NoSQL(NoSQL = Not Only SQL ),意即"不仅仅是SQL"。
在现代的计算系统上每天网络上都会产生庞大的数据量。
这些数据有很大一部分是由关系数据库管理系统(RDBMS)来处理。 1970年 E.F.Codd's提出的关系模型的论文 "A relational model of data for large shared data banks",这使得数据建模和应用程序编程更加简单。
通过应用实践证明,关系模型是非常适合于客户服务器编程,远远超出预期的利益,今天它是结构化数据存储在网络和商务应用的主导技术。
NoSQL 是一项全新的数据库革命性运动,早期就有人提出,发展至2009年趋势越发高涨。NoSQL的拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
事务在英文中是transaction,和现实世界中的交易很类似,它有如下四个特性:
1、A (Atomicity) 原子性
原子性很容易理解,也就是说事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。
比如银行转账,从A账户转100元至B账户,分为两个步骤:1)从A账户取100元;2)存入100元至B账户。这两步要么一起完成,要么一起不完成,如果只完成第一步,第二步失败,钱会莫名其妙少了100元。
2、C (Consistency) 一致性
一致性也比较容易理解,也就是说数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
例如现有完整性约束a+b=10,如果一个事务改变了a,那么必须得改变b,使得事务结束后依然满足a+b=10,否则事务失败。
3、I (Isolation) 独立性
所谓的独立性是指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。
比如现在有个交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加的100元的。
4、D (Durability) 持久性
持久性是指一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
分布式系统(distributed system)由多台计算机和通信的软件组件通过计算机网络连接(本地网络或广域网)组成。
分布式系统是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。
因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件。
分布式系统可以应用在不同的平台上如:Pc、工作站、局域网和广域网上等。
可靠性(容错) :
分布式计算系统中的一个重要的优点是可靠性。一台服务器的系统崩溃并不影响到其余的服务器。
可扩展性:
在分布式计算系统可以根据需要增加更多的机器。
资源共享:
共享数据是必不可少的应用,如银行,预订系统。
灵活性:
由于该系统是非常灵活的,它很容易安装,实施和调试新的服务。
更快的速度:
分布式计算系统可以有多台计算机的计算能力,使得它比其他系统有更快的处理速度。
开放系统:
由于它是开放的系统,本地或者远程都可以访问到该服务。
更高的性能:
相较于集中式计算机网络集群可以提供更高的性能(及更好的性价比)。
故障排除:
故障排除和诊断问题。
软件:
更少的软件支持是分布式计算系统的主要缺点。
网络:
网络基础设施的问题,包括:传输问题,高负载,信息丢失等。
安全性:
开放系统的特性让分布式计算系统存在着数据的安全性和共享的风险等问题。
NoSQL,指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据。用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL 数据库的发展却能很好的处理这些大的数据。

社会化关系网:
Wikipedia 页面 :
RDBMS
-
高度组织化结构化数据
- 结构化查询语言(SQL) (SQL)
-
数据和关系都存储在单独的表中。
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
NoSQL
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
-键 - 值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性和可伸缩性

