论文地址:https://arxiv.org/pdf/1803.11485.pdf
首先介绍一下VDN(value decomposition networks)顾名思义,VDN是一种价值分解的网络,采用对每个智能体的值函数进行整合,得到一个联合动作值函数。
为了简单阐述考虑两个智能体:(o-observations,a-actions,Q-action-value function)

当智能体观察他自己的目标时,但不一定是队友的目标,那么有:

当(
o
i
,
a
i
o^i,a^i
oi,ai)不足以完全建模
Q
ˉ
i
π
(
s
,
a
)
\bar{Q}_{i}^{\pi}(\mathbf{s}, \mathbf{a})
Qˉiπ(s,a),利用LSTM网络的历史观测获取额外信息(t时刻看到目标A,t+5时刻目标A被挡住了,利用t+5时刻的观测数据无法获得目标A的有效信息,只有利用历史观测数据从新定位目标A)
Q
π
(
s
,
a
)
=
:
Q
ˉ
1
π
(
s
,
a
)
+
Q
ˉ
2
π
(
s
,
a
)
≈
Q
~
1
π
(
h
1
,
a
1
)
+
Q
~
2
π
(
h
2
,
a
2
)
Q^{\pi}(\mathbf{s}, \mathbf{a})=: \bar{Q}_{1}^{\pi}(\mathbf{s}, \mathbf{a})+\bar{Q}_{2}^{\pi}(\mathbf{s}, \mathbf{a}) \approx \tilde{Q}_{1}^{\pi}\left(h^{1}, a^{1}\right)+\tilde{Q}_{2}^{\pi}\left(h^{2}, a^{2}\right)
Qπ(s,a)=:Qˉ1π(s,a)+Qˉ2π(s,a)≈Q~1π(h1,a1)+Q~2π(h2,a2)
值分解网络旨在学习一个联合动作值函数
Q
t
o
t
(
τ
,
u
)
Q_{t o t}(\tau,u)
Qtot(τ,u) ,其中
τ
∈
T
≡
τ
n
\tau \in T \equiv \tau^{n}
τ∈T≡τn 是一个联合动作-观测的历史轨迹,
u
u
u是一个联合动作。它是由每个智能体
i
i
i独立计算其值函数
Q
i
(
τ
i
,
u
i
;
θ
i
)
Q_{i}\left(\tau^{i}, u^{i} ; \theta^{i}\right)
Qi(τi,ui;θi),之后累加求和得到的。其关系如下所示:
Q
t
o
t
=
∑
i
=
1
n
Q
i
(
τ
i
,
a
i
;
θ
i
)
Q_{t o t}=\sum_{i=1}^{n} Q_{i}\left(\tau_{i}, a_{i} ; \theta_{i}\right)
Qtot=i=1∑nQi(τi,ai;θi)
具体请看原论文:https://arxiv.org/pdf/1706.05296.pdf
QMIX,和VDN类似,也是一种基于价值的方法,可以以集中的端到端方式训练分散策略。QMIX采用了一个网络,将联合动作值估计为每个智能体值的复杂非线性组合(VDN是线性加和),且仅基于局部观测。并且在结构上施加约束,使联合动作值函数与每个智能体动作值函数之间是单调的,保证集中策略和分散策略之间的一致性。
IGM(Individual-Global-Max):
argmax u Q t o t ( τ , u ) = ( argmax u 1 Q 1 ( τ 1 , u 1 ) ⋮ argmax u n Q n ( τ n , u n ) ) \underset{\mathbf{u}}{\operatorname{argmax}} Q_{t o t}(\tau, \mathbf{u})=\left(\begin{array}{cc} \operatorname{argmax}_{u^{1}} & Q_{1}\left(\tau^{1}, u^{1}\right) \\ \vdots \\ {\operatorname{argmax}}_{u^{n}} & Q_{n}\left(\tau^{n}, u^{n}\right) \end{array}\right) uargmaxQtot(τ,u)=⎝⎜⎛argmaxu1⋮argmaxunQ1(τ1,u1)Qn(τn,un)⎠⎟⎞
