我国高分辨率对地观测系统重大专项已全面启动,高空间、高光谱、高时间分辨率和宽地面覆盖于一体的全球天空地一体化立体对地观测网逐步形成,将成为保障国家安全的基础性和战略性资源。随着小卫星星座的普及,对地观测已具备多次以上的全球覆盖能力,遥感影像也不断被更深入的应用于矿产勘探、精准农业、城市规划、林业测量、军事目标识别和灾害评估。未来10年全球每天获取的观测数据将超过10PB,遥感大数据时代已然来临。
另一方面,随着无人机自动化能力的逐步升级,它被广泛的应用于多种领域,如航拍、农业、植保、灾难评估、救援、测绘、电力巡检等。但同时由于无人机飞行高度低、获取目标类型多、以及环境复杂等因素使得对无人机获取的数据处理越来越复杂。
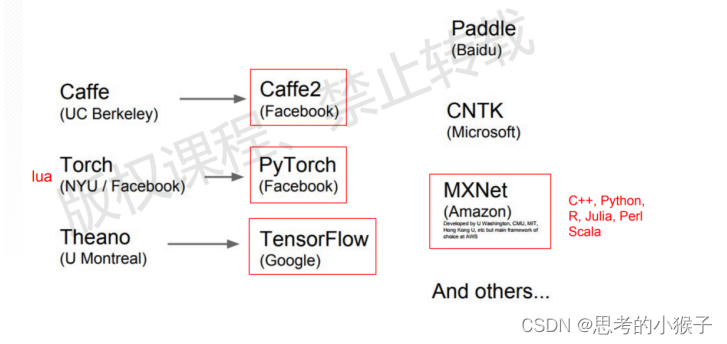
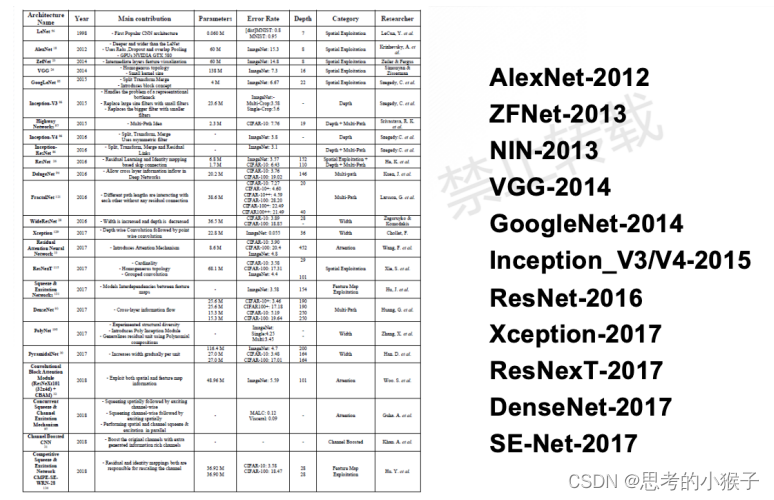
面对这些挑战,当前基于卷积神经网络的影像自动识别取得了令人印象深刻的结果。深度卷积网络采用“端对端”的特征学习,通过多层处理机制揭示隐藏于数据中的非线性特征,能够从大量训练集中自动学习全局特征(这种特征被称为“学习特征”),是其在遥感影像自动目标识别取得成功的重要原因,也标志特征模型从手工特征向学习特征转变。同时,当前以Transformer等结构为基础模型的检测模型也发展迅速,在许多应用场景下甚至超过了原有的以CNN为主的模型。虽然以PyTorch为主体的深度学习平台为使用卷积神经网络也提供程序框架。但卷积神经网络涉及到的数学模型和计算机算法都十分复杂、运行及处理难度很大,PyTorch平台的掌握也并不容易。为使广大学者能理解卷积神经网络背后的数学模型和计算机算法。
专题一:
深度卷积网络知识详解
专题二:
PyTorch应用与实践(遥感图像场景分类)
6.PyTorch图像分类任务讲解
7.不同超参数,如初始化,学习率对结果的影响
8.使用PyTorch搭建神经网络并实现手写数字的分类
9.使用PyTorch修改模型并提升分类模型表现
专题三:
卷积神经网络实践与目标检测
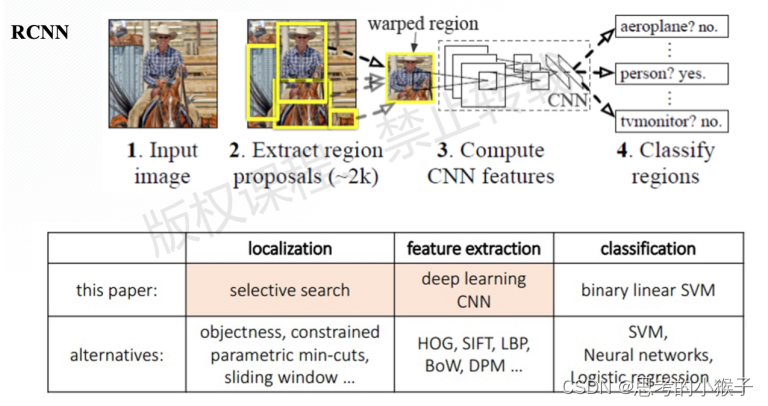
【FasterRCNN】
专题四:
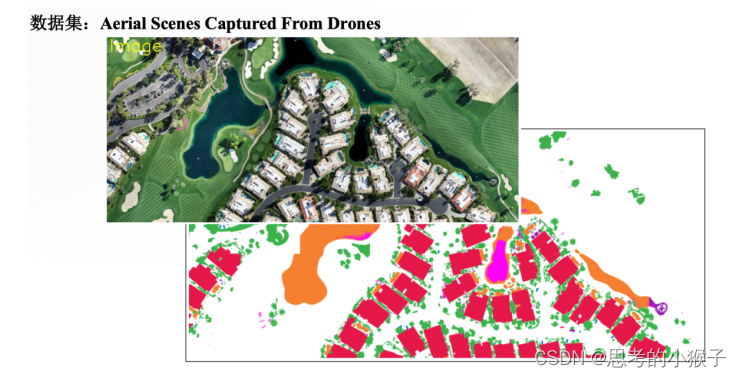
卷积神经网络的遥感影像目标检测任务案例
专题五:
Transformer与遥感影像目标检测
专题六:
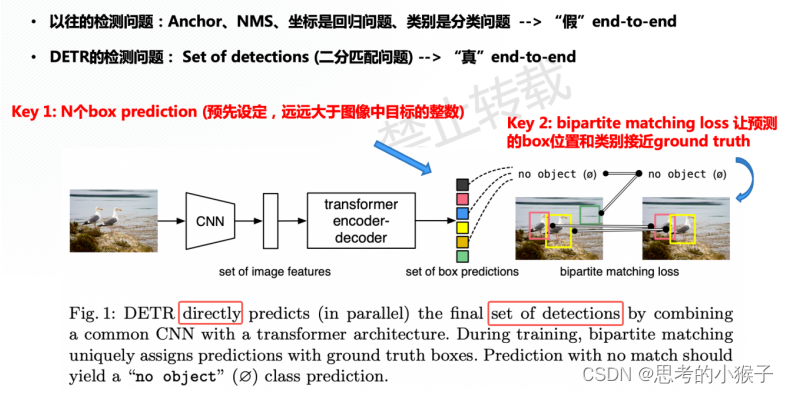
Transformer的遥感影像目标检测任务案例 【DETR】
专题七:
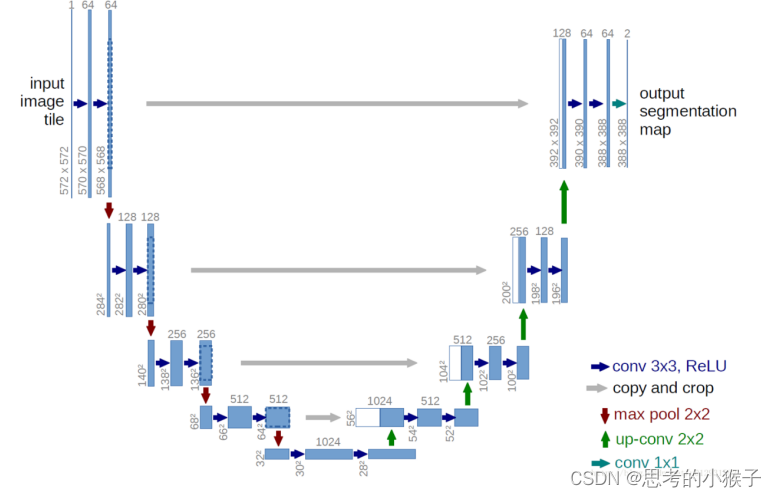
深度学习与遥感影像分割任务
案例

专题八:
深度学习下的ASL(机载激光扫描仪)点云数据语义分类任务的基本知识

专题九:
遥感影像问题探讨与深度学习优化技巧
 从CNN到Transformer:基于PyTorch的遥感影像、无人机影像的地物分类、目标检测、语义分割和点云分类 (qq.com)
