目录

1、100万日活 * 没人每天产生日志100条 = 1亿条 (中型公司)
处理日志速度 1亿条 / (24 * 3600s ) = 1150条/s
1条日志 (0.5k - 2k 1k)
1150条 * 1k /s = 1m/s
高峰值 (中午小高峰 8 -12 ): 1m/s * 20倍 = 20m/s -40m/s
2、购买多少台服务器
服务器台数= 2 * (生产者峰值生产速率 * 副本数 / 100) + 1
= 2 * (20m/s * 2 /100) + 1
= 3 台
3、磁盘选择
kafka 按照顺序读写 机械硬盘和固态硬盘 顺序读写速度差不多
1亿条 * 1k = 100g
100g * 2个副本 * 3天 / 0.7 = 1t
建议三台服务器总的磁盘大小 大于1t
4、内存选择
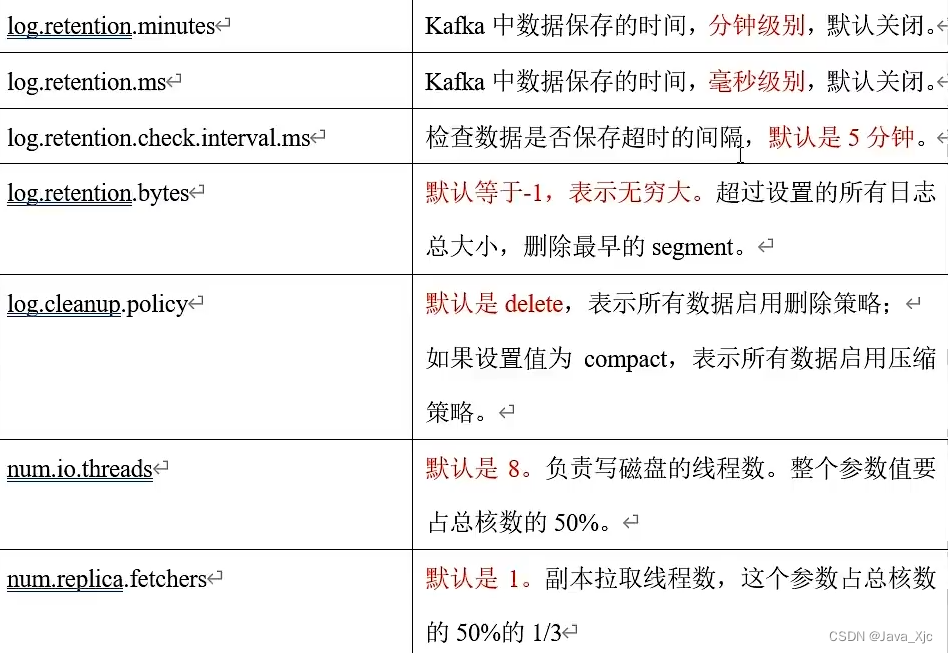
kafka 内存 = 堆内存(kafka 内部配置) + 页缓存(服务器内存)
1)堆内存 10 -15g
2)页缓存 segment (1g ) (分区数Leader(10) * 1g * 25%)/ 3 = 1g
一台服务器 10g + 1g
5、CPU选择
32cpu
6、网络选择











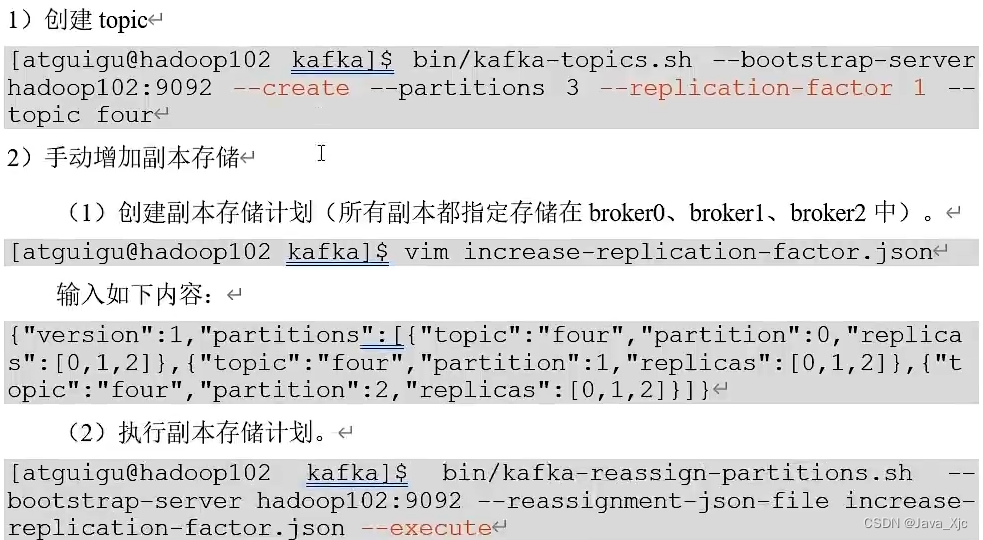
分区只能增加不能减少!

















