这是我第一次使用FreeRTOS构建STM32的项目,踩了好些坑,又发现了我缺乏对于操作系统的内存及其空间的分配的知识,故写下文档记录学习成果。
文章最后要解决的问题是,如何恰当地分配FreeRTOS中的堆、任务栈的空间。但是在概念的理解上,也需要知道STM32内存的相关知识。所以首先大致介绍一下STM32的内存结构。
STM32的数据在物理上分别储存在RAM和Flash中。RAM可读可写,掉电清零。Flash可读可写,但是读写时间很长,能掉电储存,并且一般空间比RAM大很多。
在关于如何使用RAM和Flash的问题上,STM32的内存又有了6个储存数据段和3种储存属性区的概念。

数据段,储存已初始化的,且初始化不为0的全局变量和静态变量。
Block Started by Symbol。储存未初始化的,或初始化为0的全局变量和静态变量。
代码段,储存程序代码。
储存只读常量。
堆,存放进程运行中被动态分配的内存段。其可用大小定义在启动文件startup_stm32fxx.s中,由程序员使用malloc()和free()函数进行分配和释放。
栈,其大小定义在启动文件startup_stm32fxx.s中,由系统自动分配和释放。可存放局部变量、函数的参数和返回值,中断发生时能保存现场。但是static声明的局部静态变量不储存在栈中,而是放在data数据段。
烧写到Flash中,可以长久保存。text代码段和constdata都属于RO。由于需要掉电储存,RO里也保存了一份data的数据。
储存在RAM中。data属于此区。上电时单片机会将Flash中保存的data类型数据复制到RAM中,以供读写使用。
零初始化区,同样储存在RAM里。系统上电时会把此区域的数据进行0初始化。bss,heap,stack均属于这个区域。
STM32的RAM上有RW和ZI两个属性区,里边包含了data,bss,堆(heap),栈(stack)这几个数据段。这里是程序运行的所在。
Flash中有RO区,包含了text、constdata和data三个段,这里则是程序本体所在。
FreeRTOS中的堆也属于ZI区,但是它与STM32内存结构中的堆并不占用相同的空间,两个堆同时存在。以下出现的堆(heap)表示FreeRTOS堆,另外在STM32启动文件中定义大小的堆称为系统堆。
void *pvPortMalloc( size_t xSize ); //申请内存
void vPortFree( void *pv ); //释放内存
以上函数控制的是FreeRTOS堆;系统堆则应使用malloc()和free()来分配和释放。
FreeRTOS有5种heap的实现方式,在STM32CubeMX中默认为heap_4.c。这种方式可以满足大部分使用需求,暂时不用关注其实现细节。
这一个堆的大小定义在FreeRTOSConfig.c中:
#define configTOTAL_HEAP_SIZE ((size_t)3072)
FreeRTOS创建任务时默认的任务栈大小为128字,在32位系统中即为128*4=512Byte,再加上TCB块占用84Byte,一共596Byte。而大小为3072Byte的堆允许创建3个这样的任务,占用约1800Byte。堆中剩余的部分则存放了系统内核、信号量、队列、任务通知等数据。
需要创建更多任务时,堆的大小可自行修改。用RAM的空间减去已分配的空间,即为能给堆分配的最大空间:
Space=RAM−bss−data−SysHeap−Stack
FreeRTOS堆和任务栈在运行中具有很强的动态性,其大小很难估计。
我们在实际使用中,可以先把空间调整得大一些。程序正常运行后,再通过一些API查看堆栈剩余的空间大小,估算程序运行中需求内存空间的最大值。最后将这个最大值乘一个安全系数,得到最终应该分配的空间大小。安全系数推荐1.3到1.5。
查看堆(heap)剩余空间的API有:
size_t xPortGetFreeHeapSize( void ); //获取当前未分配的内存堆大小
size_t xPortGetMinimumEverFreeHeapSize( void ); //获取未分配的内存堆历史最小值
它们返回值的单位都是字节。
需要注意的是,xPortGetFreeHeapSize()在使用heap_3.c时不能被调用;xPortGetMinimumEverFreeHeapSize()则只能在使用heap_4.c或heap_5.c时生效。
UBaseType_t uxTaskGetStackHighWaterMark( TaskHandle_t xTask );
这个函数可以获取一个任务从创建好到调用此函数时,任务栈空间的历史最小剩余值(HighWaterMark)。使用这个函数时需注意,它的返回值的单位是字(STM32里1个字长为4个字节)。
这个API默认是关闭状态,需要手动在Cubemx(或配置文件中)将宏INCLUDE_uxTaskGetStackHighWaterMark置为1。
我在使用过这些API后发现,他们本身也会占用相当的内存空间,尤其是uxTaskGetStackHighWaterMark(),会拖慢任务运行速度。所以在程序的正式版中,应该将他们删除。
在使用STM32编程时,一般情况下我们不会关注堆栈空间的大小,因为在STM32的启动文件中,已经帮我们预先设置好了堆栈空间的大小。如下图所示的启动代码中,Stack栈的大小为:0x400(1024Byte),Heap堆的大小为:0x200(512Byte)。
1、若工程中使用的局部变量较多,定义的数据长度较大时,若不调整栈的空间大小,则会导致程序出现栈溢出,程序运行结果与预期的不符或程序跑飞。这时我们就需要手动的调整栈的大小。
2、当工程中使用了malloc动态分配内存空间时,这时分配的空间就为堆的空间。所以若默认的堆空间大小不满足工程需求时,就需要手动调整堆空间的大小。
裸机程序里面这两个值 在程序中我要怎么计算才能知道分配多少合适?
