val TN = dataTN.count()
val total = TP + FN + FP + TN根据定义计算指标即可:
- TP 真正率 对的预测对
- FP 假正率 错的预测对
- FN 假负率 对的预测错
- TN 真阴率 错的预测错
Tips:
这里阈值常规为 0.5,大家也可以根据自己场景的需求进行阈值调整,对于 AUC 而言,其计算只关注序不关注分数,而 TP、TN 这些指标则与阈值分数相关。其次这里一定要加 persist,否则性能会慢很多。
基于 TP、FP、FN、TN 计算 Precision、Recall 与 Accuracy,最后计算 F1-Score,大家也可以自定义 β,实现 F-β 参数。
val Precision = if ((TP + FP) > 0) (TP * 1.0) / (TP + FP) else 0.0
val Recall = if ((TP + FN) > 0) (TP * 1.0) / (TP + FN) else 0.0
val Accuracy = if (total > 0) (TP + TN) * 1.0 / total else 0.0
val F1Score = if ((Precision + Recall) > 0.0) (2 * Precision * Recall) / (Precision + Recall) else 0.0
// sort by predict
val sorted = rankResult.sortBy(x => x._3)
val numTotal = sorted.count() // M + N
val numPositive = rankResult.filter(x => x._1 == 1).count // M
val numNegative = numTotal - numPositive // N
val sumRanks = sorted.zipWithIndex().filter(x => x._1._1 == 1).map(x => x._2 + 1).reduce(_ + _)
val AUC = if (numNegative > 0 & numPositive > 0) {
sumRanks * 1.0 / numPositive / numNegative - (numPositive + 1.0) / 2.0 / numNegative
} else 0.0直接根据 predict 分排序即可,这也再次呼应前面 Tips 提到的,AUC 只关注正负样本的序,最后套用约分后的公式即可:
其中 M = numPositive,N = numNegative。
AUC 评估的优点是:
- 对数据不平衡的情况有很好的适应能力,不受正负样本比例影响
- 评估结果简单,易于理解
- 不会受到分类器的阈值选择的影响
AUC 评估的缺点是:
- 不直接给出分类器的分类阈值
- 不适用于多分类问题
针对不同问题,除了 AUC 还有很多指标可供参考,大家需要根据自己的场景需求选择最优的评估指标,或者基于现有指标进行拓展。
一、获取当前时间1、current_date当前日期(年月日)Examples:SELECTcurrent_date;2、current_timestamp/now()当前日期(时间戳)Examples:SELECTcurrent_timestamp;二、从日期字段中提取时间1、year,month,day/dayofmonth,hour,minute,secondExamples:SELECTyear(now());其他的日期函数以此类推month:1day:12(当月的第几天)dayofmonth:12hour,minute,second:分别对应时分秒2、dayofweek、dayofm
我想在Controller上使用这个辅助方法。有什么办法可以实现吗? 最佳答案 可能不是一个好主意,但如果必须,请像这样包含帮助程序:classWhateverControllerincludeActionView::Helpers::NumberHelperdefshowrender:text=>number_with_precision(2342.234,:precision=>2)endend 关于ruby-on-rails-在rails3的Controller上使用number_
spark官方提供了两种方法实现从RDD转换到DataFrame。第一种方法是利用反射机制来推断包含特定类型对象的Schema,这种方式适用于对已知的数据结构的RDD转换; 第二种方法通过编程接口构造一个Schema,并将其应用在已知的RDD数据中。一、反射机制推断Schema实现反射机制Schema需要定义一个caseclass样例类,定义字段和属性,样例类的参数名称会被反射机制利用作为列名objectRddToDataFrameByReflect{//定义一个student样例类caseclassStudent(name:String,age:Int)defmain(args:Array[
