ShardingSphere学习笔记
看了很多分库分表,之前遇到分表都是手动的Create Table <tablename-XXX> 进行分表,这里去学了一下ShardingSphere,做一下简单记录
海量数据,单数据库难以满足需求,需要考虑集群。500W 或者 单表2GB建议分库分表
将数据库读写操作分散到不同的节点上

增删改操作路由到主机、读路由到从机。从机需要复制主机的数据。
这里会涉及数据不一致问题:CAP理论、BASE理论
因为CAP中的C很难保证,即很难保证强一致性,这个时候就出现了BASE理论。
阿里巴巴开发手册:三年后如果能到达单表500万行或者2GB,才推荐分库分表
数据量小的时候,一个数据库有多张不同业务的表,如用户表、商品表、订单表……
垂直分片就是按业务分类,将表分到不同的数据库,将压力分散到不同数据库。
当表中数据很多的时候,可以进行垂直分表、水平分表
字段过多,可以将很多不常用的字段分到另一张表
不是根据业务,而是相当于用一些算法进行映射,决定插入到那个数据库中的数据表,如最常见的根据ID 进行水平分库。
偶数到0库,奇数到1库。
将一部分数据分到另一张表,如以日期进行拆分到多张表,减少数据的扫描,提升性能。
自己进行数据访问层的封装,实现读写分离和数据库服务器的连接管理。
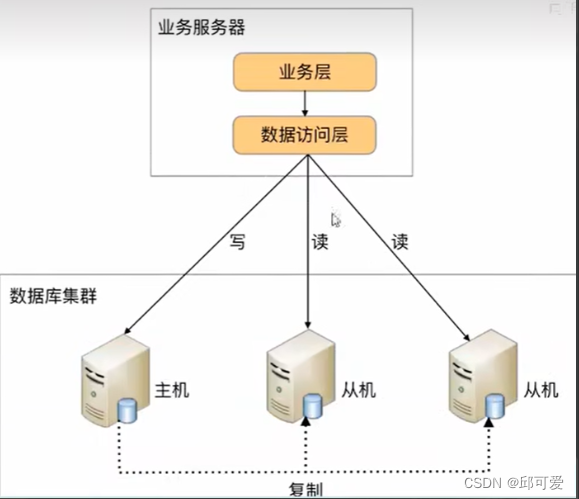
解耦,将负责读写分离和数据库服务器连接的数据库中间件独立出来,以此独立一套系统出来。

slave通过一个IO线程从master读取binlog进行数据同步,需要一个连接验证,即登录账号
# 查看系统内核
uname -r
# 查看已经安装的CentOS版本
cat /etc/redhat-release
# docker
# 添加镜像源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装yum 依赖 和 镜像源
yum install -y yum-utils device-mapper-persistent-data lvm2
yum makecache
# 安装docker
yum -y install docker-ce(如果centos8 `sudo yum install docker-ce docker-ce-cli containerd.io --allowerasing`
systemctl enable docker && systemctl start docker
# 设置docker镜像
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://tgie9tnd.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload && sudo systemctl restart docker
# 卸载docker
systemctl stop docker
yum remove -y docker-ce
rm -rf /var/lib/docker
# 关闭防火墙以免连接不上,当然也可以直接开放端口
systemctl stop docker
systemctl stop firewalld
systemctl start docker
# -d 守护进程后台启动
docker run -d \
-p 3306:3306 \
-v /software/mysql/master/conf:/etc/mysql/conf.d \
-v /software/mysql/master/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name mysql-master \
mysql:8.0.29
# 宿主机MYSQL配置文件修改
vim /software/mysql/master/conf/my.cnf
# 重启mysql
docker restart mysql-master
配置内容如下:
[mysqld]
# 服务器唯一id 默认1
server-id=1
# 设置日志格式,默认ROW
binlog_format=STATEMENT
# 二进制日志名字,默认binlog
# log-bin=binlog
# 设置需要复制的数据库,默认复制全部数据库
# binlog-do-db=db_test
# 设置不需要复制的数据库
#binlog-ignore-db=mysql
#binlog-ignore-db=information_schema
# 进入容器 env LANG=C.UTF-8 避免容器中文乱码
docker exec -it mysql-master env LANG=C.UTF-8 /bin/bash
# 在容器中进入MYSQL
mysql -uroot -p
# 修改默认密码校验方式
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
-- 主机中创建slave用户
-- 创建slave用户
CREATE USER 'slave'@'%';
-- 设置密码
ALTER USER 'slave'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
-- 授予复制权限
GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%';
-- 刷新权限
FLUSH PRIVILEGES;
-- 查看主服务器状态
SHOW MASTER STATUS;
这里标出了后续slave需要读取数据的位置

SLAVE1
docker run -d \
-p 3307:3306 \
-v /software/mysql/slave1/conf:/etc/mysql/conf.d \
-v /software/mysql/slave1/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name mysql-slave1 \
mysql:8.0.29
# 宿主机MYSQL配置文件修改
vim /software/mysql/slave1/conf/my.cnf
# 重启mysql
docker restart mysql-slave1
配置内容如下:
[mysqld]
# 服务器唯一id 默认1
server-id=2
# 中继日志名字,默认XXXX-relay-bin
# relay-log=relay-bin
# 进入容器
docker exec -it mysql-slave1 env LANG=C.UTF-8 /bin/bash
# 进入容器内
mysql -uroot -p
# 修改默认密码校验方式
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
-- 在从机上执行一下SQL,配置主从关系
CHANGE MASTER TO MASTER_HOST='172.19.240.201',
MASTER_USER='slave',MASTER_PASSWORD='123456', MASTER_PORT=3306,
MASTER_LOG_FILE='binlog.000003',MASTER_LOG_POS=1051;
SLAVE2
docker run -d \
-p 3308:3306 \
-v /software/mysql/slave2/conf:/etc/mysql/conf.d \
-v /software/mysql/slave2/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name mysql-slave2 \
mysql:8.0.29
# 宿主机MYSQL配置文件修改
vim /software/mysql/slave2/conf/my.cnf
# 重启mysql
docker restart mysql-slave2
配置内容如下:
[mysqld]
# 服务器唯一id 默认1
server-id=3
# 中继日志名字,默认XXXX-relay-bin
# relay-log=relay-bin
# 进入容器
docker exec -it mysql-slave2 env LANG=C.UTF-8 /bin/bash
# 进入容器内
mysql -uroot -p
# 修改默认密码校验方式
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
-- 在从机上执行一下SQL,配置主从关系
CHANGE MASTER TO MASTER_HOST='172.19.240.201',
MASTER_USER='slave',MASTER_PASSWORD='123456', MASTER_PORT=3306,
MASTER_LOG_FILE='binlog.000003',MASTER_LOG_POS=1051;
-- 启动从机复制功能
START SLAVE ;
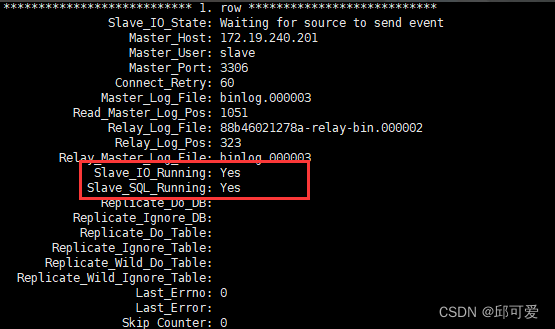
-- 查看状态
SHOW SLAVE STATUS\G
如果是yes就是启动成功。
-- 在从机执行,停止IO和SQL线程
STOP SLAVE;
-- 在从机执行,删除SLAVE数据库的relaylog日志,并重新启用relaylog
RESET SLAVE;
-- 在主机执行,删除所有binlog日志文件,并将日志索引文件清空,重新开始所有新的日志文件
-- 用于第一次进行搭建主从库,进行主库binlog初始化工作
RESET MASTER;
slave_io_running是no或者connecting的时候,需要SHOW SLAVE STATUS\G查看last_io_error
启动之后出现WARNING:IPV4 forwarding is disabled. Networking will not work; 会导致远程连不上容器中的mysql。
需要开启防火墙端口。
利用上述的主从架构完成读写分离
默认主库写,从库读。开启事务之后,为了保证主从库间的事务一致性,避免跨服务器的分布式事务,ShardingSphere-JDBC读写都用主库。
Junit 只要加了@Tranctional就会默认回滚,即使没有Rollback
# 应用名称
spring.application.name=sharding-jdbc-demo
# 开发环境设置
spring.profiles.active=dev
# 内存模式
spring.shardingsphere.mode.type=Memory
# 配置真实数据源
spring.shardingsphere.datasource.names=master,slave1,slave2
# 配置第 1 个数据源
spring.shardingsphere.datasource.master.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.master.jdbc-url=jdbc:mysql://172.19.240.201:3306/db_test
spring.shardingsphere.datasource.master.username=root
spring.shardingsphere.datasource.master.password=123456
# 配置第 2 个数据源
spring.shardingsphere.datasource.slave1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.slave1.jdbc-url=jdbc:mysql://172.19.240.201:3307/db_test
spring.shardingsphere.datasource.slave1.username=root
spring.shardingsphere.datasource.slave1.password=123456
# 配置第 3 个数据源
spring.shardingsphere.datasource.slave2.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.slave2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.slave2.jdbc-url=jdbc:mysql://172.19.240.201:3308/db_test
spring.shardingsphere.datasource.slave2.username=root
spring.shardingsphere.datasource.slave2.password=123456
# 读写分离类型,如: Static,Dynamic
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.type=Static
# 写数据源名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.write-data-source-name=master
# 读数据源名称,多个从数据源用逗号分隔
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.props.read-data-source-names=slave1,slave2
# 负载均衡算法名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.myds.load-balancer-name=alg_round
# 负载均衡算法配置
# 负载均衡算法类型
spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_round.type=ROUND_ROBIN
#spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_random.type=RANDOM
#spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.type=WEIGHT
#spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.slave1=1
#spring.shardingsphere.rules.readwrite-splitting.load-balancers.alg_weight.props.slave2=2
# 打印SQl
spring.shardingsphere.props.sql-show=true
testLoadBalance、testTransactional、testInsert
docker run -d \
-p 3301:3306 \
-v /software/mysql/user/conf:/etc/mysql/conf.d \
-v /software/mysql/user/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name mysql-user \
mysql:8.0.29
docker exec -it mysql-user env LANG=C.UTF-8 /bin/bash
CREATE DATABASE db_user;
CREATE TABLE t_user(
id BIGINT AUTO_INCREMENT,
uname VARCHAR(30)
);
