title: 红黑树
date: 2022-03-31 10:41:30
sidebar: auto
categories:
- 数据结构
- 二叉树
tags:
- 红黑树
1.2 树的特点


| Trees | Graphs |
|---|---|
| 1. A tree is a special kind of graph that there are never multiple paths exist. There is always one way to get from A to B. | 1. A graph is a system that has multiple ways to get from any point A to any other point B. |
| 2. Tree must be connected. | 2. Graph may not be connected. |
| 3. Since it connected we can reach from one particular node to all other nodes. This kind of searching is called traversal. | 3. Traversal always not applicable on graphs. Because graphs may not be connected. |
| 4. Tree contains no loops, no circuits. | 4. Graph may contain self-loops, loops. |
| 5. There must be a root node in tree. | 5. There is no such kind of root node in graphs |
| 6. We do traversal on trees. That mean from a point we go to each and every node of tree. | 6. We do searching on graphs. That means starting from any node try to find a particular node which we need. |
| 7. pre-order, in-order, post-order are some kind of traversals in trees. | 7. Breath first search, Depth first search, are some kind of searching algorithms in graphs. |
| 8. Trees are directed acyclic graphs. | 8. Graphs are cyclic or acyclic. |
| 9. Tree is a hierarchical model structure. | 9. Graph is network model. |
| 10. All trees are graphs. | 10. But all graphs are not trees. |
| 11. Based on different properties trees can be classified as Binary tree, Binary search tree, AVL trees, Heaps. | 11. We differ the graphs like directed graphs and undirected graphs. |
| 12. If tree have “n” vertices then it must have exactly “n-1” edges only. | 12. In graphs number of edges doesn’t depend on the number of vertices. |
| 13. Main use of trees is for sorting and traversing. | 13. Main use of graphs is coloring and job scheduling. |
| 14. Less in complexity compared to graphs. | 14. High complexity than trees due to loops. |

除最后一层无任何子节点外,每一层上的所有结点都有两个子结点的二叉树
满二叉树特点:

除最后一层外,每一层上的结点数均达到最大值;在最后一层上只缺少右边的若干结点
完全二叉树特点:
堆的实现一般基于完全二叉树

什么是平衡二叉查找树
由前苏联的数学家 Adelse-Velskil 和 Landis 在 1962 年提出的高度平衡的二叉树,根据科学家的英文名也称为 AVL 树。它具有如下几个性质:
可以是空树。
平衡之意,如天平,即两边的分量大约相同。
最早的自平衡二叉搜索树结构
第一个自平衡二叉查找树就是AVL 树,它规定,每个结点的左右子树的高度之差不超过 1。在插入或删除结点,打破平衡后,就会通过一次或多次树旋转来重新平衡。
为什么有平衡二叉查找树
平衡二叉查找树的缺点
AVL 树是严格平衡的,适用于查找密集型应用程序,因为在频繁插入或删除结点的场景下,它花费在树旋转的代价太高。
而红黑树就是一种折中方案,它不追求完美平衡,只求部分达到平衡,从而降低在调整时树旋转次数。

在二叉树的第i层上最多有2 i-1 个节点 。(i>=1)
二叉树中如果深度为k,那么最多有2k-1个节点。(k>=1)
n0=n2+1 n0表示度数为0的节点 n2表示度数为2的节点
在完全二叉树中,具有n个节点的完全二叉树的深度为[log2n]+1,其中[log2n]+1是向下取整。
若对含 n 个结点的完全二叉树从上到下且从左至右进行 1 至 n 的编号,则对完全二叉树中任意一个编号为 i 的结点:
(1) 若 i=1,则该结点是二叉树的根,无双亲, 否则,编号为 [i/2] 的结点为其双亲结点;
(2) 若 2i>n,则该结点无左孩子, 否则,编号为 2i 的结点为其左孩子结点;
(3) 若 2i+1>n,则该结点无右孩子结点, 否则,编号为2i+1 的结点为其右孩子结点
红黑树的英文是“Red-Black Tree",简称R-B Tree。
红黑树是一种二叉查找树,通过设置一些规则来保证二叉搜索树的平衡性,使二叉搜索树不会在极端情况下变成链表。
红黑树也是一种平衡二叉查找树的变体,它的左右子树高差有可能大于1,所以红黑树不是严格意义上的平衡二叉树(AVL),但对之进行平衡的代价较低, 其平均统计性能要强于 AVL。