其中,
Q
t
o
t
Q_{tot}
Qtot表示联合Q函数;
Q
i
Q_i
Qi表示智能体 i的动作值函数。
IGM表示
a
r
g
m
a
x
(
Q
t
o
t
)
argmax (Q_{tot})
argmax(Qtot) 与
a
r
g
m
a
x
(
Q
i
)
argmax (Q_i)
argmax(Qi)得到相同结果,这表示在无约束条件的情况下,个体最优就代表整体最优。为了保证这一条件,QMIX以单调条件进行限制:


框架主要分三两部分:
下面进行具体分析:
输入:
t
t
t时刻智能体
a
a
a的观测值
o
t
a
o_t^a
ota、
t
−
1
t-1
t−1时刻智能体
a
a
a的动作
u
t
−
1
a
u_{t-1}^a
ut−1a
输出:
t
t
t时刻智能体
a
a
a的值函数
Q
a
(
τ
a
,
u
t
a
)
Q_{a}\left(\tau^{a}, u_t^{a}\right)
Qa(τa,uta)

Agent network由DRQN网络实现,根据不同的任务需求,不同智能体的网络可以进行单独训练,也可进行参数共享,DRQN是将DQN中的全连接层替换为GRU网络,其循环层由一个具有64维隐藏状态的GRU组成,循环网络在观测质量变化的情况下,具有更强的适应性。如图所示,其网络一共包含 3 层,输入层(MLP多层神经网络)→ 中间层(GRU门控循环神经网络)→ 输出层(MLP多层神经网络)
实现代码如下:
智能体网络参数配置:
# --- Agent parameters ---
agent: "rnn" # Default rnn agent
rnn_hidden_dim: 64 # Size of hidden state for default rnn agent
obs_agent_id: True # Include the agent's one_hot id in the observation
obs_last_action: True # Include the agent's last action (one_hot) in the observation
RNN网络:
class RNNAgent(nn.Module):
def __init__(self, input_shape, args):
super(RNNAgent, self).__init__()
self.args = args
#根据参数配置,智能体网络的输入
#input_shape = obs_shape + n_actions + one_hot_code(one_hot_code_o+one_hot_code_u)
self.fc1 = nn.Linear(input_shape, args.rnn_hidden_dim) # 线性层
self.rnn = nn.GRUCell(args.rnn_hidden_dim, args.rnn_hidden_dim) # GRU层,需要输入隐藏状态
self.fc2 = nn.Linear(args.rnn_hidden_dim, args.n_actions) # 线性层
def init_hidden(self):
# make hidden states on same device as model
return self.fc1.weight.new(1, self.args.rnn_hidden_dim).zero_()
def forward(self, inputs, hidden_state):
x = F.relu(self.fc1(inputs)) # 输入经过线性层后relu激活,输出x
h_in = hidden_state.reshape(-1, self.args.rnn_hidden_dim) # 对隐藏状态进行变形,列数为隐藏层维度大小
h = self.rnn(x, h_in) # 循环神经网络,输入x,与隐藏状态(上一时刻信息)
q = self.fc2(h) # 输出Q值
return q, h
输入:
t
t
t时刻智能体
a
a
a的值函数
Q
a
(
