== 注:本文参考2021年华数杯数学建模C题优秀论文==
汽车产业是国民经济的重要支柱产业,而新能源汽车产业是战略性新兴产业。大力 发展以电动汽车为代表的新能源汽车是解决能源环境问题的有效途径,市场前景广阔。 但是,电动汽车毕竟是一个新兴的事物,与传统汽车相比,消费者在一些领域,如电池 问题,还是存在着一些疑虑,其市场销售需要科学决策。 某汽车公司最新推出了三款品牌电动汽车,包括合资品牌(用 1 表示)、自主品牌 (用 2 表示)和新势力品牌(用 3 表示)。为研究消费者对电动汽车的购买意愿,制定 相应的销售策略,销售部门邀请了 1964 位目标客户对三款品牌电动汽车进行体验。具 体体验数据有电池技术性能(电池耐用和充电方便)满意度得分(满分 100 分,下同) a1、舒适性(环保与空间座椅)整体表现满意度得分 a2、经济性(耗能与保值率)整体 满意度得分 a3、安全性表现(刹车和行车视野)整体满意度得分 a4、动力性表现(爬 坡和加速)整体满意度得分 a5、驾驶操控性表现(转弯和高速的稳定性)整体满意度得 分 a6、外观内饰整体表现满意度得分 a7、配置与质量品质整体满意度得分 a8 等。另外 还有目标客户体验者个人特征的信息,详情见附录 1 和 2。
问题:请做数据清洗工作,指出异常值和缺失数据以及处理方法。对数据做描述性统计分析,包括目标客户对于不同品牌汽车满意度的比较分析。

缺失值、异常值的处理是数据处理不可缺少的一环。缺失值是源于数据采集的空 缺、传输间丢失等不可控情况所导致或人为故意丢失等多种情况,如何处理空值是数 据处理中恒久不变的问题。而其中异常值是由于数据传输错误所导致的,通常对其采 取修改或是剔除的处理方式,但具体所采取的方式也需要依据客观上分析数据所决定。 以下主要分成三点叙述本文所采用的处理方法及处理结果。
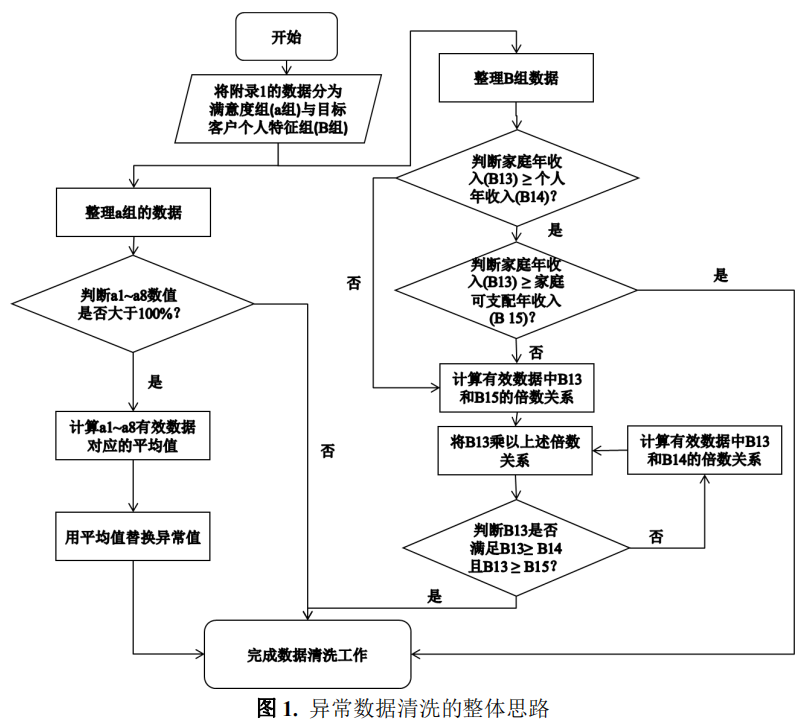
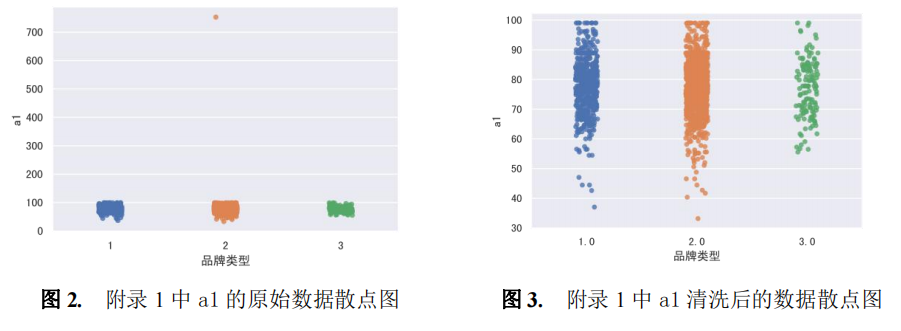