为了更好地理解什么是红黑树以及这种看起来特殊的数据结构是如何被提出的,我们首先需要了解一下2-3树,这种数据结构与红黑树是等价的。
说到红黑树,就不得不提 2-3 树,因为,红黑树可以说就是它的一种特殊实现,对它有所了解,非常有助于理解红黑树。




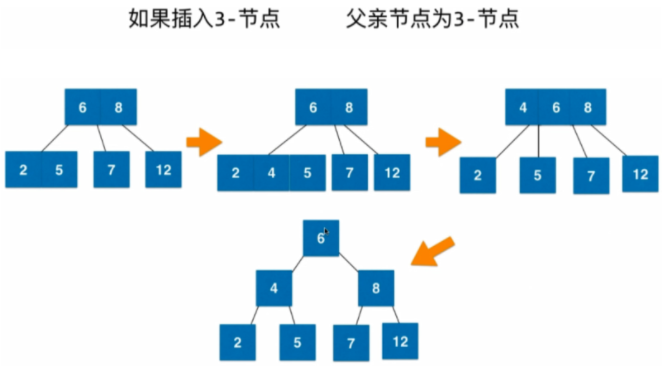



与2-3树添加元素是等价的
2-3 树插入的都是叶子结点,红黑树插入的结点都是红色的,因为在 2-3 树中,待插入结点都认为可以插入到一个多值结点中。
在分析插入和删除之前,先了解下什么是树旋转。树旋转是二叉树中调整子树的一种操作,常用于调整树的局部平衡性,它包含两种方式,左旋转和右旋转。

其实旋转操作很容易理解:左旋转就是将用两个结点中的较小者作为根结点变为将较大者作为根结点,右旋转刚好于此相反,如上图所示:
红黑树的旋转其实就是为了确保和其结构相同的 2-3树的一一对应关系,同时保证红黑树的有序性和平衡性。
增加一个元素右倾:进行一次左旋转


颜色翻转:



右旋转:







左倾红黑树(Left-leaning Red-Black Tree)是红黑树的一种变种,它的主要思想是将红色节点向左倾斜,从而简化插入和删除操作的实现。在左倾红黑树中,所有节点都被标记为红色或黑色,而且满足以下性质:
下面是左倾红黑树的Java代码实现:
public class LeftLeaningRedBlackTree<Key extends Comparable<Key>, Value> {
private static final boolean RED = true;
private static final boolean BLACK = false;
private Node root;
private class Node {
private Key key;
private Value val;
private Node left, right;
private boolean color;
public Node(Key key, Value val, boolean color) {
this.key = key;
this.val = val;
this.color = color;
}
}
private boolean isRed(Node x) {
if (x == null) return false;
return x.color == RED;
}
// 坐旋转,坐旋转的同时变色
private Node rotateLeft(Node h) {
Node x = h.right;
h.right = x.left;
x.left = h;
x.color = h.color;
h.color = RED;
return x;
}
// 右旋转,右旋转的同时变色
private Node rotateRight(Node h) {
Node x = h.left;
h.left = x.right;
x.right = h;
x.color = h.color;
h.color = RED;
return x;
}
private void flipColors(Node h) {
h.color = RED;
h.left.color = BLACK;
h.right.color = BLACK;
}
public void put(Key key, Value val) {
root = put(root, key, val);
root.color = BLACK;
}
private Node put(Node h, Key key, Value val) {
if (h == null) return new Node(key, val, RED);
int cmp = key.compareTo(h.key);
if (cmp < 0) h.left = put(h.left, key, val);
else if (cmp > 0) h.right = put(h.right, key, val);
else h.val = val;
// 左旋
if (isRed(h.right) && !isRed(h.left)) h = rotateLeft(h);
// 右旋
if (isRed(h.left) && isRed(h.left.left)) h = rotateRight(h);
// 颜色翻转
if (isRed(h.left) && isRed(h.right)) flipColors(h);
return h;
}
}
在这个实现中,我们使用了三种基本操作来维护左倾红黑树的性质:
在插入节点时,我们首先按照二叉搜索树的方式找到要插入的位置,并将节点标记为红色。然后,我们检查当前节点的父节点、父节点的兄弟节点和祖父节点的颜色,根据需要进行旋转和颜色翻转,以保证左倾红黑树的性质不被破坏。
在这个实现中,我们将所有空节点都视为黑色节点,并将根节点标记为黑色。这些约定使得插入操作更加简单,同时保证了左倾红黑树的性质。
总的来说,左倾红黑树是一种比较优秀的数据结构,它能够在保持红黑树性质的前提下,简化插入和删除操作的实现,同时也能够保持良好的平衡性能。
RB-Tree和AVL树作为BBST,其实现的算法时间复杂度相同,AVL作为最先提出的BBST,貌似RB-tree实现的功能都可以用AVL树是代替,那么为什么还需要引入RB-Tree呢?
AVL更平衡,结构上更加直观,时间效能针对读取而言更高;维护稍慢,空间开销较大。
红黑树,读取略逊于AVL,维护强于AVL,空间开销与AVL类似,内容极多时略优于AVL,维护优于AVL。
基本上主要的几种平衡树看来,红黑树有着良好的稳定性和完整的功能,性能表现也很不错,综合实力强,在诸如STL的场景中需要稳定表现。
红黑树的查询性能略微逊色于AVL树,因为其比AVL树会稍微不平衡最多一层,也就是说红黑树的查询性能只比相同内容的AVL树最多多一次比较,但是,红黑树在插入和删除上优于AVL树,AVL树每次插入删除会进行大量的平衡度计算,而红黑树为了维持红黑性质所做的红黑变换和旋转的开销,相较于AVL树为了维持平衡的开销要小得多
红黑树是一种自平衡的二叉搜索树,它可以在保持二叉搜索树的性质下,保持树的高度平衡,从而保证了树操作的时间复杂度在最坏情况下也是O(log n)。由于其优秀的性能表现,红黑树被广泛应用于Java的TreeMap和TreeSet中。
TreeMap和TreeSet都是基于红黑树实现的数据结构,它们分别用于实现基于键的有序映射和基于元素的有序集合。它们都支持一系列的操作,如插入、删除、查找最大值、查找最小值、查找某个键或元素的前驱或后继等操作。
在TreeMap中,每个键值对被表示为一个节点,节点按照键的大小进行排序,并存储在一棵红黑树中。在TreeSet中,每个元素被表示为一个节点,节点按照元素的大小进行排序,并存储在一棵红黑树中。