从CNN到Transformer:基于PyTorch的遥感影像、无人机影像的地物分类、目标检测、语义分割和点云分类 (qq.com)
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
我正在寻找用于Rails的优质管理插件。似乎大多数现有的插件/gem(例如“restful_authentication”、“acts_as_authenticated”)都围绕着self注册等展开。但是,我正在寻找一种功能齐全的基于管理/管理角色的解决方案——但不是简单地附加到另一个非基于角色的解决方案。如果我找不到,我想我会自己动手......只是不想重新发明轮子。 最佳答案 RyanBates最近做了两个关于授权的railscast(注意身份验证和授权之间的区别;身份验证检查用户是否如她所说的那样,授权检查用户是否有权访问资源
我正在根据Rakefile中的现有测试文件动态生成测试任务。假设您有各种以模式命名的单元测试文件test_.rb.所以我正在做的是创建一个以“测试”命名空间内的文件名命名的任务。使用下面的代码,我可以用raketest:调用所有测试require'rake/testtask'task:default=>'test:all'namespace:testdodesc"Runalltests"Rake::TestTask.new(:all)do|t|t.test_files=FileList['test_*.rb']endFileList['test_*.rb'].eachdo|task|n
我想要像“嘿那里”这样的东西变成,例如,#316583。我希望将任意长度的字符串“归结”为十六进制颜色。我不知道从哪里开始。我在想,每个字符串的MD5散列都是不同的-但如何将该散列转换为十六进制颜色数字? 最佳答案 你可以只取几位前几位:require'digest/md5'color=Digest::MD5.hexdigest('Mytext')[0..5] 关于ruby-如何使用Ruby基于字母数字字符串生成颜色?,我们在StackOverflow上找到一个类似的问题:
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3
我刚刚开始按照包括AlexOtt在内的各种指南设置cedet。这是我的init文件中目前的内容。(require'cedet)(semantic-load-enable-code-helpers);;imenubreaksifIdon'tenablethis(global-semantic-highlight-func-mode1)(global-semantic-tag-folding-mode)我非常喜欢代码折叠,因为语义比hideshow等包更了解代码我想对ruby进行相同的折叠。我知道cedet还可以做其他事情,但我现在只是试一试。所以我在contrib/文件夹中看到了wi