归并排序:是创建在归并操作上的一种有效的排序算法。算法是采用分治法(Divide and Conquer)的一个非常典型的应用,且各层分治递归可以同时进行。归并排序思路简单,速度仅次于快速排序,为稳定排序算法,一般用于对总体无序,但是各子项相对有序的数列。
归并排序是用分治思想,分治模式在每一层递归上有三个步骤:
归并排序的特性总结:
1. 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序题。
2. 时间复杂度:O(N*logN)
3. 空间复杂度:O(N)
4. 稳定性:稳定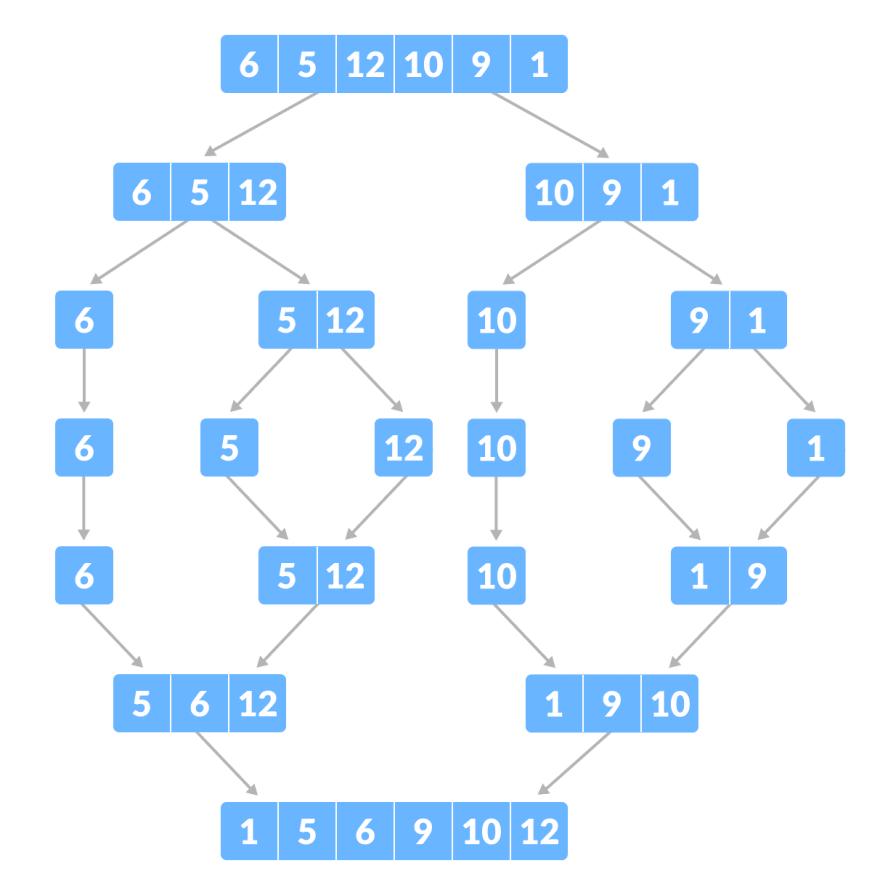
这是归并排序的主要概念。
归并排序有递归和非递归两种,我们首先来实现递归的代码
代码
//归并递归
void _MergeSore(int* arr, int left, int right, int* tmp)
{
//递归结束条件
if (left >= right)
return;
//int min = left + ((right - left) >> 1);
int min = (left + right) / 2;
//递归开始
_MergeSore(arr, left, min, tmp);
_MergeSore(arr, min + 1, right, tmp);
//排序开始
int begin1 = left, end1 = min;
int begin2 = min + 1, end2 = right;
int i = left;
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] < arr[begin2])
{
tmp[i++] = arr[begin1++];
/*i++;
begin1++;*/
}
if (arr[begin1] >= arr[begin2])
{
tmp[i++] = arr[begin2++];
/*i++;
begin2++;*/
}
}
while (begin1 <= end1)
{
tmp[i++] = arr[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = arr[begin2++];
}
//将建立的数组拷贝到原数组中
for (int i = 0; i <= right; i++)
{
arr[i] = tmp[i];
}
}
//归并排序
void MergeSort(int* arr, int n)
{
//先建立一个数组,用来存放排序的元素
int* tmp = (int*)malloc(sizeof(int) * (n));
if (tmp == NULL)
{
perror("perror,file");
return;
}
//归并函数实现