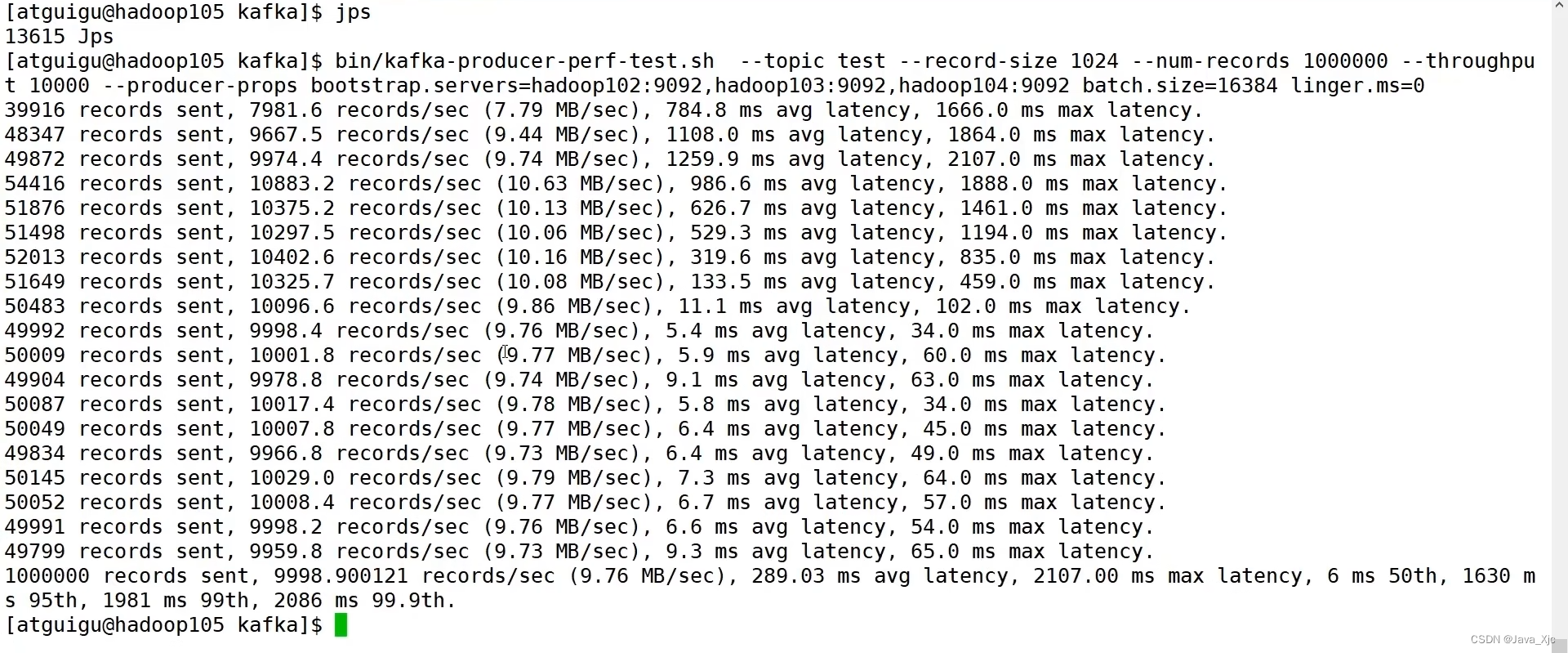
测试:
1、batch.size=16384 linger.ms=0 9.76 MB/sec
2、batch.size=32768 linger.ms=0 9.76 MB/sec
3、batch.size=4096 linger.ms=0 3.81 MB/sec
4、batch.size=4096 linger.ms=50 3.83 MB/sec
5、batch.size=4096 linger.ms=50 compression.type=snappy 3.77 MB/sec
6、batch.size=4096 linger.ms=50 compression.type=zstd 5.68 MB/sec
7、batch.size=4096 linger.ms=50 compression.type=gzip 5.90 MB/sec
8、batch.size=4096 linger.ms=50 compression.type=lz4 3.72 MB/sec
9、batch.size=4096 linger.ms=50 buffer.memory=67108864 3.76 MB/sec
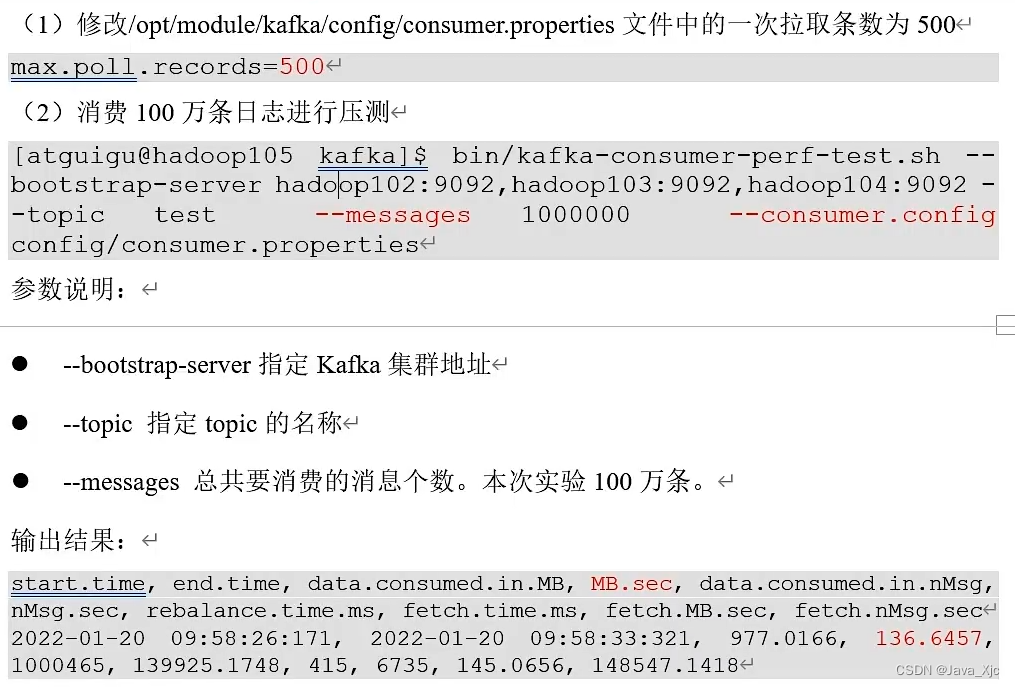


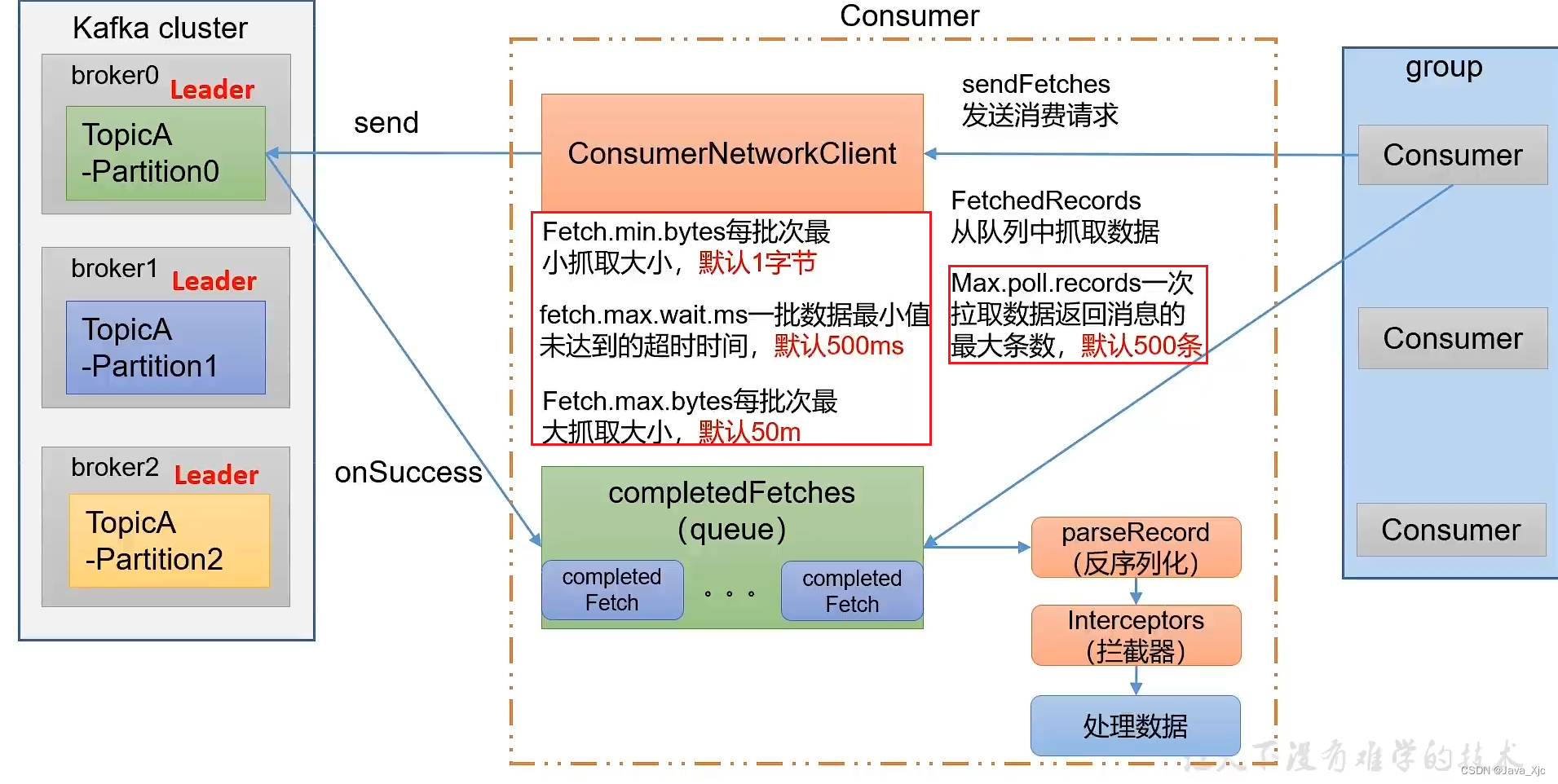
测试:
消费者 一次处理500条 81.2066m/s
消费者 一次处理2000条 138.0992m/s
消费者 一次处理2000条 fetch.max.bytes=104857600 145.2033m/s
一、解决痛点使用spring-kafka客户端,每次新增topic主题,都需要硬编码客户端并重新发布服务,操作麻烦耗时长。kafkaListener虽可以支持通配符消费topic,缺点是并发数需要手动改并且重启服务。