作者:vivo 互联网数据库团队- Li Shihai
本文主要介绍无损压缩图片的概要流程和原理,以及Lepton无损压缩在前期调研中发现的问题和解决方案。
请拿出你的秒表计时,在15秒时间内找出下面图片的差异。

时间到了,你发现两张图片的差异了吗?
在上面的游戏中,你可能你并没有发现两张图片间有任何差异,而实际上它们一张是3.7MB的jpg格式的原图,另外一张是大小为485KB的jpg格式压缩图片,只是大小不同。你可能会有些生气,愤愤不平到这是欺骗,然而聪明的你很快在大脑中产生了一连串的疑问,这些问号让你层层揭开游戏的面纱,不在为愚弄而悔恨,反而从新知中获得快乐。
上面图片为何变小了?图片从3.7MB变成485KB是因为我使用了图片查看工具将原图另存成一张新的图片,在另存的过程中,有一个图片质量选择的参数,我选择了质量最低,保存后便生成了一张更小的图片。可是图片质量下降了,为什么看不出来呢?这就需要了解图片压缩的原理。
利用人眼的弱点。
人的视网膜上有两种细胞,视锥细胞和视杆细胞。视锥细胞用来感知颜色,视杆细胞用来感知亮度。而相对于颜色,我们对明暗的感知更明显。
因此可以采取对颜色信息进行压缩来减小图片的大小。
所以我们在图片压缩前会进行颜色空间的变换,JPEG图片通常会变换成YCbCr颜色空间,Y代表亮度,Cb蓝色色彩度,Cr红色色彩度,变换后我们更容易处理色彩部分。然后我们将一张图片切成一块块8*8的像素块,然后使用离散余弦转换算法(DCT)计算出高频区和低频区。
由于人眼对高频区的复杂信息不敏感,因此可以对这一部分进行压缩,这个过程叫量化。最后再将新的文件进行打包。这个流程下来就完成了图片的压缩。
基本流程如下图:

JPEG压缩有损。
在上面的流程中,在预测模块的颜色空间转换后,通过舍弃部分颜色浓度信息,提高压缩率。常见选项为4:2:0,经过这一步后原来需要8个数字表示的信息,现在只需要2个,直接抛弃了75%的Cb Cr信息,然而这一步骤是不可逆的,也就造成了图片压缩的有损。此外在熵编码模块,会进一步使用行程长度编码或Huffman编码进一步对图片信息进行压缩,而这一部分的压缩是无损的,是可逆的。
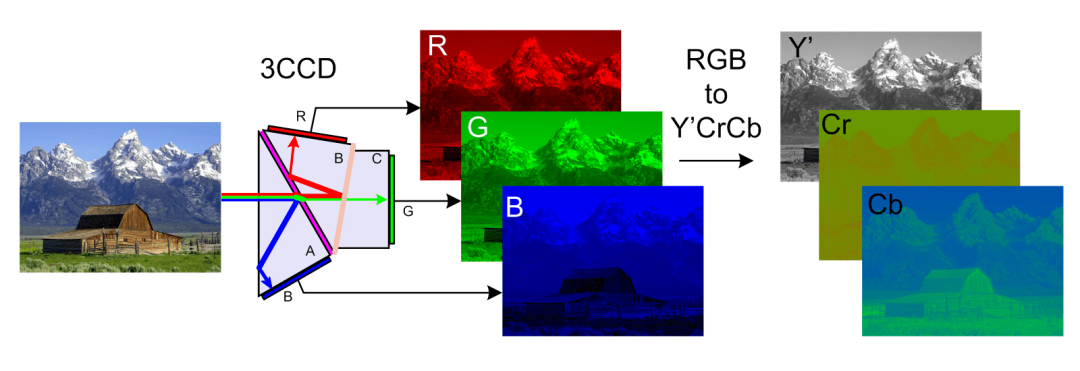
(YCbCr空间转换)
霍夫曼编码原理如下:
假如待编码的字符总共38个符号数据,对其进行统计,得到的符号和对应频度如下表:

首先,对所有符号按照频数大小排序,排序后如下图:

然后,选择两个频数最小的作为叶子节点,频数最小的作为左子节点,另外一个作为右子节点,根节点为两个叶子节点的频数之和。
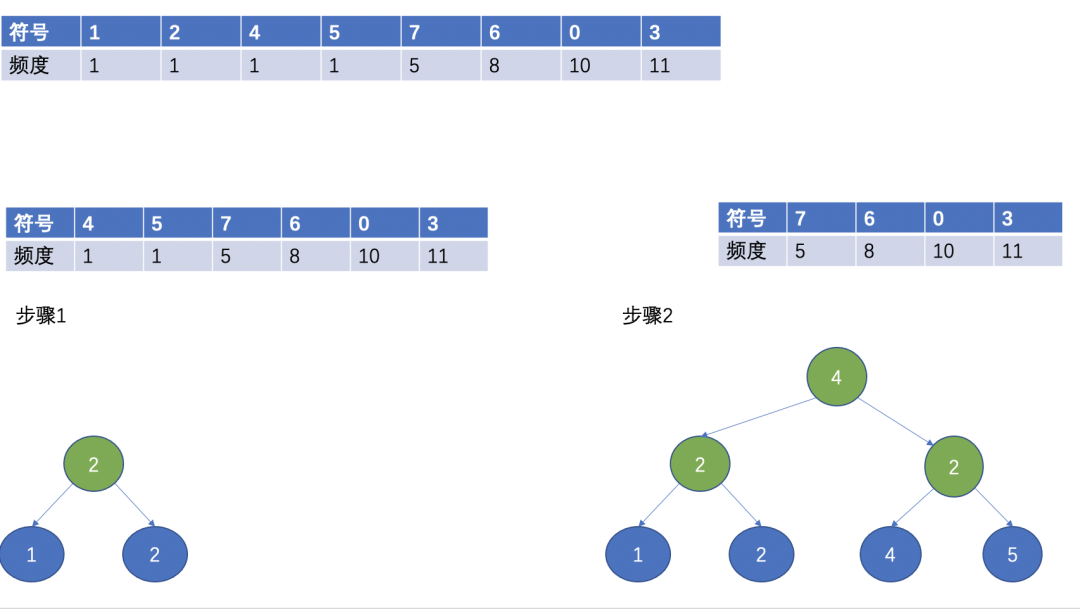
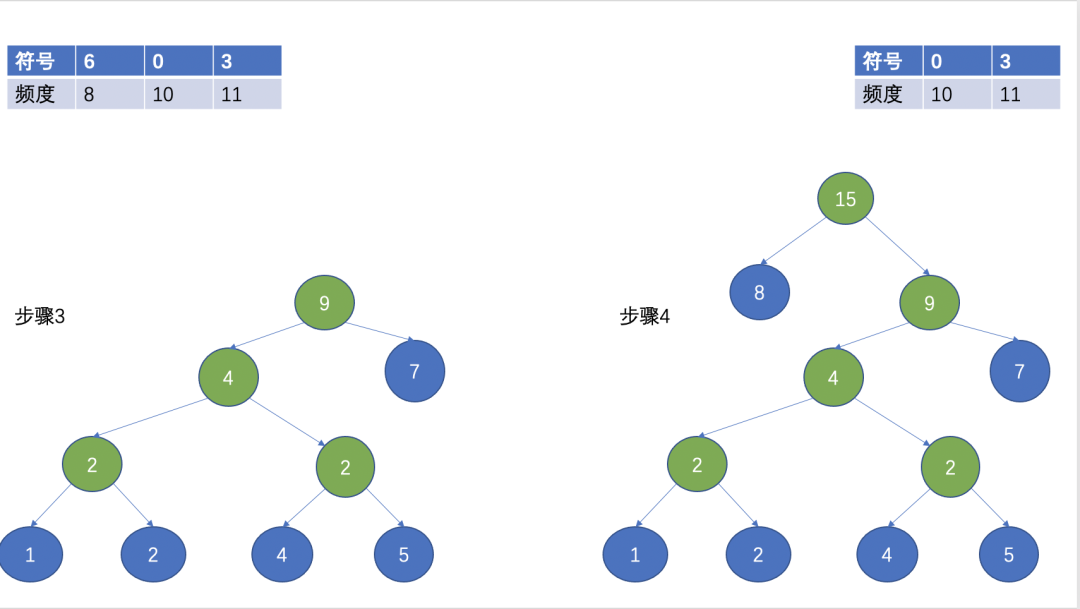
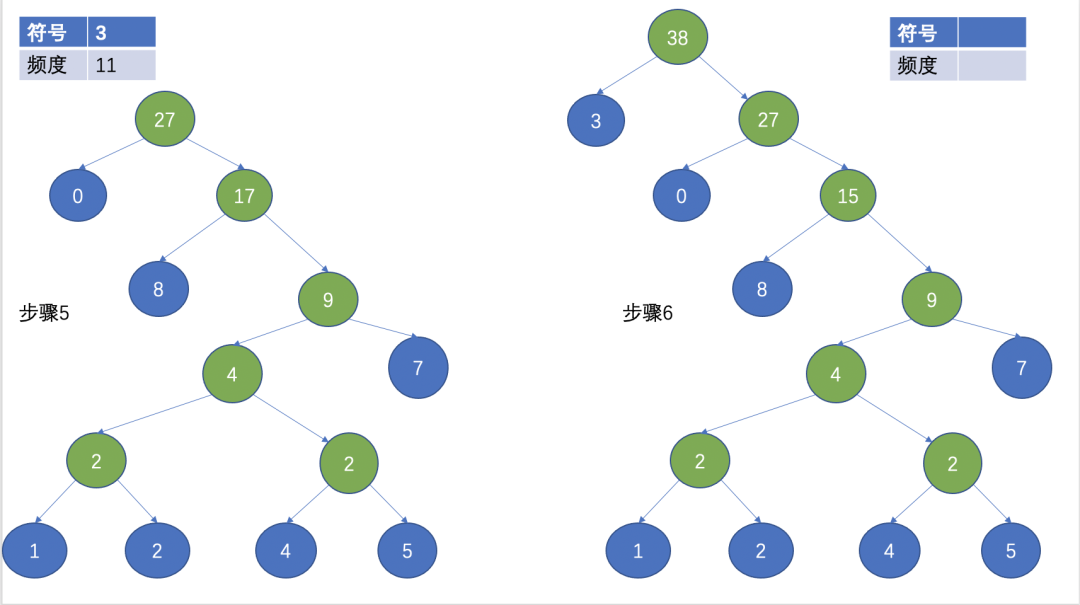
(Huffman 树)
经过上面的步骤,就形成了一颗Huffman树,Huffman编码经常用在无损压缩中,其基本思想是用短的编码表示出现频率高的字符,用长的编码来表示出现频率低的字符,这使得编码之后的字符串的平均长度、长度的期望值降低,从而实现压缩的目的。
不完美。
上面的JPEG压缩虽然降低了图片的大小且质量良好以至于人眼很难分辨其差异,但是由于是有损的压缩,图片质量不能恢复到原来的品质,而且实际上此时的jpg图片仍有压缩空间。