根据题意,该公司的销售部门对目标客户进行体验调查时,规定满意度得分满分为 100 分,故在数据清洗时剔除附录 1 中 a1~a8 数值大于 100 的数据。以 a1 为例, 该列展示了目标客户对电池技术性能的满意度得分情况。利用散点图经筛查发现,编 号为 0001 的目标客户对电池技术性能的满意度高达 753.04 分(> 100 分),故用正常 值数据的平均值(77.93 分)进行替换。数据清洗前后的结果如图 2、图 3 所示。同理 可分别对编号为 1964、0480 的目标客户对应在 a3、a5 的数据进行清洗(满意度原始 评价分数分别为 703.00 分、605.03 分)。
由附录 1 可知,缺失数据集中在 B7,即目标客户的孩子数量。由于目前已有的 数据仅为 1、2、3 名孩子数量,不符合常理,因此考虑了出生年份后,将所有缺失数 据的孩子数量均替换为 0,共完成 1457 处的替换。
根据题意可知,影响目标客户对三款品牌电动汽车满意度的主要影响因素主要有 8 个,分别为电池技术性能(电池耐用和充电方便)、舒适性(环保与空间座椅)整体 表现、经济性(耗能与保值率)、安全性表现(刹车和行车视野)、动力性表现(爬坡 和加速)、驾驶操控性表现(转弯和高速的稳定性)、外观内饰整体表现、配置与质量 品质,其满意度分别是 a1~a8。为此,基于上述数据清洗的结果,对全体目标客户评 价的 a1~a8 分别求平均值,然后再对这 8 项指标的平均值再次求平均,并求出最后得分。运行结果显示,合资品牌、自主品牌和新势力品牌的满意度最终得分分别为 78.16 分、77.54 分和 76.93 分,表明目标客户普遍对合资品牌的满意度评价最高,新势力品 牌的满意度最低。
问题:决定目标客户是否购买电动车的影响因素有很多,有电动汽车本身的因素,也有目标客户个人特征的因素。在这次目标客户体验活动中,有部分目标客户购买了体验的电动汽车(购买了用 1 表示,没有购买用 0 表示)。结合这些信息,请研究哪些因素可能会对不同品牌电动汽车的销售有影响?