τ
a
,
u
t
a
)
Q_{a}\left(\tau^{a}, u_t^{a}\right)
Qa(τa,uta)、
t
t
t时刻全局状态
s
s
s
输出:
t
t
t时刻联合动作价值函数
Q
t
o
t
(
τ
,
u
)
Q_{tot}\left(\tau, u\right)
Qtot(τ,u)
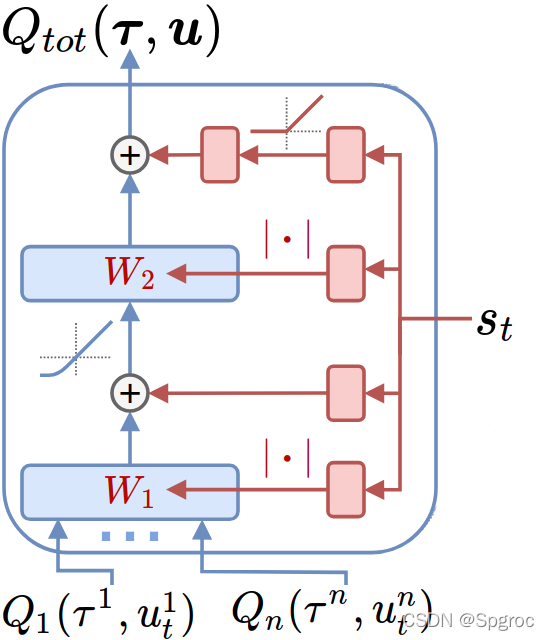
Mixing network是一个前馈神经网络,它以智能体网络的输出作为输入,单调地混合,产生
Q
t
o
t
Q_{tot}
Qtot的值,如图所示。为了保证的单调性约束,混合网络的权值
w
e
i
g
h
t
s
weights
weights被限制为非负值(偏差bias可以为负数)。这使得混合网络可以逼近任何单调函数。
混合网络的权值是由单独的超网络产生的。每个超网络以全局状态
s
s
s作为输入,生成一层混合网络的权值。每个超网络由一个单一的线性层组成,然后是一个绝对值激活函数,确保混合网络的权值是非负的。偏差也以同样的方式产生,但偏差的生成网络没有绝对值激活函数。最终的偏差是由一个具有ReLU非线性的2层超网络产生。
实现代码如下:
mixer: "qmix"
mixing_embed_dim: 32
hypernet_layers: 2
hypernet_embed: 64
class QMixer(nn.Module):
def __init__(self, args):
super(QMixer, self).__init__()
self.args = args
self.n_agents = args.n_agents # 智能体个数
self.state_dim = int(np.prod(args.state_shape)) # 状态维度
self.embed_dim = args.mixing_embed_dim # 网络内部嵌入维度
if getattr(args, "hypernet_layers", 1) == 1: # 超网络的层数是否为1
# 不包含隐层,只有一个线性层
self.hyper_w_1 = nn.Linear(self.state_dim, self.embed_dim * self.n_agents)
self.hyper_w_final = nn.Linear(self.state_dim, self.embed_dim)
elif getattr(args, "hypernet_layers", 1) == 2: # 超网络的层数是否为2
hypernet_embed = self.args.hypernet_embed # 超网络的嵌入层数
# 因为生成的hyper_w1需要是一个矩阵,而pytorch神经网络只能输出一个向量,
# 所以就先输出长度为需要的 矩阵行*矩阵列 的向量,然后再转化成矩阵
# hyper_w1 网络用于输出推理网络中的第一层神经元所需的 weights
self.hyper_w_1 = nn.Sequential(nn.Linear(self.state_dim, hypernet_embed),
nn.ReLU(),
nn.Linear(hypernet_embed, self.embed_dim * self.n_agents))
# hyper_w_final 生成推理网络需要的从隐层到输出 Q 值的所有 weights,共 embed_dim 个
self.hyper_w_final = nn.Sequential(nn.Linear(self.state_dim, hypernet_embed),
nn.ReLU(),
nn.Linear(hypernet_embed, self.embed_dim))
elif getattr(args, "hypernet_layers", 1) > 2: # 超网络层数进行判断
raise Exception("Sorry >2 hypernet layers is not implemented!")
else:
raise Exception("Error setting number of hypernet layers.")