1,Stack Size,一般小工程0X400足够,我们综合实验才设置0X1000就够用,所以默认无需设置太大。
2,Heap Size,如果没有用到标准库的malloc,就是废物,纯属浪费内存,所以直接设置为0即可。
在嵌入式使用UCOSII和LUA的时候堆栈也很重
1,Stack Size,0X2000足够,我们综合实验才设置0X1000就够用,所以默认无需设置太大。
2,Heap Size,如果没有用到标准库的malloc,就是废物,纯属浪费内存,所以直接设置为0即可。
实际应用中我的设计如下:
Stack_Size EQU 0x00002000
AREA STACK, NOINIT, READWRITE, ALIGN=3
Stack_Mem SPACE Stack_Size
__initial_sp
; <h> Heap Configuration
; <o> Heap Size (in Bytes) <0x0-0xFFFFFFFF:8>
; </h>
Heap_Size EQU 0x00002000
AREA HEAP, NOINIT, READWRITE, ALIGN=3
运行freertos系统的大部分都是资源有限的MCU,所以对于ram我们都要考虑尽量的节省,避免资源浪费,从而也可以针对项目选择性价比更好的mcu。
首先要配置freertos的堆(heap)空间,创建任务我们还需要为每个任务分配栈(stack)空间,那么针对freertos的堆栈空间到底该如何确定?
freertos从V9版本以后同时支持静态内存和动态内存分配方式。静态内存分配在编译时候就会对freertos的内核对象分配ram空间。动态分配都是在程序运行起来以后从堆空间上分配的。这里我们也只讨论动态内存分配,动态内存分配的好处是可以在删除对象的时候释放掉内存的空间。从而保证ram的可持续利用!
先看下图弄清楚freertos的heap空间和任务栈空间的不同与联系。
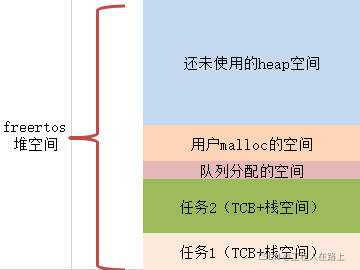
假设在freertos的配置选项中已经配置使用动态内存分配方式。如上图所示,其他比如任务或者队列或者用户使用 pvPortMalloc() 分配的空间都从heap堆上面划分。所以我相信你不会做把任务栈分配的比heap堆还大的傻事!
