深度信念网络是一个生成模型,用来生成符合特定分布的样本。隐变量用来描述在可观测变量之间的高阶相关性。假如加入服从分布 𝑝(𝑣)的训练数据,通过训练得到一个深度信念网络。
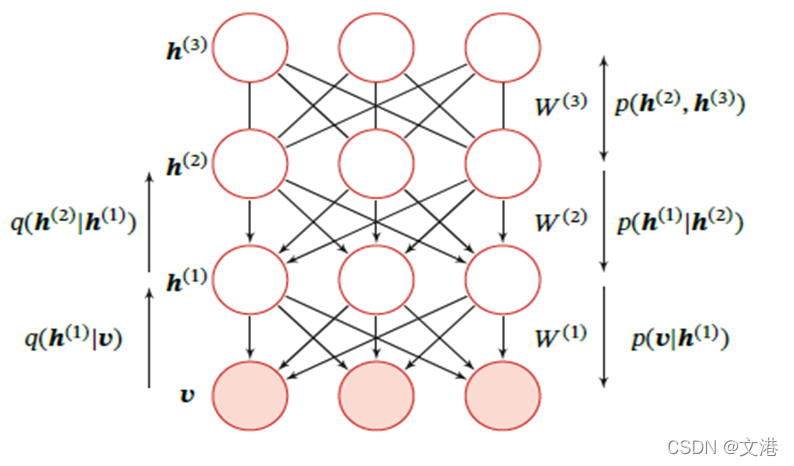
生成样本时,先在最顶两层进行足够多的吉布斯采样,在达到热平衡时生成样本ℎ^((𝐿−1)),然后依次计算下一层隐变量的分布。因为在给定上一层变量取值时,下一层的变量是条件独立的,故可独立采样。这样,从第𝐿−1层开始,自顶向下进行逐层采样,最终得到可观测层的样本。
深度信念网络最直接的训练方式是最大化可观测变量的边际分布𝑝(𝑣)在训练集上的似然 。但是在深度信念网络中,隐变量ℎ之间的关系十分复杂,由于“贡献度分配问题”,很难直接学习。即使对于简单的单层Sigmoid信念网络:
p ( v = 1 ∣ h ) = σ ( b + ω T h ) p(v=1 \mid h)=\sigma\left(b+\omega^{T} h\right) p(v=1∣h)=σ(b+ωTh)
在已知可观测变量时,其隐变量的联合后验概率𝑝(ℎ|𝑣)不再相互独立,因此很难估计所有隐变量的后验概率,早期深度信念网络的后验概率一般通过蒙特卡洛方法或变分方法来近似估计,但效率低,从而导致其参数学习比较困难。
为了有效训练深度信念网络,我们将每一层的Sigmoid信念网络转换为受限玻尔兹曼机,这样做的好处是隐变量的后验概率事相互独立的,从而可容易进行采样。这样,深度信念网络可看做多个受限玻尔兹曼机从下到上进行堆叠,第𝑙层受限玻尔兹曼机的隐层作为第𝑙+1受限玻尔兹曼机的可观测层。进一步,深度信念网络可采用逐层训练的方式来快速训练,即从最底层开始,每次只训练一层,直到最后一层。
深度信念网络的训练过程可分为逐层预训练和精调两个阶段,先通过逐层预训练将模型的参数初始化为较优的值,然后通过传统机器学习方法对参数进行精调。
采用逐层训练的方式,将深度信念网络的训练简化为对多个受限玻尔兹曼机的训练。具体的逐层训练过程为自下而上依次训练每一层的首先玻尔兹曼机。假设已训练好前𝑙−1层的受限玻尔兹曼机,可计算隐变量自下而上的条件概率:
p ( h ( i ) ∣ h ( i − 1 ) ) = σ ( b i + W ( i ) h ( i − 1 ) ) , 1 ≤ i ≤ ( l − 1 ) p\left(h^{(i)} \mid h^{(i-1)}\right)=\sigma\left(b^{i}+W^{(i)} h^{(i-1)}\right), 1 \leq i \leq(l-1) p(h(i)∣h(i−1))=σ(bi+W(i)h(i−1)),1≤i≤(l−1)
这样可按照
𝑣
=
h
(
0
)
→
⋯
→
h
(
𝑙
−
1
)
𝑣=ℎ^{(0)}→⋯→ℎ^{(𝑙−1)}
v=h(0)→⋯→h(l−1)的顺序生成一组
h
𝑙
−
1
ℎ^{𝑙−1}
hl−1的样本,记为
H
(
l
−
1
)
=
h
(
l
,
1
)
,
.