NoSQL一词最早出现于1998年,是Carlo Strozzi开发的一个轻量、开源、不提供SQL功能的关系数据库。
2009年,Last.fm的Johan Oskarsson发起了一次关于分布式开源数据库的讨论[2],来自Rackspace的Eric Evans再次提出了NoSQL的概念,这时的NoSQL主要指非关系型、分布式、不提供ACID的数据库设计模式。
2009年在亚特兰大举行的"no:sql(east)"讨论会是一个里程碑,其口号是"select fun, profit from real_world where relational=false;"。因此,对NoSQL最普遍的解释是"非关联型的",强调Key-Value Stores和文档数据库的优点,而不是单纯的反对RDBMS。
在计算机科学中, CAP定理(CAP theorem), 又被称作 布鲁尔定理(Brewer's theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
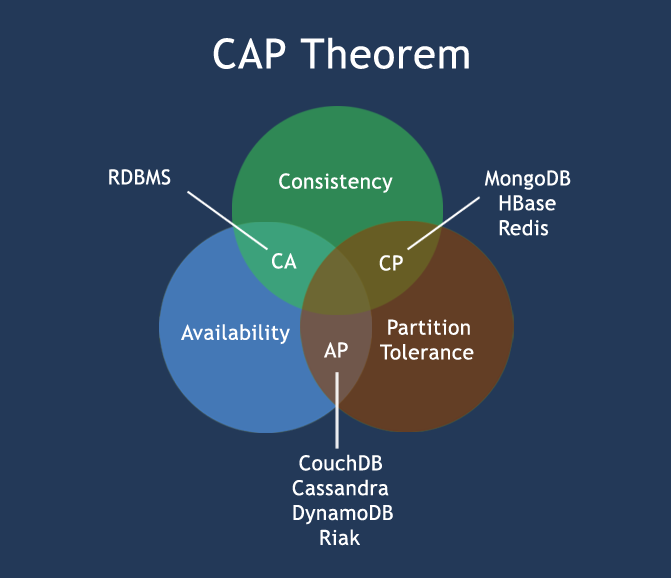
优点:
缺点:
BASE:Basically Available, Soft-state, Eventually Consistent。 由 Eric Brewer 定义。
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
BASE是NoSQL数据库通常对可用性及一致性的弱要求原则:
| ACID | BASE |
|---|---|
| 原子性(Atomicity) | 基本可用(Basically Available) |
| 一致性(Consistency) | 软状态/柔性事务(Soft state) |
| 隔离性(Isolation) | 最终一致性 (Eventual consistency) |
| 持久性 (Durable) |
| 类型 |
部分代表
|
特点 |
| 列存储 |
Hbase Cassandra Hypertable |
顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的IO优势。 |
|
文档存储 |
MongoDB CouchDB |
文档存储一般用类似json的格式存储,存储的内容是文档型的。这样也就有机会对某些字段建立索引,实现关系数据库的某些功能。 |
|
key-value存储 |
Tokyo Cabinet / Tyrant Berkeley DB MemcacheDB Redis |
可以通过key快速查询到其value。一般来说,存储不管value的格式,照单全收。(Redis包含了其他功能) |
|
图存储 |
Neo4J FlockDB |
图形关系的最佳存储。使用传统关系数据库来解决的话性能低下,而且设计使用不方便。 |
|
对象存储 |
db4o Versant |
通过类似面向对象语言的语法操作数据库,通过对象的方式存取数据。 |
|
xml数据库 |
Berkeley DB XML BaseX |
高效的存储XML数据,并支持XML的内部查询语法,比如XQuery,Xpath。 |
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
昨晚看到IDEA官推宣布IntelliJIDEA2023.1正式发布了。简单看了一下,发现这次的新版本包含了许多改进,进一步优化了用户体验,提高了便捷性。至于是否升级最新版本完全是个人意愿,如果觉得新版本没有让自己感兴趣的改进,完全就不用升级,影响不大。软件的版本迭代非常正常,正确看待即可,不持续改进就会慢慢被淘汰!根据官方介绍:IntelliJIDEA2023.1针对新的用户界面进行了大量重构,这些改进都是基于收到的宝贵反馈而实现的。官方还实施了性能增强措施,使得Maven导入更快,并且在打开项目时IDE功能更早地可用。由于后台提交检查,新版本提供了简化的提交流程。IntelliJIDEA
介绍pytest是一个非常成熟的全功能的Python测试框架,主要有以下几个特点:简单灵活,容易上手支持参数化能够支持简单的单元测试和复杂的功能测试,还可以用来做selenium/appnium等自动化测试、接口自动化测试(pytest+requests)pytest具有很多第三方插件,并且可以自定义扩展,比较好用的如pytest-selenium(集成selenium)、pytest-html(完美html测试报告生成)、pytest-rerunfailures(失败case重复执行)、pytest-xdist(多CPU分发)等测试用例的skip和xfail处理可以很好的和jenkins集成