# hyper_b1 生成第一层网络对应维度的偏差 bias
self.hyper_b_1 = nn.Linear(self.state_dim, self.embed_dim)
# V 生成对应从隐层到输出 Q 值层的 bias
self.V = nn.Sequential(nn.Linear(self.state_dim, self.embed_dim),
nn.ReLU(),
nn.Linear(self.embed_dim, 1))
def forward(self, agent_qs, states):
# 输入状态单个智能体的q值,全局状态s
# states的shape为(episode_num, max_episode_len, state_shape)
bs = agent_qs.size(0) # 传入的agent_qs是三维的,shape为(episode_num, max_episode_len, n_agents)
states = states.reshape(-1, self.state_dim) # (episode_num * max_episode_len, state_shape)
agent_qs = agent_qs.view(-1, 1, self.n_agents) # (episode_num * max_episode_len, 1, n_agents)
# First layer
w1 = th.abs(self.hyper_w_1(states)) # 获得参数w1,加绝对值,保证单调
b1 = self.hyper_b_1(states) # 获得偏差b1
w1 = w1.view(-1, self.n_agents, self.embed_dim) # 变换(episode_num, n_agents, embed_dim)
b1 = b1.view(-1, 1, self.embed_dim) # 变换(episode_num, 1, embed_dim)
hidden = F.elu(th.bmm(agent_qs, w1) + b1) # th.bmm矩阵乘法,输出到隐藏
# Second layer
w_final = th.abs(self.hyper_w_final(states)) # 获得参数w2,加绝对值,保证单调
w_final = w_final.view(-1, self.embed_dim, 1) # 变换(episode_num, embed_dim, 1)
# State-dependent bias
v = self.V(states).view(-1, 1, 1) # 获得偏差b2(episode_num, 1, 1)
# Compute final output
y = th.bmm(hidden, w_final) + v # th.bmm矩阵乘法,得到最终数值
# Reshape and return
q_tot = y.view(bs, -1, 1) # 变换(episode_num,1,1)
return q_tot # 得到Q_tot
损失函数:
L
(
θ
)
=
∑
i
=
1
b
[
(
y
i
t
o
t
−
Q
t
o
t
(
τ
,
u
,
s
;
θ
)
)
2
]
\mathcal{L}(\theta)=\sum_{i=1}^{b}\left[\left(y_{i}^{t o t}-Q_{t o t}(\tau, \mathbf{u}, s ; \theta)\right)^{2}\right]
L(θ)=∑i=1b[(yitot−Qtot(τ,u,s;θ))2]
其中
b
b
b表示从经验池中采样的样本数量,
y
t
o
t
=
r
+
γ
max
u
′
Q
t
o
t
(
τ
′
,
u
′
,
s
′
;
θ
−
)
y^{t o t}=r+\gamma \max _{\mathbf{u}^{\prime}} Q_{t o t}\left(\tau^{\prime}, \mathbf{u}^{\prime}, s^{\prime} ; \theta^{-}\right)
ytot=r+γmaxu′Qtot(τ′,u′,s′;θ−),
θ
−
\theta^{-}
θ−是目标网络的参数,
所以时序差分的误差可表示为:
T
D
e
r
r
o
r
=
(
r
+
γ
Q
t
o
t
(
target
)
)
−
Q
t
o
t
(
evalutate
)
\begin{aligned} {TDerror}=(r+\gamma Q _{ tot }(\text { target })) -Q _{ tot }(\text { evalutate }) \end{aligned}
TDerror=(r+γQtot( target ))−Qtot( evalutate )
Q
t
o
t
(
target
)
Q _{ tot }(\text { target })
Qtot( target ):状态
s
′
s^{'}
s′的情况下,所有行为中,获取的最大价值
Q
t
o
t
Q_{tot}
Qtot。根据IGM条件,输入为此状态下每个智能体的最大动作价值。
Q
t
o
t
(
evalutate
)
Q _{ tot }(\text { evalutate })
Qtot( evalutate ): 状态
s
s
s的情况下,根据当前网络策略所能获得
Q
t
o
t
Q_{tot}
Qtot。
实现代码如下:
参数配置:
# use epsilon greedy action selector
action_selector: "epsilon_greedy"
epsilon_start: 1.0
epsilon_finish: 0.05
epsilon_anneal_time: 50000
runner: "episode"
buffer_size: 5000
# update the target network every {} episodes
target_update_interval: 200