.
.
,
h
(
l
,
M
)
H^{(l-1)} = h^{(l,1)},...,h^{(l,M)}
H(l−1)=h(l,1),...,h(l,M)。然后将
h
(
𝑙
−
1
)
ℎ^{(𝑙−1)}
h(l−1) 和
h
(
𝑙
)
ℎ^{(𝑙)}
h(l)组成一个受限玻尔兹曼机,用
𝐻
(
𝑙
−
1
)
𝐻^{(𝑙−1)}
H(l−1)作为训练集充分训练第𝑙层的受限玻尔兹曼机.

大量实践表明,逐层预训练可以产生非常好的参数初始值,从而极大地降低了模型的学习难度。
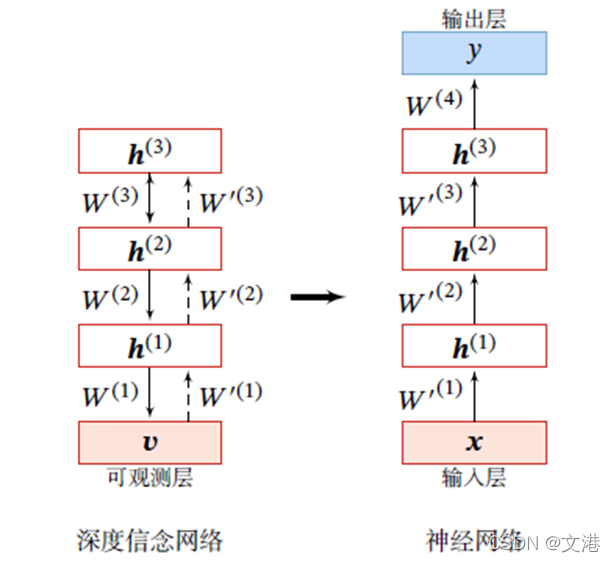
经过预训练,再结合具体的任务(监督或无监督学习),通过传统的全局学习算法对网络进行精调(fine-tuning),使模型收敛到更好的局部最优点。
作为生成模型的精调:除了顶层的受限玻尔兹曼机,其它层之间的权重可以被分为向上的认知权重(Recognition Weight) 𝑊 ∗ 𝑊^* W∗和向下的生成权重(Generative Weight)𝑊。认知权重用来计算后验概率,生成权重用来定义模型,认知权重初始值 𝑊(‘𝑙)=𝑊(𝑙)𝑇
深度信念网络一般采用 Contrastive Wake-Sleep算法进行精调:
1.Wake阶段:认知过程,通过外界输入(可观测变量)和向上的认知权重,计算每一层隐变量的后验概率并采样。修改下行的生成权重使得下一层的变量的后验概率最大。
2.Sleep阶段:生成过程,通过顶层的采样和向下的生成权重,逐层计算每一层的后验概率并采样。然后,修改向上的认知权重使得上一层变量的后验概率最大。
3.交替进行Wake和Sleep过程,直到收敛

作为判别模型的精调 :深度信念网络的一个应用是作为深度神经网络的预训练模型,提供神经网络的初始权重,这时只需要向上的认知权重,作为判别模型使用:
import sys
import numpy
numpy.seterr(all='ignore')
def sigmoid(x):
return 1. / (1 + numpy.exp(-x))
def softmax(x):
e = numpy.exp(x - numpy.max(x)) # prevent overflow
if e.ndim == 1:
return e / numpy.sum(e, axis=0)
else:
return e / numpy.array([numpy.sum(e, axis=1)]).T # ndim = 2
class DBN(object):
def __init__(self, input=None, label=None,\
n_ins=2, hidden_layer_sizes=[3, 3], n_outs=2,\
numpy_rng=None):
self.x = input
self.y = label
self.sigmoid_layers = []
self.rbm_layers = []
self.n_layers = len(hidden_layer_sizes) # = len(self.rbm_layers)
if numpy_rng is None:
numpy_rng = numpy.random.RandomState(1234)
assert self.n_layers > 0
# construct multi-layer
for i in range(self.n_layers):
# layer_size
if i == 0:
input_size = n_ins
else:
input_size = hidden_layer_sizes[i - 1]
# layer_input
if i == 0:
layer_input = self.x
else:
layer_input = self.sigmoid_layers[-1].sample_h_given_v()
# print('=============')
# construct sigmoid_layer
sigmoid_layer = HiddenLayer(input=layer_input,
n_in=input_size,
n_out=hidden_layer_sizes[i],
numpy_rng=numpy_rng,
activation=sigmoid)
self.sigmoid_layers.append(sigmoid_layer)
# construct rbm_layer
rbm_layer = RBM(input=layer_input,
n_visible=input_size,
n_hidden=hidden_layer_sizes[i],
W=sigmoid_layer.W, # W, b are shared
hbias=sigmoid_layer.b)
self.rbm_layers.append(rbm_layer)
# layer for output using Logistic Regression
self.log_layer = LogisticRegression(input=self.sigmoid_layers[-1].sample_h_given_v(),
label=self.y,
n_in=hidden_layer_sizes[-1],
n_out=n_outs)
# finetune cost: the negative log likelihood of the logistic regression layer
self.finetune_cost = self.log_layer.negative_log_likelihood()
def pretrain(self, lr=0.1, k=1, epochs=100):
# pre-train layer-wise
# print('pre-training')
for i in range(self.n_layers):
if i == 0:
layer_input = self.x
else:
layer_input = self.sigmoid_layers[i-1].sample_h_given_v(layer_input)
# print(layer_input)
rbm = self.rbm_layers[i]
for epoch in range(epochs):
rbm.contrastive_divergence(lr=lr, k=k, input=layer_input)