对于业务逻辑相似场景,创建新主题动态监听可以用kafka-batch-starter组件二、组件能力1、新增topic名称为:auto.topic1(由于配置spring.kafka.consumer.prefix为auto,因此只有auto前缀的topic,才会被组件动态监听。)2、应用输出日志,监听到新增auto.topic1,并初始化客户端(主题刷新间隔为10s)3、发新的消
1.Zookeeper Zookeeper是 ApacheHadoop 的子项目,是一个树型的目录服务,支持变更推送,适合作为Dubbo服务的注册中心,工业强度较高。 Zookeeper的功能主要是它的树形节点来实现的。当有数据变化的时候或者节点过期的时候,会通过事件触发通知对应的客户端数据变化了,然后客户端再请求zookeeper获取最新数据,采用push-pull来做数据更新。服务注册和消费信息直接存储在zk树形节点上,集群下采用过半机制保证服务节点间一致性。 2.Nacos Nacos是 Alibaba 公司推出的开源工具,用于实现分布式系统的服务发现与配置管理。Nacos是Dub
我使用Kafka流媒体从KAFKA主题中消费。(KafkaDirect流)此主题中的数据每5分钟从另一个来源到达。现在,我需要处理每5分钟后到达的数据,并将其转换为SparkDataFrame。现在,流是数据的连续流。我的问题是,如何确定我已经完成了在Kafka主题中加载的第一组数据的阅读?(以便我可以将其转换为数据框架并开始我的工作)我知道我可以提及某个数字的批处理间隔(在JavastreamingContext中),但是即使那样,我也永远无法确定源将数据将数据推到主题的时间。欢迎任何建议。看答案如果我正确理解您的问题,您希望不创建批处理,直到阅读5分钟的所有数据。开箱即用的Spark不会提
Python3.6.9Flink1.15.2消费KafakaTopicPyFlink基础应用之kafka通过PyFlink作业处理Kafka数据1环境准备1.1启动kafka(1)启动zookeeperzkServer.shstart(2)启动kafkacd/usr/local/kafka/nohup./bin/kafka-server-start.sh./config/server.properties>>/tmp/kafkaoutput.log2>&1&或者./bin/kafka-server-start.sh-daemon./config/server0.properties(3)查看进
