手把手教你:基于粒子群优化算法(PSO)优化卷积神经网络(CNN)的文本分类
目录
本文主要介绍如何使用python搭建:一个基于深度残差网络(ResNet)的水果图像分类识别系统。
项目只是用水果分类作为抛砖引玉,其中包含了使用ResNet进行图像分类的相关代码。主要功能如下:
如各位童鞋需要更换训练数据,完全可以根据源码将图像和标注文件更换即可直接运行。
博主也参考过网上图像分类的文章,但大多是理论大于方法。很多同学肯定对原理不需要过多了解,只需要搭建出一个预测系统即可。
本文只会告诉你如何快速搭建一个基于ResNet的图像分类系统并运行,原理的东西可以参考其他博主。
也正是因为我发现网上大多的帖子只是针对原理进行介绍,功能实现的相对很少。
如果您有以上想法,那就找对地方了!
不多废话,直接进入正题!
首先我们来看下模型最终预测的水果类别的情况。本项目采用的数据集共有13种水果:香蕉、樱桃、无花果、芒果等等。博主英语不好就不在这献丑了,感兴趣的同学可以百度翻译



本项目开发IDE使用的是:Anaconda中的jupyter notebook,大家可以直接csdn搜索安装指南非常多,这里就不再赘述。
因为本项目基于TensorFlow因此需要以下环境:
环境都可以通过pip进行安装。如果只是想要使用博主训练的模型直接进行预测,不需要对模型重新训练的话,这边建议tensorflow安装cpu版的。
如果没使用过jupyter notebook通过pip安装包的同学可以参考如下:


点开“终端”,然后通过pip进行安装pandas,其他环境包也可以通过上面的方法安装。
环境安装好后就可以打开jupyter notebook开始愉快的执行代码了。由于代码众多,博客中就不放入最终代码了,有需要的童鞋可以在博客最下方找到下载地址。
其中按13类的水果分别建立文件夹放入对应水果图片:
这里拿芒果举例:
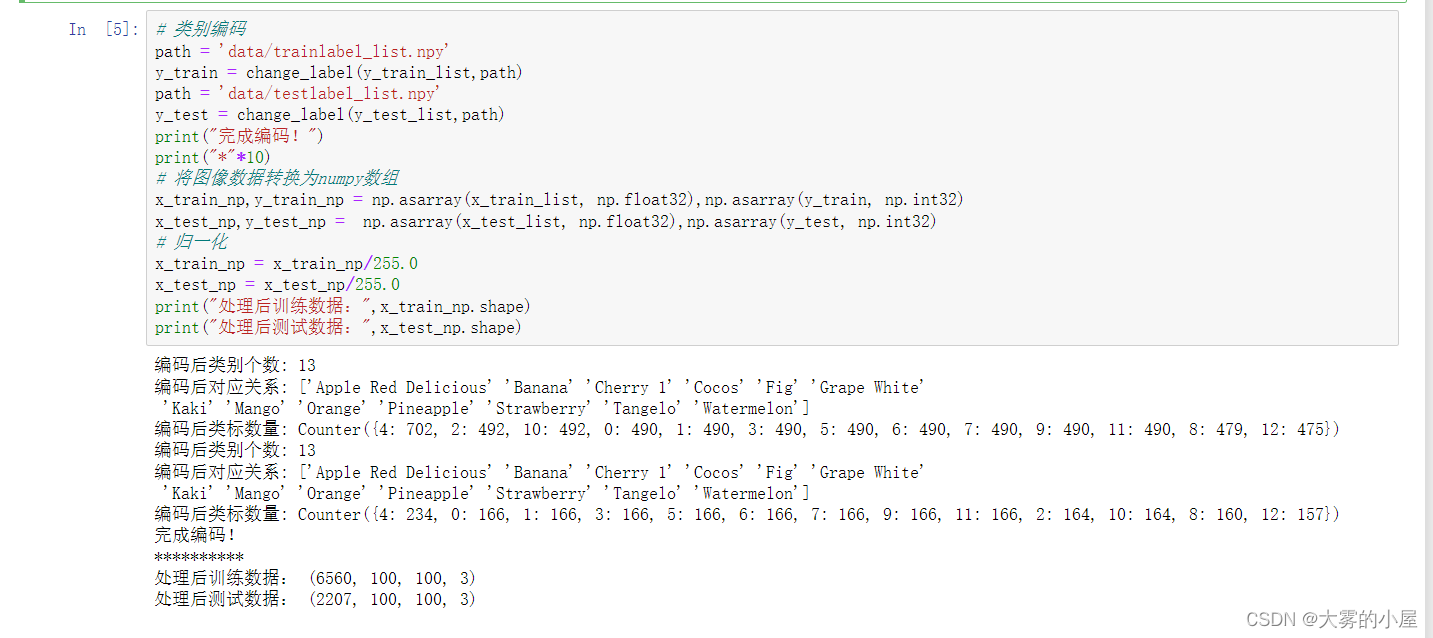