特征选择方法中的过滤法和包裹法,在特征选择过程与模型训练过程是独立进行的,而嵌入法则是综合考虑这两个过程,在学习的同时进行特征选择,因此,为了使 结果更具有代表性,利于模型训练,本文使用以下两种嵌入法:
from sklearn.linear_model import LogisticRegression as LR
from sklearn.svm import LinearSVC
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import Lasso, LassoCV
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
import numpy as np
df = pd.read_excel('2.xlsx')
# b13,14,15 处理
df.loc[(df['B13'] < df['B14']) | (df['B13'] < df['B15']), 'B13'] = np.nan
df.loc[df['B13'].isnull(), 'B13'] = df.loc[df['B13'].isnull(), 'B15'] * 1.667
df.loc[(df['B13'] < df['B14']) | (df['B13'] < df['B15']), 'B13'] = np.nan
df.loc[df['B13'].isnull(), 'B13'] = df.loc[df['B13'].isnull(), 'B14'] * 1.7142
x = df.iloc[:, 2:-1]
Y = df.iloc[:, -1]
Scaler = MinMaxScaler().fit(x) # 标准化
X = Scaler.transform(x)
print(X.shape)
print(Y.shape)
X是将x数据进行标准化之后的数据。
lsvc = LinearSVC(C=3, penalty="l1", dual=False) # 1-0.99; 2-3;3-0.35
sfm = SelectFromModel(lsvc, max_features=8).fit(X, Y)
print(sfm)
print(sfm.get_support())
print(df.columns[2:-1][sfm.get_support()])
clf = LassoCV()
sfm = SelectFromModel(clf, max_features=8).fit(X, Y)
print(sfm)
print(sfm.get_support())
print(df.columns[2:-1][sfm.get_support()])
sfm = SelectFromModel(estimator=LR(C=7), max_features=8).fit(X, Y)
print(sfm)
print(sfm.get_support())
print(df.columns[2:-1][sfm.get_support()])