我们使用Kafka集群实时发送/接收消息。我们能够成功地向Kafka主题发布消息。现在我们希望在使用JavaScript的Web浏览器上运行的单页应用程序(SPA)上实时接收这些消息。是否可以直接从Kafka将消息推送到在任何著名浏览器上运行的最新版本的SPA?我找到了使用NodeJS实时接收消息的示例,但没有找到在Web浏览器上运行JavaScript的示例。 最佳答案 Kafka有Javascript客户端,但鉴于您的用例描述,我建议您在浏览器端javascript和Kafka之间使用REST或WebSocket代理。这将确保消
我一直在尝试创建需要转义格式的json数据的负载。我可以序列化该对象,但不确定如何对同一对象进行双重转义?我是否应该双重编码(marshal)我的对象以便它逃脱它?Input:{"new":{"Id":"1","Class":"23"}}Expected:{\"new\":{\"Id\":\"1\",\"Class\":\"23\"}} 最佳答案 将最后一行更改为fmt.Printf("%q",string(b))-这会导致格式为“转义字符串”。(或者如果你想存储转义字符串,```fmt.Sprintf``)https://play
我需要将RESTAPI调用的输出推送到KAFKA。Restapi返回json输出,其中包含支持信息以及数据输出到json.RawMessagetypeResponsestruct{RequestIDstring`json:"requestId"`Successbool`json:"success"`NextPageTokenstring`json:"nextPageToken,omitempty"`MoreResultbool`json:"moreResult,omitempty"`Errors[]struct{Codestring`json:"code"`Messagestring`