# 进行表以及数据库创建
docker run -d \
-p 3302:3306 \
-v /software/mysql/order/conf:/etc/mysql/conf.d \
-v /software/mysql/order/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name mysql-order \
mysql:8.0.29
docker exec -it mysql-order env LANG=C.UTF-8 /bin/bash
CREATE DATABASE db_order;
CREATE TABLE t_order(
id BIGINT AUTO_INCREMENT,
order_no VARCHAR(30),
user_id BIGINT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
# 应用名称
spring.application.name=sharding-jdbc-demo
# 开发环境设置
spring.profiles.active=dev
# 内存模式
spring.shardingsphere.mode.type=Memory
# 配置真实数据源
spring.shardingsphere.datasource.names=server-user,server-order
# 配置第 1 个数据源
spring.shardingsphere.datasource.server-user.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-user.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.server-user.jdbc-url=jdbc:mysql://172.19.240.201:3301/db_user
spring.shardingsphere.datasource.server-user.username=root
spring.shardingsphere.datasource.server-user.password=123456
# 配置第 2 个数据源
spring.shardingsphere.datasource.server-order.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-order.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.server-order.jdbc-url=jdbc:mysql://172.19.240.201:3302/db_order
spring.shardingsphere.datasource.server-order.username=root
spring.shardingsphere.datasource.server-order.password=123456
# 标准分片表配置(数据节点)
# spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=值
# 值由数据源名 + 表名组成,以小数点分隔。
# <table-name>:逻辑表名
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=server-user.t_user
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=server-order.t_order
# 打印SQl
spring.shardingsphere.props.sql-show=true
testInsertOrderAndUser、testSelectFromOrderAndUser
# 创建容器
docker run -d \
-p 3310:3306 \
-v /software/mysql/order0/conf:/etc/mysql/conf.d \
-v /software/mysql/order0/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name mysql-order0 \
mysql:8.0.29
docker exec -it mysql-order0 env LANG=C.UTF-8 /bin/bash
CREATE DATABASE db_order;
USE db_order;
CREATE TABLE t_order0(
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
CREATE TABLE t_order1(
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
docker run -d \
-p 3311:3306 \
-v /software/mysql/order1/conf:/etc/mysql/conf.d \
-v /software/mysql/order1/data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name mysql-order1 \
mysql:8.0.29
docker exec -it mysql-order1 env LANG=C.UTF-8 /bin/bash
CREATE DATABASE db_order;
USE db_order;
CREATE TABLE t_order0(
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
CREATE TABLE t_order1(
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
水平分片主键需要在业务层进行控制,不能自增
# 应用名称
spring.application.name=sharding-jdbc-demo
# 开发环境设置
spring.profiles.active=dev
# 内存模式
spring.shardingsphere.mode.type=Memory
# 配置真实数据源
spring.shardingsphere.datasource.names=server-user,server-order0,server-order1
# 配置第 1 个数据源
spring.shardingsphere.datasource.server-user.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-user.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.server-user.jdbc-url=jdbc:mysql://172.19.240.201:3301/db_user?useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.server-user.username=root
spring.shardingsphere.datasource.server-user.password=123456
# 配置第 2 个数据源
spring.shardingsphere.datasource.server-order0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-order0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.server-order0.jdbc-url=jdbc:mysql://172.19.240.201:3310/db_order?useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.server-order0.username=root