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from IPython.display import display
sns.set(style="darkgrid",palette='deep')
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
%matplotlib inline
from IPython.core.interactiveshell import InteractiveShell InteractiveShell.ast_node_interactivity = "all" from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
df = pd.read_excel('2_del.xlsx')
df1 = df[df.品牌类型 == 1]
df2 = df[df.品牌类型 == 2]
df3 = df[df.品牌类型 == 3]
X = df3.iloc[:,2:27]
# X.drop(['B1','B6','B7'],axis=1)
# X.sample(n=100,random_state=0)
target = df3.iloc[:,27]
x_train, x_test, y_train, y_test = train_test_split(X, target, test_size = 0.2, random_state = 0) feat_labels = df.columns[2:27]
forest = RandomForestClassifier(n_estimators=10000, random_state=0, n_jobs=-1)
forest.fit(x_train, y_train)
# 特征重要性
l = []
importances = forest.feature_importances_
indices = np.argsort(importances)[::-1]
for f in range(x_train.shape[1]):
print("%2d) %-*s %f" % (f + 1, 30, feat_labels[indices[f]], importances[indices[f]]))
l.append((feat_labels[indices[f]],importances[indices[f]]))
l=pd.DataFrame(l)
from sklearn.metrics import mean_squared_error
import lightgbm as lgb
from sklearn.model_selection import train_test_split
df = pd.read_excel('2_del.xlsx')
X = df.iloc[:,0:12]
target = df.iloc[:,12]
