1、准备3台机器
| 主机名称 | 主机IP | zookeeper版本 | kafka版本 |
| worker01 | 192.168.19.130 | zookeeper-3.6.3 | kafka_2.12-3.0.1 |
| worker02 | 192.168.19.131 | zookeeper-3.6.3 | kafka_2.12-3.0.1 |
| worker03 | 192.168.19.132 | zookeeper-3.6.3 | kafka_2.12-3.0.1 |
2、3台机器安装jdk1.8环境
3、下载kafka安装包(此处下载,可忽略第二步:下载安装包):
kafka_2.12-3.0.1.tgz
4、下载zookeeper安装包(此处下载,可忽略第二步:下载安装包):
apache-zookeeper-3.6.3-bin.tar.gz
1、登录官方:Index of /
2、下载zookeeper安装包,apache-zookeeper-3.6.3-bin.tar.gz
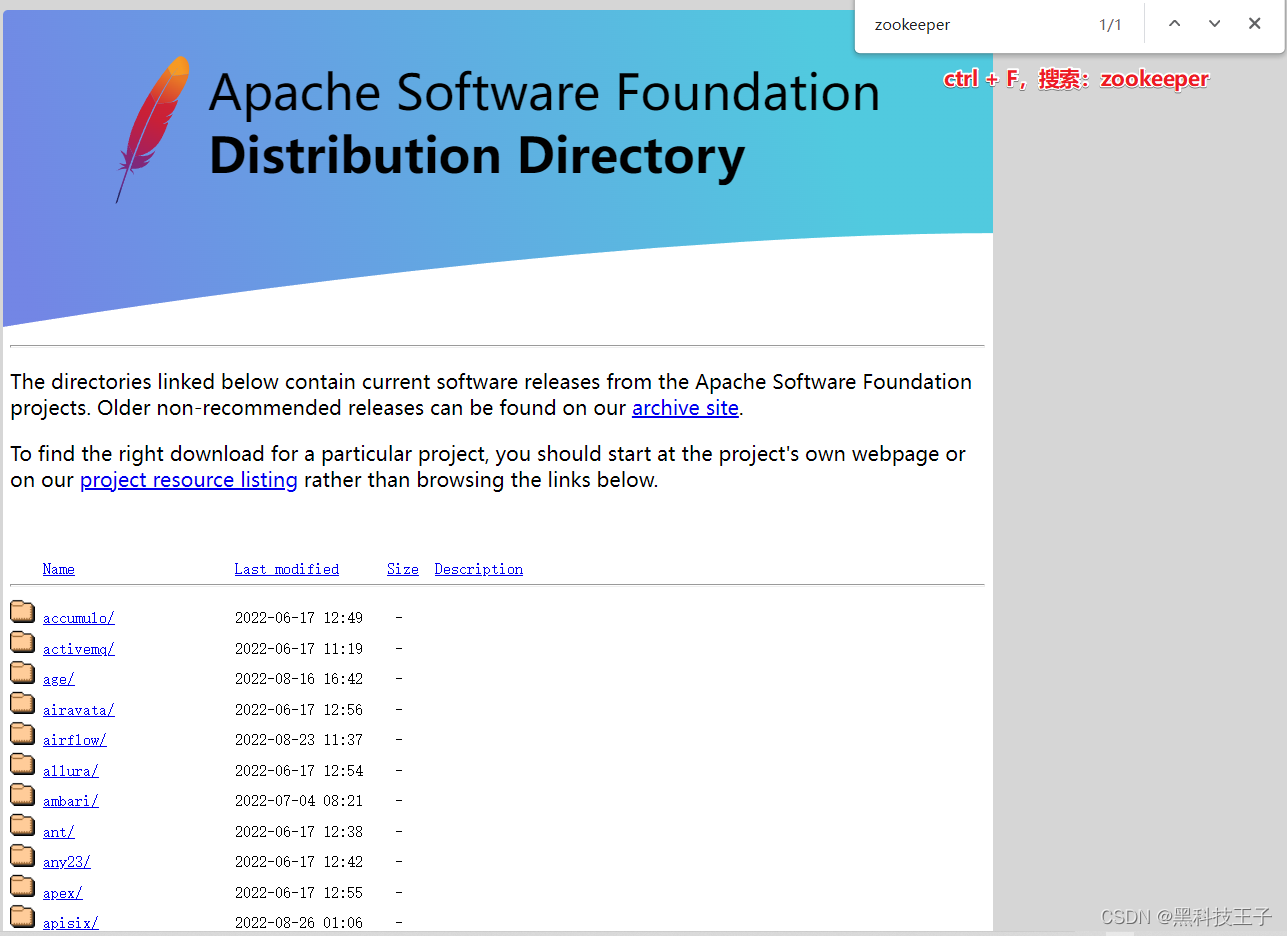
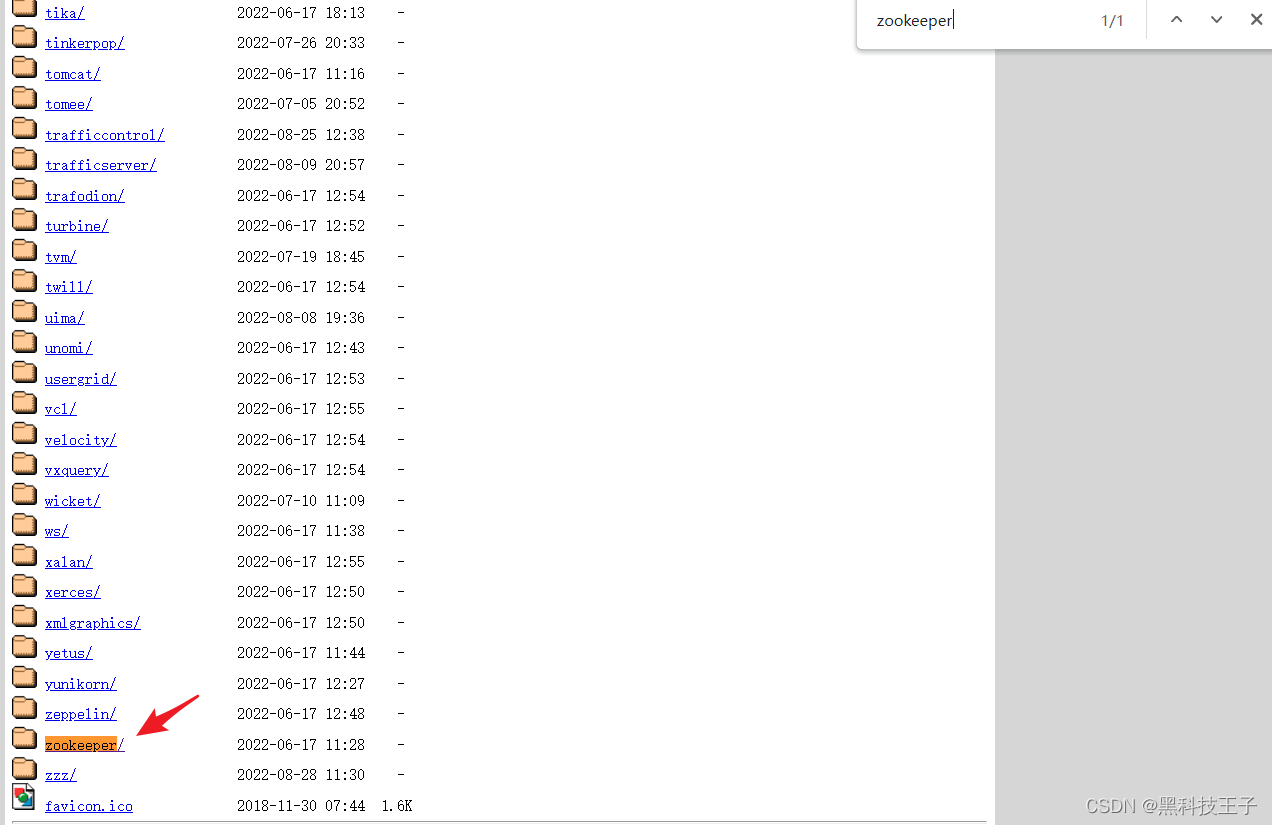
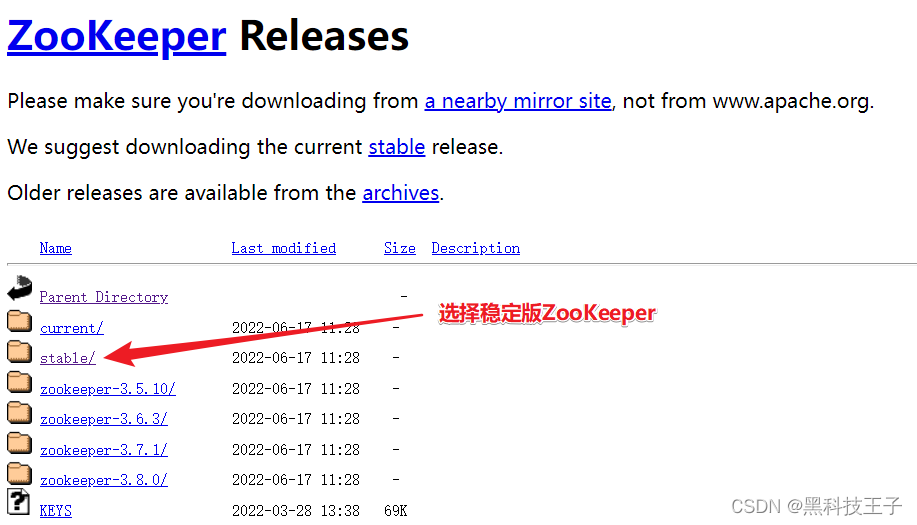

3、下载kafka安装包,kafka_2.12-3.0.1.tgz




1、修改主机名(分别单独执行)
# 修改主机名,在worker01上执行
hostnamectl set-hostname worker01
bash # 不重启,使修改主机名生效
# 修改主机名,在worker02上执行
hostnamectl set-hostname worker02
bash # 不重启,使修改主机名生效
# 修改主机名,在worker03上执行
hostnamectl set-hostname worker03
bash # 不重启,使修改主机名生效2、关闭防火墙(worker01、worker02、worker02都执行)
systemctl stop firewalld
systemctl disable firewalld
systemctl status firewalld3、配置/etc/hosts(worker01、worker02、worker02都执行)
cat >> /etc/hosts << EOF
192.168.19.130 worker01
192.168.19.131 worker02
192.168.19.132 worker03
EOF1、查询仓库jdk软件包(worker01、worker02、worker02都执行)
# 查询jdk软件包
yum list |grep jdk
# 安装系统对应版本
yum install -y java-1.8.0-openjdk-devel.x86_64
# 查看jdk是否配置生效
java -version
# 后续可以用jps查看,主机启动的所有java进程
jps
1、解压目录(worker01、worker02、worker03,都要执行)
# 创建目录
mkdir -p /home/kafaka-zookeeper
cd /home/kafaka-zookeeper
# 上传安装包apache-zookeeper-3.6.3-bin.tar.gz到该目录下
# 解压
tar -zxvf apache-zookeeper-3.6.3-bin.tar.gz
# 重命名
mv apache-zookeeper-3.6.3-bin apache-zookeeper-3.6.3
2、修改配置文件(worker01、worker02、worker03,都执行)
