目录
熵权法是一种客观赋值方法。在具体使用的过程中,熵权法根据各指标的变异程度,利用信息熵计算出各指标的熵权,再通过熵权对各指标的权重进行修正,从而得到较为客观的指标权重。
一般来说,若某个指标的信息熵指标权重确定方法之熵权法越小,表明指标值得变异程度越大,提供的信息量越多,在综合评价中所能起到的作用也越大,其权重也就越大。
相反,若某个指标的信息熵指标权重确定方法之熵权法越大,表明指标值得变异程度越小,提供的信息量也越少,在综合评价中所起到的作用也越小,其权重也就越小。
这个步骤视情况自己决定把。。。。
不同的指标代表含义不一样,有的指标越大越好,称为越大越优型指标。有的指标越小越好,称为越小越优型指标,而有些指标在某个点是最好的,称为某点最优型指标。为方便评价,应把所有指标转化成越大越优型指标。
设有m个待评对象,n个评价指标,可以构成数据矩阵

设数据矩阵内元素,经过指标正向化处理过后的元素为 (Xij)'
越小越优型指标:C,D属于此类指标

其他处理方法也可,只要指标性质不变即可
某点最优型指标:E属于此类指标
设最优点为a, 当a=90时E最优。

其他处理方法也可,只要指标性质不变即可
越大越优型指标:其余所有指标属于此类指标
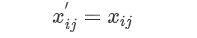
此类指标可以不用处理,想要处理也可,只要指标性质不变
最大最小值归一化
语法
[Y,PS] = mapminmax(X,YMIN,YMAX)
[Y,PS] = mapminmax(X,FP)
Y = mapminmax('apply',X,PS)
X = mapminmax('reverse',Y,PS)
说明:
[Y,PS] = mapminmax(X,YMIN,YMAX)mapminmax(X,YMIN,YMAX) 将矩阵的每一行压缩到 [YMIN,YMAX],其中当前行的最大值变为YMAX,最小值变为YMIN。PS为结构体储存相关信息,如最大最小值等
[Y,PS] = mapminmax(X,FP)其中FP为结构体类型,这时就是将矩阵的每一行压缩到[ FP.ymin, FP.ymax]中
Y = mapminmax('apply',X,PS)可以将之前储存的结构体应用到新的矩阵中,利用上一步得到的PS来映射X到Y
X = mapminmax('reverse',Y,PS)可按照之前数据规律,反归一化,利用归一化后的Y和PS重新得到X
因为每个指标的数量级不一样,需要把它们化到同一个范围内再比较。标准化的方法比较多,这里仅用最大最小值标准化方法。
设标准化后的数据矩阵元素为rij,由上可得指标正向化后数据矩阵元素为 (Xij)'


为避免Pij零元素的出现出现计算错误,归一化最低区间可以从0.002开始。如果某个指标的信息熵Ej越小,就表明其指标值的变异程度越大,提供的 信息量也越大,可以认为该指标在综合评价起到作用也越大。
权重为:
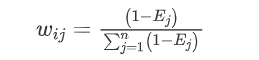
得分为:

用一篇高引用的核心期刊论文[1]为例,针对各个银行的资产收益率,费用利润率,逾期贷款率,非生息资产率,流动性比率,资产使用率,自有资本率指标进行评价。设资产收益率为A,费用利润率为B,逾期贷款率为C,非生息资产率为D,流动性比率为E,资产使用率为F,自有资本率为G。数据表格如下:
%读取数据
data=xlsread('D:\桌面\shangquan.xlsx')返回:

在这里,我们可以看到读取的数据中,有部分是我们不想要的,于是我们得做处理
data=data(:,3:end) %只取指标数据返回:

%指标正向 化处理后数据为data1
data1=data;%%越小越优型处理
index=[3,4];%越小越优指标位置
for i=1:length(index)
data1(:,index(i))=max(data(:,index(i)))-data(:,index(i))
end
返回:

%%某点最优型指标处理
index=[5];
a=90;%最优型数值
for i=1:length(index)
data1(:,index(i))=1-abs(data(:,index(i))-a)/max(abs(data(:,index(i))-a))
end返回:

data2=mapminmax(data1',0.002,1) %标准化到0.002-1区间返回:

由于是mapminmax对行进行标准化,所以需要转置一下
data2=data2'返回:

%得到信息熵
[m,n]=size(data2);
p=zeros(m,n);
for j=1:n
p(:,j)=data2(:,j)/sum(data2(:,j))
end
for j=1:n
E(j)=-1/log(m)*sum(p(:,j).*log(p(:,j)))
end返回:

%计算权重
w=(1-E)/sum(1-E)返回:

%计算得分
s=data2*w';
Score=100*s/max(s);
disp('12个银行分别得分为:')
disp(Score)返回:

clc;clear;
%读取数据
data=xlsread('D:\桌面\shangquan.xlsx');
data=data(:,3:end); %只取指标数据
%指标正向 化处理后数据为data1
data1=data;
%%越小越优型处理
index=[3,4];%越小越优指标位置
for i=1:length(index)
data1(:,index(i))=max(data(:,index(i)))-data(:,index(i));
end
%%某点最优型指标处理
index=[5];
a=90;%最优型数值
for i=1:length(index)
data1(:,index(i))=1-abs(data(:,index(i))-a)/max(abs(data(:,index(i))-a));
end
%数据标准化 mapminmax对行进行标准化,所以转置一下
data2=mapminmax(data1',0.002,1); %标准化到0.002-1区间
data2=data2';
%得到信息熵
[m,n]=size(data2);
p=zeros(m,n);
for j=1:n
p(:,j)=data2(:,j)/sum(data2(:,j));
end
for j=1:n
E(j)=-1/log(m)*sum(p(:,j).*log(p(:,j)));
end
%计算权重
w=(1-E)/sum(1-E);
%计算得分
s=data2*w';
Score=100*s/max(s);
disp('12个银行分别得分为:')
disp(Score)
matlab打开matlab,用最简单的imread方法读取一个图像clcclearimg_h=imread('hua.jpg');返回一个数组(矩阵),往往是a*b*cunit8类型解释一下这个三维数组的意思,行数、数和层数,unit8:指数据类型,无符号八位整形,可理解为0~2^8的数三个层数分别代表RGB三个通道图像rgb最常用的是24-位实现方法,即RGB每个通道有256色阶(2^8)。基于这样的24-位RGB模型的色彩空间可以表现256×256×256≈1670万色当imshow传入了一个二维数组,它将以灰度方式绘制;可以把图像拆分为rgb三层,可以以灰度的方式观察它figure(1
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
目录0专栏介绍1平面2R机器人概述2运动学建模2.1正运动学模型2.2逆运动学模型2.3机器人运动学仿真3动力学建模3.1计算动能3.2势能计算与动力学方程3.3动力学仿真0专栏介绍?附C++/Python/Matlab全套代码?课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等);局部规划(DWA、APF等);曲线优化(贝塞尔曲线、B样条曲线等)。?详情:图解自动驾驶中的运动规划(MotionPlanning),附几十种规划算法1平面2R机器人概述如图1所示为本文的研究本体——平面2R机器人。对参数进行如下定义:机器人广义坐标
一、机器人介绍 此处是基于MATLABRVC工具箱,对ABB-IRB-1200型号的微型机械臂进行正逆向运动学分析,并利Simulink工具实现对机械臂进行具有动力学参数的末端轨迹规划仿真,最后根据机械模型设计Simulink-Adams联合仿真。 图1.ABBIRB 1200尺寸参数示意图ABBIRB 1200提供的两种型号广泛适用于各作业,且两者间零部件通用,两种型号的工作范围分别为700 mm 和 900 mm,大有效负载分别为 7 kg 和5 kg。 IRB 1200 能够在狭小空间内能发挥其工作范围与性能优势,具有全新的设计、小型化的体积、高效的性能、易于集成、便捷的接