X_train, X_test, y_train, y_test = train_test_split(X, target, test_size=0.2,random_state=0)
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import
confusion_matrix,classification_report,accuracy_score,roc_auc_score,f1_score evals_result = {}
valid_sets = [X_train, X_test]
valid_name = ['train', 'eval']
# 创建成 lgb 特征的数据集格式
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
# 将参数写成字典下形式
params = {
'task': 'train',
'boosting_type': 'gbdt', # 设置提升类型
'min_data_in_leaf': 10,
'max_depth': -1,
'objective': 'binary', # 目标函数
'metric': {'binary_logloss', 'auc','f1'}, # 评估函数
'num_leaves':3, # 叶子节点数
'learning_rate': 0.0001, # 学习速率
'feature_fraction': 0.8, # 建树的特征选择比例
'bagging_fraction': 0.8, # 建树的样本采样比例
"lambda_l1": 0.1,
'verbose': -1 ,# <0 显示致命的, =0 显示错误 (警告), >0 显示信息
"nthread": -1,
'n_estimators' : 500,
'is_unbalance':True,
}
# 训练 cv and train
gbm = lgb.train(params, lgb_train,
valid_names=valid_name,
num_boost_round=500,
valid_sets=lgb_eval,
evals_result=evals_result,
early_stopping_rounds=20)
# 预测数据集
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration) lgb.plot_metric(evals_result, metric='auc')
绘图:
plt.figure(figsize=(12,6))
lgb.plot_importance(gbm, max_num_features=30)
plt.title("Featurertances")
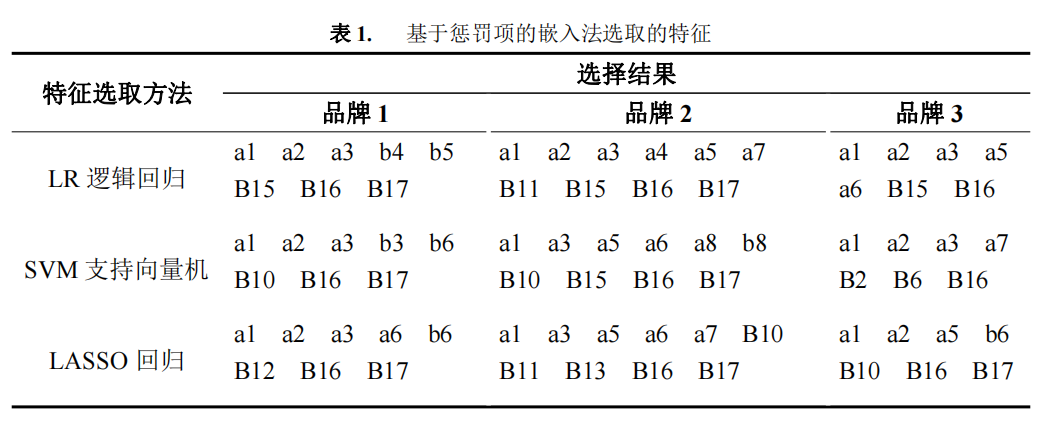
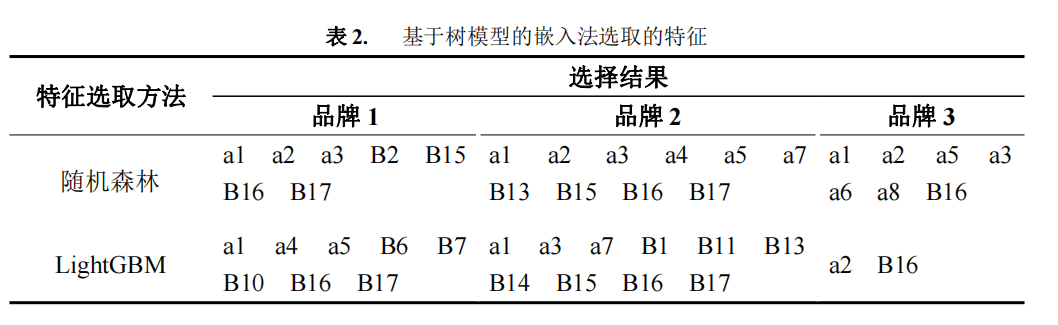
图 6 是利用五种模型对各个特征进行投票得出的特征出现次数图,本文选取大于 等于 2 出现次数的特征为重要特征,并认为会分别对三种品牌的电动汽车产生影响。