# 创建目录
mkdir -p /home/kafaka-zookeeper/apache-zookeeper-3.6.3/{data,logs}
# 修改配置文件名
cd /home/kafaka-zookeeper/apache-zookeeper-3.6.3/conf
mv zoo_sample.cfg zoo.cfg3、修改配置文件(worker01、worker02、worker03,都要执行)
vi zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/kafaka-zookeeper/apache-zookeeper-3.6.3/data
dataLogDir=/home/kafaka-zookeeper/apache-zookeeper-3.6.3/logs
clientPort=2181
server.1=192.168.19.130:2888:3888
server.2=192.168.19.131:2888:3888
server.3=192.168.19.132:2888:3888
4、创建myid
# 在 worker01、worker02、worker03 上都执行
cd /home/kafaka-zookeeper/apache-zookeeper-3.6.3/data
# 在 worker01、worker02、worker03 上都执行
touch myid
# 只在 192.168.19.130 worker01 上执行
echo 1 > /home/kafaka-zookeeper/apache-zookeeper-3.6.3/data/myid
# 只在192.168.19.131 worker02 上执行
echo 2 > /home/kafaka-zookeeper/apache-zookeeper-3.6.3/data/myid
# 只在192.168.19.132 worker03 上执行
echo 3 > /home/kafaka-zookeeper/apache-zookeeper-3.6.3/data/myid
5、zookeeper启动、停止
# zookeeper 启动
/home/kafaka-zookeeper/apache-zookeeper-3.6.3/bin/zkServer.sh start
# zookeeper 停止
/home/kafaka-zookeeper/apache-zookeeper-3.6.3/bin/zkServer.sh stop
# zookeeper 查看状态
/home/kafaka-zookeeper/apache-zookeeper-3.6.3/bin/zkServer.sh status
# 3台机器的状态
mode:follower # 从
mode:leader # 主
mode:follower # 从
# 运行客户端(后面介绍kafka注册)
/home/kafaka-zookeeper/apache-zookeeper-3.6.3/bin/zkCli.sh -server worker0x的IP:21813台主机,需要全部执行启动命令,查看zookeeper启动状态,如果正常选主,就启动成功了;反之,失败,需要检查日志 dataLogDir=/home/kafaka-zookeeper/apache-zookeeper-3.6.3/logs。

1、解压目录(worker01、worker02、worker03,都要执行)
# 进入目录
cd /home/kafaka-zookeeper
# 上传kafka_2.12-3.0.1.tgz到该目录下
# 解压安装包kafka_2.12-3.0.1.tgz
tar -zxvf kafka_2.12-3.0.1.tgz2、修改配置(worker01、worker02、worker03,都要执行)
