插值与拟合的区别:
- 实现方法:插值要求曲线穿过样本点,而拟合不需要穿过样本点,只要求总体误差最小。
- 结果形式:插值是分段逼近样本点,没有同一的逼近函数;函数拟合则用一个函数去逼近,有完整的表达式。
- 侧重点:插值可以用于估计区间内某些点对应的函数值;拟合不仅可以估计区间内的点,也可以预测区间外的点。
- 应用场合:插值多用于精确数据集;拟合多用于统计数据集。
polyfit函数用于一元多次曲线拟合(亦多项式拟合),形如: y = a x 5 + b x 4 + c x 3 + d x 2 + e x + f y=ax^5+bx^4+cx^3+dx^2+ex+f y=ax5+bx4+cx3+dx2+ex+f,我们已知 x x x、 y y y样本数据,利用此函数求解参数(系数) a a a、 b b b、 c c c、 d d d、 e e e、 f f f。
regress函数用于一元或多元线性回归(拟合),形如: y = a x 1 + b x 2 + c x 3 + d x 4 + e y=ax_1+bx_2+cx_3+dx_4+e y=ax1+bx2+cx3+dx4+e,我们已知 x 1 x_1 x1、 x 2 x_2 x2、 x 3 x_3 x3、 x 4 x_4 x4、 y y y样本数据,利用此函数求解参数(系数) a a a、 b b b、 c c c、 d d d、 e e e。
调用格式:
[P,S,mu]=polyfit(X,Y,m)
[P,S]=polyfit(X,Y,m)
P=polyfit(X,Y,m)
参数解释:
根据样本数据X和Y,产生一个m次多项式系数向量P及其在采样点误差数据S,mu是一个二元向量,mu(1)是mean(X),而mu(2)是std(X)。
x=0: 0.1: 1;
y=[-0.447, 1.978, 3.11, 5.25, 5.02, 4.66, 4.01, 4.58, 3.45, 5, 35];
p = polyfit(x, y, 3) % 三次多项式拟合
xx = 0: 0.01 : 1;
yy = polyval(p, xx) ; % 根据系数向量p计算在xx点处的函数值
plot(xx, yy, '-b', x, y, 'markersize', 20)
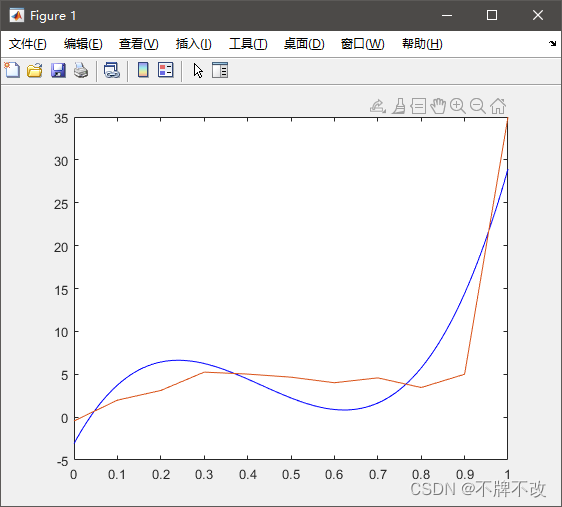
当还需要进行线性回归分析时,可以再利用corrcoef函数获取相关系数。
在matlab的regress函数中置信区间bint、rint以及stats后面三个值全都为无穷大,这说明数据不服从线性关系,应考虑用非线性拟合函数来拟合。
调用格式:
参数解释:
调用该函数要保证目标函数的形式已知,比如目标函数为: y = a x 1 + b x 2 + c x 3 + d x 4 + e y=ax_1+bx_2+cx_3+dx_4+e y=ax1+bx2+cx3+dx4+e,或者是 y = a x 1 2 + b x 2 2 + c x 1 + d x 2 + e x 1 × x 2 + f y = ax_1^2+bx_2^2+cx_1+dx_2+ex_1×x_2+f y=ax12+bx22+cx1+dx2+ex1×x2+f这样的多元多次多项式。传入参数,调用该函数后得到拟合出的系数值。
该函数根据多个样本的 x i x_i xi和 y y y拟合出多项式的系数。
返回值解释:
x1=[3.91 6.67 5.33 5.56 6.12 7.92 5.82 5.5 5.59 6.12 6.68 6.93]';
