文章目录
m个样本,共n个指标, X i j X_{ij} Xij为为第 i i i个样本的第 j j j个指标的数值, i = 1 , 2 , 3 , . . . m ; j = 1 , 2 , 3... n . i = 1 , 2 , 3 , . . . m ; j = 1 , 2 , 3... n. i=1,2,3,...m;j=1,2,3...n.
各项指标的计量单位以及方向不统一的情况下,需要对对数据进行标准化,为了避免求熵值时对数无意义,可以为每个值加上较小数量级的实数,如0.001
X ′ = X i j − M i n ( X i j ) M a x ( X i j ) − M i n ( X i j ) X'= \frac{X_{ij}- Min(X_{ij})}{Max(X_{ij})-Min(X_{ij})} X′=Max(Xij)−Min(Xij)Xij−Min(Xij)
X ′ = M a x ( X i j ) − X i j M a x ( X i j ) − M i n ( X i j ) X' = \frac{Max(X_{ij})-X_{ij}}{Max(X_{ij})-Min(X_{ij})} X′=Max(Xij)−Min(Xij)Max(Xij)−Xij
计算样本权重:
P
i
j
=
X
i
j
∑
i
=
1
n
X
i
j
P_{ij} = \frac{X_{ij}}{\sum_{i=1}^nX_{ij}}
Pij=∑i=1nXijXij
计算指标熵值:
e
j
=
−
1
l
n
(
m
)
∗
∑
i
=
1
m
(
P
i
j
∗
l
n
(
P
i
j
)
)
e_j = -\frac{1}{ln(m)}*\sum_{i=1}^m(P_{ij}*ln(P_{ij}))
ej=−ln(m)1∗i=1∑m(Pij∗ln(Pij))
,其中m为样本个数。
某项指标的信息效用值取决于该指标的信息熵与 1 之间的差值,它的值直接影响权重的大小。信息效用值越大,对评价的重要性就越大,权重也就越大。
d
j
=
1
−
e
j
d_j=1-e_j
dj=1−ej
利用熵值法估算各指标的权重,其本质是利用该指标信息的差异系数来计算,其差异系数越高,对评价的重要性就越大(或称权重越大,对评价结果的贡献就越大)
第j jj项指标的权重:
w
j
=
d
j
∑
j
=
1
m
d
j
w_j=\frac{d_j}{\sum_{j=1}^md_j}
wj=∑j=1mdjdj
z i = ∑ j = 1 m w j x i j z_i=\sum_{j=1}^mw_jx_{ij} zi=j=1∑mwjxij
| 样品编号 | 氨基酸总量 | 天门冬氨酸 | 苏氨酸 | 丝氨酸 | 谷氨酸 | 脯氨酸 |
|---|---|---|---|---|---|---|
| 葡萄样品1 | 2027.96 | 101.22 | 393.42 | 77.61 | 266.6 | 723.88 |
| 葡萄样品2 | 2128.82 | 64.43 | 140.62 | 71.94 | 39.26 | 1560.97 |
| 葡萄样品3 | 8397.28 | 108.07 | 222.35 | 173.08 | 67.54 | 7472.28 |
| 葡萄样品4 | 2144.68 | 79.39 | 133.83 | 158.74 | 156.72 | 1182.23 |
| 葡萄样品5 | 1844 | 52.28 | 145.09 | 164.05 | 102.43 | 816.08 |
| 葡萄样品6 | 3434.17 | 68.01 | 102.42 | 75.78 | 80.6 | 2932.76 |
| 葡萄样品7 | 2391.16 | 65.1 | 267.76 | 239.2 | 208.97 | 1096.28 |
| 葡萄样品8 | 1950.76 | 72.09 | 345.87 | 44.23 | 176.02 | 962.01 |
import numpy as np
import pandas as pd
## 读取数据
data=pd.read_csv('redputao.csv',encoding='utf-8',index_col=0)
indicator=data.columns.tolist() ## 指标个数 多少列
project=data.index.tolist() ## 样本个数 多少行
value=data.values
print(indicator)
print(project)
print(value)
## 定义数据标准化函数。为了避免求熵值时对数无意义,对数据进行平移,对标准化后的数据统一加了常数0.001
def std_data(value,flag):
for i in range(len(indicator)):
if flag[i]=='+':
value[:,i]=(value[:,i]-np.min(value[:,i],axis=0))/(np.max(value[:,i],axis=0)-np.min(value[:,i],axis=0))+0.01
elif flag[i]=='-':
value[:,i]=(np.max(value[:,i],axis=0)-value[:,i])/(np.max(value[:,i],axis=0)-np.min(value[:,i],axis=0))+0.01
return value
# 定义熵值法函数、熵值法计算变量的权重
def cal_weight(indicator, project, value):
p = np.array([[0.0 for i in range(len(indicator))] for i in range(len(project))])
# print(p)
for i in range(len(indicator)):
p[:, i] = value[:, i] / np.sum(value[:, i], axis=0)
e = -1 / np.log(len(project)) * sum(p * np.log(p)) # 计算熵值
g = 1 - e # 计算一致性程度
w = g / sum(g) # 计算权重
return w
# 表示各项指标为正向指标还是反向指标
flag=["+","+","+","+","+", "+","+","+","+","+",
"+","+","+","+","+", "+","+","+","+","+",
"+","+","+","+","+", "+","+","+","+","+",
"+","+","+","+","+", "+","+","+","+","+",
"+","+","+","+","+", "+","+","+","+","+",
"+","+","+","+"]
# 调用函数将数据标准化,即为每个数据添加正相关还是负相关标志
std_value=std_data(value, flag)
# 调用函数求权重
w = cal_weight(indicator, project, std_value)
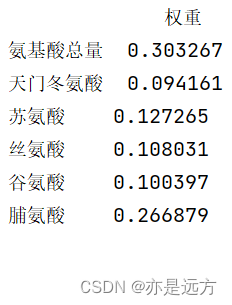
w = pd.DataFrame(w, index=data.columns, columns=['权重'])
print(w)
# 调用函数求得分
score = np.dot(std_value, w).round(4) # 对应数据与权重相乘得到分数,结果保留四位小数
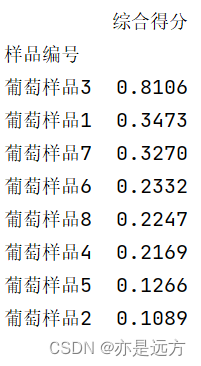
score = pd.DataFrame(score, index=data.index, columns=['综合得分']).sort_values(by=['综合得分'], ascending=False)
print(score)
运行结果
csv下载链接 提取码:1234
关闭。这个问题需要debuggingdetails.它目前不接受答案。编辑问题以包含desiredbehavior,aspecificproblemorerror,andtheshortestcodenecessarytoreproducetheproblem.这将有助于其他人回答问题。关闭3年前。Improvethisquestion这是整个HTML文档:Top5ImportersofTungsten@font-face{font-family:Planewalker;src:url('https://dl.dropboxusercontent.com/s/3hn6zi8ez2vf4
我有一个图,有X个节点和Y个边。加权边缘。重点是从一个节点开始,并在最后一个位置的另一个节点停止。现在问题来了:将问题可视化。边缘是道路,边缘权重是在道路上行驶的车辆的最大重量限制。我们想驾驶最大的卡车从A到F。我想要从A到F的所有路径的最大允许重量。我可以使用某种Dijkstra算法来解决这个问题吗?我不确定如何以我可以实现的算法的形式来表达这个问题。任何帮助深表感谢。我很困惑,因为Dijkstra算法只考虑最短路径。 最佳答案 如果我没理解错的话,你想找到一些具有最大瓶颈边的节点之间的路径。也就是说,你想要最小边尽可能大的路径。
我的XML文件的TextView权重属性有问题。我在没有ScrollView的情况下添加了Weight属性,当时它可以正常工作,但是当我添加ScrollView时它无法正常工作。解决方案可接受谢谢 最佳答案 实际上是scrollView没有达到全高,为此你应该添加android:fillViewport="true"在你的ScrollView中。你可以在这里查看我的答案AndroidTableLayoutinsideScrollView然后试试这个xml,我已经在我的机器上检查过了:--
让我们假设:List哪个元素是:publicclassElement{intWeight{get;set;}}我想实现的是,根据权重随机选择一个元素。例如:Element_1.Weight=100;Element_2.Weight=50;Element_3.Weight=200;所以机会Element_1被选中是100/(100+50+200)=28.57%机会Element_2被选中是50/(100+50+200)=14.29%机会Element_3被选中的是200/(100+50+200)=57.14%我知道我可以创建循环、计算总数等...我想了解的是,Linq在一行(或尽可能短)
我正在从表中随机检索4行。但是,我希望它能为刚插入表中的行赋予更多权重,而不会对较旧的行造成太大影响。有没有办法在PHP/SQL中做到这一点? 最佳答案 SELECT*,(RAND()/id)ASoFROMyour_tableORDERBYoLIMIT4这将按o排序,其中o是0到1之间的某个随机整数/id,这意味着,您的行越旧,它的o值就越低(但仍然是随机顺序)。 关于php-加权随机性。我怎样才能给刚刚添加到数据库中的行更多的权重?,我们在StackOverflow上找到一个类似的问题
假设我想从1-10中随机选择一个数字,但每个数字都有权重。1-15%chance2-15%chance3-12%chance4-12%chance5-10%chance6-10%chance7-8%chance8-8%chance9-5%chance10-5%chance我将如何在PHP中对此进行编码? 最佳答案 我假设您的百分比总和为100%?用构建一个数组15timesa'1'value,15timesa'2'value,...10timesa'6'value,8timesa'7'value,...5times1'10'valu
我想通过让它在操作系统而不是Apache上运行来平衡Web应用程序上的大量进程。我可以通过shell执行该过程来做到这一点,但我认为在这种情况下最好也征求其他人的意见。这是场景;用户登录应用点击过程继续在服务器上处理,同时让用户执行他/她的正常事件。注意:用户不应该被进程打断,应该是并行进程。 最佳答案 考虑在将持续运行的服务器上启动单独的进程,将从PHP脚本接收工作单元,执行它们并返回结果。PHP脚本和这个过程可能会使用数据库来交换工作单元,所以当PHP有一些工作时,它会将工作描述插入到数据库中。当单独的进程准备好工作时,它查询数
非常重要的编辑:所有Ai都是独一无二的。问题我有一个Anunique对象列表。每个对象Ai都有一个可变百分比Pi。我想创建一个算法,生成k个对象的新列表B(kn/2并且在大多数情况下k明显小于n/2。例如n=231,k=21)。列表B不应有重复项,并将填充来自列表A的对象,但有以下限制:TheprobabilitythatanobjectAiappearsinBisPi.我尝试过的(这些snipits在PHP中只是为了测试目的)我首先列出了A$list=["A"=>2.5,"B"=>2.5,"C"=>2.5,"D"=>2.5,"E"=>2.5,"F"=>2.5,"G"=>2.5,"H"
[3D检测系列-PointRCNN] 复现PointRCNN代码1.下载代码2.准备数据集(1)使用官网提供的数据集格式(2)使用软连接3.检测结果4.结果可视化(1)仅显示LiDAR(2)显示LiDAR和图像 (3)显示具有特定索引的LiDAR和图像(4)显示带有modifiedLiDARfile附加点云标签/标记的LiDAR作为第5维先附上环境配置:Ubuntu18.04python3.6pytorch1.8.0 torchvision0.9.0 cuda11.1(这几个先不急着装,后面有教程)mayavi4.7.1 vkt8.2.0 traits6.2.0 traitsui7.2.1
文章目录前言一、抛出问题及解决思路1、问题现象2、问题解决思路3、需求二、新增这个自定义Similarity1、编写TzzSolrSimilarity类2、放置TzzSolrSimilarity-1.0-SNAPSHOT.jar3、下载配置4、managed-schema新增配置5、修改solrconfig.xml6、使用solr用户更新配置集7、重启solr服务总结前言本篇文章通过介绍“有重复词汇的前提下,调整一个文档中,term在文档命中的频率对分数和排名的影响,如何降低词频对得分的影响”案例,来教你Solr/Elasticsearch如何自定义Similarity。。一、抛出问题及解决思