动作选择:(ε-greedy)
class EpsilonGreedyActionSelector():
def __init__(self, args):
self.args = args
self.schedule = DecayThenFlatSchedule(args.epsilon_start, args.epsilon_finish, args.epsilon_anneal_time,
decay="linear")
self.epsilon = self.schedule.eval(0)
def select_action(self, agent_inputs, avail_actions, t_env, test_mode=False):
# Assuming agent_inputs is a batch of Q-Values for each agent bav
self.epsilon = self.schedule.eval(t_env) # 获取epsilon
if test_mode:
# Greedy action selection only
self.epsilon = 0.0
# mask actions that are excluded from selection
masked_q_values = agent_inputs.clone() # q值 q_value
masked_q_values[avail_actions == 0.0] = -float("inf") # should never be selected! 不能选择的动作赋值为 负无穷
random_numbers = th.rand_like(agent_inputs[:, :, 0]) # 生成相同维度的随机矩阵
pick_random = (random_numbers < self.epsilon).long() # 如果小于epsilon
random_actions = Categorical(avail_actions.float()).sample().long() # 把可选的动作进行类别分布
# pick_random==1 说明 random_numbers < self.epsilon 进行随机探索
# pick_random==0 说明 random_numbers > self.epsilon 选择动作价值最大的函数
picked_actions = pick_random * random_actions + (1 - pick_random) * masked_q_values.max(dim=2)[1] # 进行动作选择
return picked_actions # 选择的动作
计算单个智能体估计的Q值
# Calculate estimated Q-Values 得到每个agent对应的Q值
mac_out = []
self.mac.init_hidden(batch.batch_size)
for t in range(batch.max_seq_length):
agent_outs = self.mac.forward(batch, t=t) #计算智能体的Q值,获得Q表
mac_out.append(agent_outs) #添加到列表中
mac_out = th.stack(mac_out, dim=1) # Concat over time 沿着维度1,连接张量 ([mac_out, 1])
# Pick the Q-Values for the actions taken by each agent
# 取每个agent动作对应的Q值,并且把最后不需要的一维去掉,因为最后一维只有一个值了
chosen_action_qvals = th.gather(mac_out[:, :-1], dim=3, index=actions).squeeze(3) # Remove the last dim
x_mac_out = mac_out.clone().detach() #提取数据不带梯度
x_mac_out[avail_actions == 0] = -9999999 #不能执行的动作赋值为负无穷
max_action_qvals, max_action_index = x_mac_out[:, :-1].max(dim=3) #最大的动作值及其索引
max_action_index = max_action_index.detach().unsqueeze(3) #去掉梯度
is_max_action = (max_action_index == actions).int().float() #是最大动作
计算单个智能体目标Q值
# Calculate the Q-Values necessary for the target 计算目标Q值
target_mac_out = []
self.target_mac.init_hidden(batch.batch_size) #初始化隐层 RNNAgent
for t in range(batch.max_seq_length):
target_agent_outs = self.target_mac.forward(batch, t=t) #计算Q值,获得Q表
target_mac_out.append(target_agent_outs)#添加到列表中
# We don't need the first timesteps Q-Value estimate for calculating targets
target_mac_out = th.stack(target_mac_out[1:], dim=1) # Concat across time
# Max over target Q-Values 找到最大的动作价值
if self.args.double_q: #是否使用double q
