桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。为了使桶排序更加高效,我们需要做到这两点:
同时,对于桶中元素的排序,选择何种比较排序算法对于性能的影响至关重要。
当输入的数据可以均匀的分配到每一个桶中。
当输入的数据被分配到了同一个桶中。
元素分布在桶中:
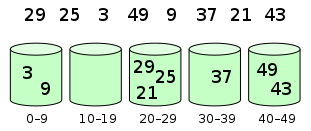
然后,元素在每个桶中排序:

function bucketSort(arr, bucketSize) {
if (arr.length === 0) {
return arr;
}
var i;
var minValue = arr[0];
var maxValue = arr[0];
for (i = 1; i < arr.length; i++) {
if (arr[i] < minValue) {
minValue = arr[i]; // 输入数据的最小值
} else if (arr[i] > maxValue) {
maxValue = arr[i]; // 输入数据的最大值
}
}
//桶的初始化
var DEFAULT_BUCKET_SIZE = 5; // 设置桶的默认数量为5
bucketSize = bucketSize || DEFAULT_BUCKET_SIZE;
var bucketCount = Math.floor((maxValue - minValue) / bucketSize) + 1;
var buckets = new Array(bucketCount);
for (i = 0; i < buckets.length; i++) {
buckets[i] = [];
}
//利用映射函数将数据分配到各个桶中
for (i = 0; i < arr.length; i++) {
buckets[Math.floor((arr[i] - minValue) / bucketSize)].push(arr[i]);
}
arr.length = 0;
for (i = 0; i < buckets.length; i++) {
insertionSort(buckets[i]); // 对每个桶进行排序,这里使用了插入排序
for (var j = 0; j < buckets[i].length; j++) {
arr.push(buckets[i][j]);
}
}
return arr;
}
public class BucketSort implements IArraySort {
private static final InsertSort insertSort = new InsertSort();
@Override
public int[] sort(int[] sourceArray) throws Exception {
// 对 arr 进行拷贝,不改变参数内容
int[] arr = Arrays.copyOf(sourceArray, sourceArray.length);
return bucketSort(arr, 5);
}
private int[] bucketSort(int[] arr, int bucketSize) throws Exception {
if (arr.length == 0) {
return arr;
}
int minValue = arr[0];
int maxValue = arr[0];
for (int value : arr) {
if (value < minValue) {
minValue = value;
} else if (value > maxValue) {
maxValue = value;
}
}
int bucketCount = (int) Math.floor((maxValue - minValue) / bucketSize) + 1;
int[][] buckets = new int[bucketCount][0];
// 利用映射函数将数据分配到各个桶中
for (int i = 0; i < arr.length; i++) {
int index = (int) Math.floor((arr[i] - minValue) / bucketSize);
buckets[index] = arrAppend(buckets[index], arr[i]);
}
int arrIndex = 0;
for (int[] bucket : buckets) {
if (bucket.length <= 0) {
continue;
}
// 对每个桶进行排序,这里使用了插入排序
bucket = insertSort.sort(bucket);
for (int value : bucket) {
arr[arrIndex++] = value;
}
}
return arr;
}
/**
* 自动扩容,并保存数据
*
* @param arr
* @param value
*/
private int[] arrAppend(int[] arr, int value) {
arr = Arrays.copyOf(arr, arr.length + 1);
arr[arr.length - 1] = value;
return arr;
}
}
function bucketSort($arr, $bucketSize = 5)
{
if (count($arr) === 0) {
return $arr;
}
$minValue = $arr[0];
$maxValue = $arr[0];
for ($i = 1; $i < count($arr); $i++) {
if ($arr[$i] < $minValue) {
$minValue = $arr[$i];
} else if ($arr[$i] > $maxValue) {
$maxValue = $arr[$i];
}
}
$bucketCount = floor(($maxValue - $minValue) / $bucketSize) + 1;
$buckets = array();
for ($i = 0; $i < $bucketCount; $i++) {
$buckets[$i] = [];
}
for ($i = 0; $i < count($arr); $i++) {
$buckets[floor(($arr[$i] - $minValue) / $bucketSize)][] = $arr[$i];
}
$arr = array();
for ($i = 0; $i < count($buckets); $i++) {
$bucketTmp = $buckets[$i];
sort($bucketTmp);
for ($j = 0; $j < count($bucketTmp); $j++) {
$arr[] = $bucketTmp[$j];
}
}
return $arr;
}
#include<iterator>
#include<iostream>
#include<vector>
using namespace std;
const int BUCKET_NUM = 10;
struct ListNode{
explicit ListNode(int i=0):mData(i),mNext(NULL){}
ListNode* mNext;
int mData;
};
ListNode* insert(ListNode* head,int val){