# cost = rbm.get_reconstruction_cross_entropy()
# print >> sys.stderr, \
# 'Pre-training layer %d, epoch %d, cost ' %(i, epoch), cost
# def pretrain(self, lr=0.1, k=1, epochs=100):
# # pre-train layer-wise
# for i in range(self.n_layers):
# rbm = self.rbm_layers[i]
# for epoch in range(epochs):
# layer_input = self.x
# for j in range(i):
# layer_input = self.sigmoid_layers[j].sample_h_given_v(layer_input)
# rbm.contrastive_divergence(lr=lr, k=k, input=layer_input)
# # cost = rbm.get_reconstruction_cross_entropy()
# # print >> sys.stderr, \
# # 'Pre-training layer %d, epoch %d, cost ' %(i, epoch), cost
def finetune(self, lr=0.1, epochs=100):
# print('finetune')
layer_input = self.sigmoid_layers[-1].sample_h_given_v()
# train log_layer
epoch = 0
done_looping = False
while (epoch < epochs) and (not done_looping):
self.log_layer.train(lr=lr, input=layer_input)
# self.finetune_cost = self.log_layer.negative_log_likelihood()
# print >> sys.stderr, 'Training epoch %d, cost is ' % epoch, self.finetune_cost
lr *= 0.95
epoch += 1
def predict(self, x):
layer_input = x
for i in range(self.n_layers):
sigmoid_layer = self.sigmoid_layers[i]
# rbm_layer = self.rbm_layers[i]
layer_input = sigmoid_layer.output(input=layer_input)
out = self.log_layer.predict(layer_input)
return out
class HiddenLayer(object):
def __init__(self, input, n_in, n_out,\
W=None, b=None, numpy_rng=None, activation=numpy.tanh):
if numpy_rng is None:
numpy_rng = numpy.random.RandomState(1234)
if W is None:
a = 1. / n_in
initial_W = numpy.array(numpy_rng.uniform( # initialize W uniformly
low=-a,
high=a,
size=(n_in, n_out)))
W = initial_W
if b is None:
b = numpy.zeros(n_out) # initialize bias 0
self.numpy_rng = numpy_rng
self.input = input
self.W = W
self.b = b
self.activation = activation
def output(self, input=None):
if input is not None:
self.input = input
linear_output = numpy.dot(self.input, self.W) + self.b
return (linear_output if self.activation is None
else self.activation(linear_output))
def sample_h_given_v(self, input=None):
if input is not None:
self.input = input
v_mean = self.output()
# print('v_mean:\n',v_mean)
h_sample = self.numpy_rng.binomial(size=v_mean.shape,
n=1,
p=v_mean)
# print('h_sample:\n',h_sample)
return h_sample
class RBM(object):
def __init__(self, input=None, n_visible=2, n_hidden=3, \
W=None, hbias=None, vbias=None, numpy_rng=None):
self.n_visible = n_visible # num of units in visible (input) layer
self.n_hidden = n_hidden # num of units in hidden layer
if numpy_rng is None:
numpy_rng = numpy.random.RandomState(1234) # 使用RandomState获得随机数生成器。
if W is None:
a = 1. / n_visible
initial_W = numpy.array(numpy_rng.uniform( # initialize W uniformly
low=-a,
high=a,
size=(n_visible, n_hidden))) # 生成权重矩阵
W = initial_W
if hbias is None:
hbias = numpy.zeros(n_hidden) # initialize h bias 0
if vbias is None:
vbias = numpy.zeros(n_visible) # initialize v bias 0
self.numpy_rng = numpy_rng
self.input = input
self.W = W
self.hbias = hbias
self.vbias = vbias