慢跑者与狗问题描述一个慢跑者在平面上沿椭圆以恒定的速率𝒗=𝟏跑步,设椭圆方程为:𝒙=𝟏𝟎+𝟐𝟎𝒄𝒐𝒔(𝒕),𝒚=𝟐𝟎+𝟓𝒔𝒊𝒏(𝒕)。突然有一只狗攻击他,这只狗从原点出发,以恒定速率𝒘跑向慢跑者,狗的运动方向始终指向慢跑者。分别求出𝒘=𝟐𝟎,𝒘=𝟓时狗的运动轨迹。模型建立设时刻t慢跑者的坐标为(𝑿(𝒕),𝒀(𝒕)),狗的坐标为(𝒙(𝒕),𝒚(𝒕))。则𝑿=𝟏𝟎+𝟐𝟎𝒄𝒐𝒔(𝒕),𝒀=𝟐𝟎+𝟏𝟓𝒔𝒊𝒏(𝒕),狗从(0,0)出发,建立狗的运动轨迹的参数方程:由于狗始终对准人,因而狗的速度方向平行于狗与人位置的差向量:消去𝝀,得由题意𝑿=𝟏𝟎+𝟐𝟎𝒄𝒐𝒔𝒕,𝒀=𝟐𝟎+1𝟓𝒔𝒊𝒏(𝒕),狗从(0,0)
在正常工作环境中往往是可以使用无线网络的,此时安装一个matlab也不是什么难事;但是也难免也会遇到一些工作电脑不允许链接无线网络,此时若安装一个matlab则是一件非常痛苦的事,因为其安装包就20多个G,当时我是用手机开热点下载的,仅仅下载安装包就浪费了一个下午+一个晚上; 下面就举一个例子,针对安装过matlab和未安装过matlab的情况去介绍C++调用matlab函数的操作流程:一、封装matlab函数首先把matlab代码封装成函数的形式,下面举一个简单的函数为例;functionc=myadd(a,b)c=a+b;end二、编译matlab函数具体的编译
matlab中矩阵点乘和乘的区别MATLAB中,一、矩阵相乘:表示两个矩阵相乘。二、矩阵点乘:表示矩阵中对应位置的元素分别相乘。三、举例3.1矩阵相乘3.2矩阵点乘MATLAB中,一、矩阵相乘:表示两个矩阵相乘。前提条件:满足矩阵相乘的规则,即前矩阵的列数等于后矩阵的行数。二、矩阵点乘:表示矩阵中对应位置的元素分别相乘。前提条件:满足矩阵点乘的规则,即前后矩阵维度相同。三、举例3.1矩阵相乘Example1:A=[123;456]A=123456>>B=[1;2;3]B=123>>C=A*BC=1432这时如果用点乘就会报错Example2:>>A=[123;456;789]A=1234567
目录1.GM(1,1)模型2. 组合预测模型3. GMDH进行时间序列预测4.运行结果5Matlab代码实现1.GM(1,1)模型灰色预测是一种对具有不确定因素的系统进行预测的方法,能有效解决数据少、序列的完整性及可靠性低的问题。GM(1,1)模型是一种较为常用的灰色模型,GM(1,1)预测模型的建立实质上就是对原始数据序列作一次累加生成,使生成数据序列呈显出一定规律,然后通过建立微分方程模型,求得拟合曲线,进而对系统进行预测。2. 组合预测模型灰色模型是通过对原始数据加工处理来弱化随机性的,若数据存在较大的波动性,预测出来的结果可能会存在较大误差。ARIMA模型对于预测的模型比较理想,要求时
🔗运行环境:Matlab🚩作者:左手の明天🥇精选专栏:《python》🔥推荐专栏:《算法研究》📚选自专栏:《数学建模》🧿优秀专栏:《Matlab神经网络案例分析》目前持续更新的专栏:🥇专栏:MatlabGUI编程技巧🔥专栏:Matlab从无到有系列大家好,我是左手の明天!今天和大家分享数学建模重要模型——马尔可夫链模型。在对数学建模之马尔可夫链模型进行介绍时,首先需要明确两个问题:马氏链模型用来干什么马尔可夫预测法是应用概率论中马尔可夫链(Markovchain)的理论和方法来研究分析时间序列的变化规律,并由此预测其未来变化趋势的一种预测技术。马氏链模型什么时候用应用马尔可夫链的计算方法进行马
我的~/.inputrc中有这些行:setediting-modevisetkeymapvi这允许我在每个使用GNUreadlines进行文本输入的程序中使用vi键绑定(bind)。示例:python、irb、sftp、bash、sqlite3等.它使使用命令行变得轻而易举。Matlab不使用readlines,但vi键绑定(bind)在调试或交互工作时会惊人。有现成的解决方案吗?我倾向于在命令行中使用matlab-nosplash-nodesktop,这让我开始思考:是否可以编写一个包装器,确实使用readlines并通过matlab的输入?(如果我必须实现它,我可能更愿意在Ruby