分解式
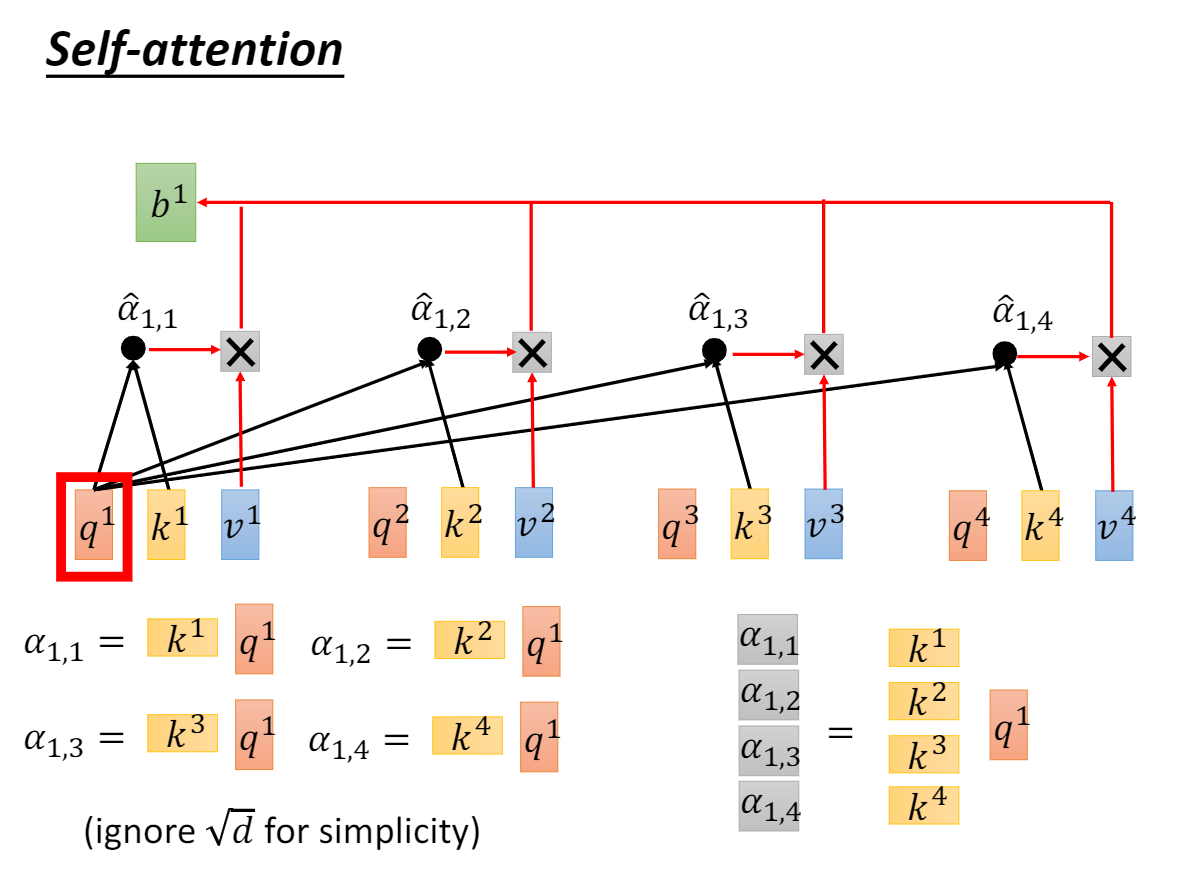
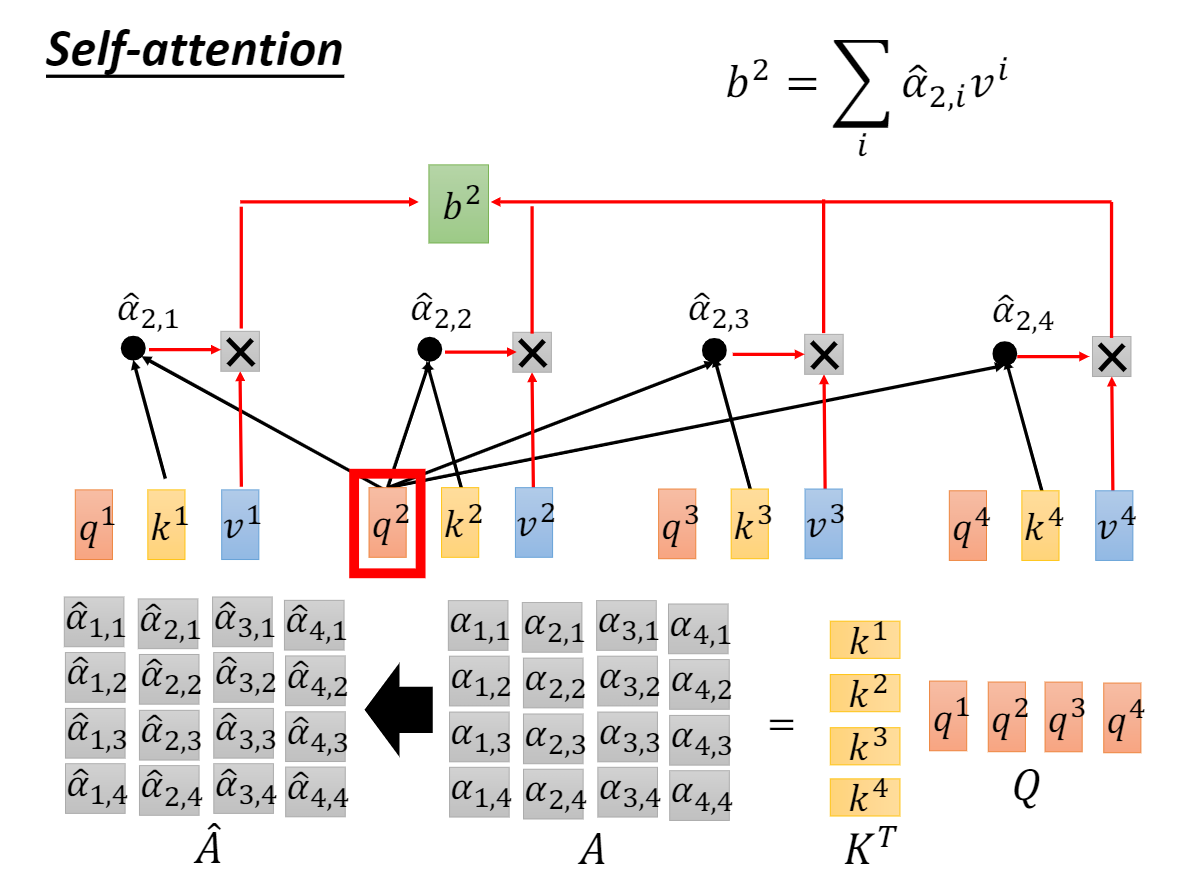
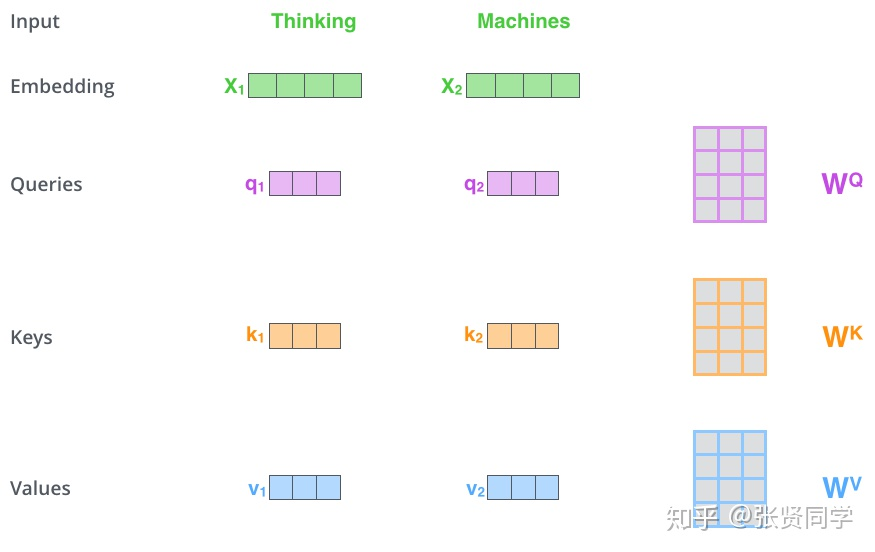
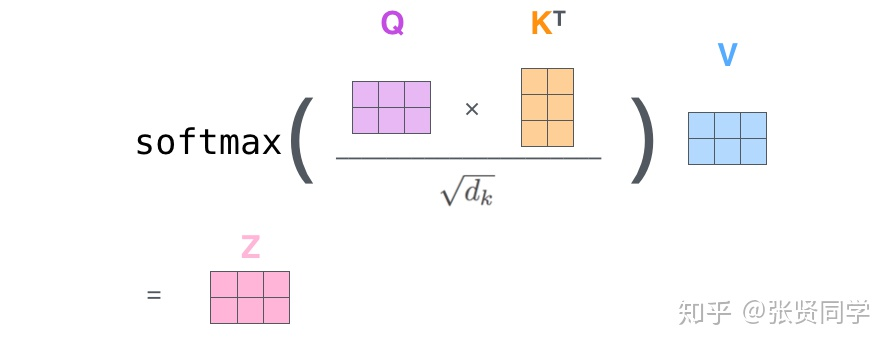
We suspect that for large values d_k, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients.To counteract this effect, we scale the dot products by sqrt(d_k)
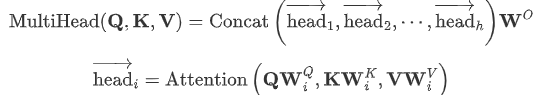
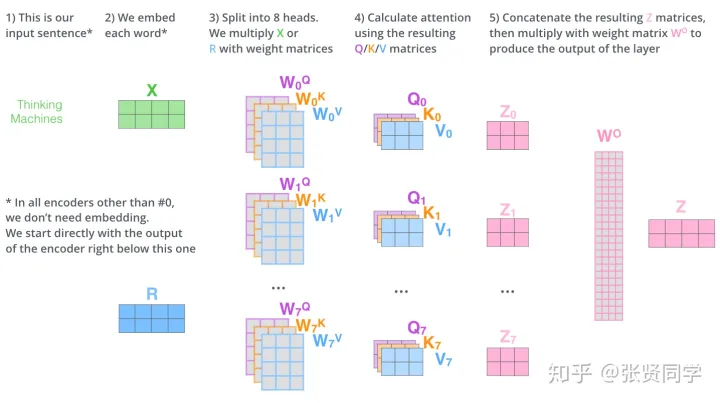
torch.nn.MultiheadAttention(embed_dim, num_heads, dropout=0.0, bias=True, add_bias_kv=False, add_zero_attn=False, kdim=None, vdim=None)
forward(query, key, value, key_padding_mask=None, need_weights=True, attn_mask=None)