# Get actions that maximise live Q (for double q-learning)
mac_out_detach = mac_out.clone().detach() #去掉梯度
mac_out_detach[avail_actions == 0] = -9999999 #不能执行的动作赋值为负无穷
cur_max_actions = mac_out_detach[:, 1:].max(dim=3, keepdim=True)[1] #找到最大价值的动作
# 利用最优动作求取最大动作价值,并且把最后不需要的一维去掉
target_max_qvals = th.gather(target_mac_out, 3, cur_max_actions).squeeze(3)
else:
target_max_qvals = target_mac_out.max(dim=3)[0] #找到最大价值函数
根据损失函数,进行反向传播
# Mix 混合网络,求total值
# qmix更新过程,evaluate网络输入的是每个agent选出来的行为的q值,target网络输入的是每个agent最大的q值,和DQN更新方式一样
if self.mixer is not None:
chosen_action_qvals = self.mixer(chosen_action_qvals, batch["state"][:, :-1]) # 计算Q _{ tot }(evalutate)
target_max_qvals = self.target_mixer(target_max_qvals, batch["state"][:, 1:]) # 计算Q _{ tot }(target )
# Calculate 1-step Q-Learning targets 以Q-Learning的方法计算目标值r+gamma*Q _{ tot }({ target }
targets = rewards + self.args.gamma * (1 - terminated) * target_max_qvals
# Td-error
td_error = (chosen_action_qvals - targets.detach())
mask = mask.expand_as(td_error) # 将mask扩展为td_error相同的size
# 0-out the targets that came from padded data
masked_td_error = td_error * mask # 抹掉填充的经验的td_error
# Normal L2 loss, take mean over actual data
# L2的损失函数,不能直接用mean,因为还有许多经验是没用的,所以要求和再比真实的经验数,才是真正的均值
loss = (masked_td_error ** 2).sum() / mask.sum()
# Optimise
# 优化
self.optimiser.zero_grad() # 梯度清零
loss.backward() # 反向传播
grad_norm = th.nn.utils.clip_grad_norm_(self.params, self.args.grad_norm_clip) # 梯度剪裁
self.optimiser.step() # 执行
# 在指定周期更新 target network 的参数
if (episode_num - self.last_target_update_episode) / self.args.target_update_interval >= 1.0:
self._update_targets()
self.last_target_update_episode = episode_num
IQL、VDN和QMIX在StarCraft II六种不同的战斗地图上的获胜率。基于启发式的算法的性能用虚线表示。

博客:【QMIX】一种基于Value-Based多智能体算法
多智能体强化学习入门(五)——QMIX算法分析
多智能体强化学习入门Qmix
代码:https://github.com/wjh720/QPLEX
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
前面一篇关于智能合约翻译文讲到了,是一种计算机程序,既然是程序,那就可以使用程序语言去编写智能合约了。而若想玩区块链上的项目,大部分区块链项目都是开源的,能看得懂智能合约代码,或找出其中的漏洞,那么,学习Solidity这门高级的智能合约语言是有必要的,当然,这都得在公链``````以太坊上,毕竟国内的联盟链有些是不兼容Solidity。Solidity是一种面向对象的高级语言,用于实现智能合约。智能合约是管理以太坊状态下的账户行为的程序。Solidity是运行在以太坊(Ethereum)虚拟机(EVM)上,其语法受到了c++、python、javascript影响。Solidity是静态类型
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c
2022年底,OpenAI的预训练模型ChatGPT给人工智能领域的爱好者和研究人员留下了深刻的印象和启发,他展现的惊人能力将人工智能的研究和应用热度推向高潮,网上也充斥着和ChatGPT的各种聊天,他可以作诗、写小说、写代码、讨论疫情问题等。下面就是一些他的神回复:人命关天的坑: 写歌,留给词作者的机会不多了。。。 回答人类怎么样面对人工智能: 什么是ChatGPT?借用网上的一段介绍,ChatGPT是由人工智能研究实验室OpenAI在2022年11月30日发布的全新聊天机器人模型,一款人工智能技术驱动的自然语言处理工具。它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动