# 创建目录
mkdir -p /home/kafaka-zookeeper/kafka_2.12-3.0.1/{data,logs}# 进入kafka_2.12-3.0.1的配置文件目录
cd /home/kafaka-zookeeper/kafka_2.12-3.0.1/config
# 备份配置文件
cp server.properties server.properties.bak
# 删除注释行
sed -i "/#/d" server.propertiesvim server.properties
# worker01 192.168.19.130 配置文件修改
broker.id=1
listeners=PLAINTEXT://192.168.19.130:9092
num.network.threads=12
num.io.threads=24
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/home/kafaka-zookeeper/kafka_2.12-3.0.1/logs
num.partitions=3
num.recovery.threads.per.data.dir=12
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.19.130:2181,192.168.19.131:2181,192.168.19.132:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
# 其它2台配置
# worker02 192.168.19.131 配置文件修改
broker.id=2
listeners=PLAINTEXT://192.168.19.131:9092
log.dirs=/home/kafaka-zookeeper/kafka_2.12-3.0.1/logs
num.partitions=3
zookeeper.connect=192.168.19.130:2181,192.168.19.131:2181,192.168.19.132:2181
# worker03 192.168.19.132 配置文件修改
broker.id=3
listeners=PLAINTEXT://192.168.19.132:9092
log.dirs=/home/kafaka-zookeeper/kafka_2.12-3.0.1/logs
num.partitions=3
zookeeper.connect=192.168.19.130:2181,192.168.19.131:2181,192.168.19.132:2181
3、启动kafka集群
# 启动kafka
nohup /home/kafaka-zookeeper/kafka_2.12-3.0.1/bin/kafka-server-start.sh /home/kafaka-zookeeper/kafka_2.12-3.0.1/config/server.properties &>> /home/kafaka-zookeeper/kafka_2.12-3.0.1/logs &4、验证kafka集群
cd /home/kafaka-zookeeper/kafka_2.12-3.0.1/bin
# 创建 kafka topic hkzs
./kafka-topics.sh --create --bootstrap-server 192.168.19.130:9092,192.168.19.131:9092,192.168.19.132:9092 --replication-factor 3 --partitions 3 --topic zbqy