# self.params = [self.W, self.hbias, self.vbias]
def contrastive_divergence(self, lr=0.1, k=1, input=None):
if input is not None:
self.input = input
''' CD-k '''
ph_mean, ph_sample = self.sample_h_given_v(self.input)
chain_start = ph_sample
for step in range(k):
if step == 0:
nv_means, nv_samples,\
nh_means, nh_samples = self.gibbs_hvh(chain_start)
else:
nv_means, nv_samples,\
nh_means, nh_samples = self.gibbs_hvh(nh_samples)
# nv_means, nv_samples, nh_means, nh_samples = self.gibbs_hvh(chain_start)
# for _ in range(1, k):
# nv_means, nv_samples, nh_means, nh_samples = self.gibbs_hvh(nh_samples)
# chain_end = nv_samples
self.W += lr * (numpy.dot(self.input.T, ph_sample)
- numpy.dot(nv_samples.T, nh_means))
self.vbias += lr * numpy.mean(self.input - nv_samples, axis=0)
self.hbias += lr * numpy.mean(ph_sample - nh_means, axis=0)
# cost = self.get_reconstruction_cross_entropy()
# return cost
def sample_h_given_v(self, v0_sample):
h1_mean = self.propup(v0_sample) #
h1_sample = self.numpy_rng.binomial(size=h1_mean.shape, # discrete: binomial 二项分布
n=1,
p=h1_mean)
return [h1_mean, h1_sample]
def sample_v_given_h(self, h0_sample):
v1_mean = self.propdown(h0_sample)
v1_sample = self.numpy_rng.binomial(size=v1_mean.shape, # discrete: binomial
n=1,
p=v1_mean)
return [v1_mean, v1_sample]
def propup(self, v):
# 返回隐藏层被激活的概率,应该是一个矩阵,对应的是每一个神经元被激活的概率
pre_sigmoid_activation = numpy.dot(v, self.W) + self.hbias
return sigmoid(pre_sigmoid_activation)
def propdown(self, h):
pre_sigmoid_activation = numpy.dot(h, self.W.T) + self.vbias
return sigmoid(pre_sigmoid_activation)
def gibbs_hvh(self, h0_sample):
v1_mean, v1_sample = self.sample_v_given_h(h0_sample)
h1_mean, h1_sample = self.sample_h_given_v(v1_sample)
return [v1_mean, v1_sample, h1_mean, h1_sample]
def get_reconstruction_cross_entropy(self):
pre_sigmoid_activation_h = numpy.dot(self.input, self.W) + self.hbias
sigmoid_activation_h = sigmoid(pre_sigmoid_activation_h)
pre_sigmoid_activation_v = numpy.dot(sigmoid_activation_h, self.W.T) + self.vbias
sigmoid_activation_v = sigmoid(pre_sigmoid_activation_v)
cross_entropy = - numpy.mean(
numpy.sum(self.input * numpy.log(sigmoid_activation_v) +
(1 - self.input) * numpy.log(1 - sigmoid_activation_v),
axis=1))
return cross_entropy
def reconstruct(self, v):
h = sigmoid(numpy.dot(v, self.W) + self.hbias)
reconstructed_v = sigmoid(numpy.dot(h, self.W.T) + self.vbias)
return reconstructed_v
class LogisticRegression(object):
def __init__(self, input, label, n_in, n_out):
self.x = input
self.y = label
self.W = numpy.zeros((n_in, n_out)) # initialize W 0
self.b = numpy.zeros(n_out) # initialize bias 0
def train(self, lr=0.1, input=None, L2_reg=0.00):
if input is not None:
self.x = input
p_y_given_x = softmax(numpy.dot(self.x, self.W) + self.b)
d_y = self.y - p_y_given_x
self.W += lr * numpy.dot(self.x.T, d_y) - lr * L2_reg * self.W
self.b += lr * numpy.mean(d_y, axis=0)
def negative_log_likelihood(self):