Lepton便可以在JPEG基础上进一步对图片进行无损压缩。
与lepton类似的压缩工具还有jpegcan,MozJPEG,PackJPG,PAQ8PX。但这些工具都或多或少有一些缺陷,使得不如lepton更加适合工业生产。
比如PackJPG需要按照全局排序的顺序重新排列文件中的所有压缩像素值。这意味着解压缩是单线程的,同时需要整个图像放入内存中导致处理图片的时延较高吞吐较低。
下图是lepton论文中对几款工具的比较:
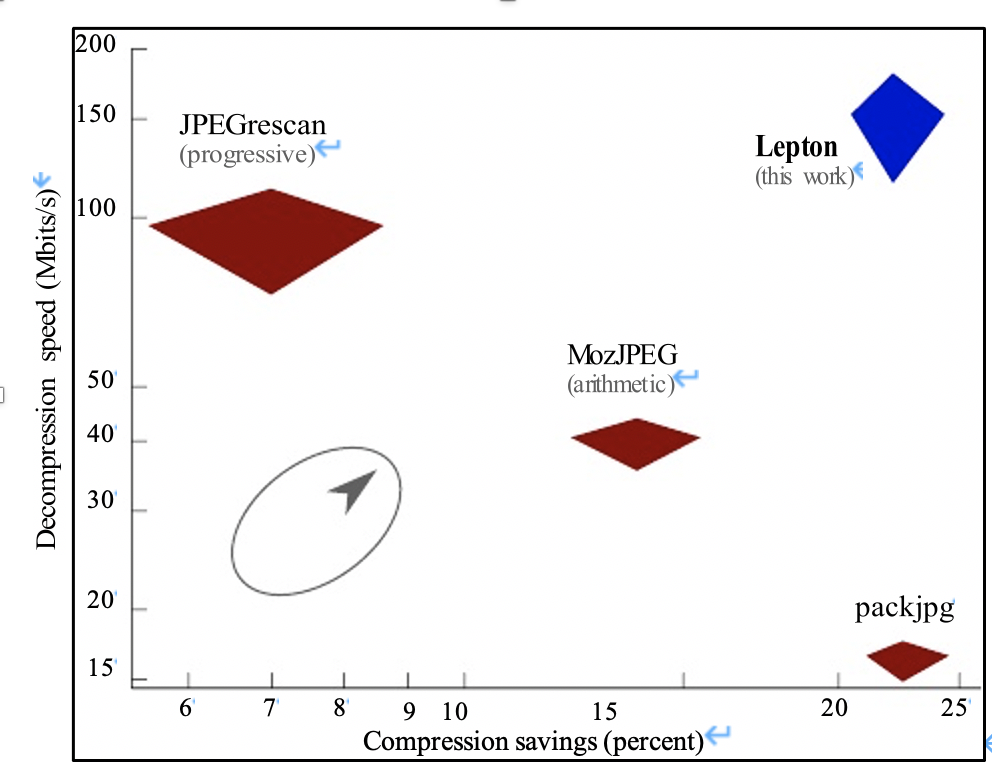
首先在算法上Lepton将图像分为两部分header和图片数据本身,header使用DEFLATE进行无损压缩,图片本身使用算数编码替换霍尔曼编码进行无损压缩。由于JPEG使用Huffman编码,这使得利用多线程比较困难,Lepton使用"Huffman切换词"进行了改进。
其次Lepton使用了一个复杂的自适应概率模型,这个模型是通过在大量的野外图像上进行测试而开发的。该模型的目标是对每个系数的值产生最准确的预测,从而产生更小的文件;在工程上允许多线程并发处理,允许分块跨多个服务器分布式处理,流的方式逐行处理有效的控制了内存,同时还保证了数据读取和输出的安全。
正是Lepton在上述关键问题的优化,使得它目前可以很好的在生产环境中使用。
预期收益:
目前对象存储其中的一个集群大约有100PB数据,其中图片数据大概占70%, 而图片中有90%的图片都是jpeg类型图片,如果按照平均23%的压缩率,那么 100PB * 70% * 90% * 23% = 14.5PB,将实现大约14.5PB的成本节约。
同时由于是无损压缩,很好的保证了用户的使用体验。当前lepton压缩功能的设计如下图:
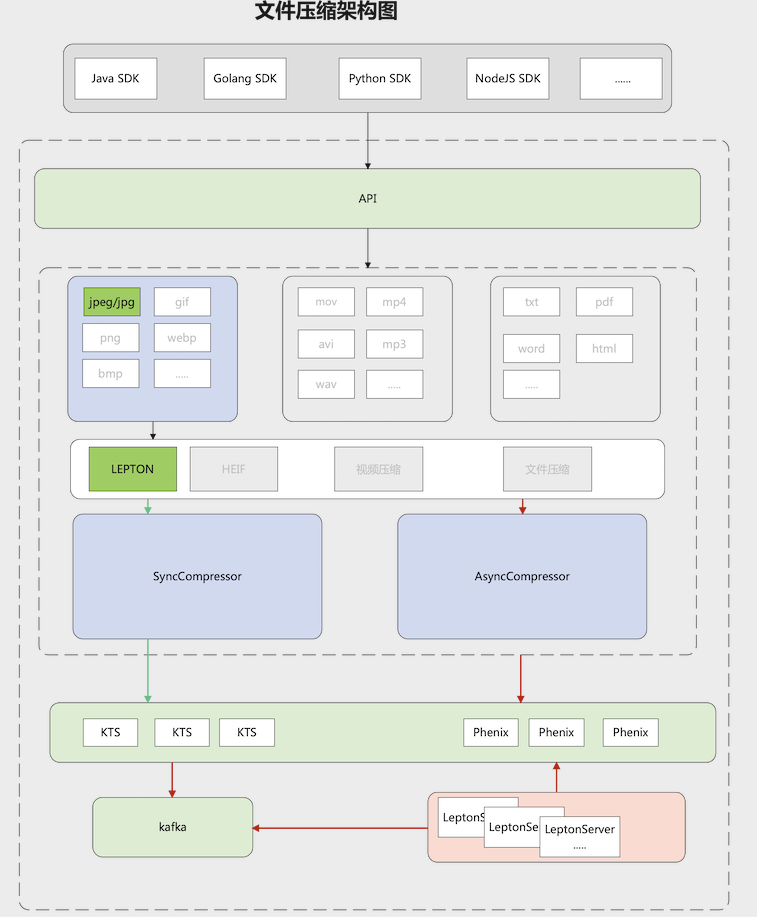
当前遇到的挑战:
当前面临的主要问题:
当前大部分图片的大小在4M-5M, 经过测试对于4M-5M大小的文件压缩时延在1s左右的情况下,需要服务器至少16核心、承载5QPS。此时每个核心的利用率都在95%以上。可见 Lepton的压缩对计算性能要求很高。当前常见的解决方案是使用FPGA卡进行硬件加速、以及横向扩容大量的计算节点。FPGA的使用会增加硬件成本,降低压缩带来的成本收益。
解决方案:
为了解决上述问题及挑战,我们尝试采用物理服务器和Kubernetes混合部署的方式解决计算资源的使用和动态扩所容的问题,架构示意图如下: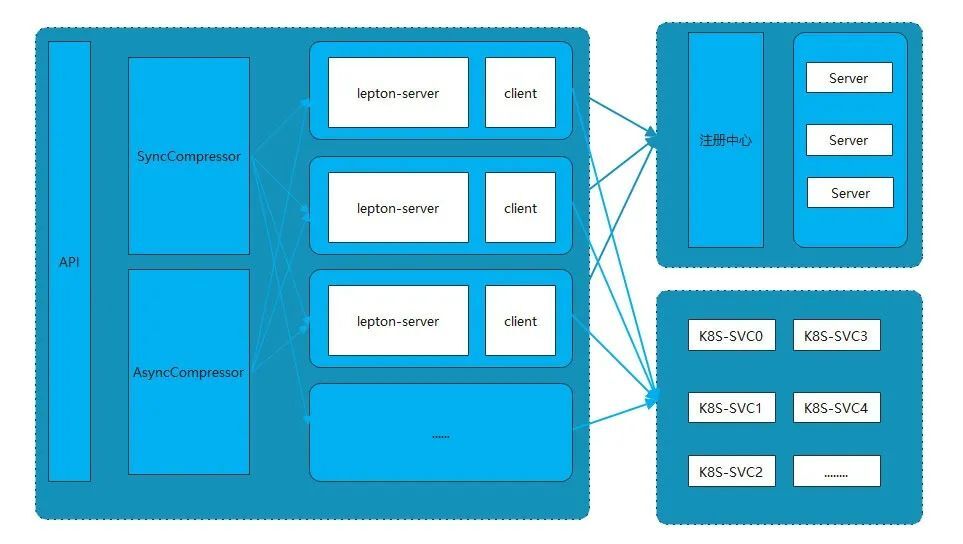
对于物理服务器的管理以及扩所容通过服务的注册于发现进行弹性扩所容、通过此cgroup/Taskset等方式对进程的cpu使用进行管理。同时对接使用Kubernetes以容器的方式进行管理、容器的灵活性更加适合这种计算型的服务。
无论是同步压缩,还是异步压缩,通常更加关注图片读取的延时。大量的图片读取会给服务器带来较大的压力,压力主要来自于图片的解压计算。为了提高解压缩效率,以及充分利用公司的资源,我们未来将lepton压缩服务以独立的服务模式分布于cpu空闲的服务器,可以按照资源空闲程度,空闲时间,充分利用资源的峰谷来提高计算性能。
压测数据:
我们选取了不同大小的图片文件,在单机环境下进行了压缩与解压缩测试,测试结果如下图:
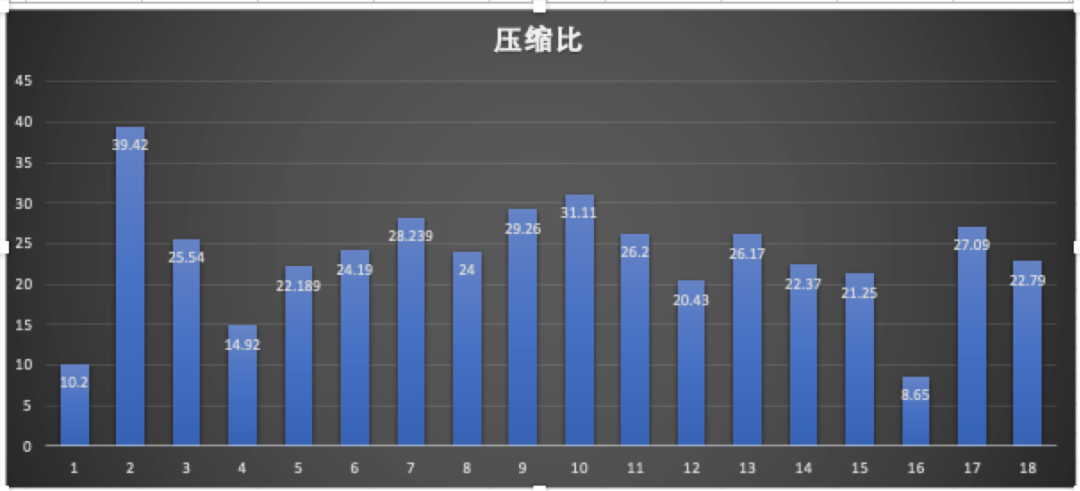
压缩比平均保持在22%左右。
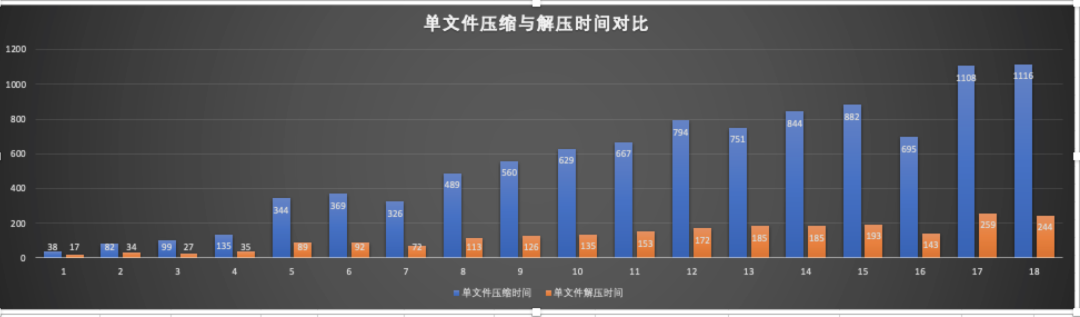
上图是不同大小的文件压缩与解压缩时间比例图,橙色是解压时间,蓝色是压缩时间。
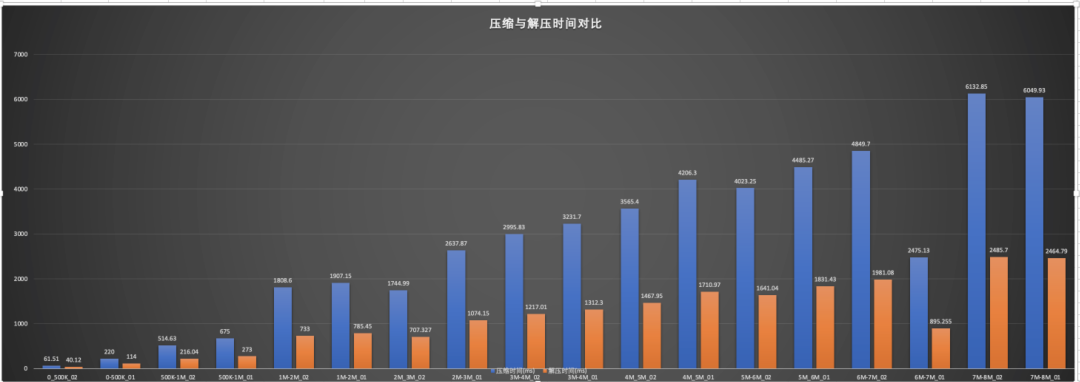
上图是不同大小的图片,在32线程并发,每个线程处理100个文件的测试数据。


Lepton的无损压缩能够提供比较高的压缩比,同时不影响用户的图片质量和使用体验、在大数据量的场景下会获得比较明显的收益。
不足之处是对计算性能要求较高、只支持jpeg类型的图片。对于性能的要求行业内也都有比较成熟的解决方案,例如上文提到的FPGA和弹性计算方案。关键在于根据企业需求选择合理的方案。
引用:
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
是否有任何可用于Ruby的开源压缩/解压库?有没有人实现过LZW?或者,是否有任何使用压缩组件的开源库可以提取出来独立使用?编辑——感谢您的回答!我应该提到我必须压缩的是只驻留在数据库中的长字符串(我不会压缩文件)。此外,如果可以执行此操作的任何库都具有用于客户端压缩/分解的等效JavaScript实现,那将是理想的,因为这将用于Web应用程序。 最佳答案 您会在rubystdlib下找到所有已交付的ruby库的一个很好的列表.我会使用zlib库,它是开放的,无处不在,您会发现几乎所有语言的库!