# 列出所有的topic
./kafka-topics.sh --list --bootstrap-server 192.168.19.130:9092
# 在worker01 192.168.19.130 上发布消息
./kafka-console-producer.sh --broker-list 192.168.19.130:9092 --topic hkzs
>我过的挺好
>zoo
# 在worker02 192.168.19.131 上消费
./kafka-console-consumer.sh --bootstrap-server 192.168.19.131:9092 --topic hkzs --from-beginning
我过的挺好
zoo
# 在worker02 192.168.19.132 上消费
./kafka-console-consumer.sh --bootstrap-server 192.168.19.132:9092 --topic hkzs --from-beginning
我过的挺好
zoo5、验证zookeeper集群
cd /home/kafaka-zookeeper/apache-zookeeper-3.6.3/bin
# 进入zookeeper客户端,如果是自定义端口一定要 -server 指定IP:port,否则默认进入2181端口
./zkCli.sh -server 192.168.19.131:2181
# 查看服务
WatchedEvent state:SyncConnected type:None path:null
[zk: 192.168.19.131:2181(CONNECTED) 0] ls /brokers/ids
[1, 2, 3]
[zk: 192.168.19.131:2181(CONNECTED) 1] ls /brokers/topics
[__consumer_offsets, hkzs]
# 进入zookeeper客户端,不是自定义
./zkCli.sh
[zk: localhost:2181(CONNECTED) 1] ls /
[admin, brokers, cluster, config, consumers, controller, controller_epoch, feature, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]
[zk: localhost:2181(CONNECTED) 2] ls /config
[brokers, changes, clients, ips, topics, users]
[zk: localhost:2181(CONNECTED) 3] ls /config/brokers
[]
[zk: localhost:2181(CONNECTED) 4] ls /config/topics
[__consumer_offsets, hkzs, zbqy]
Unity自动旋转动画1.开门需要门把手先动,门再动2.关门需要门先动,门把手再动3.中途播放过程中不可以再次进行操作觉得太复杂?查看我的文章开关门简易进阶版效果:如果这个门可以直接打开的话,就不需要放置"门把手"如果门把手还有钥匙需要旋转,那就可以把钥匙放在门把手的"门把手",理论上是可以无限套娃的可调整参数有:角度,反向,轴向,速度运行时点击Test进行测试自己写的代码比较垃圾,命名与结构比较拉,高手轻点喷,新手有类似的需求可以拿去做参考上代码usingSystem.Collections;usingSystem.Collections.Generic;usingUnityEngine;u