x2=[9.43 14.5 15.8 19.8 17.4 23.8 31.6 37.1 36.4 32.2 36.6 41.3]';
X=[ones(12,1), x1, x2];
Y=[280 338 405 432 452 582 596 602 606 621 629 656]';
[b,bint,r,rint,stats] = regress(Y,X)
rcoplot(r,rint) % 绘制残差图
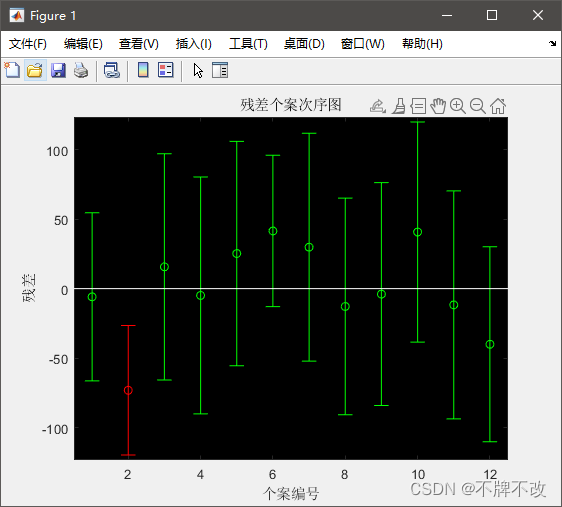
残差图:残差图中圆圈是每个数据点的实际残差,横线区间是残差置信区间,置信区间穿过原点说明方程拟合的很好;未通过原点,可视为异常点,比如上图中显示第二组数据未通过原点,因此第二组数据拟合结果较差。
之后可将第二组数据去除后再次进行拟合,得到的结果更为准确。
%% 目标函数:y=Ax1^2+Bx2^2+Cx1+Dx2+Ex1*x2+F (这是一个二次函数,两个变量,大写的字母是常数)
format long;
y=[7613.51 7850.91 8381.86 9142.81 10813.6 8631.43 8124.94 9429.79 10230.81 10163.61 9737.56 8561.06 7781.82 7110.97]';
x1=[7666 7704 8148 8571 8679 7704 6471 5870 5289 3815 3335 2927 2758 2591]';
x2=[16.22 16.85 17.93 17.28 17.23 17 19 18.22 16.3 13.37 11.62 10.36 9.83 9.25]';
X=[ones(size(y)) x1.^2 x2.^2 x1 x2 x1.*x2]; % 构造X矩阵!!!
[b,bint,r,rint,stats] = regress(y,X)
结果如下:
b =
1.0e+04 *
-1.353935450267780
0.000000089381408
-0.005811190715467
-0.000605427789545
0.479983626458515
-0.000037869040292
bint =
1.0e+04 *
-2.621944842897225 -0.085926057638335
0.000000034253753 0.000000144509063
-0.027588831662544 0.015966450231609
-0.001309493882546 0.000098638303455
0.119564693553897 0.840402559363132
-0.000105954336341 0.000030216255756
r =
1.0e+02 *
-4.397667358984126
-2.361417286008764
-1.434643909138249
-5.904203974279353
7.511701773844997
5.570806699070599
-2.447861341816779
0.494622057474844
6.376995507987613
-6.789520765534544
2.744335484633611
1.578124015815701
-0.803533566911865
-0.137737336155596
rint =
1.0e+03 *
-1.219619853471144 0.340086381674319
-1.426253867770768 0.953970410569015