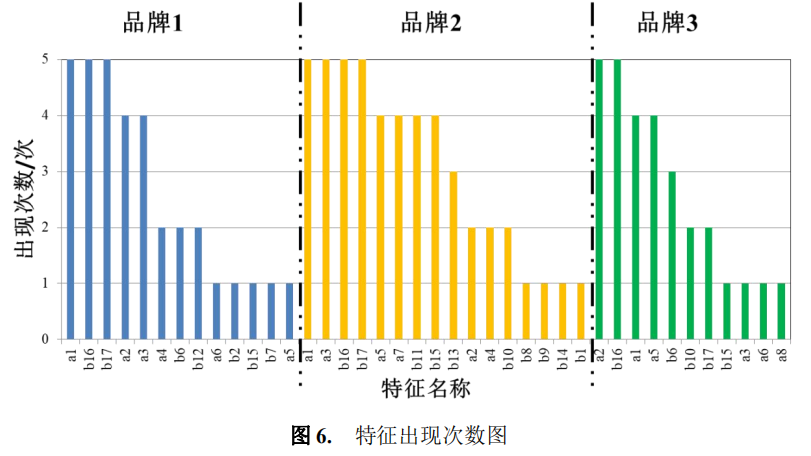
由图 6 可知,对三种品牌来说,电动车的电池技术性能、舒适性、目标客户全年 房贷、车贷占家庭年收入的占比均为两次及以上,说明这四个指标对顾客的购买情况 有较大的影响。除了以上的四个指标外,影响品牌 1 购买情况的因子还有经济型、安 全性、驾驶操控性以及目标客户的职位;经济型、安全性、动力性、外观内饰、目标 客户的工作情况(包括工作年限、单位性质)、家庭年收入、可支配年收入会是目标 客户购买品牌 2 的主要考虑因素;品牌 3 销售的主要影响指标则还有动力性、目标客 户的婚姻家庭情况还有工作年限。
问题:结合前面的研究成果,请你建立不同品牌电动汽车的客户挖掘模型,并评价模型的优良性。运用模型判断附件3中15名目标客户购买电动车的可能性。
对于类别不平衡问题,通过 SMOTE 进行采样,为了评价模型的优良性,我们使 用 F1 值和 AUC 值对单个模型进行综合评价。同时对每个模型进行 k 折交叉验证,计算 F1 值和 AUC 值,对不同模型的分数进行横向比较,从而挑选出适用于不同品牌的 最优模型。进而利用网络搜索方法给每个品牌效果最优的模型进行超参数调优。
(一)数据采样
数据附件一中的 1964 条数据中只有 99 位客户有购买意愿,类别的比例不均衡时, 多数类的样本会被过多地关注,这样,少数类样本的分类性能就会受到影响,因此需要对数据不平衡的问题进行处理,本文采用抽样 SMOTE 法解决标签类别不平衡问题, 使得目标客户的购买意向 1 标签(购买)与 0 标签(不买)的比值调整为 0.6。
(二)训练集与验证集的划分
本文将把 1964 条数据集划分成训练集和验证集,训练集占比 0.8,验证集占比 0.2, 进行 K 折交叉验证。
(三)模型训练与比较
使用 python 对五个模型在三个品牌的训练集上进行训练,对验证集进行预测,计 算 F1 值和 AUC 值,计算结果如下:
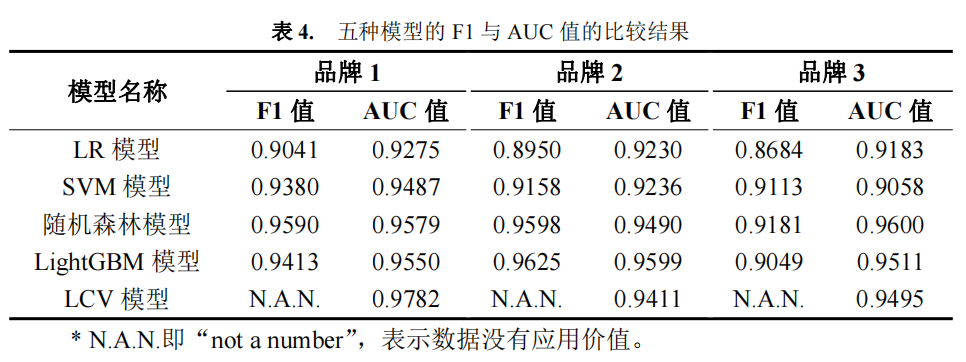
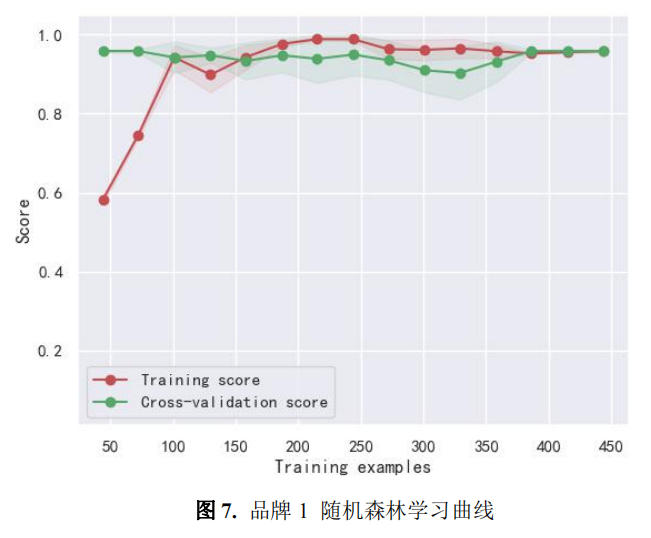
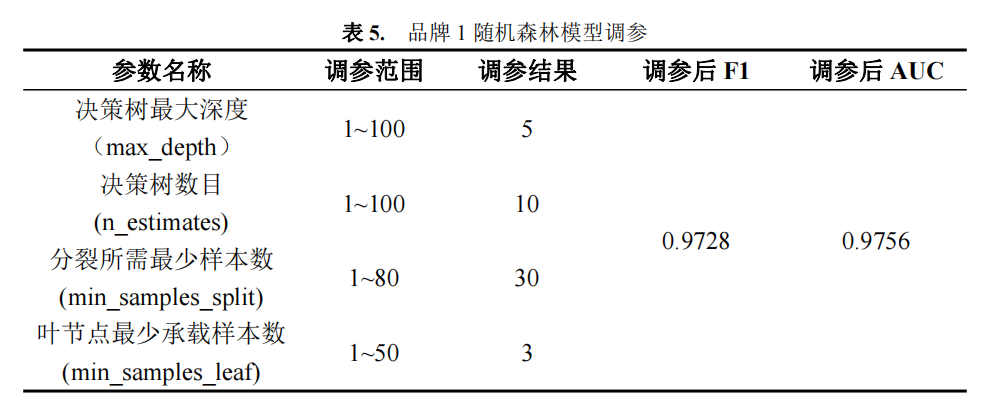
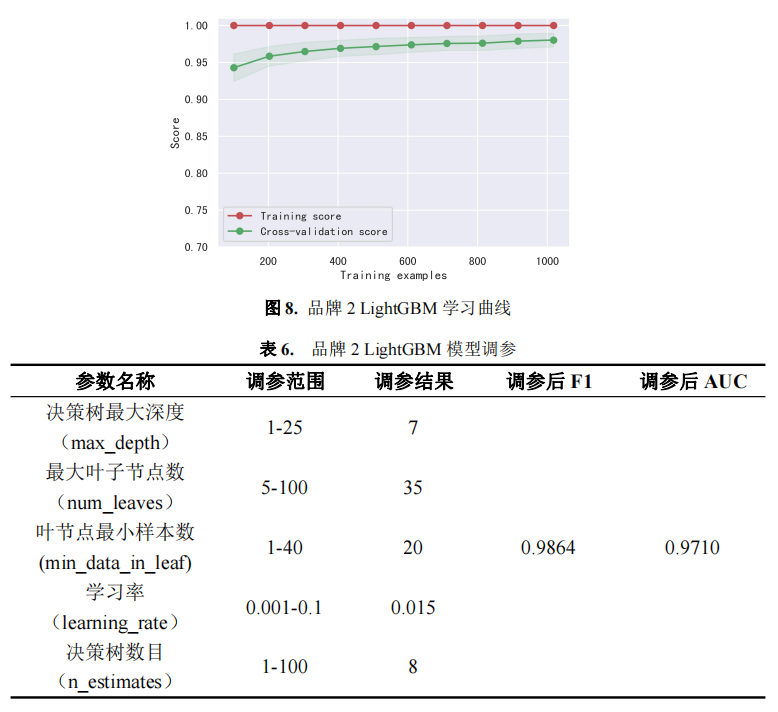
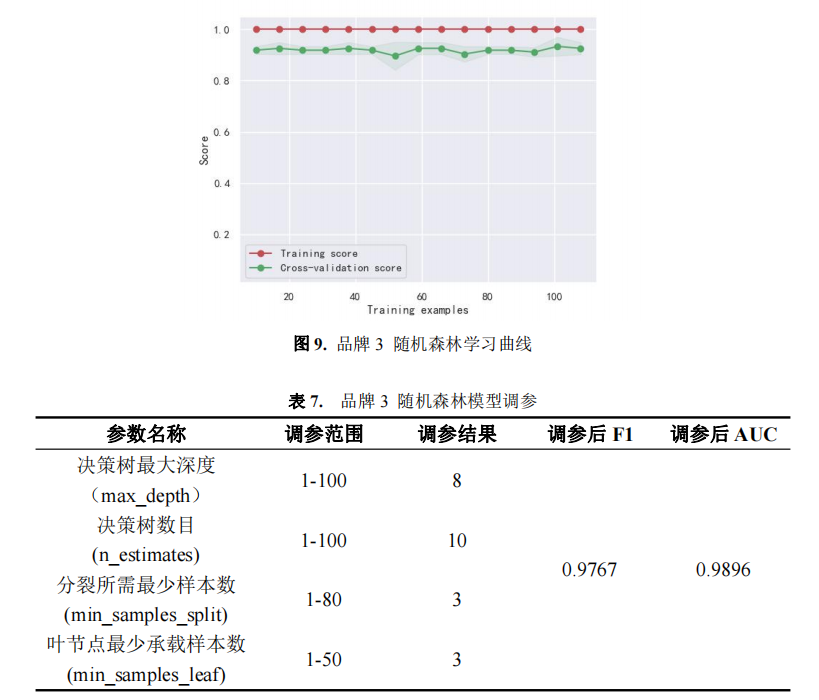
由上述分析可知,品牌 1 和 3 与随机森林模型匹配性较好,品牌二与 LightGBM 模型的匹配性较好,故本文将利用随机森林、LightGBM 模型来预测附件三中 15 名目 标客户购买电动汽车的可能性。
利用随机森林模型、LightGBM 模型、随机森林模型分别对品牌 1、2 和 3 的客户 进行预测,结果如表 8 所示。
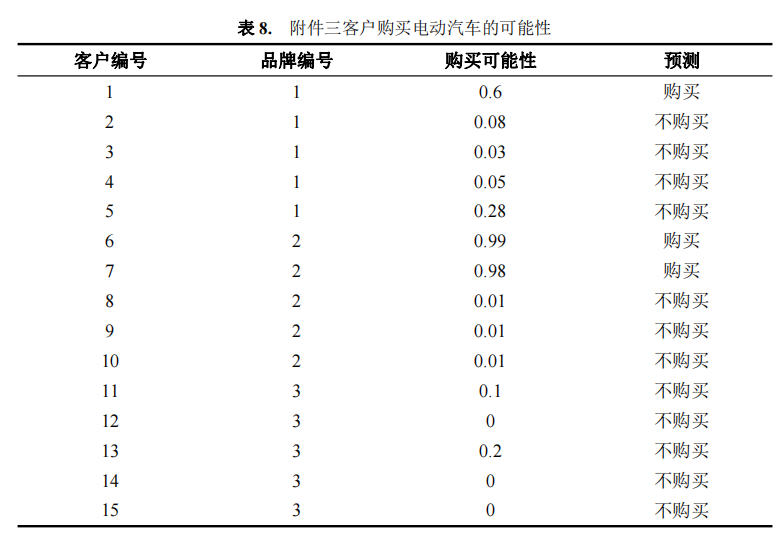
由结果可知,附件三中 15 名待预测的目标客户中,仅有编号为 1、6、7 的客户 有较大概率会选购品牌 1、品牌 2、品牌 2 的电动汽车,其他客户选购电动车的可能 性较低。