spring.shardingsphere.datasource.server-order0.password=123456
# 配置第 3 个数据源
spring.shardingsphere.datasource.server-order1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-order1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.server-order1.jdbc-url=jdbc:mysql://172.19.240.201:3311/db_order?useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.server-order1.username=root
spring.shardingsphere.datasource.server-order1.password=123456
# 标准分片表配置(数据节点)
# spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=值
# 值由数据源名 + 表名组成,以小数点分隔。
# <table-name>:逻辑表名
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=server-user.t_user
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=server-order$->{0..1}.t_order$->{0..1}
#------------------------分库策略
# 分片列名称 根据user_id进行分库
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=user_id
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=alg_inline_userid
#------------------------分片算法配置
# 行表达式分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_inline_userid.type=INLINE
# 分片算法属性配置 我们对user_id取模,如果为偶数 放入第一个数据源,如果为奇数 放入第二个数据源
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_inline_userid.props.algorithm-expression=server-order$->{user_id % 2}
# 分片算法名称 取模分片算法 如果使用这个,就把上面的分配算法名称注释掉,和行表达式分片算法是一样的效果
#spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=alg_mod
# 取模分片算法
# 分片算法类型
#spring.shardingsphere.rules.sharding.sharding-algorithms.alg_mod.type=MOD
# 分片算法属性配置
#spring.shardingsphere.rules.sharding.sharding-algorithms.alg_mod.props.sharding-count=2
#------------------------分表策略
# 分片列名称 按照订单编号去分表 哈希取模 一条在t_order0,一条在t_order1表
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_no
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=alg_hash_mod
#------------------------分片算法配置
# 哈希取模分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_hash_mod.type=HASH_MOD
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_hash_mod.props.sharding-count=2
#------------------------分布式序列策略配置
# 分布式序列列名称 按照id生成雪花算法
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=id
# 分布式序列算法名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=alg_snowflake
# 分布式序列算法配置
# 分布式序列算法类型
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
# 打印SQl
spring.shardingsphere.props.sql-show=true
inline 表达式 ${begin…end} 表示范围区间 , ${[unit1,unit2,unit_x]}枚举值
testInsertOrder、testShardingSelectAll、testInsertOrderDatabaseStrategy、testShardingSelectByUserId
分库分表之后查询的时候会使用union all

根据ID进行分片是考虑到经常可能会用id进行查询

尽量让相关联的表数据在同一个库,同一个服务器,防止跨服务器跨库影响性能。
USE db_order;
CREATE TABLE t_order_item0(
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
price DECIMAL(10,2),
`count` INT,
primary key (id)
);
CREATE TABLE t_order_item1(
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
price DECIMAL(10,2),
`count` INT,
primary key (id)
);
USE db_order1;
CREATE TABLE t_order_item0(
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
price DECIMAL(10,2),
`count` INT,
primary key (id)
);
CREATE TABLE t_order_item1(
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
price DECIMAL(10,2),
`count` INT,
primary key (id)
);
# 应用名称
spring.application.name=sharding-jdbc-demo
# 开发环境设置
spring.profiles.active=dev
# 内存模式
spring.shardingsphere.mode.type=Memory
# 配置真实数据源
spring.shardingsphere.datasource.names=server-user,server-order0,server-order1
# 配置第 1 个数据源
spring.shardingsphere.datasource.server-user.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-user.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.server-user.jdbc-url=jdbc:mysql://172.19.240.201:3301/db_user?useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.server-user.username=root
spring.shardingsphere.datasource.server-user.password=123456
# 配置第 2 个数据源
spring.shardingsphere.datasource.server-order0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-order0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.server-order0.jdbc-url=jdbc:mysql://172.19.240.201:3310/db_order?useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.server-order0.username=root
spring.shardingsphere.datasource.server-order0.password=123456
# 配置第 3 个数据源
spring.shardingsphere.datasource.server-order1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-order1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.server-order1.jdbc-url=jdbc:mysql://172.19.240.201:3311/db_order?useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.server-order1.username=root
spring.shardingsphere.datasource.server-order1.password=123456
# 标准分片表配置(数据节点)
# spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=值
# 值由数据源名 + 表名组成,以小数点分隔。
# <table-name>:逻辑表名
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=server-user.t_user
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=server-order$->{0..1}.t_order$->{0..1}
spring.shardingsphere.rules.sharding.tables.t_order_item.actual-data-nodes=server-order$->{0..1}.t_order_item$->{0..1}
#------------------------分库策略
# 分片列名称 根据user_id进行分库
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=user_id
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=alg_inline_userid
# 分片列名称 根据user_id进行分库
spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-column=user_id
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-algorithm-name=alg_inline_userid
#------------------------分片算法配置
# 行表达式分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_inline_userid.type=INLINE
# 分片算法属性配置 我们对user_id取模,如果为偶数 放入第一个数据源,如果为奇数 放入第二个数据源
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_inline_userid.props.algorithm-expression=server-order$->{user_id % 2}
# 分片算法名称 取模分片算法 如果使用这个,就把上面的分配算法名称注释掉,和行表达式分片算法是一样的效果
#spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=alg_mod
# 取模分片算法
# 分片算法类型
#spring.shardingsphere.rules.sharding.sharding-algorithms.alg_mod.type=MOD
# 分片算法属性配置
#spring.shardingsphere.rules.sharding.sharding-algorithms.alg_mod.props.sharding-count=2
#------------------------分表策略
# 分片列名称 按照订单编号去分表 哈希取模 一条在t_order0,一条在t_order1表
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_no
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=alg_hash_mod
# 分片列名称 按照订单编号去分表 哈希取模 一条在t_order0,一条在t_order1表
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-column=order_no
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-algorithm-name=alg_hash_mod
#------------------------分片算法配置
# 哈希取模分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_hash_mod.type=HASH_MOD
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_hash_mod.props.sharding-count=2
#------------------------分布式序列策略配置
# 分布式序列列名称 按照id生成雪花算法
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=id
# 分布式序列算法名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=alg_snowflake
# 分布式序列列名称 按照id生成雪花算法
spring.shardingsphere.rules.sharding.tables.t_order_item.key-generate-strategy.column=id