-0.919089416302223 0.632160634474573
-1.568776909577359 0.387936114721488
0.111430783412043 1.390909571356956
-0.533006860832905 1.647168200647025
-1.168898277755904 0.679326009392548
-0.977546779130818 1.076471190625786
-0.398546999643731 1.673946101241254
-1.439044988776064 0.081140835669156
-0.919162439561023 1.468029536487746
-1.088788822632291 1.404413625795431
-1.271236485719865 1.110529772337492
-1.017369947314269 0.989822480083149
stats =
1.0e+05 *
0.000008444011951 0.000086828553270 0.000000043344434 3.162249735298930
参数X的第一列为全1列向量,从第二列开始分别为每一个系数对应项对应样本数据构成的列向量,本题的目标函数是个二元二次的,由于regress函数只能解决线性问题,因此我们将 x 1 2 x_1^2 x12看作第一项, x 2 2 x_2^2 x22看作第二项, x 1 x_1 x1看作第三项, x 2 x_2 x2看作第四项, x 1 x 2 x_1x_2 x1x2看作第五项,这样就相当于一个五元一次的目标函数了。
b为对应的参数 b(1)为F(最后那个常数项) ,b(2)为A(第一个参数),b(3)为B,b(4)为C,b(4)为D,b(5)为E。
bint为b的95%置信区间。
stats的第三个参数为F检测的p值,p值很小(p<0.05),说明拟合模型有效。
已知随机性参数与多样性度量和与收敛性度量之间的关系如下表,多样性与收敛性同样重要,问选取随机参数的平衡点。
表1 随机性参数与多样性度量之间的关系
| x | 0.03 | 0.06 | 0.09 | 0.12 | 0.15 | 0.18 | 0.21 | 0.24 | 0.27 | 0.3 |
| y1 | 0.01 | 0.01 | 0.02 | 0.03 | 0.06 | 0.07 | 0.13 | 0.17 | 0.25 | 0.37 |
表2 随机性参数与收敛性度量之间的关系
| x | 0.03 | 0.06 | 0.09 | 0.12 | 0.15 | 0.18 | 0.21 | 0.24 | 0.27 | 0.3 |
| y1 | 0.85 | 0.76 | 0.68 | 0.62 | 0.54 | 0.52 | 0.5 | 0.49 | 0.48 | 0.47 |
x=0.03:0.03:0.3;
y1=[0.01,0.01,0.02,0.03,0.06,0.07,0.13,0.17,0.25,0.37];
y2=[0.85,0.76,0.68,0.62,0.56,0.52,0.49,0.46,0.43,0.39];
plot(x,y1,'*',x,y2,'o');
legend('多样性','收敛性')
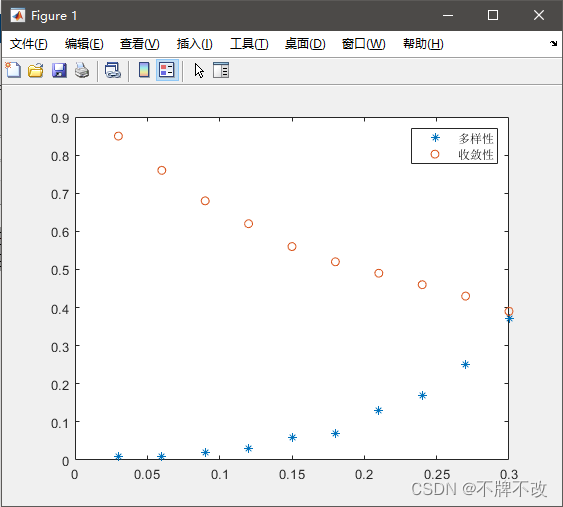
问题分析:
随机性参数的增长导致多样性增加,收敛性降低;两者同等重要,则取平衡点;平衡点最佳位置是多样性和收敛性相等的地方。