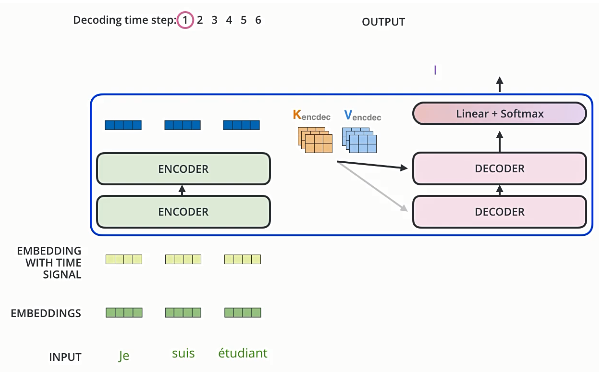
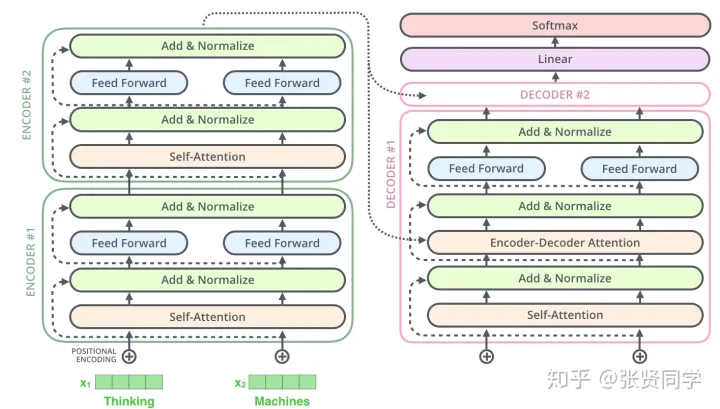
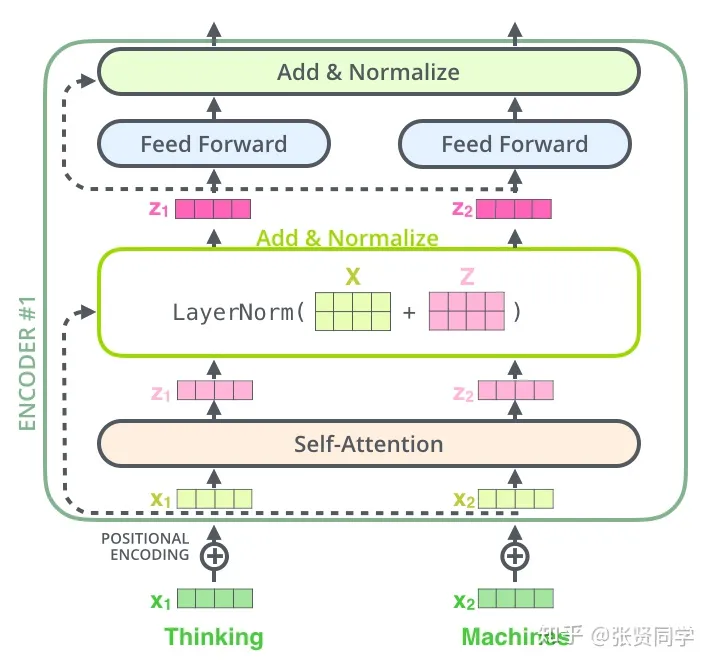
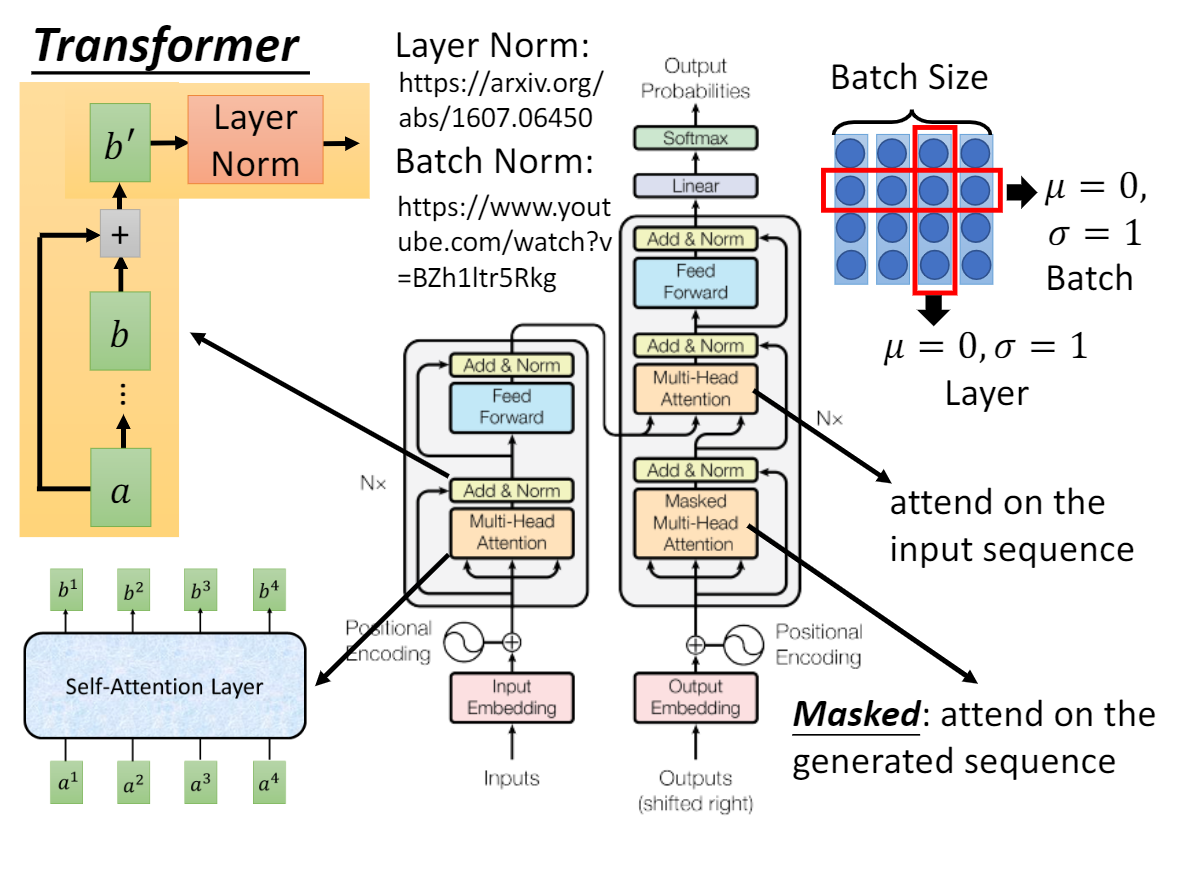
Self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position.We need to prevent leftward information flow in the decoder to preserve the auto-regressive property.We implement this inside of scaled dot-product attention by masking out (setting to −∞) all values in the input of the softmax which correspond to illegal connections.
attention = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale if mask is not None: attention = attention.masked_fill(mask == 0, -1e10) attention = self.do(torch.softmax(attention, dim=-1)) x = torch.matmul(attention, V)

我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
#app/models/product.rbclassProduct我从Controller调用方法1。当我运行程序时。我收到一个错误:method_missing(atlinemethod2(param2)).rbenv/versions/2.3.1/lib/ruby/gems/2.3.0/gems/activerecord-5.0.0/lib/active_record/relation/batches.rb:59:in`block(2levels)infind_each... 最佳答案 classProduct说明:第一个是类
我明白了defa(&block)block.call(self)end和defa()yieldselfend导致相同的结果,如果我假设有这样一个blocka{}。我的问题是-因为我偶然发现了一些这样的代码,它是否有任何区别或者是否有任何优势(如果我不使用变量/引用block):defa(&block)yieldselfend这是一个我不理解&block用法的具体案例:defrule(code,name,&block)@rules=[]if@rules.nil?@rules 最佳答案 我能想到的唯一优点就是自省(introspecti
我正在尝试获得良好的Ruby编码风格。为防止意外调用具有相同名称的局部变量,我总是在适当的地方使用self.。但是现在我偶然发现了这个:classMyClass上面的代码导致错误privatemethodsanitize_namecalled但是当删除self.并仅使用sanitize_name时,它会起作用。这是为什么? 最佳答案 发生这种情况是因为无法使用显式接收器调用私有(private)方法,并且说self.sanitize_name是显式指定应该接收sanitize_name的对象(self),而不是依赖于隐式接收器(也是
我的rails3.1.6应用程序中有一个自定义访问器方法,它为一个属性分配一个值,即使该值不存在。my_attr属性是一个序列化的哈希,除非为空白,否则应与给定值合并指定了值,在这种情况下,它将当前值设置为空值。(添加了检查以确保值是它们应该的值,但为简洁起见被删除,因为它们不是我的问题的一部分。)我的setter定义为:defmy_attr=(new_val)cur_val=read_attribute(:my_attr)#storecurrentvalue#makesureweareworkingwithahash,andresetvalueifablankvalueisgiven
是否可以在不实际下载文件的情况下检查文件是否存在?我有这么大的(~40mb)文件,例如:http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm这与ruby不严格相关,但如果发件人可以设置内容长度就好了。RestClient.get"http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm",headers:{"Content-Length"=>100} 最佳答案
我在这方面尝试了很多URL,在我遇到这个特定的之前,它们似乎都很好:require'rubygems'require'nokogiri'require'open-uri'doc=Nokogiri::HTML(open("http://www.moxyst.com/fashion/men-clothing/underwear.html"))putsdoc这是结果:/Users/macbookair/.rvm/rubies/ruby-2.0.0-p481/lib/ruby/2.0.0/open-uri.rb:353:in`open_http':404NotFound(OpenURI::HT
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG