Kafka 本质上是⼀个消息队列。与zeromq不同的是,Kafka是一个独立的框架而不是一个库。这里主要介绍其原理,至于具体的安装等操作不做介绍,只是提示一下,第一次运行时,先设置前台运行,看会不会报错。
注意下图没有画上zookeeper,请自行脑补。kafka需要连接到zookeeper,来完成注册发现等集群操作。broker都是由zookeeper管理。
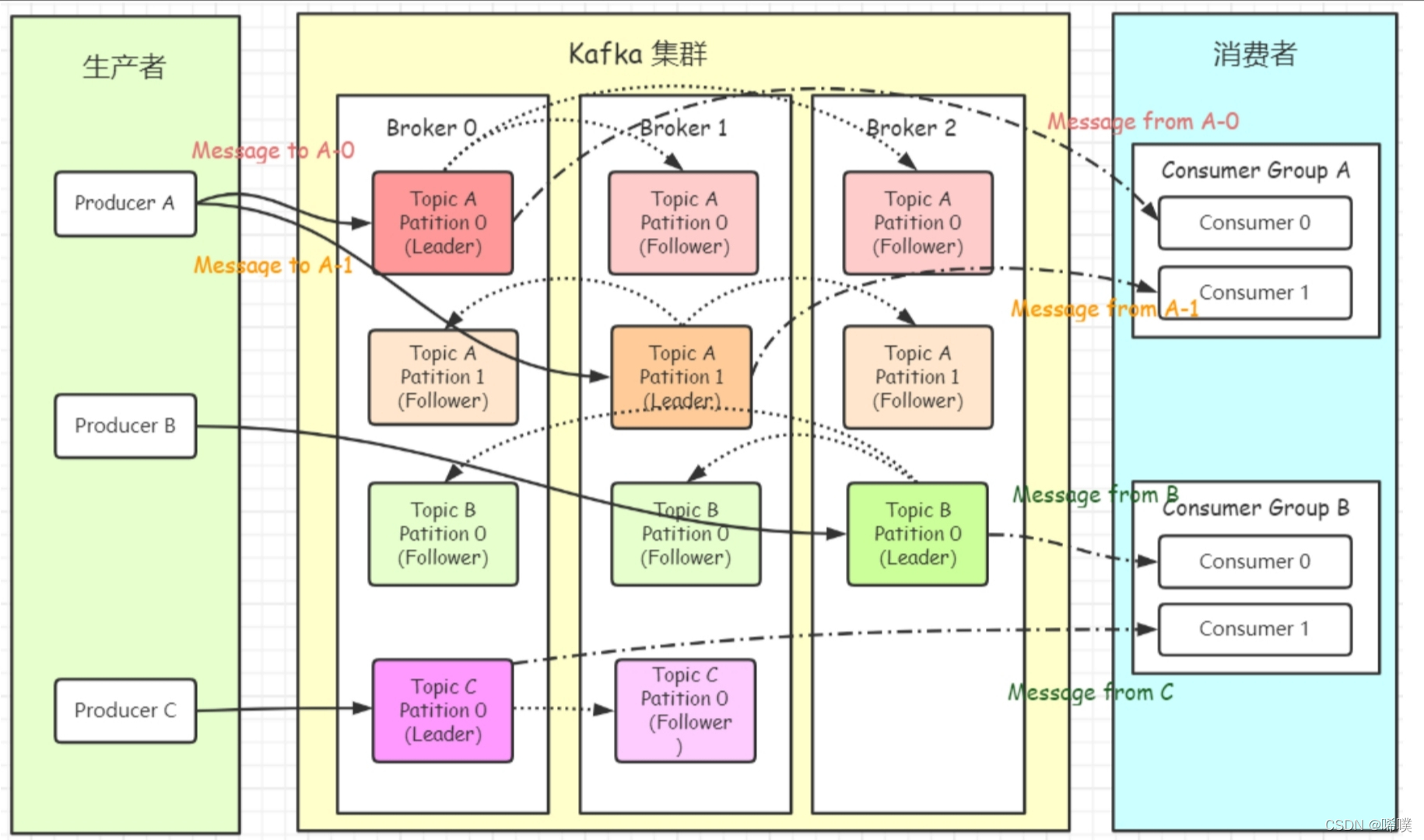
先给出 Kafka ⼀些重要概念,让⼤家对 Kafka 有个整体的认识和感知,后⾯还会详细的解析每⼀个概念的作⽤以及更深⼊的原理:
kafka 存储的消息来⾃任意多被称为 Producer ⽣产者的进程。数据从⽽可以被发布到不同的Topic 主题下的不同 Partition 分区。在⼀个分区内,这些消息被索引并连同时间戳存储在⼀起。其它被称为 Consumer 消费者的进程可以从分区订阅消息。
Kafka 运⾏在⼀个由⼀台或多台服务器组成的集群上,并且分区可以跨集群结点分布。
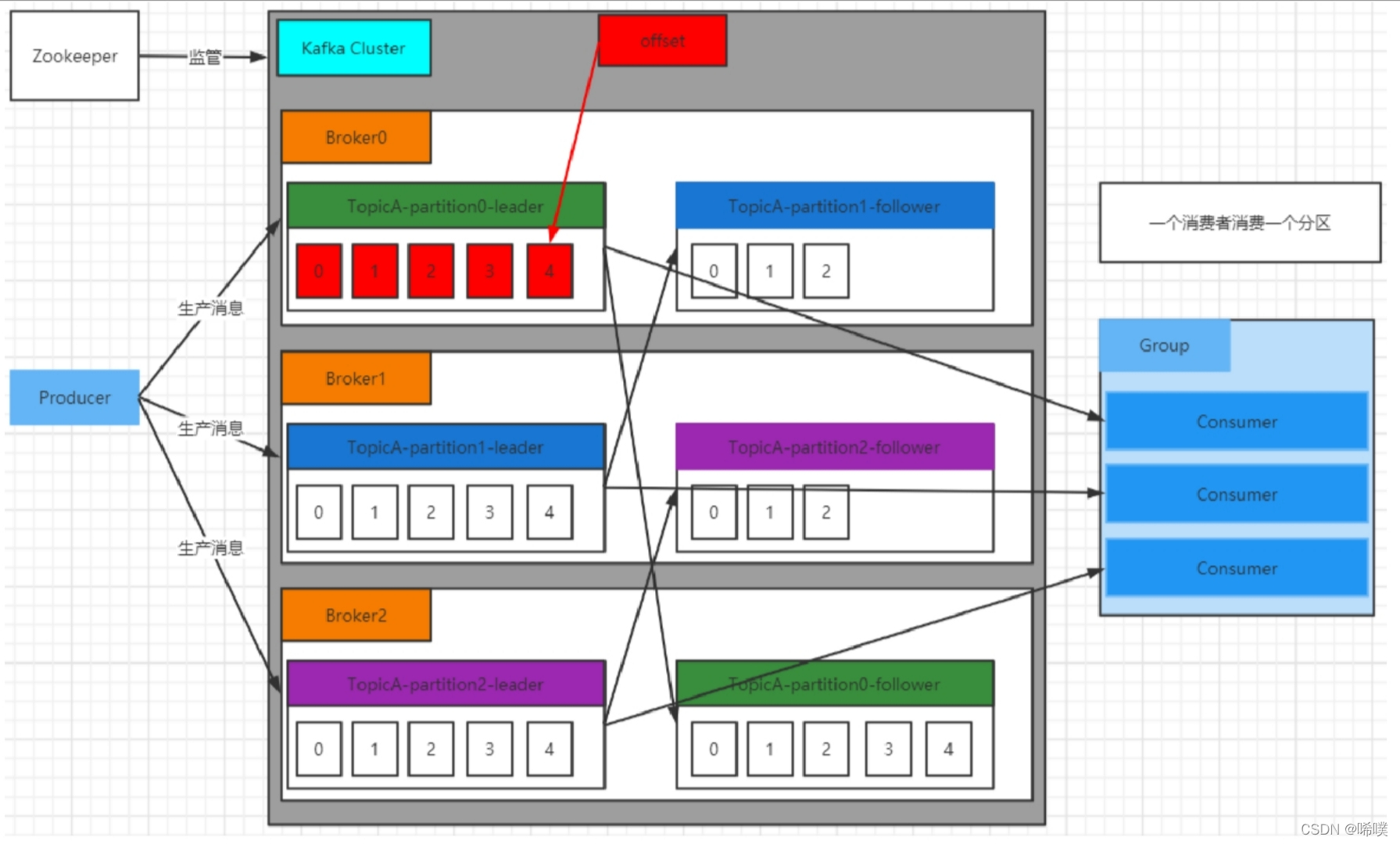
Kafka集群将 Record 流存储在称为 Topic 的类中,每个记录由⼀个键、⼀个值和⼀个时间戳组成。
Kafka 中消息是以 Topic 进⾏分类的,⽣产者⽣产消息,消费者消费消息,⾯向的都是同⼀个Topic。Topic 是逻辑上的概念,⽽ Partition 是物理上的概念,每个 Partition 对应于⼀个 log ⽂件,该log ⽂件中存储的就是 Producer ⽣产的数据。Producer ⽣产的数据会不断追加到该 log ⽂件末端,且每条数据都有⾃⼰的 Offset。消费者组中的每个消费者,都会实时记录⾃⼰消费到了哪个 Offset,以便出错恢复时,从上次的位置继续消费。
由于⽣产者⽣产的消息会不断追加到 log ⽂件末尾,为防⽌ log ⽂件过⼤导致数据定位效率低下,Kafka 采取了分⽚和索引机制。它将每个 Partition 分为多个 Segment,每个 Segment 对应两个⽂件:“.index” 索引⽂件和“.log” 数据⽂件。这种索引思想值得我们学习应用到平时的开发中。
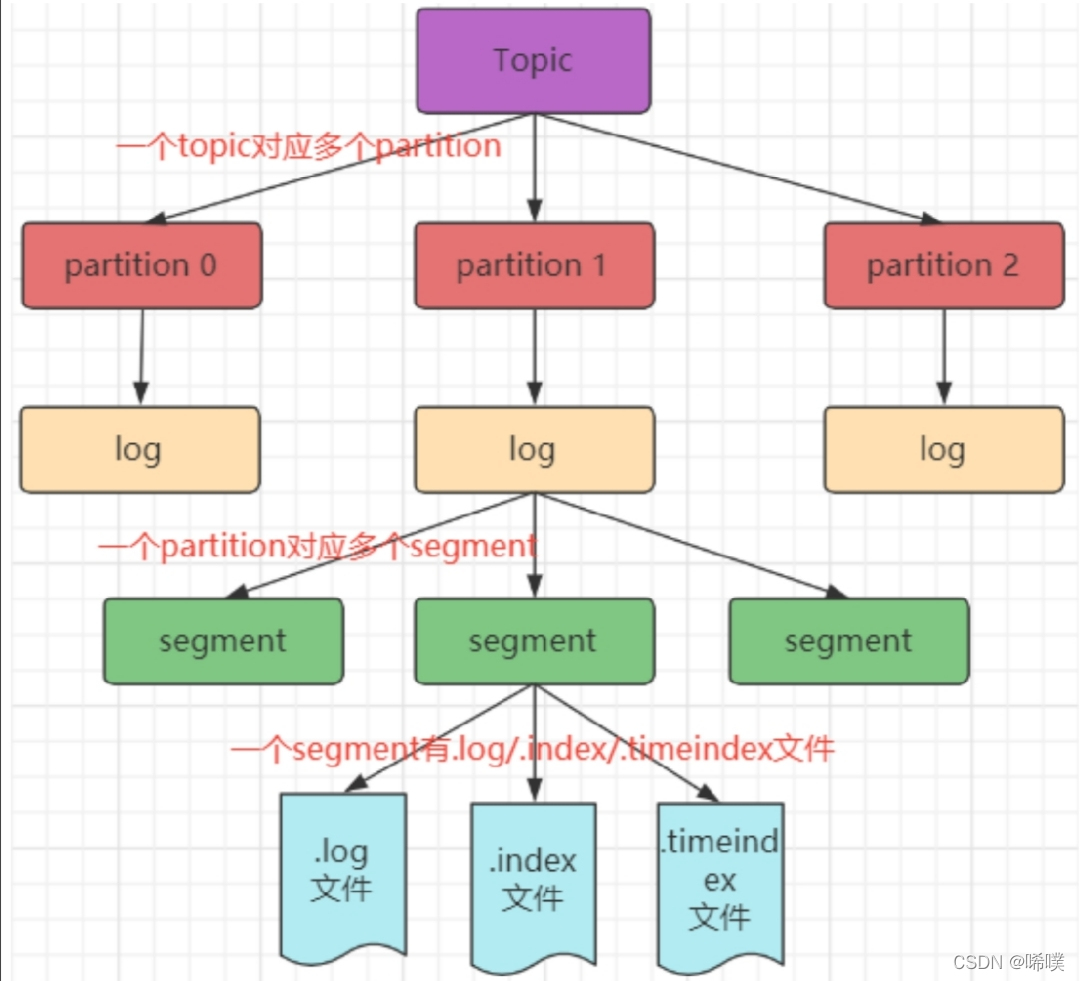
这些⽂件位于同⼀⽂件下,该⽂件夹的命名规则为:topic 名-分区号。例如,test这个 topic 有三个分区,则其对应的⽂件夹为 test-0,test-1,test-2。
$ ls /tmp/kafka-logs/test-1
00000000000000009014.index
00000000000000009014.log
00000000000000009014.timeindex
leader-epoch-checkpoint
index 和 log ⽂件以当前 Segment 的第⼀条消息的 Offset 命名。下图为 index ⽂件和 log ⽂件的结构示意图
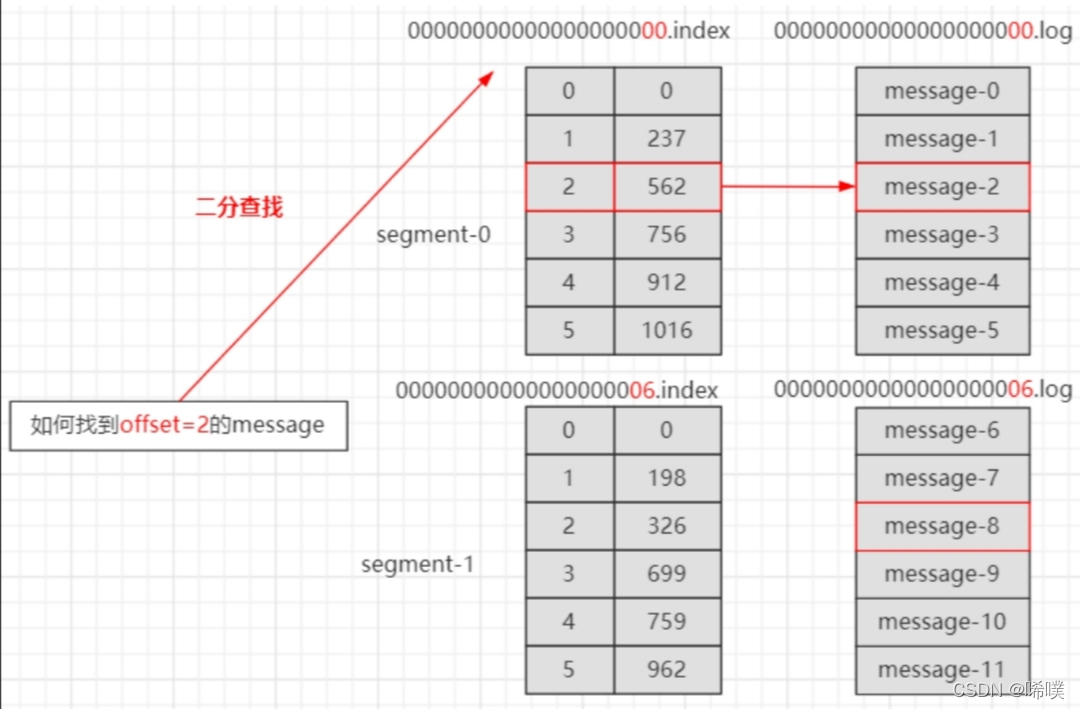
“.index” ⽂件存储⼤量的索引信息,“.log” ⽂件存储⼤量的数据,索引⽂件中的元数据指向对应数据⽂件中 Message 的物理偏移量。
使用shell命令查看索引
./kafka-dump-log.sh --files /tmp/kafka-logs/test-1/00000000000000000000.index
分区原因:
分区原则:我们需要将 Producer 发送的数据封装成⼀个 ProducerRecord 对象。该对象需要指定⼀些参数:
指明 Partition 的情况下,直接将给定的 Value 作为 Partition 的值;没有指明 Partition 但有 Key 的情况下,将 Key 的 Hash 值与分区数取余得到 Partition 值;既没有 Partition 又没有 Key 的情况下,第⼀次调⽤时随机⽣成⼀个整数(后⾯每次调⽤都在这个整数上⾃增),将这个值与可⽤的分区数取余,得到 Partition 值,也就是常说的 Round-Robin轮询算法。
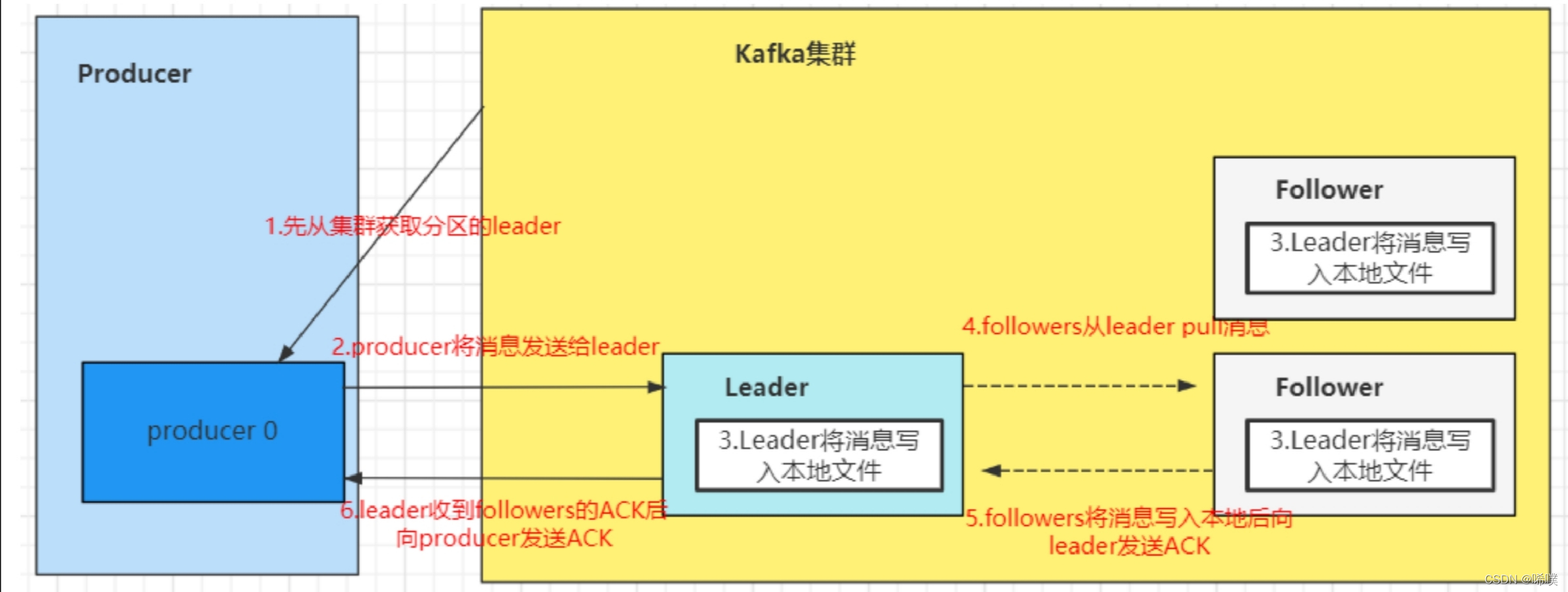
Producer⽣产者,是数据的⼊⼝。Producer在写⼊数据的时候永远的找leader,不会直接将数据写⼊follower。下图很好地阐释了生产者的工作流程。
这里获取分区信息,是从zookeeper中获取的。
生产者不会每个消息都调用一次send(),这样效率太低,默认是数据攒到16K或是超时(如10ms)会send()一次。注意这里发消息是异步操作。
producer端设置request.required.acks=0;只要请求已发送出去,就算是发送完了,不关心有没有写成功。性能很好,如果是对一些日志进行分析,可以承受丢数据的情况,用这个参数,性能会很好。
request.required.acks=1;发送一条消息,当leader partition写入成功以后,才算写入成功。不过这种方式也有丢数据的可能。
request.required.acks=-1;需要ISR列表里面,所有副本都写完以后,这条消息才算写入成功。
设计一个不丢数据的方案:数据不丢失的方案:1)分区副本 >=2 2)acks = -1 3)min.insync.replicas >=2。
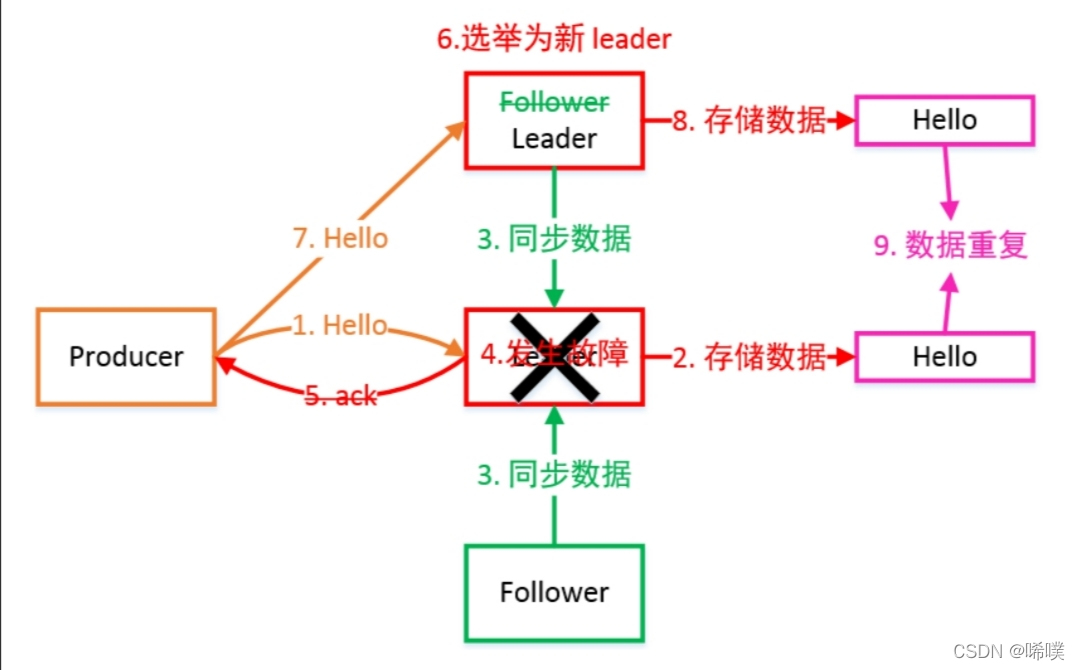
下面给出此时leader出现故障的情况,可以看出,此时数据可能重复。
解释上面出现的几个名词。Leader维护了⼀个动态的 in-sync replica set(ISR):和 Leader 保持同步的 Follower 集合。当 ISR 集合中的 Follower 完成数据的同步之后,Leader 就会给 Follower 发送 ACK。如果 Follower ⻓时间未向 Leader 同步数据,则该 Follower 将被踢出 ISR 集合,该时间阈值由replica.lag.time.max.ms 参数设定。Leader 发⽣故障后,就会从 ISR 中选举出新的 Leader。
kafka服务端中min.insync.replicas。 如果我们不设置的话,默认这个值是1。一个leader partition会维护一个ISR列表,这个值就是限制ISR列表里面 至少得有几个副本,比如这个值是2,那么当ISR列表里面只有一个副本的时候,往这个分区插入数据的时候会报错。
Consumer 采⽤ Pull(拉取)模式从 Broker 中读取数据。Pull 模式则可以根据 Consumer 的消费能⼒以适当的速率消费消息。Pull 模式不⾜之处是,如果Kafka 没有数据,消费者可能会陷⼊循环中,⼀直返回空数据。因为消费者从 Broker 主动拉取数据,需要维护⼀个⻓轮询,针对这⼀点, Kafka 的消费者在消费数据时会传⼊⼀个时⻓参数 timeout。如果当前没有数据可供消费,Consumer 会等待⼀段时间之后再返回,这段时⻓即为 timeout。
⼀个 Consumer Group 中有多个 Consumer,⼀个 Topic 有多个 Partition。不同组间的消费者是相互独立的,相同组内的消费者才会协作,这就必然会涉及到Partition 的分配问题,即确定哪个 Partition 由哪个 Consumer 来消费。
Kafka 有三种分配策略:
当消费者组内消费者发⽣变化时,会触发分区分配策略(⽅法重新分配),在分配完成前,kafka会暂停对外服务。注意为了尽量确保消息的有序执行,一个分区只能对应一个消费者,这也说明消费者的数量不能超过分区的数量。
Range ⽅式是按照主题来分的,不会产⽣轮询⽅式的消费混乱问题,但是也有不足。
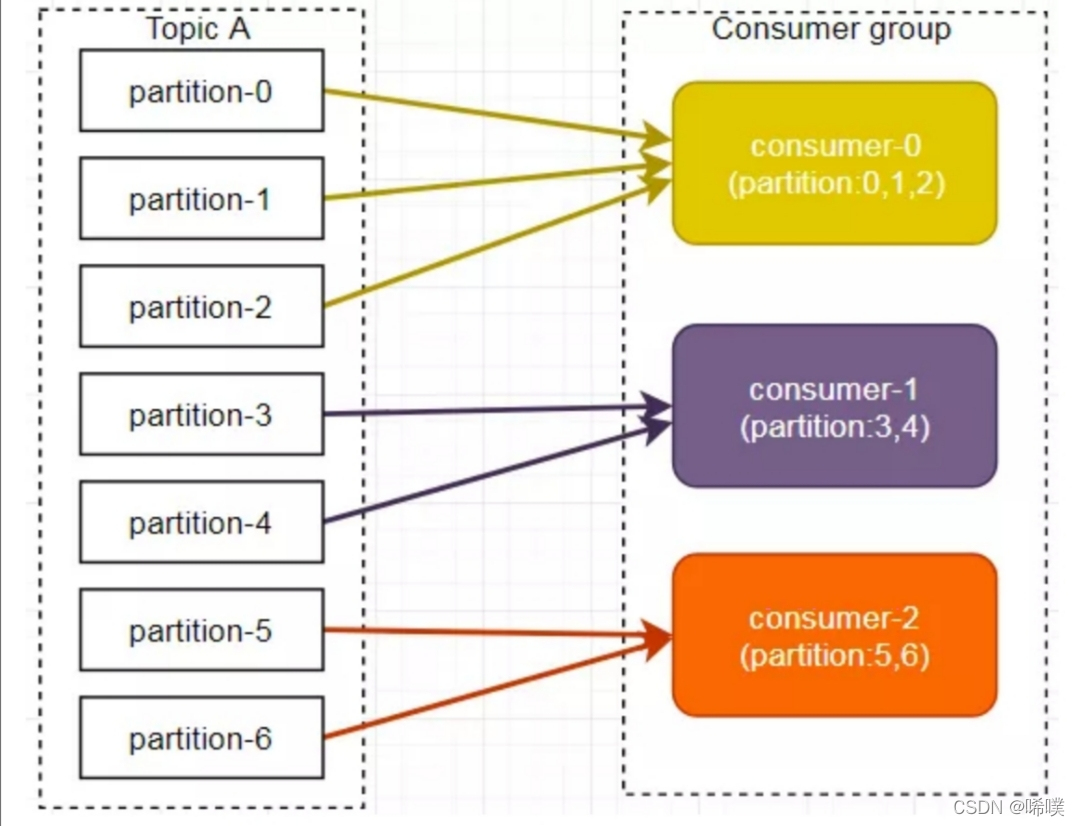
注意图文不符,图片是一个例子,文字再给一个例子,以便理解。假设我们有10个分区,3个消费者,排完序的分区将会是0,1,2,3,4,5,6,7,8,9;消费者线程排完序将会是C1-0,C2-0,C3-0。然后将partitions的个数除于消费者线程的总数来决定每个消费者线程消费⼏个分区。如果除不尽,那么前⾯⼏个消费者线程将会多消费⼀个分区。
在我们的例⼦⾥⾯,我们有10个分区,3个消费者线程, 10/3 = 3,⽽且除不尽,那么消费者线程 C1-0将会多消费⼀个分区:C1-0 将消费 0, 1, 2, 3 分区;C2-0将消费 4,5,6分区;C3-0将消费 7,8,9分区。
假如我们有11个分区,那么最后分区分配的结果看起来是这样的:
C1-0将消费 0,1,2,3分区;C2-0将消费 4,5,6,7分区;C3-0 将消费 8, 9, 10 分区。
假如我们有2个主题(T1和T2),分别有10个分区,那么最后分区分配的结果看起来是这样的:
C1-0 将消费 T1主题的 0, 1, 2, 3 分区以及 T2主题的 0, 1, 2, 3分区
C2-0将消费 T1主题的 4,5,6分区以及 T2主题的 4,5,6分区
C3-0将消费 T1主题的 7,8,9分区以及 T2主题的 7,8,9分区
这就可以看出,C1-0 消费者线程⽐其他消费者线程多消费了2个分区,这就是Range strategy的⼀个很明显的弊端。如下图所示,Consumer0、Consumer1 同时订阅了主题 A 和 B,可能造成消息分配不对等问题,当消费者组内订阅的主题越多,分区分配可能越不均衡。
RoundRobin 轮询⽅式将分区所有作为⼀个整体进⾏ Hash 排序,消费者组内分配分区个数最⼤差别为 1,是按照组来分的,可以解决多个消费者消费数据不均衡的问题。
轮询分区策略是把所有partition和所有consumer线程都列出来,然后按照hashcode进⾏排序。最后通过轮询算法分配partition给消费线程。如果所有consumer实例的订阅是相同的,那么partition会均匀分布。
在上面的例⼦⾥⾯,假如按照 hashCode排序完的topic-partitions组依次为T1-5,T1-3,T1-0,T1-8,T1-2,T1-1,T1-4,T1-7,T1-6,T1-9,我们的消费者线程排序为C1-0,C1-1,C2-0,C2-1,最后分区分配的结果为:
C1-0将消费 T1-5,T1-2,T1-6分区;
C1-1将消费 T1-3,T1-1,T1-9分区;
C2-0将消费 T1-0,T1-4分区;
C2-1将消费 T1-8,T1-7分区。
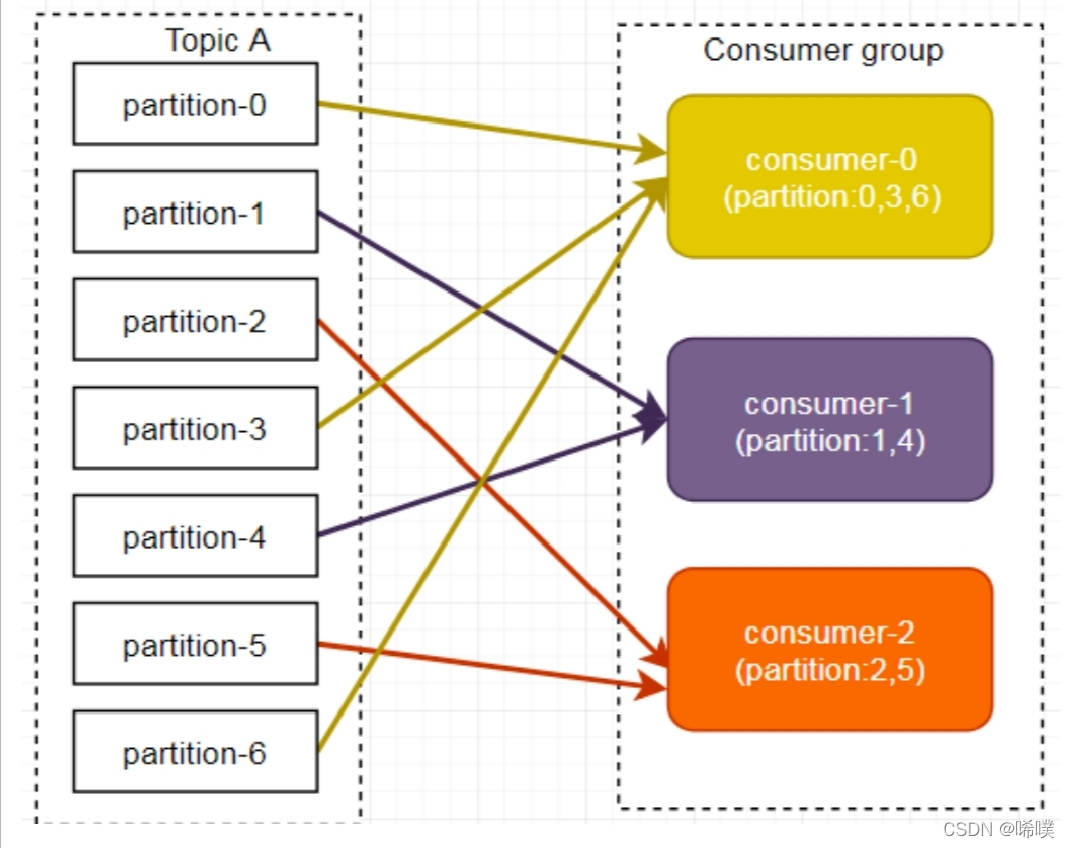
图文不符。
但是,当消费者组内订阅不同主题时,可能造成消费混乱,如下图所示,Consumer0 订阅主题A,Consumer1 订阅主题 B。
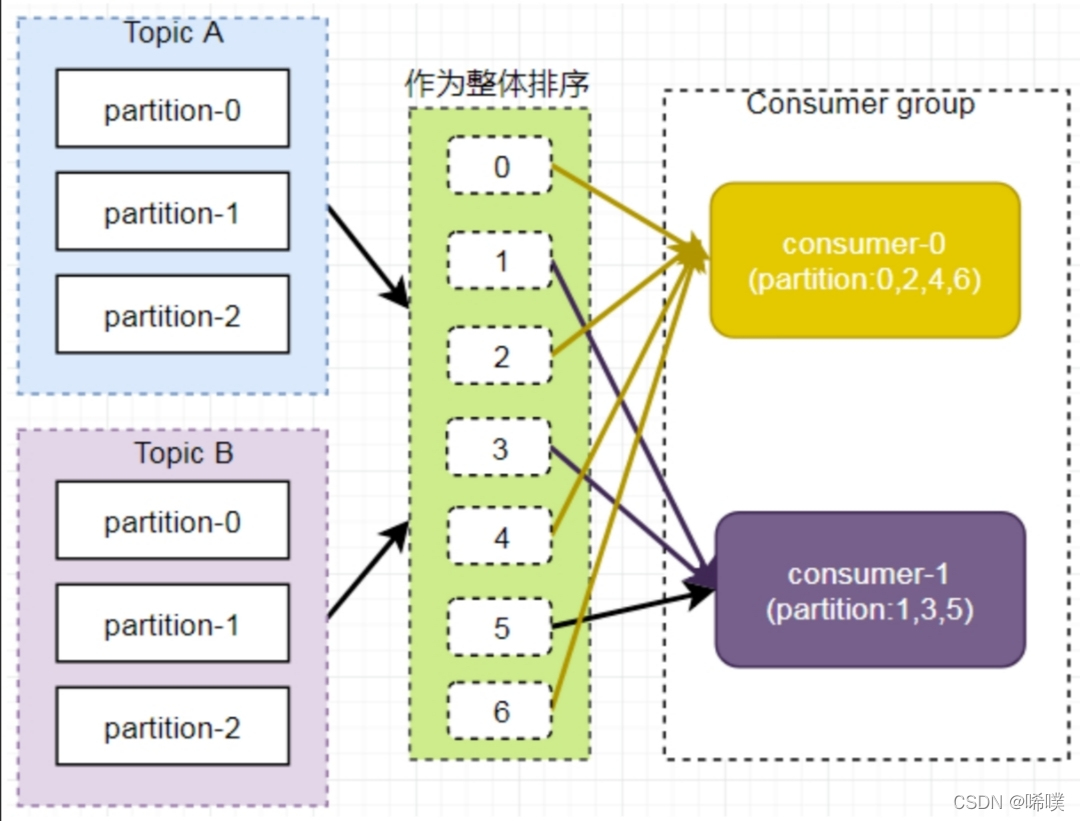
将 A、B 主题的分区排序后分配给消费者组,TopicB 分区中的数据可能分配到 Consumer0 中。
因此,使⽤轮询分区策略必须满⾜两个条件:
注意,其实对于生产者而言,可以自定义push但哪个分区中,也可以使用如hash等方法。
前两种rebalance方式需要重新映射,代价较大,特别是由于rebalance期间会暂停服务,这就要求该过程尽量短。Sticky在没有rebalance时采用轮询方式,发生rebalance时,尽量保持原映射关系,只是改变与宕机相关的映射,依然采用轮询的方式。
在前面ack保障消息到了broker之后,消费者也需要有⼀定的保证,因为消费者也可能出现某些问题导致消息没有消费到。
这里介绍一下偏移量。每个consumer内存里数据结构保存对每个topic的每个分区的消费offset,定期会提交offset,0.9版本以后,提交offset发送给kafka内部额外生成的一个topic:__consumer_offsets,提交过去的时候, key是group.id+topic+分区号,value就是当前offset的值,每隔一段时间,kafka内部会对这个topic进行compact(合并),也就是每个group.id+topic+分区号就保留最新数据。
这里引入enable.auto.commit,默认为true,也就是⾃动提交offset,⾃动提交是批量执⾏的,有⼀个时间窗⼝,这种⽅式会带来重复提交或者消息丢失的问题,所以对于⾼可靠性要求的程序,要使⽤⼿动提交。对于⾼可靠要求的应⽤来说,宁愿重复消费也不应该因为消费异常⽽导致消息丢失。当然,我们也可以使用策略来避免消息的重复消费与丢失,比如使用事务,将offset与消息执行放在同一数据库中。
最后再简单介绍一个应用。kafka可以用在分布式延时队列中。创建一个额外的主题和一个定时进程,检测这个主题中是否有消息过期,过期后放在常规的消息队列中,消费者从这个常规的队列中获取消息来消费。
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。Region的结构hbaseregion的大小设置默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的RegionServer,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的RegionServer。RegionSplit时机:当1个region中的某个Store下所有StoreFile
昨晚看到IDEA官推宣布IntelliJIDEA2023.1正式发布了。简单看了一下,发现这次的新版本包含了许多改进,进一步优化了用户体验,提高了便捷性。至于是否升级最新版本完全是个人意愿,如果觉得新版本没有让自己感兴趣的改进,完全就不用升级,影响不大。软件的版本迭代非常正常,正确看待即可,不持续改进就会慢慢被淘汰!根据官方介绍:IntelliJIDEA2023.1针对新的用户界面进行了大量重构,这些改进都是基于收到的宝贵反馈而实现的。官方还实施了性能增强措施,使得Maven导入更快,并且在打开项目时IDE功能更早地可用。由于后台提交检查,新版本提供了简化的提交流程。IntelliJIDEA
介绍pytest是一个非常成熟的全功能的Python测试框架,主要有以下几个特点:简单灵活,容易上手支持参数化能够支持简单的单元测试和复杂的功能测试,还可以用来做selenium/appnium等自动化测试、接口自动化测试(pytest+requests)pytest具有很多第三方插件,并且可以自定义扩展,比较好用的如pytest-selenium(集成selenium)、pytest-html(完美html测试报告生成)、pytest-rerunfailures(失败case重复执行)、pytest-xdist(多CPU分发)等测试用例的skip和xfail处理可以很好的和jenkins集成
一、解决痛点使用spring-kafka客户端,每次新增topic主题,都需要硬编码客户端并重新发布服务,操作麻烦耗时长。kafkaListener虽可以支持通配符消费topic,缺点是并发数需要手动改并且重启服务。对于业务逻辑相似场景,创建新主题动态监听可以用kafka-batch-starter组件二、组件能力1、新增topic名称为:auto.topic1(由于配置spring.kafka.consumer.prefix为auto,因此只有auto前缀的topic,才会被组件动态监听。)2、应用输出日志,监听到新增auto.topic1,并初始化客户端(主题刷新间隔为10s)3、发新的消
📝学技术、更要掌握学习的方法,一起学习,让进步发生👩🏻作者:一只IT攻城狮。💐学习建议:1、养成习惯,学习java的任何一个技术,都可以先去官网先看看,更准确、更专业。💐学习建议:2、然后记住每个技术最关键的特性(通常一句话或者几个字),从主线入手,由浅入深学习。❤️《SpringCloud入门实战系列》解锁SpringCloud主流组件入门应用及关键特性。带你了解SpringCloud主流组件,是如何一战解决微服务诸多难题的。项目demo:源码地址👉🏻SpringCloud入门实战系列不迷路👈🏻:SpringCloud入门实战(一)什么是SpringCloud?SpringCloud入门实战
文章目录一,什么是kaliPurle(卡利紫)二,如何安装kaliPurple。(有步骤没图片直接是默认)1,复制它的下载链接到迅雷可以让你下镜像变得更快。2,打开你的虚拟机创建新的虚拟机3,点击后面浏览然后找到镜像的所在地选中确定,下一步4,这里默认就可以,因为Ubuntu和这个差不多架构。5,然后,名字自己改一下,然后把他安到你想要装的盘,容量默认。之后一直下一步就可以**6,打开它,然后第一个图形界面安装,直接回车,然后选中文点continue之后没有图片的直接点继续。7,密码想设什么设什么。然后一直继续到我的图片那里改一下就可以了。8,软件默认就行。9,耐心等待。然后点手动配置dvc然
1.Zookeeper Zookeeper是 ApacheHadoop 的子项目,是一个树型的目录服务,支持变更推送,适合作为Dubbo服务的注册中心,工业强度较高。 Zookeeper的功能主要是它的树形节点来实现的。当有数据变化的时候或者节点过期的时候,会通过事件触发通知对应的客户端数据变化了,然后客户端再请求zookeeper获取最新数据,采用push-pull来做数据更新。服务注册和消费信息直接存储在zk树形节点上,集群下采用过半机制保证服务节点间一致性。 2.Nacos Nacos是 Alibaba 公司推出的开源工具,用于实现分布式系统的服务发现与配置管理。Nacos是Dub
我使用Kafka流媒体从KAFKA主题中消费。(KafkaDirect流)此主题中的数据每5分钟从另一个来源到达。现在,我需要处理每5分钟后到达的数据,并将其转换为SparkDataFrame。现在,流是数据的连续流。我的问题是,如何确定我已经完成了在Kafka主题中加载的第一组数据的阅读?(以便我可以将其转换为数据框架并开始我的工作)我知道我可以提及某个数字的批处理间隔(在JavastreamingContext中),但是即使那样,我也永远无法确定源将数据将数据推到主题的时间。欢迎任何建议。看答案如果我正确理解您的问题,您希望不创建批处理,直到阅读5分钟的所有数据。开箱即用的Spark不会提
目录关于MPU6050芯片关于小板关于厂家和DATASHEET关于漂移关于角加速度还是角速度关于精度和量程(可调,可选)关于功耗,陀螺仪+加速器工作电流:3.8mA(全功率,陀螺仪在所有速率下,在1kHz采样率下加速)采样率高,功耗也高可以参考 MPU6050陀螺仪与Processing和匿名上位机飞控联动实录-知乎关于MPU6050芯片MPU6050传感器模块是6轴运动跟踪设备。包含3轴陀螺仪、3轴加速度计、运动处理器、温度传感器。I2C总线接口,可与微控制器进行通信。通过辅助I2C总线与其他传感器设备通信,如3轴磁力计、压力传感器等。如果3轴磁力计连接到辅助I2C总线,则MPU6050可
MySQL为您提供了一个有用的字符串函数REPLACE(),它允许您用新的字符串替换表的列中的字符串。REPLACE()函数的语法如下:REPLACE(str,old_string,new_string);SQLREPLACE()函数有三个参数,它将string中的old_string替换为new_string字符串。注意:有一个也叫作REPLACE的语句用于插入或更新数据。所以不要将REPLACE语句与这里的REPLACE字符串函数混淆。REPLACE()函数非常方便搜索和替换表中的文本,例如更新过时的URL,纠正拼写错误等。在UPDATE语句中使用REPLACE函数的语法如下:UPDATE