论文题目:《Hierarchical Text-Conditional Image Generation with CLIP Latents》(使用CLIP特征的 层次文本条件图像生成)
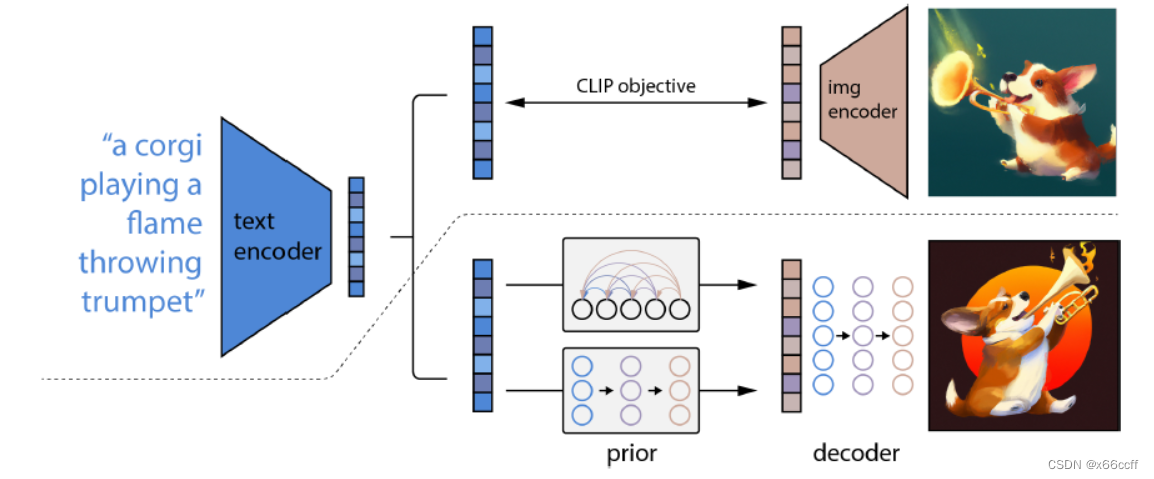
首先训练一个 CLIP 模型,进行图片-文本对的对比学习,训练得到一个 text encoder 和一个 img encoder,然后将 text encoder 固定住,拿来进行 DALL·E 2 的训练。
先经过一个 prior 扩散模型,从文本特征得到图像特征,然后再通过图像特征decode 得到完整的图片。
文本 -> 文本特征 ->[prior模型] -> 图像特征 ->[decoder模型]-> 图像
这段解读来自博文
https://blog.csdn.net/u012193416/article/details/126162618
结合这个图来看,首先虚线上面是一个clip,这个clip是提前训练好的,在dalle2的训练期间不会再去训练clip,是个权重锁死的,在dalle2的训练时,输入也是一对数据,一个文本对及其对应的图像,首先输入一个文本,经过clip的文本编码模块(bert,clip对图像使用vit,对text使用bert进行编码,clip是基本的对比学习,两个模态的编码很重要,模态编码之后直接余弦求相似度了),在输入一个图像,经过clip的图像编码模块,产生了图像的vector,这个图像vector其实是gt。产生的文本编码输入到第一个prior模型中,这是一个扩散模型,也可以用自回归的transformer,这个扩散模型输出一组图像vector,这时候通过经过clip产生的图像vector进行监督,此处其实是一个监督模型,后面是一个decoder模块,在以往的dalle中,encoder和decoder是放在dvae中一起训练的,但是此处的deocder是单训的,也是一个扩散模型,其实虚线之下的生成模型,是将一个完整的生成步骤,变成了二阶段显式的图像生成,作者实验这种显式的生成效果更好。这篇文章称自己为unclip,clip是将输入的文本和图像转成特征,而dalle2是将文本特征转成图像特征再转成图像的过程,其实图像特征到图像是通过一个扩散模型实现的。在deocder时既用了classifier-free guidence也用了clip的guidence,这个guidence指的是在decoder的过程中,输入是t时刻的一个带噪声的图像,最终输出是一个图像,这个带噪声的图像通过unet每一次得到的一个特征图可以用一个图像分类器去做判定,此处一般就用交叉熵函数做一个二分类,但是可以获取图像分类的梯度,利用这个梯度去引导扩散去更好的decoder。
GAN的缺点:保真度高,但是多样性不好。而扩散模型在刚刚提出(数年前)的时候,保真度不及 GAN,但是多样性很好。人们为了提高 GAN 的生成多样性,从 AE(Auto-Encoder)中改进得到了 VAE(Variational Auto-Encoder),VAE 的改进是将 AE 的 bottleneck 从预测一个低维特征图改为了预测是从一个正态分布的哪个位置采样得到的,这样,训练完成之后,就可以将 Encoder 部分扔掉,让正态分布随机采样,从而生成不同的图片了。在 VAE 之后,又提出了 VQ-VAE,VQ-VAE-2 模型,随后出现的就是现在所说的 DALLE 模型的第一代(使用 VQ-VAE 的改进版),然后是DALLE 2(使用扩散模型的版本,并使用了很多其他技巧),至此,扩散模型完全打败了GAN。
这个 Decoder解码器,实际上是一个扩散模型 DDPM (Denoising Diffusion Probabilistic Models,去噪声扩散概率模型)