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式
目录一、安装包链接二、安装详细步骤1.安装Wireshark和WinPcap2.安装OracleVMVirtualBox3.安装ensp三、安装后注册四、启动路由器出现40错误怎么解决一、安装包链接二、安装详细步骤链接:https://pan.baidu.com/s/1QbUUYMOMIV2oeIKHWP1SpA?pwd=xftx提取码:xftx1.安装Wireshark和WinPcap找到Wireshark安装包所在文件夹,双击它,按照以下步骤安装。2.安装OracleVMVirtualBox找到OracleVMVirtualBox安装包所在文件夹,双击它,按照以下步骤安装。注:可自定义安装
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
Nginx安装1.官网下载Nginx2.使用XShell和Xftp将压缩包上传到Linux虚拟机中3.解压文件nginx-1.20.2.tar.gz4.配置nginx5.启动nginx6.拓展(修改端口和常用命令)(一)修改nginx端口(二)常用命令1.官网下载Nginxhttp://nginx.org/en/download.html这里我下载的是1.20.2版本,大家按需下载对应稳定版即可2.使用XShell和Xftp将压缩包上传到Linux虚拟机中没有XShell可以参考《Linux操作系统CentOS7连接XShell》3.解压文件nginx-1.20.2.tar.gz1)检查是否存
因学习需要用到keras,通过查找较多资料最终完成Anaconda、TensorFlow和Keras的简单安装。因为网上的相关资料较多但大部分不够全面,查找起来不太方便,因此自己记录一下成功下载安装的详细过程,顺便推荐一下借鉴的写的很好的相关教程文章。keras需要在TensorFlow之上才能运行,所以要先安装TensorFlow,而TensorFlow只能在3.7以前的python版本中运行,所以需要先创建一个基于python3.6的虚拟环境,因此便需要先下载Anaconda。一、Anaconda3下载和安装Anaconda下载安装教程原文链接:https://blog.csdn.net/
【动态规划】一、背包问题1.背包问题总结1)动规四部曲:2)递推公式总结:3)遍历顺序总结:2.01背包1)二维dp数组代码实现2)一维dp数组代码实现3.完全背包代码实现4.多重背包代码实现一、背包问题1.背包问题总结暴力的解法是指数级别的时间复杂度。进而才需要动态规划的解法来进行优化!背包问题是动态规划(DynamicPlanning)里的非常重要的一部分,关于几种常见的背包,其关系如下:在解决背包问题的时候,我们通常都是按照如下五部来逐步分析,把这五部都搞透了,算是对动规来理解深入了。1)动规四部曲:(1)确定dp数组及其下标的含义(2)确定递推公式(3)dp数组的初始化(4)确定遍历顺
文章目录华为OD面试流程1.mysql数据库建了两个字段,且设置了联合索引,如果其中有一个字段为空会出现什么问题?2.谈谈springIOC的理解,有什么好处,解决了什么问题3.谈谈springAOP的理解,切面编程有没有实际应用,有哪些注解,作用是什么,有那些应用场景?4.Erika和zookeeper有了解过吗,作用是什么,主要解决了什么问题5.谈谈JDK、JRE、JVM的理解,区别是什么6.谈谈对泛型的理解7.JVM的组成华为OD面试流程机试:三道算法题,关于机试,橡皮擦已经准备好了各语言专栏,可以直接订阅。性格测试:机试技术一面(本专栏核心)技术二面(本专栏核心)主管面试定级定薪发of