_MergeSore(arr, 0, n - 1, tmp);
//销毁新建数组,防止内存泄漏
free(tmp);
//防止野指针
tmp = NULL;
}下面是非递归的写法,非递归的思想与递归的思想几乎一样,大家可以自己想下过程。
void _MergeSoreNonR1(int* arr, int left, int right, int* tmp)
{
int gap = 1;
int i = 0;
while (gap <= right)
{
for (i = 0; i <= right; i += 2 * gap)
{
//[i,I+gap-1] [i+gap,2*gap-1]
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//printf(" %d", end2);
if (end1 > right)
end1 = right;
if (begin2 > right)
{
begin2 = right + 1;
end2 = right;
}
if (end2 > right)
end2 = right;
int index = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] < arr[begin2])
{
tmp[index++] = arr[begin1++];
}
if (arr[begin1] >= arr[begin2])
{
tmp[index++] = arr[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = arr[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = arr[begin2++];
}
}
for (i = 0; i <= right; i++)
{
arr[i] = tmp[i];
}
gap *= 2;
}
}
void MergeSortNonR(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc,file");
return;
}
_MergeSoreNonR1(arr, 0, n-1, tmp);
free(tmp);
tmp = NULL;
}下面来看计数排序
计数排序不用比较两个数的大小,它的做法是统计哪个元素出现的次数,然后通过这个元素出现的次数来排序。
计数算法只能使用在已知序列中的元素在0-k之间,且要求排序的复杂度在线性效率上。 Â 计数排序和基数排序很类似,都是非比较型排序算法。但是,它们的核心思想是不同的,基数排序主要是按照进制位对整数进行依次排序,而计数排序主要侧重于对有限范围内对象的统计。基数排序可以采用计数排序来实现。
计数排序的特性总结:
1. 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