问题:销售部门认为,满意度是目标客户汽车体验的一种感觉,只要营销者加大服务力度,在短的时间内提高 a1-a8 五个百分点的满意度是有可能的,但服务难度与提高的满 意度百分点是成正比的,即提高体验满意度 5%的服务难度是提高体验满意度 1%服务难 度的 5 倍。基于这种思路和前面的研究成果,请你在附件 3 每个品牌中各挑选 1 名没有购买电动汽车的目标客户,实施销售策略。
这题较难。。。所以。。
问题:根据前面的研究结论,请你给销售部门提出不超过 500 字的销售策略建议。
思路:这问没啥好说的了吧,主要看写作同学的发挥。
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
一、机器人介绍 此处是基于MATLABRVC工具箱,对ABB-IRB-1200型号的微型机械臂进行正逆向运动学分析,并利Simulink工具实现对机械臂进行具有动力学参数的末端轨迹规划仿真,最后根据机械模型设计Simulink-Adams联合仿真。 图1.ABBIRB 1200尺寸参数示意图ABBIRB 1200提供的两种型号广泛适用于各作业,且两者间零部件通用,两种型号的工作范围分别为700 mm 和 900 mm,大有效负载分别为 7 kg 和5 kg。 IRB 1200 能够在狭小空间内能发挥其工作范围与性能优势,具有全新的设计、小型化的体积、高效的性能、易于集成、便捷的接
目录一.大致如下常见问题:(1)找不到程序所依赖的Qt库version`Qt_5'notfound(requiredby(2)CouldnotLoadtheQtplatformplugin"xcb"in""eventhoughitwasfound(3)打包到在不同的linux系统下,或者打包到高版本的相同系统下,运行程序时,直接提示段错误即segmentationfault,或者Illegalinstruction(coredumped)非法指令(4)ldd应用程序或者库,查看运行所依赖的库时,直接报段错误二.问题逐个分析,得出解决方法:(1)找不到程序所依赖的Qt库version`Qt_5'
我想使用ruby-prof和JMeter分析Rails应用程序。我对分析特定Controller/操作/或模型方法的建议方法不感兴趣,我想分析完整堆栈,从上到下。所以我运行这样的东西:RAILS_ENV=productionruby-prof-fprof.outscript/server>/dev/null然后我在上面运行我的JMeter测试计划。然而,问题是使用CTRL+C或SIGKILL中断它也会在ruby-prof可以写入任何输出之前杀死它。如何在不中断ruby-prof的情况下停止mongrel服务器? 最佳答案