扩散模型的原理:
给定一个图像 x 0 x_0 x0 ,每一次加一点点高斯噪声,变成 x t x_t xt 直到加到 x T x_T xT 变成一个完全是高斯噪声的图像,然后训练一个模型让模型根据 x t x_t xt 图像,预测 x t − 1 x_{t-1} xt−1 图像的情况(实际上,是预测残差图 ϵ \epsilon ϵ ,也就是预测在哪些位置加了噪声,有点 ResNet的感觉了,这样训练起来更方便,效果更好),模型因为输入输出是一样的尺寸,所以一般使用 U-Net 进行生成,原来用 T T T 步生成图片,就用 T T T 步循环 forward 这个 U-Net 网络来进行图片的还原,这样就可以做到从高斯模型还原回一副真实的图片,训练的时候,用( x t − 1 x_{t-1} xt−1 , x t x_{t} xt)构建数据集 ground truth,进行训练,生成的时候,让模型从高斯噪声图片一步步还原(生成)图片。此外,还通过某种方式往这个 U-Net 中加入当前的时间信息(目前预测到 t t t 步),来提醒模型当前是需要增加低频(轮廓,色彩)信息还是高频(细节)信息。
DALL·E 2的训练过程中还使用到一些训练技巧:
在从 x t x_{t} xt 生成 x t − 1 x_{t-1} xt−1 的过程中,为了使得生成的图片更加逼真,引入了一个在加了噪声的 ImageNet 图像数据集上预训练好的分类器 f f f ,来对 x t x_{t} xt 生成的图片进行分类,看是否和文本特征匹配,并反传梯度给 U-Net 模型,让模型在不匹配的地方重点进行生成
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
写在之前Shader变体、Shader属性定义技巧、自定义材质面板,这三个知识点任何一个单拿出来都是一套知识体系,不能一概而论,本文章目的在于将学习和实际工作中遇见的问题进行总结,类似于网络笔记之用,方便后续回顾查看,如有以偏概全、不祥不尽之处,还望海涵。1、Shader变体先看一段代码......Properties{ [KeywordEnum(on,off)]USL_USE_COL("IsUseColorMixTex?",int)=0 [Toggle(IS_RED_ON)]_IsRed("IsRed?",int)=0}......//中间省略,后续会有完整代码 #pragmamulti_c
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
我正在使用RABL输出Sunspot/SOLR结果集,搜索结果对象由多种模型类型组成。目前在rablView中我有:objectfalsechild@search.results=>:resultsdoattribute:id,:resource,:upccodeattribute:display_description=>:descriptioncode:start_datedo|r|r.utc_start_date.to_iendcode:end_datedo|r|r.utc_end_date.to_iendendchild@search=>:statsdoattribute:to
TCP是面向连接的协议,连接的建立和释放是每一次面向连接的通信中必不可少的过程。TCP连接的管理就是使连接的建立和释放都能正常地进行。三次握手TCP连接的建立—三次握手建立TCP连接①若主机A中运行了一个客户进程,当它需要主机B的服务时,就发起TCP连接请求,并在所发送的分段中用SYN=1表示连接请求,并产生一个随机发送序号x,如果连接成功,A将以x作为其发送序号的初始值:seq=x。主机B收到A的连接请求报文,就完成了第一次握手。客户端发送SYN=1表示连接请求客户端发送一个随机发送序号x,如果连接成功,A将以x作为其发送序号的初始值:seq=x②主机B如果同意建立连接,则向主机A发送确认报