2. 时间复杂度:O(MAX(N,范围))
3. 空间复杂度:O(范围)
4. 稳定性:稳定
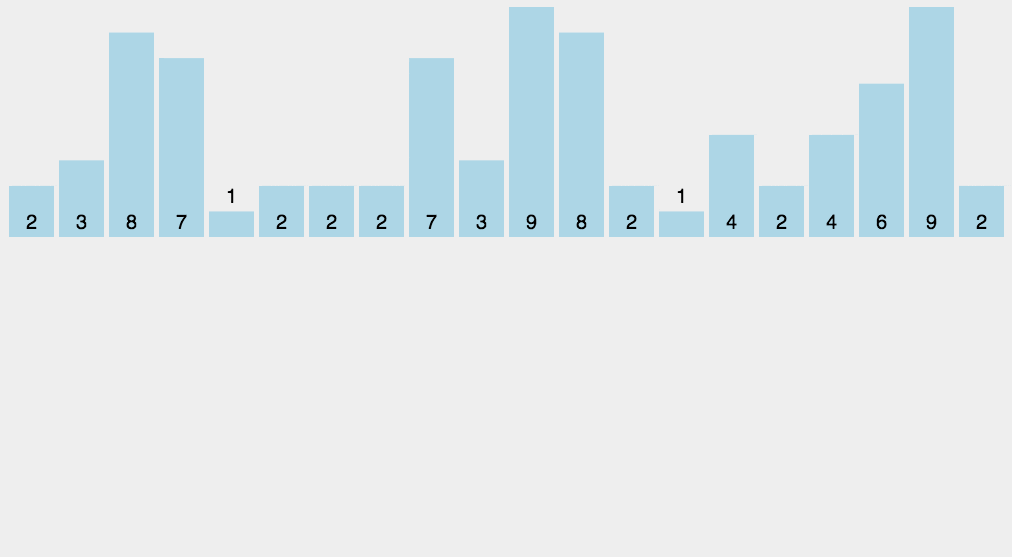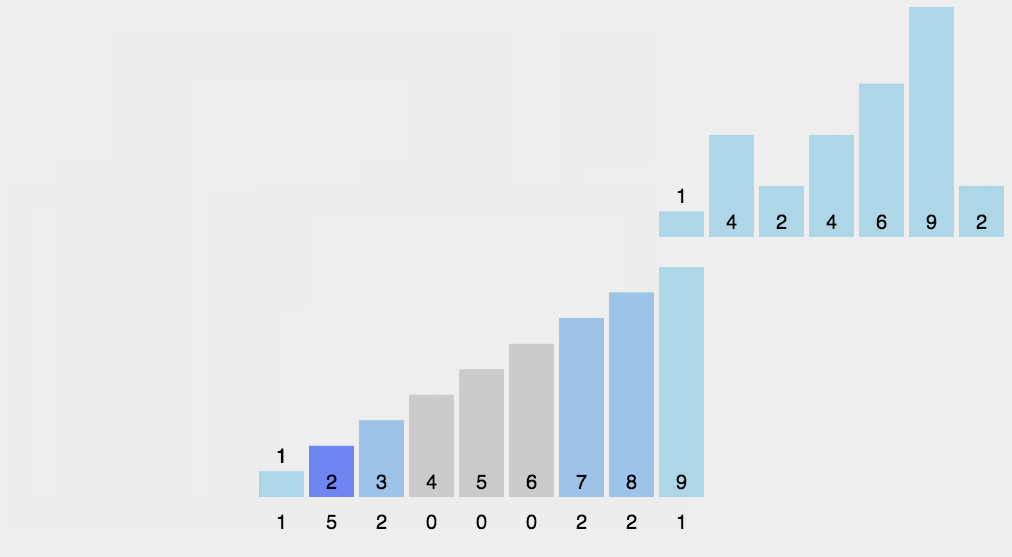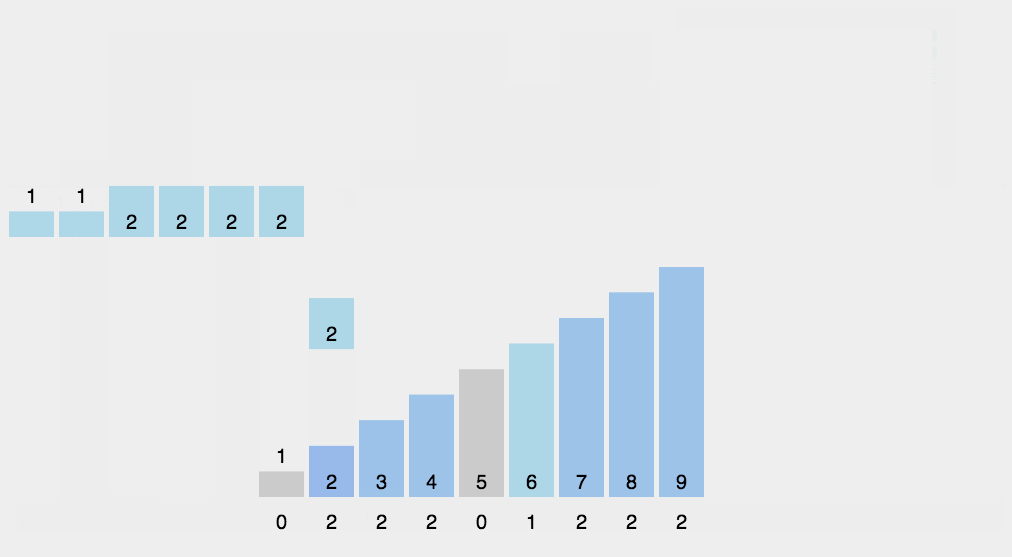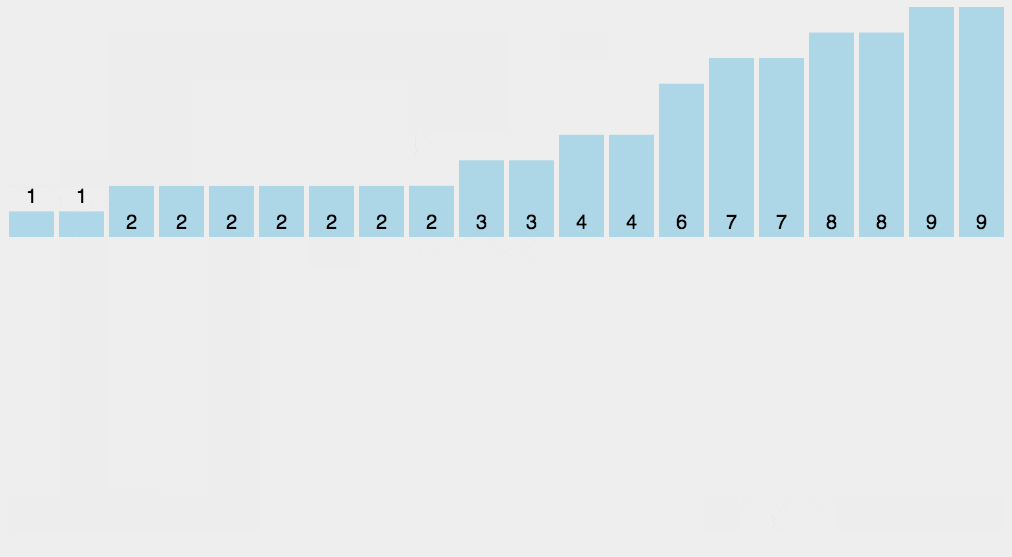
代码实现
void CountSort(int* arr, int n)
{
//确定数组开辟的大小
int max = arr[0], min = arr[0];
for (int i = 1; i < n; i++)
{
if (arr[i] > max)
max = arr[i];
if (arr[i] < min)
min = arr[i];
}
int range = max - min + 1;
//建立一个数组
int* count = (int*)malloc(sizeof(int) * range);
if (count == NULL)
{
perror("malloc file");
return NULL;
}
memset(count, 0, sizeof(int) * range);
for (int i = 0; i < n; i++)
{
count[arr[i]-min]++;
}
int j = 0;
for (int i = 0; i < n; i++)
{
while (count[i]--)
{
arr[j] = i+min;
j++;
}
}
free(count);
count = NULL;
}下面是一张八大排序的比较图
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭3年前。Improvethisquestion我正处于学习Ruby的阶段,我想查看一些小型库的源代码以了解它们是如何构建的。我不知道什么是小型图书馆,但希望SO能推荐一些易于理解的图书馆来学习。因此,如果有人知道一两个非常小的库,这是新手Rubyists学习的好例子,请推荐!我想使用Manveru'sInnatelib,因为它试图保持在2000LOC以下,但我还不熟悉其中经常使用的Ruby速记。也许大约100-5
由于匿名block和散列block看起来大致相同。我正在玩它。我做了一些严肃的观察,如下所示:{}.class#=>Hash好的,这很酷。空block被视为Hash。print{}.class#=>NilClassputs{}.class#=>NilClass为什么上面的代码和NilClass一样,下面的代码又显示了Hash?puts({}.class)#Hash#=>nilprint({}.class)#Hash=>nil谁能帮我理解上面发生了什么?我完全不同意@Lindydancer的观点你如何解释下面几行:print{}.class#NilClassprint[].class#A