# 分布式序列算法名称
spring.shardingsphere.rules.sharding.tables.t_order_item.key-generate-strategy.key-generator-name=alg_snowflake
# 分布式序列算法配置
# 分布式序列算法类型
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
# 打印SQl
spring.shardingsphere.props.sql-show=true
testInsertOrderAndOrderItem
@Data
public class OrderVo {
private String orderNo;
private BigDecimal amount;
}
数组的形式默认会用空格拼接
@Select ({"SELECT o.order_no, sum(price * `count`) AS amount",
"FROM t_order o INNER JOIN t_order_item t on o.user_id = t.user_id",
"GROUP BY o.order_no"})
List<OrderVo> getOrderAmount();
testGetOrderAmount 默认会进行多次笛卡尔积,即使使用了完全相同的分库分表规则,还是会全部进行笛卡尔积
,显然多余了很多查询,性能差

# 应用名称
spring.application.name=sharding-jdbc-demo
# 开发环境设置
spring.profiles.active=dev
# 内存模式
spring.shardingsphere.mode.type=Memory
# 配置真实数据源
spring.shardingsphere.datasource.names=server-user,server-order0,server-order1
# 配置第 1 个数据源
spring.shardingsphere.datasource.server-user.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-user.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.server-user.jdbc-url=jdbc:mysql://172.19.240.201:3301/db_user?useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.server-user.username=root
spring.shardingsphere.datasource.server-user.password=123456
# 配置第 2 个数据源
spring.shardingsphere.datasource.server-order0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-order0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.server-order0.jdbc-url=jdbc:mysql://172.19.240.201:3310/db_order?useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.server-order0.username=root
spring.shardingsphere.datasource.server-order0.password=123456
# 配置第 3 个数据源
spring.shardingsphere.datasource.server-order1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.server-order1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.server-order1.jdbc-url=jdbc:mysql://172.19.240.201:3311/db_order?useSSL=false&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.server-order1.username=root
spring.shardingsphere.datasource.server-order1.password=123456
# 标准分片表配置(数据节点)
# spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes=值
# 值由数据源名 + 表名组成,以小数点分隔。
# <table-name>:逻辑表名
spring.shardingsphere.rules.sharding.tables.t_user.actual-data-nodes=server-user.t_user
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=server-order$->{0..1}.t_order$->{0..1}
spring.shardingsphere.rules.sharding.tables.t_order_item.actual-data-nodes=server-order$->{0..1}.t_order_item$->{0..1}
#------------------------分库策略
# 分片列名称 根据user_id进行分库
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=user_id
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=alg_inline_userid
# 分片列名称 根据user_id进行分库
spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-column=user_id
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order_item.database-strategy.standard.sharding-algorithm-name=alg_inline_userid
#------------------------分片算法配置
# 行表达式分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_inline_userid.type=INLINE
# 分片算法属性配置 我们对user_id取模,如果为偶数 放入第一个数据源,如果为奇数 放入第二个数据源
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_inline_userid.props.algorithm-expression=server-order$->{user_id % 2}
# 分片算法名称 取模分片算法 如果使用这个,就把上面的分配算法名称注释掉,和行表达式分片算法是一样的效果
#spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=alg_mod
# 取模分片算法
# 分片算法类型
#spring.shardingsphere.rules.sharding.sharding-algorithms.alg_mod.type=MOD