解决方案:
第一步:分别对多样性和收敛性进行拟合,得到拟合曲线。
第二步:找到两曲线的交点。
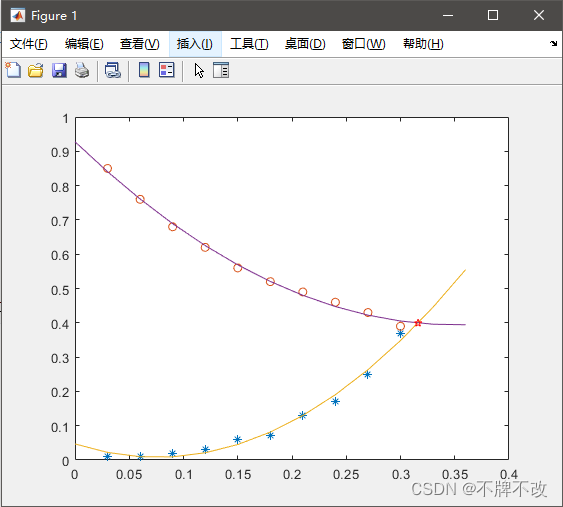
p1=polyfit(x,y1,2);
p2=polyfit(x,y2,2);
p=p1-p2;
xi=roots(p); % -1.14148334023966 0.316172995412073
xj=0:0.03:0.36;
yj1=polyval(p1,xj);
yj2=polyval(p2,xj);
yi=polyval(p1,xi(2))
plot(x,y1,'*',x,y2,'o',xj,yj1,xj,yj2,xi(2),yi,'rp');
由于这个函数用的比较少,网上相关资料也就比较少,因此下面部分思路比较主观。
具有边界或线性约束的线性最小二乘求解器。
求解以下形式的最小二乘曲线拟合问题:
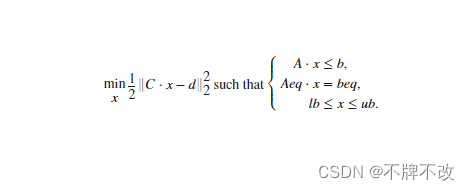
这里我就举个最简单的例子:
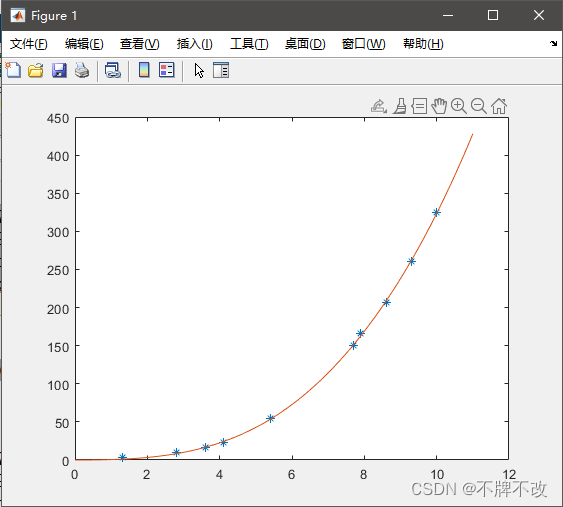
%% y=ax^2+bxsinx+cx^3
xdata = [3.6,7.7,9.3,4.1,8.6,2.8,1.3,7.9,10.0,5.4];
ydata = [16,150.5,260.1,22.5,206.5,9.9,2.7,165.5,325.0,54.5];
C =[ xdata'.^2, xdata'.*sin(xdata'),xdata'.^3]; d = ydata';
[x, resnorm, residual] = lsqlin(C, d);
%% 绘图
xi = 0:0.1:11;
f = @(c, x) c(1).*x.^2 + c(2).*x.*sin(x) + c(3).*x.^3;
plot(xdata, ydata, '*', xi, f(x, xi))
函数的缺点:当上边界(ub)或下边界(lb)或Aeq或beq中的限制是对非多项式项进行的时,这些限制矩阵是很难构造出来的。比如,上面的代码中将 x 2 x^2 x2、 x s i n x xsinx xsinx、 x 3 x^3 x3分别看作第一、二、三项,因此约束条件矩阵也必须是对这三项的约束,但是若题目只给出了对 x x x的限制呢?若题目只给出了对 x e x l g x xe^xlgx xexlgx的限制呢?很难转化成对每一项的约束条件。
不知道如何处理”某些项有上下界的限制,而其他项没有上下界的限制“的情况。
对于这个函数所知甚少,且网上相关内容太少了。
最小二乘法求解非线性拟合问题!!!
调用格式:
x = lsqcurvefit(fun,x0,xdata,ydata)
x = lsqcurvefit(fun,x0,xdata,ydata,lb,ub)
x = lsqcurvefit(fun,x0,xdata,ydata,lb,ub,options)
[x,resnorm,residual,exitflag] = lsqcurvefit(…)
参数解释:
返回值解释:
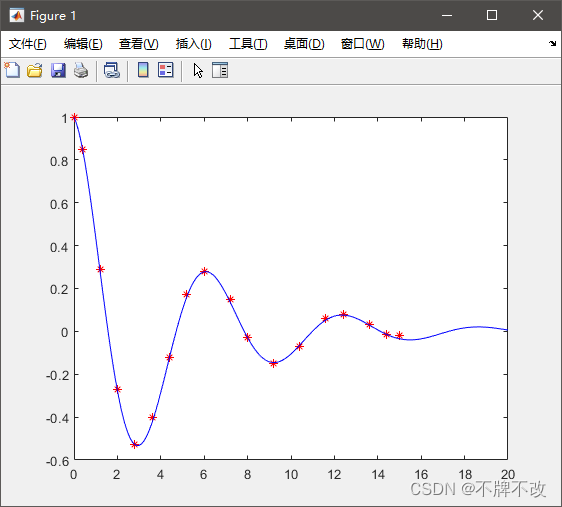
%% y=tcos(kx)e^(wx)
x=[0,0.4,1.2,2,2.8,3.6,4.4,5.2,6,7.2,8,9.2,10.4,11.6,12.4,13.6,14.4,15]';