我很难理解Ruby中sender和receiver的实际含义。它们一般是什么意思?到目前为止,我只是将它们理解为方法调用和获取其返回值的调用。但是,我知道我的理解还远远不够。谁能给我一个Ruby中发送者和接收者的具体解释? 最佳答案 面向对象中的一个核心概念是消息传递和早期概念化,这在很大程度上借鉴了计算的Actor模型。艾伦·凯(AlanKay)创造了面向对象一词并发明了最早的OO语言之一SmallTalk,他拥有voicedregretatusingatermwhichputthefocusonobjectsinsteadofo
rails新手。只是想了解\assests目录中的这两个文件。例如,application.js文件有如下行://=requirejquery//=requirejquery_ujs//=require_tree.我理解require_tree。只是将所有JS文件添加到当前目录中。根据上下文,我可以看出requirejquery添加了jQuery库。但是它从哪里得到这些jQuery库呢?我没有在我的Assets文件夹中看到任何jquery.js文件——或者直接在我的整个应用程序中没有看到任何jquery.js文件?同样,我正在按照一些说明安装TwitterBootstrap(http:
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
进行这种深度检查的最佳方法是什么:{:a=>1,:b=>{:c=>2,:f=>3,:d=>4}}.include?({:b=>{:c=>2,:f=>3}})#=>true谢谢 最佳答案 我想我从那个例子中明白了你的意思(不知何故)。我们检查子哈希中的每个键是否在超哈希中,然后检查这些键的对应值是否以某种方式匹配:如果值是哈希,则执行另一次深度检查,否则,检查值是否相等:classHashdefdeep_include?(sub_hash)sub_hash.keys.all?do|key|self.has_key?(key)&&ifs
我有一个Rails应用程序,它从WorldWeatherOnlineAPI获取响应。我正在使用rest-clientgem,响应采用JSON格式。我使用以下方法解析响应:parsed_response=JSON.parse(response)parsed_response显然是一个散列。我需要的数据是哈希内的字符串,数组内的哈希,另一个数组内的哈希,另一个哈希内的另一个哈希内的字符串。最内层的嵌套散列在["hourly"]中,这是一个由8个散列组成的数组,每个散列有20个键,拥有各种天气参数的字符串值。数组中的每个哈希值都是一天中的不同时间(预测是每三小时一次,3*8=24小时)。因此