# 分片算法属性配置
#spring.shardingsphere.rules.sharding.sharding-algorithms.alg_mod.props.sharding-count=2
#------------------------分表策略
# 分片列名称 按照订单编号去分表 哈希取模 一条在t_order0,一条在t_order1表
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_no
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=alg_hash_mod
# 分片列名称 按照订单编号去分表 哈希取模 一条在t_order0,一条在t_order1表
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-column=order_no
# 分片算法名称
spring.shardingsphere.rules.sharding.tables.t_order_item.table-strategy.standard.sharding-algorithm-name=alg_hash_mod
#------------------------分片算法配置
# 哈希取模分片算法
# 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_hash_mod.type=HASH_MOD
# 分片算法属性配置
spring.shardingsphere.rules.sharding.sharding-algorithms.alg_hash_mod.props.sharding-count=2
#------------------------分布式序列策略配置
# 分布式序列列名称 按照id生成雪花算法
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=id
# 分布式序列算法名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=alg_snowflake
# 分布式序列列名称 按照id生成雪花算法
spring.shardingsphere.rules.sharding.tables.t_order_item.key-generate-strategy.column=id
# 分布式序列算法名称
spring.shardingsphere.rules.sharding.tables.t_order_item.key-generate-strategy.key-generator-name=alg_snowflake
# 分布式序列算法配置
# 分布式序列算法类型
spring.shardingsphere.rules.sharding.key-generators.alg_snowflake.type=SNOWFLAKE
# 打印SQl
spring.shardingsphere.props.sql-show=true
#------------------------ 绑定表
spring.shardingsphere.rules.sharding.binding-tables[0]=t_order,t_order_item
如果不配置绑定表:测试结果8条SQL;配置后只有4条SQL。
绑定表:按照分片规则,对一组表进行绑定,需要提前对关联表进行统一的分片分库,同时必须使用分库键进行关联。
广播表就是在所有数据库都有这张表,并且数据都一样。适用于数据量不大且需要海量数据的表进行关联查询的场景,例如字典表
USE db_order;
CREATE TABLE t_dict(
id BIGINT,
dict_type VARCHAR(200),
PRIMARY KEY (id)
);
USE db_user;
CREATE TABLE t_dict(
id BIGINT,
dict_type VARCHAR(200),
PRIMARY KEY (id)
);
docker run -d \
-v /software/server/proxy-a/conf:/opt/shardingsphere-proxy/conf \
-v /software/server/proxy-a/ext-lib:/opt/shardingsphere-proxy/ext-lib \
-e ES_JAVA_OPTS="-Xmx256m -Xms256m -Xmn128m" \
-p 3320:3307 \
--name server-proxy-a \
apache/shardingsphere-proxy:5.1.1
docker 无法远程连接:docker exec -it server-proxy-a env LANG=C.UTF-8 /bin/bash
cd /opt/shardingsphere-proxy/logs
tail -100f stdout.log
后续启动可能容器内存不够,所以-e ES_JAVA_OPTS="-Xmx256m -Xms256m -Xmn128m"进行设置
# 配置服务器
vim /software/server/proxy-a/conf/server.yaml
rules:
- !AUTHORITY
users:
- root@%:root
provider:
type: ALL_PRIVILEGES_PERMITTED
props:
sql-show: true
docker restart server-proxy-a
# 配置读写分离
vim /software/server/proxy-a/conf/config-readwrite-splitting.yaml
schemaName: readwrite_splitting_db
dataSources:
write_ds:
url: jdbc:mysql://172.19.240.201:3306/db_test?useSSL=false&allowPublicKeyRetrieval=true
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
read_ds_0:
url: jdbc:mysql://172.19.240.201:3307/db_test?useSSL=false&allowPublicKeyRetrieval=true
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
read_ds_1:
url: jdbc:mysql://172.19.240.201:3308/db_test?useSSL=false&allowPublicKeyRetrieval=true
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !READWRITE_SPLITTING
dataSources:
readwrite_ds:
type: Static
props:
write-data-source-name: write_ds
read-data-source-names: read_ds_0,read_ds_1
docker restart server-proxy-a
docker exec -it server-proxy-a env LANG=C.UTF-8 /bin/bash
# 查看日志
tail -20f /opt/shardingsphere-proxy/logs/stdout.log
显然已经把库进行同步
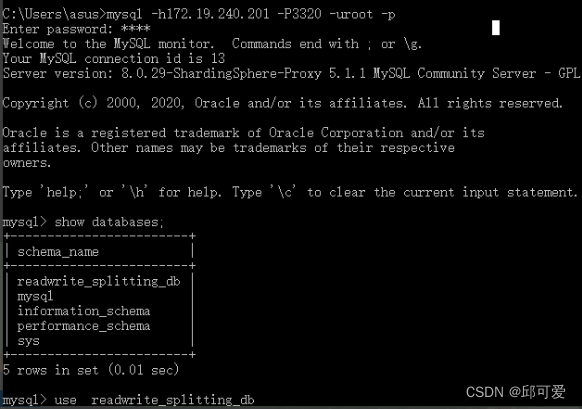
查询测试
插入测试
