文章同步发于 github、博客园 和 知乎。最新版以
github为主。如果看完文章有所收获,一定要先点赞后收藏。毕竟,赠人玫瑰,手有余香。
MobileNet论文的主要贡献在于提出了一种深度可分离卷积架构(DW+PW 卷积),先通过理论证明这种架构比常规的卷积计算成本(Mult-Adds)更小,然后通过分类、检测等多种实验证明模型的有效性。
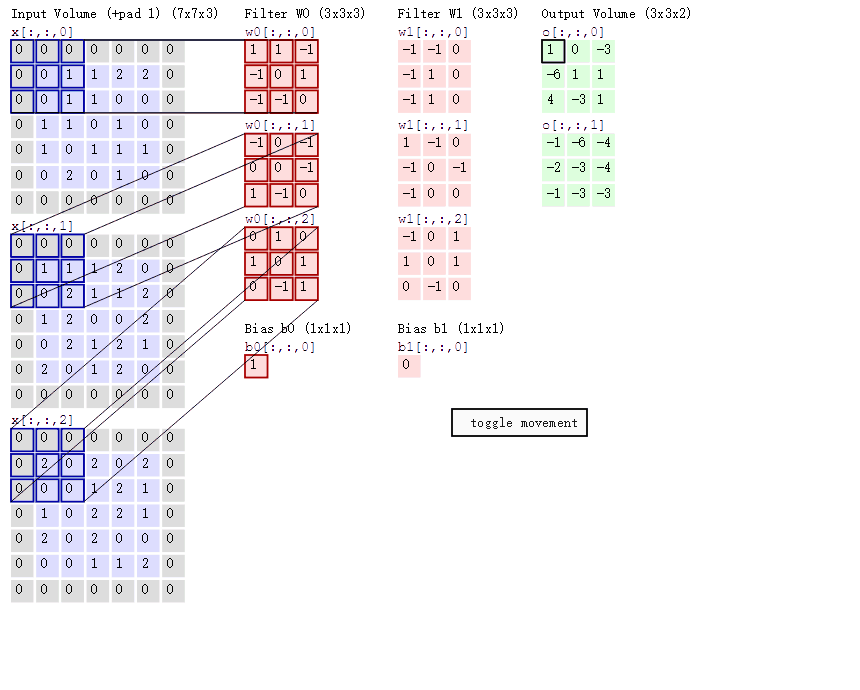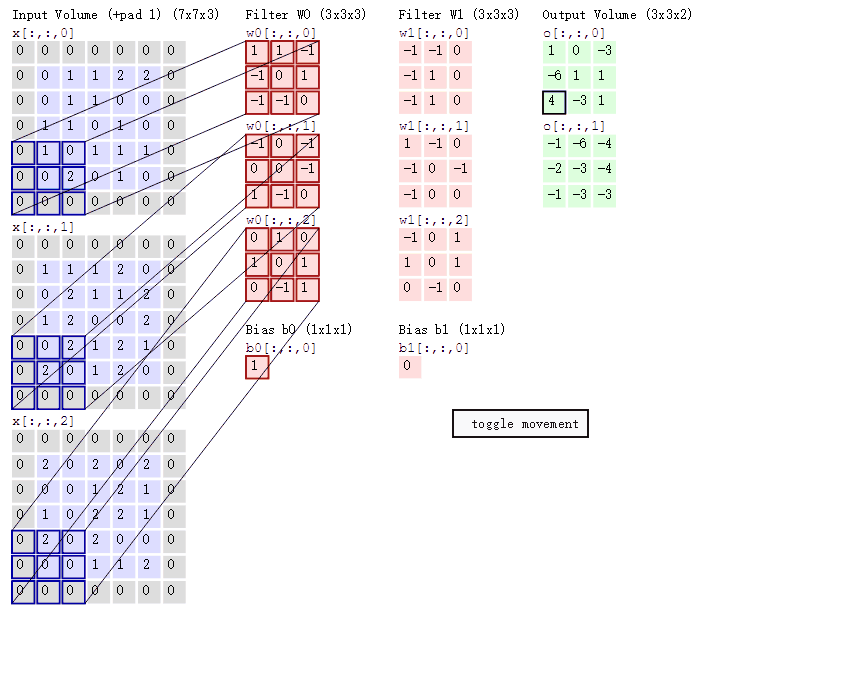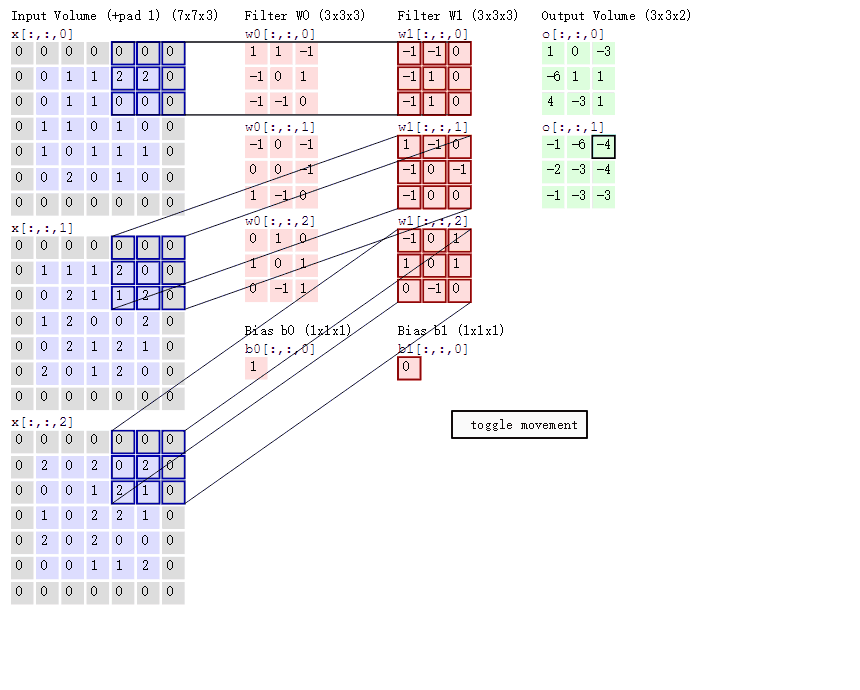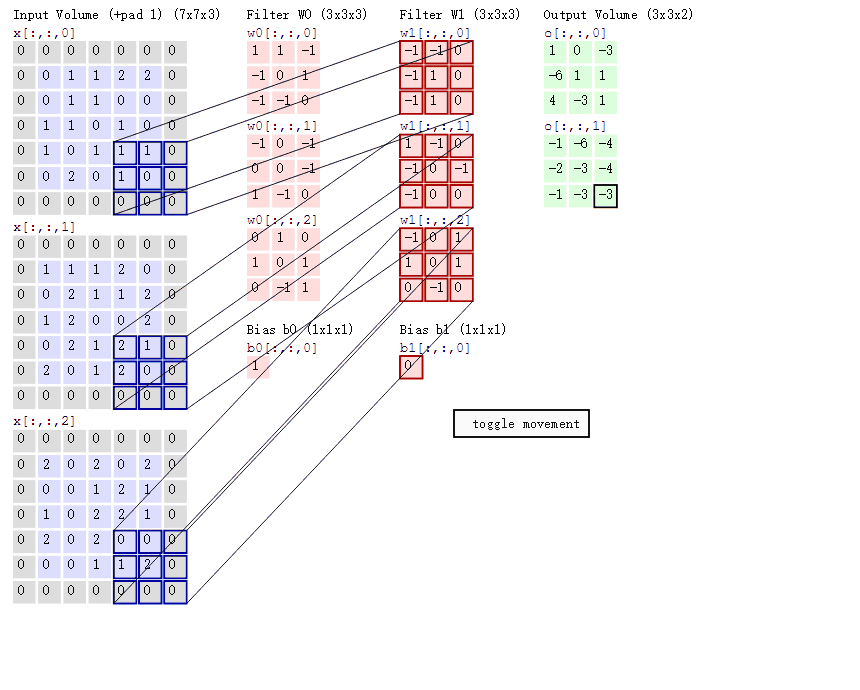
一个大小为 \(h_1\times w_1\) 过滤器(2 维卷积核),沿着 feature map 的左上角移动到右下角,过滤器每移动一次,将过滤器参数矩阵和对应特征图 \(h_1 \times w_1 \times c_1\) 大小的区域内的像素点相乘后累加得到一个值,又因为 feature map 的数量(通道数)为 \(c_1\),所以我们需要一个 shape 为 $ (c_1, h_1, w_1)$ 的滤波器( 3 维卷积核),将每个输入 featue map 对应输出像素点位置计算和的值相加,即得到输出 feature map 对应像素点的值。又因为输出 feature map 的数量为 \(c_2\) 个,所以需要 \(c_2\) 个滤波器。标准卷积抽象过程如下图所示。

2D 卷积计算过程动态图如下,通过这张图能够更直观理解卷积核如何执行滑窗操作,又如何相加并输出 \(c_2\) 个 feature map ,动态图来源 这里。
Group Convolution 分组卷积,最早见于 AlexNet。常规卷积与分组卷积的输入 feature map 与输出 feature map 的连接方式如下图所示,图片来自CondenseNet。

分组卷积的定义:对输入 feature map 进行分组,然后分组分别进行卷积。假设输入 feature map 的尺寸为 \(H \times W \times c_{1}\),输出 feature map 数量为 \(c_2\) 个,如果将输入 feature map 按通道分为 \(g\) 组,则每组特征图的尺寸为 \(H \times W \times \frac{c_1}{g}\),每组对应的滤波器(卷积核)的 尺寸 为 \(h_{1} \times w_{1} \times \frac{c_{1}}{g}\),每组的滤波器数量为 \(\frac{c_{2}}{g}\) 个,滤波器总数依然为 \(c_2\) 个,即分组卷积的卷积核 shape 为 \((c_2,\frac{c_1}{g}, h_1,w_1)\)。每组的滤波器只与其同组的输入 map 进行卷积,每组输出特征图尺寸为 \(H \times W \times \frac{c_{2}}{g}\),将 \(g\) 组卷积后的结果进行拼接 (concatenate) 得到最终的得到最终尺寸为 \(H \times W \times c_2\) 的输出特征图,其分组卷积过程如下图所示:

分组卷积的意义:分组卷积是现在网络结构设计的核心,它通过通道之间的稀疏连接(也就是只和同一个组内的特征连接)来降低计算复杂度。一方面,它允许我们使用更多的通道数来增加网络容量进而提升准确率,但另一方面随着通道数的增多也对带来更多的 \(MAC\)。针对 \(1 \times 1\) 的分组卷积,\(MAC\) 和 \(FLOPs\) 计算如下:
从以上公式可以得出分组卷积的参数量和计算量是标准卷积的 \(\frac{1}{g}\) 的结论 ,但其实对分组卷积过程进行深入理解之后也可以直接得出以上结论。
分组卷积的深入理解:对于 \(1\times 1\) 卷积,常规卷积输出的特征图上,每一个像素点是由输入特征图的 \(c_1\) 个点计算得到,而分组卷积输出的特征图上,每一个像素点是由输入特征图的 $ \frac{c_1}{g}$个点得到(参考常规卷积计算过程)。卷积运算过程是线性的,自然,分组卷积的参数量和计算量是标准卷积的 \(\frac{1}{g}\) 了。
当分组卷积的分组数量 = 输入 feature map 数量 = 输出 feature map 数量,即 \(g=c_1=c_2\),有 \(c_1\) 个滤波器,且每个滤波器尺寸为 \(1 \times K \times K\) 时,Group Convolution 就成了 Depthwise Convolution(DW 卷积),DW 卷积的卷积核权重尺寸为 \((c_{1}, 1, K, K)\)。
常规卷积的卷积核权重 shape 都为(
C_out, C_in, kernel_height, kernel_width),分组卷积的卷积核权重shape为(C_out, C_in/g, kernel_height, kernel_width),DW卷积的卷积核权重shape为(C_in, 1, kernel_height, kernel_width)。
深度可分离卷积(depthwise separable convolutions)的提出最早来源于 Xception 论文,Xception 的论文中提到,对于卷积来说,卷积核可以看做一个三维的滤波器:通道维+空间维(Feature Map 的宽和高),常规的卷积操作其实就是实现通道相关性和空间相关性的联合映射。Inception 模块的背后存在这样的一种假设:卷积层通道间的相关性和空间相关性是可以退耦合(完全可分)的,将它们分开映射,能达到更好的效果(the fundamental hypothesis behind Inception is that cross-channel correlations and spatial correlations are sufficiently decoupled that it is preferable not to map them jointly.)。
引入深度可分离卷积的 Inception,称之为 Xception,其作为 Inception v3 的改进版,在 ImageNet 和 JFT 数据集上有一定的性能提升,但是参数量和速度并没有太大的变化,因为 Xception 的目的也不在于模型的压缩。深度可分离卷积的 Inception 模块如图 Figure 4 所示。

Figure 4 中的“极限” Inception 模块与本文的主角-深度可分离卷积模块相似,区别在于:深度可分离卷积先进行 channel-wise 的空间卷积,再进行 \(1 \times 1\) 的通道卷积,Figure 4 的 Inception 则相反;
MobileNets 是谷歌 2017 年提出的一种高效的移动端轻量化网络,其核心是深度可分离卷积(depthwise separable convolutions),深度可分离卷积的核心思想是将一个完整的卷积运算分解为两步进行,分别为 Depthwise Convolution(DW 卷积) 与 Pointwise Convolution(PW 卷积)。深度可分离卷积的计算步骤和滤波器尺寸如下所示。


注意本文 DW 和 PW 卷积计算量的计算与论文有所区别,本文的输出 Feature map 大小是 \(D_G \times D_G\), 论文公式是\(D_F \times D_F\)。