VXLAN简介定义RFC定义了VLAN扩展方案VXLAN(VirtualeXtensibleLocalAreaNetwork,虚拟扩展局域网)。VXLAN采用MACinUDP(UserDatagramProtocol)封装方式,是NVO3(NetworkVirtualizationoverLayer3)中的一种网络虚拟化技术。目的随着网络技术的发展,云计算凭借其在系统利用率高、人力/管理成本低、灵活性/可扩展性强等方面表现出的优势,已经成为目前企业IT建设的新趋势。而服务器虚拟化作为云计算的核心技术之一,得到了越来越多的应用。服务器虚拟化技术的广泛部署,极大地增加了数据中心的计算密度;同时,为
我有一个连接表create_table"combine_tags",force:truedo|t|t.integer"user_id"t.integer"habit_id"t.integer"valuation_id"t.integer"goal_id"t.integer"quantified_id"end其目的是让tag_cloud为多个模型工作。我把它放在application_controllerdeftag_cloud@tags=CombineTag.tag_counts_on(:tags)end我的tag_cloud看起来像这样:css_class%>#orthisdepen
目录一、原理部分1、什么是串行通信(1)并行通信与串行通信(2)串行通信的制式(3)串行通信的主要方式 2、配置串口(1)SCON和PCON:串行口1的控制寄存器(2)SBUF:串行口数据缓冲寄存器 (3)AUXR:辅助寄存器编辑(4)ES、PS:与串行口1中断相关的寄存器(5)波特率设置 3、串口框架编写二、程序案例一、原理部分1、什么是串行通信(1)并行通信与串行通信微控制器与外部设备的数据通信,根据连线结构和传送方式的不同,可以分为两种:并行通信和串行通信。并行通信:数据的各位同时发送与接收,每个数据位使用一条导线,这种方式传输快,但是需要多条导线进行信号传输。串行通信:数据一位一
这篇文章,主要介绍如何使用SpringCloud微服务组件从0到1搭建一个微服务工程。目录一、从0到1搭建微服务工程1.1、基础环境说明(1)使用组件(2)微服务依赖1.2、搭建注册中心(1)引入依赖(2)配置文件(3)启动类1.3、搭建配置中心(1)引入依赖(2)配置文件(3)启动类1.4、搭建API网关(1)引入依赖(2)配置文件(3)启动类1.5、搭建服务提供者(1)引入依赖(2)配置文件(3)启动类1.6、搭建服务消费者(1)引入依赖(2)配置文件(3)启动类1.7、运行测试一、从0到1搭建微服务工程1.1、基础环境说明(1)使用组件这里主要是使用的SpringCloudNetflix
目录文章信息写在前面Background&MotivationMethodDCNV2DCNV3模型架构Experiment分类检测文章信息Title:InternImage:ExploringLarge-ScaleVisionFoundationModelswithDeformableConvolutionsPaperLink:https://arxiv.org/abs/2211.05778CodeLink:https://github.com/OpenGVLab/InternImage写在前面拿到文章之后先看了一眼在ImageNet1k上的结果,确实很高,超越了同等大小下的VAN、RepLK