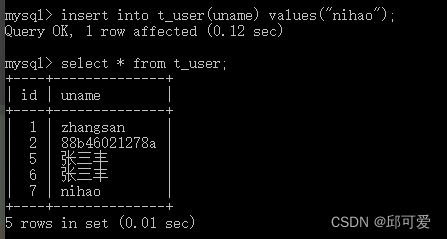
日志确实向写库进行写

<!--导入sharding依赖-->
<!-- <dependency>-->
<!-- <groupId>org.apache.shardingsphere</groupId>-->
<!-- <artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>-->
<!-- <version>5.1.1</version>-->
<!-- </dependency>-->
# 应用名称
spring.application.name=sharding-proxy-demo
# 开发环境设置
spring.profiles.active=dev
#mysql数据库连接(proxy)
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://172.19.240.201:3320/readwrite_splitting_db?serverTimezone=GMT%2B8&useSSL=false
spring.datasource.username=root
spring.datasource.password=root
#mybatis日志
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
testUserSelectAll
vi /software/server/proxy-a/conf/config-sharding.yaml
schemaName: sharding_db
dataSources:
ds_user:
url: jdbc:mysql://172.19.240.201:3301/db_user?useSSL=false&allowPublicKeyRetrieval=true
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_order:
url: jdbc:mysql://172.19.240.201:3302/db_order?useSSL=false&allowPublicKeyRetrieval=true
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
tables:
t_user:
actualDataNodes: ds_user.t_user
t_order:
actualDataNodes: ds_order.t_order
docker restart server-proxy-a
# 查看日志
tail -20f /opt/shardingsphere-proxy/logs/stdout.log
docker start mysql-user
docker start mysql-order0
docker start mysql-order1
# 修改配置
vi /software/server/proxy-a/conf/config-sharding.yaml
schemaName: sharding_db
dataSources:
ds_user:
url: jdbc:mysql://172.19.240.201:3301/db_user?useSSL=false&allowPublicKeyRetrieval=true
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_order0:
url: jdbc:mysql://172.19.240.201:3310/db_order?useSSL=false&allowPublicKeyRetrieval=true
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_order1:
url: jdbc:mysql://172.19.240.201:3311/db_order?useSSL=false&allowPublicKeyRetrieval=true
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
tables:
t_user:
actualDataNodes: ds_user.t_user
t_order:
actualDataNodes: ds_order${0..1}.t_order${0..1}
tableStrategy:
standard:
shardingColumn: order_no
shardingAlgorithmName: alg_hash_mod
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: alg_mod
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
t_order_item:
actualDataNodes: ds_order${0..1}.t_order_item${0..1}
tableStrategy:
standard:
shardingColumn: order_no
shardingAlgorithmName: alg_hash_mod
databaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: alg_mod
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake
bindingTables:
- t_order,t_order_item
broadcastTables:
- t_dict
shardingAlgorithms:
alg_mod:
type: MOD
props:
sharding-count: 2
alg_hash_mod:
type: HASH_MOD
props:
sharding-count: 2
keyGenerators:
snowflake:
type: SNOWFLAKE
docker restart server-proxy-a
# 查看日志
docker exec -it server-proxy-a env LANG=C.UTF-8 /bin/bash
# 查看日志
tail -20f /opt/shardingsphere-proxy/logs/stdout.log

日志如下

目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
文章目录1、自相关函数ACF2、偏自相关函数PACF3、ARIMA(p,d,q)的阶数判断4、代码实现1、引入所需依赖2、数据读取与处理3、一阶差分与绘图4、ACF5、PACF1、自相关函数ACF自相关函数反映了同一序列在不同时序的取值之间的相关性。公式:ACF(k)=ρk=Cov(yt,yt−k)Var(yt)ACF(k)=\rho_{k}=\frac{Cov(y_{t},y_{t-k})}{Var(y_{t})}ACF(k)=ρk=Var(yt)Cov(yt,yt−k)其中分子用于求协方差矩阵,分母用于计算样本方差。求出的ACF值为[-1,1]。但对于一个平稳的AR模型,求出其滞
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我来自C、php和bash背景,很容易学习,因为它们都有相同的C结构,我可以将其与我已经知道的联系起来。然后2年前我学了Python并且学得很好,Python对我来说比Ruby更容易学。然后从去年开始,我一直在尝试学习Ruby,然后是Rails,我承认,直到现在我还是学不会,讽刺的是那些打着简单易学的烙印,但是对于我这样一个老练的程序员来说,我只是无法将它