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我正在寻找一个用ruby演示计时器的在线示例,并发现了下面的代码。它按预期工作,但这个简单的程序使用30Mo内存(如Windows任务管理器中所示)和太多CPU有意义吗?非常感谢deftime_blockstart_time=Time.nowThread.new{yield}Time.now-start_timeenddefrepeat_every(seconds)whiletruedotime_spent=time_block{yield}#Tohandle-vesleepinteravalsleep(seconds-time_spent)iftime_spent
如果用户是所有者,我有一个条件来检查说删除和文章。delete_articleifuser.owner?另一种方式是user.owner?&&delete_article选择它有什么好处还是它只是一种写作风格 最佳答案 性能不太可能成为该声明的问题。第一个要好得多-它更容易阅读。您future的自己和其他将开始编写代码的人会为此感谢您。 关于ruby-on-rails-如果条件与&&,是否有任何性能提升,我们在StackOverflow上找到一个类似的问题:
我有一个包含100多个zip文件的目录,我需要读取zip文件中的文件以进行一些数据处理,而无需解压缩存档。是否有一个Ruby库可以在不解压缩文件的情况下读取zip存档中的文件内容?使用rubyzip报错:require'zip'Zip::File.open('my_zip.zip')do|zip_file|#Handleentriesonebyonezip_file.eachdo|entry|#Extracttofile/directory/symlinkputs"Extracting#{entry.name}"entry.extract('here')#Readintomemoryc
我编写了一个Ruby应用程序,它可以解析来自不同格式html、xml和csv文件的源中的大量数据。我如何找出代码的哪些区域花费的时间最长?有没有关于如何提高Ruby应用程序性能的好资源?或者您是否有任何始终遵循的性能编码标准?例如,你总是用加入你的字符串吗?output=String.newoutput或者你会使用output="#{part_one}#{part_two}\n" 最佳答案 好吧,有一些众所周知的做法,例如字符串连接比“#{value}”慢得多,但是为了找出您的脚本在哪里消耗了大部分时间或比所需时间更多,您需要进行分
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
LL库和HAL库简介LL:Low-Layer,底层库HAL:HardwareAbstractionLayer,硬件抽象层库LL库和hal库对比,很精简,这实际上是一个精简的库。LL库的配置选择如下:在STM32CUBEMX中,点击菜单的“ProjectManager”–>“AdvancedSettings”,在下面的界面中选择“AdvancedSettings”,然后在每个模块后面选择使用的库总结:1、如果使用的MCU是小容量的,那么STM32CubeLL将是最佳选择;2、如果结合可移植性和优化,使用STM32CubeHAL并使用特定的优化实现替换一些调用,可保持最大的可移植性。另外HAL和L