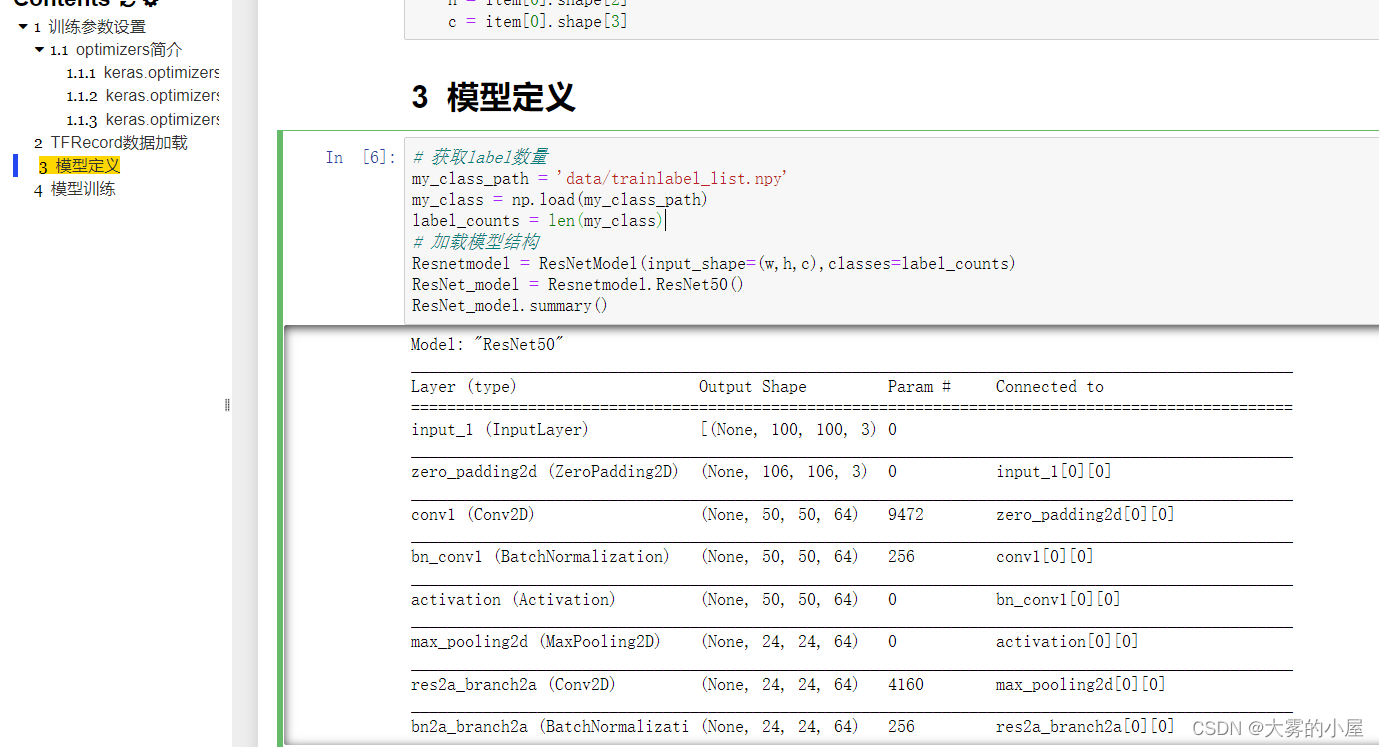
使用opencv2来读取图像生成:(100,100,3)的三通道图像数据。
# 定义图像处理函数
def read_img(path):
print("数据集地址:"+path)
imgs = []
labels = []
for root, dirs, files in tqdm(os.walk(path)):
for file in files:
# print(path+'/'+file+'/'+folder)
# 读取的图片
img = cv2.imread(os.path.join(root, file))
# 将读取的图片数据加载到imgs[]列表中
imgs.append(img)
# 将图片的label加载到labels[]中,与上方的imgs索引对应
labels.append(str(os.path.basename(root)))
return imgs,labels

from tensorflow.keras.callbacks import (
ReduceLROnPlateau,
EarlyStopping,
ModelCheckpoint,
TensorBoard)
# 编译模型来配置学习过程
ResNet_model.compile(optimizer=optimizer,loss='sparse_categorical_crossentropy',metrics=['accuracy'])
callbacks = [
# ReduceLROnPlateau(verbose=1),
# 提前结束解决过拟合
# EarlyStopping(patience=10, verbose=1),
# 保存模型
ModelCheckpoint(checkpoints + 'resnet_train_{epoch}.tf', monitor='accuracy',verbose=0,