y=[1,0.85,0.29,-0.27,-0.53,-0.4,-0.12,0.17,0.28,0.15,-0.03,-0.15,-0.07,0.059,0.08,0.032,-0.015,-0.02]';
f= @(c,x) c(1)*cos(c(2)*x).*exp(c(3)*x);
c0= [0 0 0];
[c, fval]= lsqcurvefit(f, c0, x, y);
xx=0:0.1:20;
yy=f(c, xx);
plot(x, y, 'r*', xx, yy, 'b-');
disp(c);
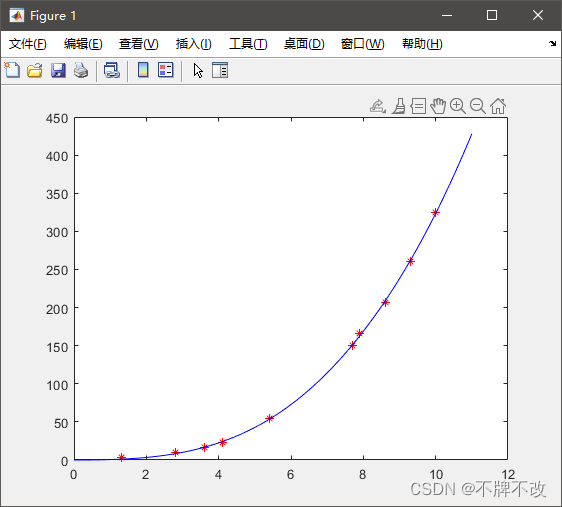
注意:这里定义的函数比较特别,待拟合参数也要作为函数的参数传到函数中,我们将待拟合参数视为一个向量传入函数的目的是使函数的形式更加简洁。
xdata = [3.6,7.7,9.3,4.1,8.6,2.8,1.3,7.9,10.0,5.4];
ydata = [16,150.5,260.1,22.5,206.5,9.9,2.7,165.5,325.0,54.5];
c0=[ 0 0 0];
f_h=@(c, x) c(1)*x.^2 + c(2)*x.*sin(x) + c(3)*x.^3;
[c, resnorm, r]=lsqcurvefit(f_h, c0, xdata, ydata);
%% 绘图
xx=0:0.1:11;
yy=f_h(c, xx);
plot(xdata, ydata, 'r*', xx, yy, 'b-');
disp(c);
自行学习,用的较少,需要时直接百度即可(对于打比赛的而言)。
matlab打开matlab,用最简单的imread方法读取一个图像clcclearimg_h=imread('hua.jpg');返回一个数组(矩阵),往往是a*b*cunit8类型解释一下这个三维数组的意思,行数、数和层数,unit8:指数据类型,无符号八位整形,可理解为0~2^8的数三个层数分别代表RGB三个通道图像rgb最常用的是24-位实现方法,即RGB每个通道有256色阶(2^8)。基于这样的24-位RGB模型的色彩空间可以表现256×256×256≈1670万色当imshow传入了一个二维数组,它将以灰度方式绘制;可以把图像拆分为rgb三层,可以以灰度的方式观察它figure(1
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标
一、机器人介绍 此处是基于MATLABRVC工具箱,对ABB-IRB-1200型号的微型机械臂进行正逆向运动学分析,并利Simulink工具实现对机械臂进行具有动力学参数的末端轨迹规划仿真,最后根据机械模型设计Simulink-Adams联合仿真。 图1.ABBIRB 1200尺寸参数示意图ABBIRB 1200提供的两种型号广泛适用于各作业,且两者间零部件通用,两种型号的工作范围分别为700 mm 和 900 mm,大有效负载分别为 7 kg 和5 kg。 IRB 1200 能够在狭小空间内能发挥其工作范围与性能优势,具有全新的设计、小型化的体积、高效的性能、易于集成、便捷的接
慢跑者与狗问题描述一个慢跑者在平面上沿椭圆以恒定的速率𝒗=𝟏跑步,设椭圆方程为:𝒙=𝟏𝟎+𝟐𝟎𝒄𝒐𝒔(𝒕),𝒚=𝟐𝟎+𝟓𝒔𝒊𝒏(𝒕)。突然有一只狗攻击他,这只狗从原点出发,以恒定速率𝒘跑向慢跑者,狗的运动方向始终指向慢跑者。分别求出𝒘=𝟐𝟎,𝒘=𝟓时狗的运动轨迹。模型建立设时刻t慢跑者的坐标为(𝑿(𝒕),𝒀(𝒕)),狗的坐标为(𝒙(𝒕),𝒚(𝒕))。则𝑿=𝟏𝟎+𝟐𝟎𝒄𝒐𝒔(𝒕),𝒀=𝟐𝟎+𝟏𝟓𝒔𝒊𝒏(𝒕),狗从(0,0)出发,建立狗的运动轨迹的参数方程:由于狗始终对准人,因而狗的速度方向平行于狗与人位置的差向量:消去𝝀,得由题意𝑿=𝟏𝟎+𝟐𝟎𝒄𝒐𝒔𝒕,𝒀=𝟐𝟎+1𝟓𝒔𝒊𝒏(𝒕),狗从(0,0)