sigmoid_activation = softmax(numpy.dot(self.x, self.W) + self.b)
cross_entropy = - numpy.mean(
numpy.sum(self.y * numpy.log(sigmoid_activation) +
(1 - self.y) * numpy.log(1 - sigmoid_activation),
axis=1))
return cross_entropy
def predict(self, x):
return softmax(numpy.dot(x, self.W) + self.b)
def test_dbn(pretrain_lr=0.1, pretraining_epochs=1000, k=1, \
finetune_lr=0.1, finetune_epochs=200):
x = numpy.array([[1,1,1,0,0,0],
[1,0,1,0,0,0],
[1,1,1,0,0,0],
[0,0,1,1,1,0],
[0,0,1,1,0,0],
[0,0,1,1,1,0]])
y = numpy.array([[1, 0],
[1, 0],
[1, 0],
[0, 1],
[0, 1],
[0, 1]])
rng = numpy.random.RandomState(123)
# construct DBN
# print('construct DBN')
dbn = DBN(input=x, label=y, n_ins=6, hidden_layer_sizes=[3, 3], n_outs=2, numpy_rng=rng)
# pre-training (TrainUnsupervisedDBN)
# k是gibbs的次数
dbn.pretrain(lr=pretrain_lr, k=1, epochs=pretraining_epochs)
# fine-tuning (DBNSupervisedFineTuning)
dbn.finetune(lr=finetune_lr, epochs=finetune_epochs)
# test
x = numpy.array([1, 1, 0, 0, 0, 0])
print(dbn.predict(x))
if __name__ == "__main__":
test_dbn()
[0.72344411 0.27655589]
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
是否可以在不实际下载文件的情况下检查文件是否存在?我有这么大的(~40mb)文件,例如:http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm这与ruby不严格相关,但如果发件人可以设置内容长度就好了。RestClient.get"http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm",headers:{"Content-Length"=>100} 最佳答案
我在这方面尝试了很多URL,在我遇到这个特定的之前,它们似乎都很好:require'rubygems'require'nokogiri'require'open-uri'doc=Nokogiri::HTML(open("http://www.moxyst.com/fashion/men-clothing/underwear.html"))putsdoc这是结果:/Users/macbookair/.rvm/rubies/ruby-2.0.0-p481/lib/ruby/2.0.0/open-uri.rb:353:in`open_http':404NotFound(OpenURI::HT
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
(本文是网络的宏观的概念铺垫)目录计算机网络背景网络发展认识"协议"网络协议初识协议分层OSI七层模型TCP/IP五层(或四层)模型报头以太网碰撞路由器IP地址和MAC地址IP地址与MAC地址总结IP地址MAC地址计算机网络背景网络发展 是最开始先有的计算机,计算机后来因为多项技术的水平升高,逐渐的计算机变的小型化、高效化。后来因为计算机其本身的计算能力比较的快速:独立模式:计算机之间相互独立。 如:有三个人,每个人做的不同的事物,但是是需要协作的完成。 而这三个人所做的事是需要进行协作的,然而刚开始因为每一台计算机之间都是互相独立的。所以前面的人处理完了就需要将数据
安全产品安全网关类防火墙Firewall防火墙防火墙主要用于边界安全防护的权限控制和安全域的划分。防火墙•信息安全的防护系统,依照特定的规则,允许或是限制传输的数据通过。防火墙是一个由软件和硬件设备组合而成,在内外网之间、专网与公网之间的界面上构成的保护屏障。下一代防火墙•下一代防火墙,NextGenerationFirewall,简称NGFirewall,是一款可以全面应对应用层威胁的高性能防火墙,提供网络层应用层一体化安全防护。生产厂家•联想网御、CheckPoint、深信服、网康、天融信、华为、H3C等防火墙部署部署于内、外网编辑额,用于权限访问控制和安全域划分。UTM统一威胁管理(Un
Linux操作系统——网络配置与SSH远程安装完VMware与系统后,需要进行网络配置。第一个目标为进行SSH连接,可以从本机到VMware进行文件传送,首先需要进行网络配置。1.下载远程软件首先需要先下载安装一款远程软件:FinalShell或者xhell7FinalShellxhell7FinalShell下载:Windows下载http://www.hostbuf.com/downloads/finalshell_install.exemacOS下载http://www.hostbuf.com/downloads/finalshell_install.pkg2.配置CentOS网络安装好
在神经网络方面,我完全是个初学者。我整天都在与ruby-fann和ai4r搏斗,不幸的是我没有任何东西可以展示,所以我想我会来到StackOverflow并询问这里的知识渊博的人。我有一组样本——每天都有一个数据点,但它们不符合我能够找出的任何明确模式(我尝试了几次回归)。不过,我认为看看是否有任何方法可以仅从日期预测future的数据会很好,而且我认为神经网络将是生成希望表达这种关系的函数的好方法.日期是DateTime对象,数据点是十进制数,例如7.68。我一直在将DateTime对象转换为float,然后除以10,000,000,000得到一个介于0和1之间的数字,我一直在将