# 当设置为True时,将只保存在验证集上性能最好的模型
save_best_only=True, save_weights_only=True,
# CheckPoint之间的间隔的epoch数
period=2),
TensorBoard(log_dir='logs')
]
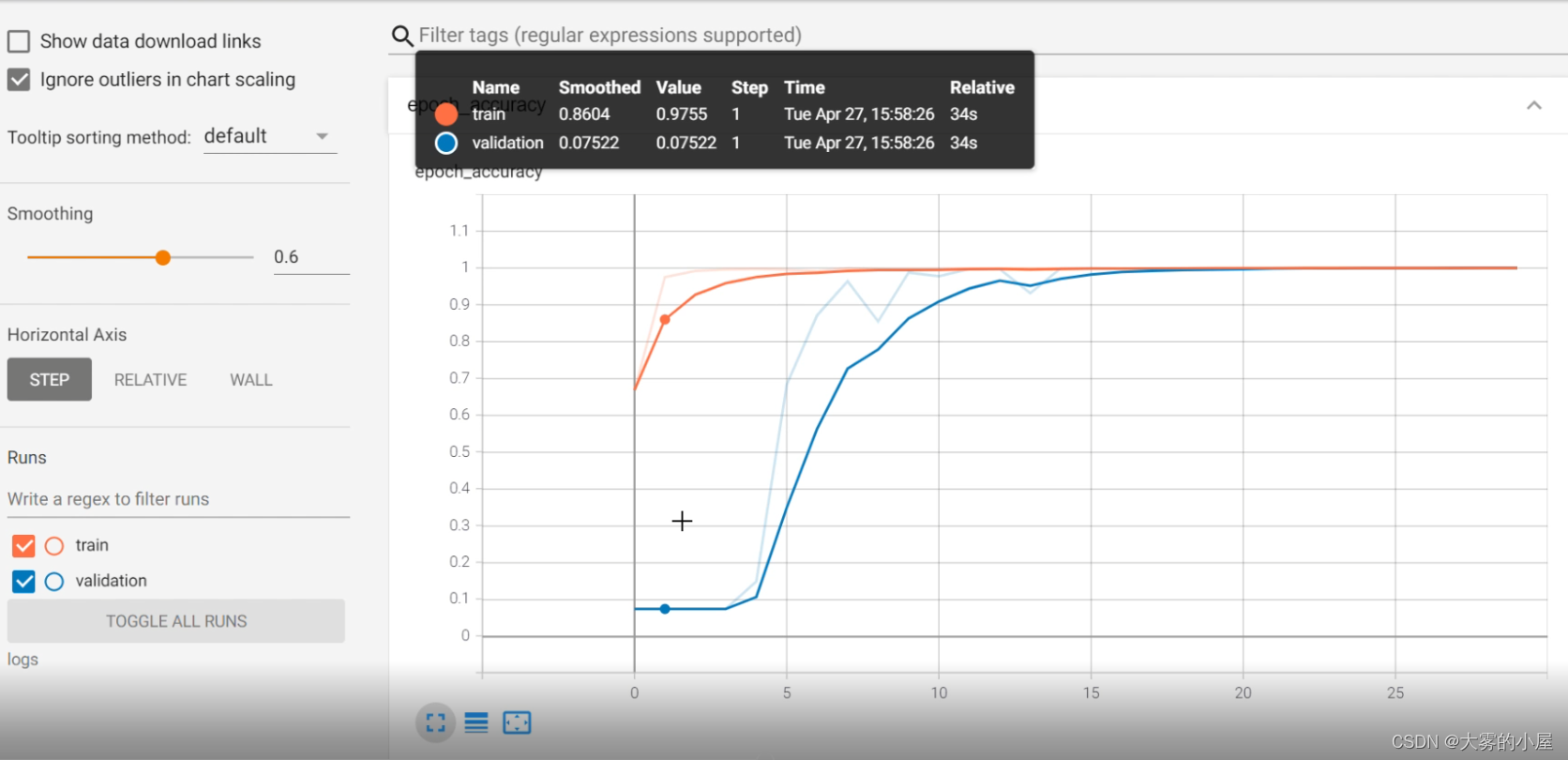
# 模型训练
history = ResNet_model.fit(data_train, epochs = epoch,callbacks=callbacks,validation_data = data_test)
./img/train/
和
./img/test/
下目录设置,一个类别的图片放入一个文件夹中,如下:
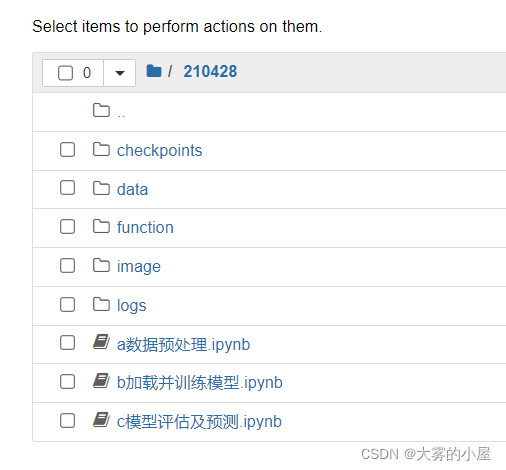
然后按顺序执行下述代码:
a数据预处理.ipynb
b加载并训练模型.ipynb
c模型评估及预测.ipynb
即可开始分类模型训练
由于项目代码量和数据集较大,感兴趣的同学可以下载完整代码,使用过程中如遇到任何问题可以在评论区进行评论,我都会一一解答。
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
Unity自动旋转动画1.开门需要门把手先动,门再动2.关门需要门先动,门把手再动3.中途播放过程中不可以再次进行操作觉得太复杂?查看我的文章开关门简易进阶版效果:如果这个门可以直接打开的话,就不需要放置"门把手"如果门把手还有钥匙需要旋转,那就可以把钥匙放在门把手的"门把手",理论上是可以无限套娃的可调整参数有:角度,反向,轴向,速度运行时点击Test进行测试自己写的代码比较垃圾,命名与结构比较拉,高手轻点喷,新手有类似的需求可以拿去做参考上代码usingSystem.Collections;usingSystem.Collections.Generic;usingUnityEngine;u