在正常工作环境中往往是可以使用无线网络的,此时安装一个matlab也不是什么难事;但是也难免也会遇到一些工作电脑不允许链接无线网络,此时若安装一个matlab则是一件非常痛苦的事,因为其安装包就20多个G,当时我是用手机开热点下载的,仅仅下载安装包就浪费了一个下午+一个晚上; 下面就举一个例子,针对安装过matlab和未安装过matlab的情况去介绍C++调用matlab函数的操作流程:一、封装matlab函数首先把matlab代码封装成函数的形式,下面举一个简单的函数为例;functionc=myadd(a,b)c=a+b;end二、编译matlab函数具体的编译
我正在寻找进行对数回归(对数方程的曲线拟合)的Rubygem或库。我试过statsample(http://ruby-statsample.rubyforge.org/),但它似乎没有我要找的东西。有人有什么建议吗? 最佳答案 尝试使用“statsample”gem。您可以使用类似的方法执行指数、对数、幂、正弦或任何其他变换。我希望这有帮助。require'statsample'#IndependentVariablex_data=[Math.exp(1),Math.exp(2),Math.exp(3),Math.exp(4),Ma
我正在尝试编写Ruby代码来检查我发现的特定消息上的椭圆曲线数字签名算法(ECDSA)签名here.问题是我不知道如何将公钥的八位字节字符串转换为OpenSSL::PKey::EC::Point目的。如果我用C写这个,我会把八位字节字符串传递给OpenSSL的o2i_ECPublicKey,它做的事情接近我想要的,实际上被referenceimplementation使用.但是,我搜索了sourcecodeofRuby(MRI)而且它不包含对o2i_ECPublicKey的调用,所以我不知道如何在不编写C扩展的情况下使用Ruby中的该函数。这是十六进制的八位字节字符串。它只是一个0x0
matlab中矩阵点乘和乘的区别MATLAB中,一、矩阵相乘:表示两个矩阵相乘。二、矩阵点乘:表示矩阵中对应位置的元素分别相乘。三、举例3.1矩阵相乘3.2矩阵点乘MATLAB中,一、矩阵相乘:表示两个矩阵相乘。前提条件:满足矩阵相乘的规则,即前矩阵的列数等于后矩阵的行数。二、矩阵点乘:表示矩阵中对应位置的元素分别相乘。前提条件:满足矩阵点乘的规则,即前后矩阵维度相同。三、举例3.1矩阵相乘Example1:A=[123;456]A=123456>>B=[1;2;3]B=123>>C=A*BC=1432这时如果用点乘就会报错Example2:>>A=[123;456;789]A=1234567
目录1.GM(1,1)模型2. 组合预测模型3. GMDH进行时间序列预测4.运行结果5Matlab代码实现1.GM(1,1)模型灰色预测是一种对具有不确定因素的系统进行预测的方法,能有效解决数据少、序列的完整性及可靠性低的问题。GM(1,1)模型是一种较为常用的灰色模型,GM(1,1)预测模型的建立实质上就是对原始数据序列作一次累加生成,使生成数据序列呈显出一定规律,然后通过建立微分方程模型,求得拟合曲线,进而对系统进行预测。2. 组合预测模型灰色模型是通过对原始数据加工处理来弱化随机性的,若数据存在较大的波动性,预测出来的结果可能会存在较大误差。ARIMA模型对于预测的模型比较理想,要求时