ListNode dummyNode;
ListNode *newNode = new ListNode(val);
ListNode *pre,*curr;
dummyNode.mNext = head;
pre = &dummyNode;
curr = head;
while(NULL!=curr && curr->mData<=val){
pre = curr;
curr = curr->mNext;
}
newNode->mNext = curr;
pre->mNext = newNode;
return dummyNode.mNext;
}
ListNode* Merge(ListNode *head1,ListNode *head2){
ListNode dummyNode;
ListNode *dummy = &dummyNode;
while(NULL!=head1 && NULL!=head2){
if(head1->mData <= head2->mData){
dummy->mNext = head1;
head1 = head1->mNext;
}else{
dummy->mNext = head2;
head2 = head2->mNext;
}
dummy = dummy->mNext;
}
if(NULL!=head1) dummy->mNext = head1;
if(NULL!=head2) dummy->mNext = head2;
return dummyNode.mNext;
}
void BucketSort(int n,int arr[]){
vector<ListNode*> buckets(BUCKET_NUM,(ListNode*)(0));
for(int i=0;i<n;++i){
int index = arr[i]/BUCKET_NUM;
ListNode *head = buckets.at(index);
buckets.at(index) = insert(head,arr[i]);
}
ListNode *head = buckets.at(0);
for(int i=1;i<BUCKET_NUM;++i){
head = Merge(head,buckets.at(i));
}
for(int i=0;i<n;++i){
arr[i] = head->mData;
head = head->mNext;
}
}
参考地址:
https://github.com/hustcc/JS-Sorting-Algorithm/blob/master/9.bucketSort.md
https://zh.wikipedia.org/wiki/%E6%A1%B6%E6%8E%92%E5%BA%8F
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
我需要用任何语言编写一个算法,根据3个因素对数组进行排序。我以度假村为例(如Hipmunk)。假设我想去度假。我想要最便宜的地方、最好的评论和最多的景点。但是,显然我找不到在所有3个中都排名第一的方法。Example(assumingthereare20importantattractions):ResortA:$150/night...98/100infavorablereviews...18of20attractionsResortB:$99/night...85/100infavorablereviews...12of20attractionsResortC:$120/night
我正在尝试按Rails相关模型中的字段进行排序。我研究的所有解决方案都没有解决如果相关模型被另一个参数过滤?元素模型classItem相关模型:classPriority我正在使用where子句检索项目:@items=Item.where('company_id=?andapproved=?',@company.id,true).all我需要按相关表格中的“位置”列进行排序。问题在于,在优先级模型中,一个项目可能会被多家公司列出。因此,这些职位取决于他们拥有的company_id。当我显示项目时,它是针对一个公司的,按公司内的职位排序。完成此任务的正确方法是什么?感谢您的帮助。PS-我
这个问题在这里已经有了答案:HashsyntaxinRuby[duplicate](1个回答)关闭5年前。我有一个Recipe,其中包含以下未通过lint测试的代码:service'apache'dosupports:status=>true,:restart=>true,:reload=>trueend失败并出现错误:UsethenewRuby1.9hashsyntax.supports:status=>true,:restart=>true,:reload=>true不确定新语法是什么样的...有人可以帮忙吗?
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排
我正在运行Ubuntu11.10并像这样安装Ruby1.9:$sudoapt-getinstallruby1.9rubygems一切都运行良好,但ri似乎有空文档。ri告诉我文档是空的,我必须安装它们。我执行此操作是因为我读到它会有所帮助:$rdoc--all--ri现在,当我尝试打开任何文档时:$riArrayNothingknownaboutArray我搜索的其他所有内容都是一样的。 最佳答案 这个呢?apt-getinstallri1.8编辑或者试试这个:(非rvm)geminstallrdocrdoc-datardoc-da
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果
我有一个对象如下:[{:id=>2,:fname=>"Ron",:lname=>"XXXXX",:photo=>"XXX"},{:id=>3,:fname=>"Dain",:lname=>"XXXX",:photo=>"XXXXXXX"},{:id=>1,:fname=>"Bob",:lname=>"XXXXXX",:photo=>"XXXX"}]我想按fname排序,不区分大小写,所以它会导致编号:1,3,2我该如何排序?我正在尝试:@people.sort!{|x,y|y[:fname]x[:fname]}但这没有任何效果。 最佳答案
有人可以告诉我如何根据自定义字符串对嵌套数组进行排序吗?比如有没有办法排序:[['Red','Blue'],['Green','Orange'],['Purple','Yellow']]“橙色”、“黄色”,然后是“蓝色”?最终结果如下所示:[['Green','Orange'],['Purple','Yellow'],['Red','Blue']]它不是按字母顺序排序的。我很想知道我是否可以定义要排序的值以实现上述目标。 最佳答案 sort_by对于这种排序总是非常方便:a=[['Red','Blue'],['Green','Ora
我有以下现有的Dog对象数组,它们按age属性排序:classDogattr_accessor:agedefinitialize(age)@age=ageendenddogs=[Dog.new(1),Dog.new(4),Dog.new(10)]我现在想插入一条新的狗记录,并将它放在数组中的正确位置。假设我想插入这个对象:another_dog=Dog.new(8)我想把它插入到数组中,让它成为数组中的第三项。这是一个人为的示例,旨在演示我特别想如何将一个项目插入到现有的有序数组中。我意识到我可以创建一个全新的数组并重新对所有对象进行排序,但这不是我的目标。谢谢!