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我正在寻找用于Rails的优质管理插件。似乎大多数现有的插件/gem(例如“restful_authentication”、“acts_as_authenticated”)都围绕着self注册等展开。但是,我正在寻找一种功能齐全的基于管理/管理角色的解决方案——但不是简单地附加到另一个非基于角色的解决方案。如果我找不到,我想我会自己动手......只是不想重新发明轮子。 最佳答案 RyanBates最近做了两个关于授权的railscast(注意身份验证和授权之间的区别;身份验证检查用户是否如她所说的那样,授权检查用户是否有权访问资源
我正在根据Rakefile中的现有测试文件动态生成测试任务。假设您有各种以模式命名的单元测试文件test_.rb.所以我正在做的是创建一个以“测试”命名空间内的文件名命名的任务。使用下面的代码,我可以用raketest:调用所有测试require'rake/testtask'task:default=>'test:all'namespace:testdodesc"Runalltests"Rake::TestTask.new(:all)do|t|t.test_files=FileList['test_*.rb']endFileList['test_*.rb'].eachdo|task|n
我想要像“嘿那里”这样的东西变成,例如,#316583。我希望将任意长度的字符串“归结”为十六进制颜色。我不知道从哪里开始。我在想,每个字符串的MD5散列都是不同的-但如何将该散列转换为十六进制颜色数字? 最佳答案 你可以只取几位前几位:require'digest/md5'color=Digest::MD5.hexdigest('Mytext')[0..5] 关于ruby-如何使用Ruby基于字母数字字符串生成颜色?,我们在StackOverflow上找到一个类似的问题:
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3