由于红黑树的自平衡性质,TreeMap和TreeSet能够在插入、删除、查找等操作中保持较为稳定的性能表现,具有很高的效率和可靠性。在Java中,TreeMap和TreeSet被广泛应用于需要高效实现有序映射和有序集合的场景,如排序、搜索、去重等场景,是非常常用的数据结构之一。
算法导论中的红黑树的实现
package rbTree;
import java.util.HashMap;
/**
* @Author WaleGarrett
* @Date 2021/7/11 18:48
*/
public class RBTree<Key extends Comparable<Key>, Value> {
private class Node<Key, value>{
private Key key;
private Value value;
private Node<Key, Value> left;
private Node<Key, Value> right;
private int color;
public Node(Key key, Value value, int color){
this.key = key;
this.value = value;
this.color = color;
}
}
private static final int RED = 0;
private static final int BLACK = 1;
/**
* 判断一个结点的颜色是否是红色
* @param node
* @return
*/
private boolean isRed(Node<Key, Value> node){
if(node == null)
return false;
return node.color == RED;
}
/** node x
* 左旋转: / \ / \
* @param node T1 x ----> node T3
* @return / \ / \
* T2 T3 T1 T2
*/
private Node<Key, Value> leftRotate(Node<Key, Value> node){
Node x = node.right;
node.right = x.left;
x.left = node;
x.color = node.color;
node.color = RED;
return x;
}
/** node x
* 右旋转: / \ / \
* @param node x T2 ----> T3 node
* @return / \ / \
* T3 T1 T1 T2
*/
private Node<Key, Value> rightRotate(Node<Key, Value> node){
Node x = node.left;
node.left = x.right;
x.right = node;
x.color = node.color;
node.color = RED;
return x;
}
/**
* 颜色翻转:当左右指针均为红色时进行颜色翻转
* @param node
*/
private void flipColor(Node<Key, Value> node){
node.color = RED;
node.left.color = BLACK;
node.right.color = BLACK;
}
/**
* 根节点
*/
private Node<Key, Value> root;
/**
* 添加元素
* @param key
* @param value
*/
public void add(Key key, Value value){
root = add(root, key, value);
// 保证根节点的颜色始终是黑色
root.color = BLACK;
}
public Node add(Node<Key, Value> node, Key key, Value value){
/**
* 新加入的结点始终保持是红色的
*/
if(node == null)
return new Node<Key, Value>(key, value, RED);
int compare = key.compareTo(node.key);
if(compare < 0){
// key小于当前node结点,新结点必然插入到node的左子树
node.left = add(node.left, key, value);
}else if(compare > 0){
// key大于当前node结点,新结点必然插入到node的右子树
node.right = add(node.right, key, value);
}else{
node.value = value;
}
/**
* 使红黑树树保持平衡
*/
// 当node结点的右结点为红色,而左结点为黑色时,左旋
if(isRed(node.right) && !isRed(node.left))
node = leftRotate(node);
// 当node左侧有两个连续的红色结点时,右旋
if(isRed(node.right) && isRed(node.right.right))
node = rightRotate(node);
// 当node的左右结点均为红色时,颜色翻转
if(isRed(node.left) && isRed(node.right))
flipColor(node);
return node;
}
}
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
我正在使用Rails3.2.2并希望递归加载某个目录中的所有代码。例如:[Railsroot]/lib/my_lib/my_lib.rb[Railsroot]/lib/my_lib/subdir/support_file_00.rb[Railsroot]/lib/my_lib/subdir/support_file_01.rb...基于谷歌搜索,我试过:config.autoload_paths+=["#{Rails.root.to_s}/lib/my_lib/**"]config.autoload_paths+=["#{Rails.root.to_s}/lib/my_lib/**/"