文章目录认识unity打包目录结构游戏逆向流程Unity游戏攻击面可被攻击原因mono的打包建议方案锁血飞天无限金币攻击力翻倍以上统称内存挂透视自瞄压枪瞬移内购破解Unity游戏防御开发时注意数据安全接入第三方反作弊系统外挂检测思路狠人自爆实战查看目录结构用il2cppdumper例子2-森林whoishe后记认识unity打包目录结构dll一般很大,因为里面是所有的游戏功能编译成的二进制码游戏逆向流程开发人员代码被编译打包到GameAssembly.dll中使用il2ppDumper工具,并借助游戏名_Data\il2cpp_data\Metadata\global-metadata.dat
在笔者前面有一篇文章《驱动开发:断链隐藏驱动程序自身》通过摘除驱动的链表实现了断链隐藏自身的目的,但此方法恢复时会触发PG会蓝屏,偶然间在网上找到了一个作者介绍的一种方法,觉得有必要详细分析一下他是如何实现的进程隐藏的,总体来说作者的思路是最终寻找到MiProcessLoaderEntry的入口地址,该函数的作用是将驱动信息加入链表和移除链表,运用这个函数即可动态处理驱动的添加和移除问题。MiProcessLoaderEntry(pDriverObject->DriverSection,1)添加MiProcessLoaderEntry(pDriverObject->DriverSection,
什么是可以轻松集成到现有应用程序的优秀开源RoR3论坛?可选功能:OpenID支持Haml/SCSS模板支持表情符号、YouTube、图片等我可能会对其进行大量更改,而且我在Ruby方面仍然很薄弱,所以干净、带注释的代码以及良好的实践会很棒。谢谢:) 最佳答案 最近我在搜索类似的功能并遇到了discourse.您绝对应该检查一下。Discourseisthe100%opensource,next-generationdiscussionplatformbuiltforthenextdecadeoftheInternet.Whenev
CSDN优秀解读:https://blog.csdn.net/jiaoyangwm/article/details/1266387752021https://arxiv.org/pdf/2103.14259.pdf关键解读在目标检测中标签分配的最新进展主要寻求为每个GT对象独立定义正/负训练样本。在本文中,我们创新性地从全局的角度重新审视标签分配,并提出将分配程序制定为一个最优传输(OT)问题——优化理论中一个被充分研究的课题。具体来说,我们将每个需求方(锚框)和供应商(GT标签)的单位传输成本定义为他们的分类和回归损失加权之和。在公式化后,找到最好的分配方案即为最小传播成本解决最优传输方案,
目录1. 研究范围定义2. 流程中台市场分析3. 厂商评估:微宏科技4. 入选证书 1. 研究范围定义近年来,随着外部市场环境快速变化、客户需求愈发多样,企业逐渐意识到,自身业务需要更加敏捷、高效,具备根据市场需求快速迭代的能力。业务流程的自动化能够帮助企业实现业务的敏捷高效,因此受到越来越多企业的关注。企业的“自动化武器库”品类丰富,包括低/零代码平台、RPA、BPM、AI等。企业可以使用多项自动化工具,但结果往往是各项自动化工具处于各自的“自动化烟囱”之中,仅能实现碎片式自动化。例如,某企业的IT团队可能在使用低代码平台、财务团队可能在使用RPA、呼叫中心则可能在使用聊天机器人。自动