我使用Kafka流媒体从KAFKA主题中消费。(KafkaDirect流)此主题中的数据每5分钟从另一个来源到达。现在,我需要处理每5分钟后到达的数据,并将其转换为SparkDataFrame。现在,流是数据的连续流。我的问题是,如何确定我已经完成了在Kafka主题中加载的第一组数据的阅读?(以便我可以将其转换为数据框架并开始我的工作)我知道我可以提及某个数字的批处理间隔(在JavastreamingContext中),但是即使那样,我也永远无法确定源将数据将数据推到主题的时间。欢迎任何建议。看答案如果我正确理解您的问题,您希望不创建批处理,直到阅读5分钟的所有数据。开箱即用的Spark不会提
问题:帖子的请求参数作为请求主体,而不是请求参数。我正在使用下面的此语法来调用SparkJavaWeb服务。http://localhost:8080/cumbcustomer?custId#4&amp;name=fredj"SparkJava告诉我:请求IP0:0:0:0:0:0:0:0:1请求动词post请求接收到:CUSTID#4&amp;name=fredj(-&gt;request.body.body())url接收:http://localhost:8080/cumbscustomer有什么想法为什么这些变量作为请求主体而不是请求参数的一部分出现?提前致谢,看答案利用request
首先,我想说我在理论上很厉害。我不喜欢抽象。在尝试使用它们之前,我想知道它们是如何工作的。我一直在到处寻找获取for-in循环的属性名称(而不是值)背后的简单理论。我将在代码中演示它,希望有人可以解释它是如何工作的……varobj={one:1,two:2,three:3};//Abasicobjectinstantiatedwith3publicproperties.for(varpropinobj){console.log(prop);//logs"one","two"and"three"???}我认为它会将prop变量评估为1、2和3,但它会记录实际的属性名称。我知道obj[pr
目录注:实验需要有安全策略配置、NAT配置基础一、防火墙用户管理重要知识点用户管理访问控制策略NGFW下一代防火墙AAA鉴别方式——认证用户认证的分类:上网用户上线流程:二、用户认证实验:实验拓扑先配置防火墙上接口和区域、地址对象配置NAT与安全策略确保内部PC能够上网对PC2进行MAC地址免认证的配置对PC3进行Portal认证的配置注:实验需要有安全策略配置、NAT配置基础传送门——》防火墙的基础配置与安全策略配置实验 传送门——》防火墙NAT配置实验一、防火墙用户管理重要知识点用户管理本地设备的用户管理基于远程认证服务器的用户管理访问控制策略IP不等于用户、端口不等于应用,传统防火墙基于
首先抱歉,我不知道如何称呼这些键(ENTER、F1、HOME等)。实际上,我正在创建一个输入搜索框,onkeyup调用了一个函数。当用户输入至少两个键时,调用我的函数并使用AJAX显示相关搜索结果。问题是当用户按下箭头键、HOME、END等时,我的ajax也会被调用,这是我不想要的。当专注于输入时按F5键重新加载页面不会重新加载页面,而是调用AJAX,这就是为什么这对我来说是个大问题。$('input[name=\'search\']').on(keyup,function(e){if($('input[name=\'search\']').val().length>=2){//cal
服务器端的代码在连接打开后立即发送一条消息(它向客户端发送初始配置/问候语)。以下代码在客户端:varsock=newWebSocket(url);sock.addEventListener('error',processError);sock.addEventListener('close',finish);sock.addEventListener('message',processMessage);我担心会丢失来自服务器的第一个与配置/问候相关的消息。理论上没有什么可以阻止它在message之前被接收到事件处理程序已设置。另一方面,实际上我从未想过。和AFAIKJavaScrip
目录SparkStreaming的核心是DStream一、DStream简介二.DStream编程模型三.DStream转换操作SparkStreaming的核心是DStream一、DStream简介1.Spark Streaming提供了一个高级抽象的流,即DStream(离散流)。2.DStream的内部结构是由一系列连续的RDD组成,每个RDD都是一小段由时间分隔开来的数据集。二.DStream编程模型三.DStream转换操作transform()1.在3个节点启动zookeeper集群服务$zkServer.shstart2.启动kafka(3个节点都要)$/opt/module/k