不同于常规卷积操作, Depthwise Convolution 的一个卷积核只负责一个通道,一个通道只能被一个卷积核卷积(不同的通道采用不同的卷积核卷积),也就是输入通道、输出通道和分组数相同的特殊分组卷积,因此 Depthwise(DW)卷积不会改变输入特征图的通道数目。深度可分离卷积的 DW卷积步骤如下图:

DW 卷积的计算量 \(MACC = M \times D_{G}^{2} \times D_{K}^{2}\)
上述 Depthwise 卷积的问题在于它让每个卷积核单独对一个通道进行计算,但是各个通道的信息没有达到交换,从而在网络后续信息流动中会损失通道之间的信息,因此论文中就加入了 Pointwise 卷积操作,来进一步融合通道之间的信息。PW 卷积是一种特殊的常规卷积,卷积核的尺寸为 \(1 \times 1\)。PW 卷积的过程如下图:

假设输入特征图大小为 \(D_{G} \times D_{G} \times M\),输出特征图大小为 \(D_{G} \times D_{G} \times N\),则滤波器尺寸为 \(1 \times 1 \times M\),且一共有 \(N\) 个滤波器。因此可计算得到 PW 卷积的计算量 \(MACC = N \times M \times D_{G}^{2}\)。
综上:Depthwise 和 Pointwise 卷积这两部分的计算量相加为 \(MACC1 = M \times D_{G}^{2} \times D_{K}^{2} + N \times M \times D_{G}^{2}\),而标准卷积的计算量 \(MACC2 = N \times D_{G}^{2} \times D_{K}^{2} \times M\)。所以深度可分离卷积计算量于标准卷积计算量比值的计算公式如下。
可以看到 Depthwise + Pointwise 卷积的计算量相较于标准卷积近乎减少了 \(N\) 倍,\(N\) 为输出特征图的通道数目,同理参数量也会减少很多。在达到相同目的(即对相邻元素以及通道之间信息进行计算)下, 深度可分离卷积能极大减少卷积计算量,因此大量移动端网络的 backbone 都采用了这种卷积结构,再加上模型蒸馏,剪枝,能让移动端更高效的推理。
深度可分离卷积的详细计算过程可参考 Depthwise卷积与Pointwise卷积。
\(3 \times 3\) 的深度可分离卷积 Block 结构如下图所示:

左边是带 bn 和 relu 的标准卷积层,右边是带 bn 和 relu 的深度可分离卷积层。
\(3 \times 3\) 的深度可分离卷积 Block 网络的 pytorch 代码如下:
class MobilnetV1Block(nn.Module):
"""Depthwise conv + Pointwise conv"""
def __init__(self, in_channels, out_channels, stride=1):
super(MobilnetV1Block, self).__init__()
# dw conv kernel shape is (in_channels, 1, ksize, ksize)
self.dw = nn.Conv2d(in_channels, in_channels, kernel_size=3,stride=stride,padding=1, groups=in_channels, bias=False)
self.bn1 = nn.BatchNorm2d(in_channels)