好了,这个关系搞清楚,那么又该如何定heap的空间大小呢,可以先进行一个粗略的计算,假设任务1分配2kbytes栈,任务2分配3kbytes栈,队列大概占1k,用户malloc大概2k,这么算一共就是8k。那么在资源有限的情况下可以先把heap空间分个15k。
因为程序运行起来实际占用heap的空间不好计算那么准,那么我们可以借助freertos的API来准确的得出空闲的heap空间和用的最对时候的空闲值。这两个API如下:
xPortGetFreeHeapSize()
这个函数可以获取调用时堆中空闲内存的大小,以字节为单位。使用它可以优化堆的大小。需要注意,当使用heap_3时是不能调用这个函数的。
xPortGetMinimumEverFreeHeapSize()
此函数返回FreeRTOS应用程序开始运行之后曾经存在的最小的未被分配的存储空间的字节数。它的返回值指示了应用程序离将要耗尽堆空间的接近程度。需要注意xPortGetMinimumEverFreeHeapSize()只在使用heap_4或者heap_5时生效。
在随便一个任务运行过程中,我们可以把这两个函数的返回值打印出来,比如分别为4200和3000,那么我们就清晰的知道了heap在分配出去最多的时候还剩余3000bytes空闲的,那么我们就可以把heap空间优化减小3000bytes。但是实际过程中请大方一点,不要算的那么死,给freertos留下一点喘息的的机会。
堆空间的大小还容易估算一点,但是任务栈空间具体占用多少想计算出来可是复杂很多的。比如任务运行过程中函数调用的圧栈,局部变量等都存在任务的栈空间上,所以我们一开始也只能尽量分配个大一点的值,之后再来调整。那么得出任务栈空间具体还有多少剩余也是有API可以调用的:
uxTaskGetStackHighWaterMark()
但是该API使用是有配置开关的,在freertosConfig.h中把 INCLUDE_uxTaskGetStackHighWaterMark 配置为1打开开关
比如我们在一个任务中如下调用:
printf(" the min free stack size is %d \r\n",
(int32_t)uxTaskGetStackHighWaterMark(NULL));
就可以打印出来该任务自启动起来最小剩余栈空间大小。然后我们就可以计算出最大使用的大小,一般可以再乘以1.5左右作为最终分配的值。需要注意的是该函数不像前面两个返回的是bytes,而返回的以字为单位,真实的bytes需要乘以4.
所以总体的原则就是:先分大再调小最终把它确定好。
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
文章目录1.开发板选择*用到的资源2.串口通信(个人理解)3.代码分析(注释比较详细)1.主函数2.串口1配置3.串口2配置以及中断函数4.注意问题5.源码链接1.开发板选择我用的是STM32F103RCT6的板子,不过代码大概在F103系列的板子上都可以运行,我试过在野火103的霸道板上也可以,主要看一下串口对应的引脚一不一样就行了,不一样的就更改一下。*用到的资源keil5软件这里用到了两个串口资源,采集数据一个,串口通信一个,板子对应引脚如下:串口1,TX:PA9,RX:PA10串口2,TX:PA2,RX:PA32.串口通信(个人理解)我就从串口采集传感器数据这个过程说一下我自己的理解,
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
如thisanswer中所述,Array.new(size,object)创建一个数组,其中size引用相同的object。hash=Hash.newa=Array.new(2,hash)a[0]['cat']='feline'a#=>[{"cat"=>"feline"},{"cat"=>"feline"}]a[1]['cat']='Felix'a#=>[{"cat"=>"Felix"},{"cat"=>"Felix"}]为什么Ruby会这样做,而不是对object进行dup或clone? 最佳答案 因为那是thedocumenta
这会导致Ruby出现内存问题吗?我知道如果大小超过10KB,Open-URI会写入TempFile。但是HTTParty会在写入TempFile之前尝试将整个PDF保存到内存吗?src=Tempfile.new("file.pdf")src.binmodesrc.writeHTTParty.get("large_file.pdf").parsed_response 最佳答案 您可以使用Net::HTTP。参见thedocumentation(特别是标题为“流媒体响应机构”的部分)。这是文档中的示例:uri=URI('http://e
我有这个ruby代码:defget_sumnreturn0ifn似乎正在为999之前的值工作。当我尝试9999时,它给了我这个:stackleveltoodeep(SystemStackError)所以,我添加了这个:RubyVM::InstructionSequence.compile_option={:tailcall_optimization=>true,:trace_instruction=>false}但什么也没发生。我的ruby版本是:ruby1.9.3p392(2013-02-22revision39386)[x86_64-darwin12.2.1]我还增加了机器的堆栈大
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c
LL库和HAL库简介LL:Low-Layer,底层库HAL:HardwareAbstractionLayer,硬件抽象层库LL库和hal库对比,很精简,这实际上是一个精简的库。LL库的配置选择如下:在STM32CUBEMX中,点击菜单的“ProjectManager”–>“AdvancedSettings”,在下面的界面中选择“AdvancedSettings”,然后在每个模块后面选择使用的库总结:1、如果使用的MCU是小容量的,那么STM32CubeLL将是最佳选择;2、如果结合可移植性和优化,使用STM32CubeHAL并使用特定的优化实现替换一些调用,可保持最大的可移植性。另外HAL和L