文章目录认识unity打包目录结构游戏逆向流程Unity游戏攻击面可被攻击原因mono的打包建议方案锁血飞天无限金币攻击力翻倍以上统称内存挂透视自瞄压枪瞬移内购破解Unity游戏防御开发时注意数据安全接入第三方反作弊系统外挂检测思路狠人自爆实战查看目录结构用il2cppdumper例子2-森林whoishe后记认识unity打包目录结构dll一般很大,因为里面是所有的游戏功能编译成的二进制码游戏逆向流程开发人员代码被编译打包到GameAssembly.dll中使用il2ppDumper工具,并借助游戏名_Data\il2cpp_data\Metadata\global-metadata.dat
对于体育新闻中文文本的关键字提取,常用的算法包括TF-IDF、TextRank和LDA等。它们的基本步骤如下:1.TF-IDF算法: -将文本进行分词和词性标注处理。-统计每个词在文本中的词频(TF)。-计算每个词在整个语料库中出现的文档频率(DF)和逆文档频率(IDF)。-计算每个词的TF-IDF值,并按照值的大小进行排序,选择排名前几的词作为关键字。2.TextRank算法:-将文本进行分词和词性标注处理。-将分词结果转化成图模型,每个词语为节点,根据词语之间的共现关系建立边。-对图模型进行迭代计算,计算每个节点的PageRank值,表示该节点的重要性。-选择排名前几的节点作为关键字。3.
光度学中的能量、通量、出度、照度、强度、亮度参数及其联系光度学中评价光的强弱有两种方式,一种是将光作为电磁波,考察其辐射的能量;另一种是以人眼视觉体验来评价光的强弱。前者被称为辐射量,后者被称为光学量。辐射量包括辐射能、辐通量、辐出量、辐照度、辐强度、辐亮度参数,与之相对应,光学量包括光能量、光通量、光出量、光照度、光强度、光亮度参数。通过该文章的阅读,读者还能掌握光学中的几个单位:流明,勒克斯,坎德拉,尼特的意义以及他们之间的关系。辐射量1.辐射能光以电磁波形式发射、传输或接收的能量。单位:焦耳。2.辐通量单位时间发射、传输和接收的辐射能。单位:瓦特。3.辐出度单位面积的辐射源辐射出的辐通量
我正在尝试掌握Rails计数器缓存功能,但无法完全掌握它。假设我们有3个模型ABCA属于B或C,取决于字段key_type和key_id。key_type表示A属于B还是C,因此如果key_type="B"则记录属于B,否则属于C。在我的模型a.rb中,我定义了以下关联:belongs_to:b,:counter_cache=>true,:foreign_key=>"key_id"belongs_to:c,:counter_cache=>true,:foreign_key=>"key_id"和在b和c模型文件中has_many:as,:conditions=>{:key_type=>"
前言 Slowloris攻击是我在李华峰老师的书——《MetasploitWeb 渗透测试实战》里面看的,感觉既简单又使用,现在这种攻击是很容易被防护的啦。不过我也不敢真刀实战的去试,只是拿个靶机玩玩罢了。 废话还是写在结语里面吧。(划掉)结语可以不看(划掉)Slowloris攻击的原理 Slowloris是一种资源消耗类DoS攻击,它利用部分HTTP请求进行操作。也叫做慢速攻击,这里的慢速并不是说发动攻击慢,而是访问一条链接的速度慢。Slowloris攻击的功能是打开与目标Web服务器的连接,然后尽可能长时间的保持这些连接打开。如果由多台电脑同时发起Slo
目录一、原理部分1、什么是串行通信(1)并行通信与串行通信(2)串行通信的制式(3)串行通信的主要方式 2、配置串口(1)SCON和PCON:串行口1的控制寄存器(2)SBUF:串行口数据缓冲寄存器 (3)AUXR:辅助寄存器编辑(4)ES、PS:与串行口1中断相关的寄存器(5)波特率设置 3、串口框架编写二、程序案例一、原理部分1、什么是串行通信(1)并行通信与串行通信微控制器与外部设备的数据通信,根据连线结构和传送方式的不同,可以分为两种:并行通信和串行通信。并行通信:数据的各位同时发送与接收,每个数据位使用一条导线,这种方式传输快,但是需要多条导线进行信号传输。串行通信:数据一位一
人类生活在充满多样性的世界里。长久以来的研究发现,人类的脑与行为受到基因、环境和文化及其相互作用的塑造,然而这种影响发生的机制始终缺乏系统性探索与研究。近年来,前沿神经影像技术方法飞速进步,推动着多模态脑成像大数据集的产生和融合性探索,并让学界得以深入探究人脑宏观结构与功能连接组架构,为包括上述主题在内的许多有趣而重要的科学问题带来了新的启发和思路。2022年12月20日,北京大学物理学院、IDG麦戈文脑科学研究所高家红团队在《NatureNeuroscience》在线发表了题为“IncreasingdiversityinconnectomicswiththeChineseHumanConne
论文常见数学符号及其含义(科研必备)返回论文和资料目录数学符号在数学领域是非常重要的。在论文中,使用数学符号可以使得论文更加简洁明了,同时也能够准确地描述各种概念和理论。在本篇博客中,我将介绍一些常见的数学符号及其含义(省去特别简单的符号),希望能够帮助读者更好地理解数学论文。高等数学∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi(求和符号):表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x2,…,xn中的所有数相加,例如∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x