self.pw = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
out1 = F.relu(self.bn1(self.dw(x)))
out2 = F.relu(self.bn2(self.pw(out1)))
return out2
MobileNet v1 的 pytorch 模型导出为 onnx 模型后,深度可分离卷积 block 结构图如下图所示。

仅用 MobileNets 的 Mult-Adds(乘加操作)次数更少来定义高性能网络是不够的,确保这些操作能够有效实施也很重要。例如非结构化稀疏矩阵运算(unstructured sparse matrix operations)通常并不会比密集矩阵运算(dense matrix operations)快,除非是非常高的稀疏度。
这句话是不是和
shufflenet v2的观点一致,即不能仅仅以 FLOPs 计算量来表现网络的运行速度,除非是同一种网络架构。
MobileNet 模型结构将几乎所有计算都放入密集的 1×1 卷积中(dense 1 × 1 convolutions),卷积计算可以通过高度优化的通用矩阵乘法(GEMM)函数来实现。 卷积通常由 GEMM 实现,但需要在内存中进行名为 im2col 的初始重新排序,然后才映射到 GEMM。 caffe 框架就是使用这种方法实现卷积计算。 1×1 卷积不需要在内存中进行重新排序,可以直接使用 GEMM(最优化的数值线性代数算法之一)来实现。
如表 2 所示,MobileNet 模型的 1x1 卷积占据了 95% 的计算量和 75% 的参数,剩下的参数几乎都在全连接层中, 3x3 的 DW 卷积核常规卷积占据了很少的计算量(Mult-Adds)和参数。

尽管基本的 MobileNet 体系结构已经很小且网络延迟 latency 很低,但很多情况下特定用例或应用可能要求模型变得更小,更快。为了构建这些更小且计算成本更低的模型,我们引入了一个非常简单的参数 \(\alpha\),称为 width 乘数。宽度乘数 \(\alpha\) 的作用是使每一层的网络均匀变薄。对于给定的层和宽度乘数 \(\alpha\),输入通道的数量变为 \(\alpha M\),而输出通道的数量 \(N\) 变为 \(\alpha N\)。具有宽度乘数 \(\alpha\) 的深度可分离卷积(其它参数和上文一致)的计算成本为:
其中 \(\alpha \in (0,1]\),典型值设置为 1、0.75、0.5 和 0.25。\(\alpha = 1\) 是基准 MobileNet 模型,\(\alpha < 1\) 是缩小版的 MobileNets。宽度乘数的作用是将计算量和参数数量大约减少 \(\alpha^2\) 倍,从而降低了网络计算成本( computational cost of a neural network)。 宽度乘数可以应用于任何模型结构,以定义新的较小模型,且具有合理的准确性、网络延迟 latency 和模型大小之间的权衡。 它用于定义新的精简结构,需要从头开始进行训练模型。基准 MobileNet 模型的整体结构定义如表 1 所示。

减少模型计算成本的的第二个超参数(hyper-parameter)是分辨率因子 \(\rho\),论文将其应用于输入图像,则网络的每一层 feature map 大小也要乘以 \(\rho\)。实际上,论文通过设置输入分辨率来隐式设置 \(\rho\)。
将网络核心层的计算成本表示为具有宽度乘数 \(\alpha\) 和分辨率乘数 \(\rho\) 的深度可分离卷积的公式如下:
其中 \(\rho \in (0,1]\),通常是隐式设置的,因此网络的输入分辨率为 224、192、160 或 128。\(\rho = 1\) 时是基准(baseline) MobilNet,\(\rho < 1\) 时缩小版 MobileNets。分辨率乘数的作用是将计算量减少 \(\rho^2\)。
softmax 层,且将 DW 卷积和 PW 卷积计为单独的一层,则 MobileNet 有 28 层网络。+ 在整个网络结构中步长为2的卷积较有特点,卷积的同时充当下采样的功能;26 层都为深度可分离卷积的重复卷积操作,分为 4 个卷积 stage;ReLU 激活函数;作者分别进行了 Stanford Dogs dataset 数据集上的细粒度识别、大规模地理分类、人脸属性分类、COCO 数据集上目标检测的实验,来证明与 Inception V3、GoogleNet、VGG16 等 backbone 相比,MobilNets 模型可以在计算量(Mult-Adds)数 10 被下降的情况下,但是精度却几乎不变。
论文提出了一种基于深度可分离卷积的新模型架构,称为 MobileNets。 在相关工作章节中,作者首先调查了一些让模型更有效的重要设计原则,然后,演示了如何通过宽度乘数和分辨率乘数来构建更小,更快的 MobileNet,通过权衡合理的精度以减少模型大小和延迟。 然后,我们将不同的 MobileNets 与流行的模型进行了比较,这些模型展示了出色的尺寸,速度和准确性特性。 最后,论文演示了 MobileNet 在应用于各种任务时的有效性。
自己复现的基准 MobileNet v1 代模型 pytorch 代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models as models
from torch import flatten
class MobilnetV1Block(nn.Module):
"""Depthwise conv + Pointwise conv"""
def __init__(self, in_channels, out_channels, stride=1):
super(MobilnetV1Block, self).__init__()
# dw conv kernel shape is (in_channels, 1, ksize, ksize)
self.dw = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3,
stride=stride, padding=1, groups=4, bias=False),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True)
)
# print(self.dw[0].weight.shape) # print dw conv kernel shape
self.pw = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1,
stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.dw(x)
x = self.pw(x)
return x
def convbn_relu(in_channels, out_channels, stride=2):
return nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride,
padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True))
class MobileNetV1(nn.Module):
# (32, 64, 1) means MobilnetV1Block in_channnels is 32, out_channels is 64, no change in map size.
stage_cfg = [(32, 64, 1),
(64, 128, 2), (128, 128, 1), # stage1 conv
(128, 256, 2), (256, 256, 1), # stage2 conv
(256, 512, 2), (512, 512, 1), (512, 512, 1), (512, 512, 1), (512, 512, 1), (512, 512, 1), # stage3 conv
(512, 1024, 2), (1024, 1024, 1) # stage4 conv
]
def __init__(self, num_classes=1000):
super(MobileNetV1, self).__init__()
self.first_conv = convbn_relu(3, 32, 2) # Input image size reduced by half
self.stage_layers = self._make_layers(in_channels=32)
self.linear = nn.Linear(1024, num_classes) # 全连接层
def _make_layers(self, in_channels):
layers = []
for x in self.stage_cfg:
in_channels = x[0]
out_channels = x[1]
stride = x[2]
layers.append(MobilnetV1Block(in_channels, out_channels, stride))
in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
"""Feature map shape(h、w) is 224 -> 112 -> 56 -> 28 -> 14 -> 7 -> 1"""
x = self.first_conv(x)
x = self.stage_layers(x)
x = F.avg_pool2d(x, 7) # x shape is 7*7
x = flatten(x, 1) # x = x.view(x.size(0), -1)
x = self.linear(x)
return x
if __name__ == "__main__":
model = MobileNetV1()
model.eval() # set the model to inference mode
input_data = torch.rand(1, 3, 224, 224)
outputs = model(input_data)
print("Model output size is", outputs.size())
程序运行结果如下:
Model output size is torch.Size([1, 1000])
在降低 FLOPs 计算量上,MobileNet 的网络架构设计确实很好,但是 MobileNet 模型在 GPU、DSP 和 TPU 硬件上却不一定性能好,原因是不同硬件进行运算时的行为不同,从而导致了 FLOPs少不等于 latency 低的问题。
如果要实际解释 TPU 与 DSP 的运作原理,可能有点麻烦,可以参考下图,从结果直观地理解他们行为上的差异。考虑一个简单的 convolution,在 CPU 上 latency 随着 input 与 output 的channel 上升正相关的增加。然而在 DSP 上却是阶梯型,甚至在更高的 channel 数下存在特别低latency 的甜蜜点。

在一定的程度上,网络越深越宽,性能越好。宽度,即通道(channel)的数量,网络深度,即 layer 的层数,如 resnet18 有 18 个卷积层。注意我们这里说的和宽度学习一类的模型没有关系,而是特指深度卷积神经网络的(通道)宽度。
CNN 的网络层能够对输入图像数据进行逐层抽象,比如第一层学习到了图像边缘特征,第二层学习到了简单形状特征,第三层学习到了目标形状的特征,网络深度增加也提高了模型的抽象能力。3 维)的数量,滤波器越多,对目标特征的提取能力越强,即让每一层网络学习到更加丰富的特征,比如不同方向、不同频率的纹理特征等。FLOPs 低不等于 latency 低,尤其是在有加速功能的硬体 (GPU、DSP与 TPU )上不成立。MobileNet conv block (depthwise separable convolution)在有加速功能的硬件(专用硬件设计-NPU 芯片)上比较没有效率。channel 数的情况下 (如网路的前几层),在有加速功能的硬件使用普通 convolution 通常会比separable convolution 有效率。channel 数为 8 的倍数比较有利计算。DSP 与 TPU 上,一般我们需要运算为 uint8 形式,quantization(低精度量化)是常见的技巧。DSP 与 TPU 上,h-Swish 与 squeeze-and-excitation 效果不明显 (因为硬体设计与 uint8 压缩的关系)。DSP 与 TPU 上,5x5 convolution 比较没效率。我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
是否可以在不实际下载文件的情况下检查文件是否存在?我有这么大的(~40mb)文件,例如:http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm这与ruby不严格相关,但如果发件人可以设置内容长度就好了。RestClient.get"http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm",headers:{"Content-Length"=>100} 最佳答案
我在这方面尝试了很多URL,在我遇到这个特定的之前,它们似乎都很好:require'rubygems'require'nokogiri'require'open-uri'doc=Nokogiri::HTML(open("http://www.moxyst.com/fashion/men-clothing/underwear.html"))putsdoc这是结果:/Users/macbookair/.rvm/rubies/ruby-2.0.0-p481/lib/ruby/2.0.0/open-uri.rb:353:in`open_http':404NotFound(OpenURI::HT
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
(本文是网络的宏观的概念铺垫)目录计算机网络背景网络发展认识"协议"网络协议初识协议分层OSI七层模型TCP/IP五层(或四层)模型报头以太网碰撞路由器IP地址和MAC地址IP地址与MAC地址总结IP地址MAC地址计算机网络背景网络发展 是最开始先有的计算机,计算机后来因为多项技术的水平升高,逐渐的计算机变的小型化、高效化。后来因为计算机其本身的计算能力比较的快速:独立模式:计算机之间相互独立。 如:有三个人,每个人做的不同的事物,但是是需要协作的完成。 而这三个人所做的事是需要进行协作的,然而刚开始因为每一台计算机之间都是互相独立的。所以前面的人处理完了就需要将数据
安全产品安全网关类防火墙Firewall防火墙防火墙主要用于边界安全防护的权限控制和安全域的划分。防火墙•信息安全的防护系统,依照特定的规则,允许或是限制传输的数据通过。防火墙是一个由软件和硬件设备组合而成,在内外网之间、专网与公网之间的界面上构成的保护屏障。下一代防火墙•下一代防火墙,NextGenerationFirewall,简称NGFirewall,是一款可以全面应对应用层威胁的高性能防火墙,提供网络层应用层一体化安全防护。生产厂家•联想网御、CheckPoint、深信服、网康、天融信、华为、H3C等防火墙部署部署于内、外网编辑额,用于权限访问控制和安全域划分。UTM统一威胁管理(Un
Linux操作系统——网络配置与SSH远程安装完VMware与系统后,需要进行网络配置。第一个目标为进行SSH连接,可以从本机到VMware进行文件传送,首先需要进行网络配置。1.下载远程软件首先需要先下载安装一款远程软件:FinalShell或者xhell7FinalShellxhell7FinalShell下载:Windows下载http://www.hostbuf.com/downloads/finalshell_install.exemacOS下载http://www.hostbuf.com/downloads/finalshell_install.pkg2.配置CentOS网络安装好
在神经网络方面,我完全是个初学者。我整天都在与ruby-fann和ai4r搏斗,不幸的是我没有任何东西可以展示,所以我想我会来到StackOverflow并询问这里的知识渊博的人。我有一组样本——每天都有一个数据点,但它们不符合我能够找出的任何明确模式(我尝试了几次回归)。不过,我认为看看是否有任何方法可以仅从日期预测future的数据会很好,而且我认为神经网络将是生成希望表达这种关系的函数的好方法.日期是DateTime对象,数据点是十进制数,例如7.68。我一直在将DateTime对象转换为float,然后除以10,000,000,000得到一个介于0和1之间的数字,我一直在将
我有一个nokigiri网络抓取工具,它发布到我试图发布到heroku的数据库。我有一个sinatra应用程序前端,我想从数据库中获取它。我是Heroku和Web开发的新手,不知道处理此类问题的最佳方法。我是否必须将上传到数据库的网络爬虫脚本放在sinatra路由下(如mywebsite.com/scraper),并让它变得如此模糊以至于没有人访问它?最后,我想让sinatra部分成为一个从数据库中提取的restapi。感谢大家的参与 最佳答案 您可以采用两种方法。第一个是通过控制台使用herokurunYOURCMD运行scrap