我正在为我的消费者使用sarama(https://github.com/Shopify/sarama/)和Kafka0.8.0。这是我的代码的样子:consumerLoop:for{select{caseevent:=我正在使用缓冲channel(c.sem)来控制一次可以运行多少个processJobgoroutine。这就是我控制消费者的并发/速度的方式。我在使用这种方法时遇到的问题是,如果我需要更改并发性,我必须关闭使用者并重新启动它(channel缓冲区大小是一个命令行标志)。我记录了已处理的偏移量,我必须查看我的日志以确定处理了哪些偏移量以及我希望消费者从哪里恢复。我想要一
我们使用Go的confluentkafka包测试了具有2和3个消费者的消费者组(知道我们将来可能会有更多消费者)。每个主题有10个分区,消息在所有消费者之间拆分。每个主题有5个分区,但不知何故只有一个消费者获取消息。知道为什么会出现这种行为吗? 最佳答案 您可以尝试使用此命令查看分区分配情况,并将结果添加到此处吗?bin/kafka-consumer-groups.sh--bootstrap-server:9092--describe--group--members--verbose默认情况下,Kafka使用范围分区方案,因此有时会
这是我正在运行的代码片段:err:=godotenv.Load()iferr!=nil{log.Fatal("Errorloading.envfile")}broker:=os.Getenv("BROKER")topic:=os.Getenv("TOPIC")username:=os.Getenv("USERNAME")password:=os.Getenv("PASSWORD")calocation:=os.Getenv("CALOCATION")p,err:=kafka.NewProducer(&kafka.ConfigMap{"metadata.broker.list":brok