我已经使用Rails几年了,并且非常习惯ActiveRecord,但最近完成了一项可以从(某些)NoSQL数据存储中获益的任务。少量数据最好放在NoSQL系统中,但大部分数据仍应放在RDBMS中。不过,我看过的每个NoSQL包装器/gem似乎都需要从应用程序中删除ActiveRecord。是否有结合这两种技术的建议方法? 最佳答案 不确定您正在研究什么NoSQL服务,但我们已经将MongoDB与Postgres结合使用了一段时间。有用的提示,他们说你需要摆脱ActiveRecord,但实际上你不需要。大多数人只是这么说,因为您最终没
我有兴趣了解使用nosql将如何影响rails应用程序的架构/设计/代码。有人知道使用nosql持久性的开源rails应用程序的一个好例子吗?谢谢 最佳答案 看看这些项目:卡桑德拉用法atDigg。卡桑德拉用法atTwitter。Friendly用法atFetLife(nsfw)。最后,MyNoSQL是一个提供nosql相关信息的好网站。 关于ruby-on-rails-有没有很好的引用(开源)RailsNoSQL应用程序?,我们在StackOverflow上找到一个类似的问题:
📝学技术、更要掌握学习的方法,一起学习,让进步发生👩🏻作者:一只IT攻城狮。💐学习建议:1、养成习惯,学习java的任何一个技术,都可以先去官网先看看,更准确、更专业。💐学习建议:2、然后记住每个技术最关键的特性(通常一句话或者几个字),从主线入手,由浅入深学习。❤️《SpringCloud入门实战系列》解锁SpringCloud主流组件入门应用及关键特性。带你了解SpringCloud主流组件,是如何一战解决微服务诸多难题的。项目demo:源码地址👉🏻SpringCloud入门实战系列不迷路👈🏻:SpringCloud入门实战(一)什么是SpringCloud?SpringCloud入门实战
我最近一直在研究NoSql选项。我的场景如下:我们从位于世界各地偏远地区的定制硬件收集和存储数据。我们每15分钟记录一次来自每个站点的数据。我们最终希望每1分钟移动一次。每条记录有20到200个测量值。一旦设置好硬件,每次都会记录和报告相同的测量值。我们面临的最大问题是我们从每个项目中获得了一组不同的衡量标准。我们测量大约50-100种不同的测量类型,但是任何项目都可以有任意数量的每种测量类型。没有可以容纳数据的预设列集。因此,当我们在系统上设置和配置项目时,我们创建并构建了每个项目数据表,其中包含所需的确切列。我们提供工具来帮助分析数据。这通常包括更多的计算和数据聚合,其中一些我们也
文章目录一,什么是kaliPurle(卡利紫)二,如何安装kaliPurple。(有步骤没图片直接是默认)1,复制它的下载链接到迅雷可以让你下镜像变得更快。2,打开你的虚拟机创建新的虚拟机3,点击后面浏览然后找到镜像的所在地选中确定,下一步4,这里默认就可以,因为Ubuntu和这个差不多架构。5,然后,名字自己改一下,然后把他安到你想要装的盘,容量默认。之后一直下一步就可以**6,打开它,然后第一个图形界面安装,直接回车,然后选中文点continue之后没有图片的直接点继续。7,密码想设什么设什么。然后一直继续到我的图片那里改一下就可以了。8,软件默认就行。9,耐心等待。然后点手动配置dvc然
目录关于MPU6050芯片关于小板关于厂家和DATASHEET关于漂移关于角加速度还是角速度关于精度和量程(可调,可选)关于功耗,陀螺仪+加速器工作电流:3.8mA(全功率,陀螺仪在所有速率下,在1kHz采样率下加速)采样率高,功耗也高可以参考 MPU6050陀螺仪与Processing和匿名上位机飞控联动实录-知乎关于MPU6050芯片MPU6050传感器模块是6轴运动跟踪设备。包含3轴陀螺仪、3轴加速度计、运动处理器、温度传感器。I2C总线接口,可与微控制器进行通信。通过辅助I2C总线与其他传感器设备通信,如3轴磁力计、压力传感器等。如果3轴磁力计连接到辅助I2C总线,则MPU6050可
MySQL为您提供了一个有用的字符串函数REPLACE(),它允许您用新的字符串替换表的列中的字符串。REPLACE()函数的语法如下:REPLACE(str,old_string,new_string);SQLREPLACE()函数有三个参数,它将string中的old_string替换为new_string字符串。注意:有一个也叫作REPLACE的语句用于插入或更新数据。所以不要将REPLACE语句与这里的REPLACE字符串函数混淆。REPLACE()函数非常方便搜索和替换表中的文本,例如更新过时的URL,纠正拼写错误等。在UPDATE语句中使用REPLACE函数的语法如下:UPDATE