目录
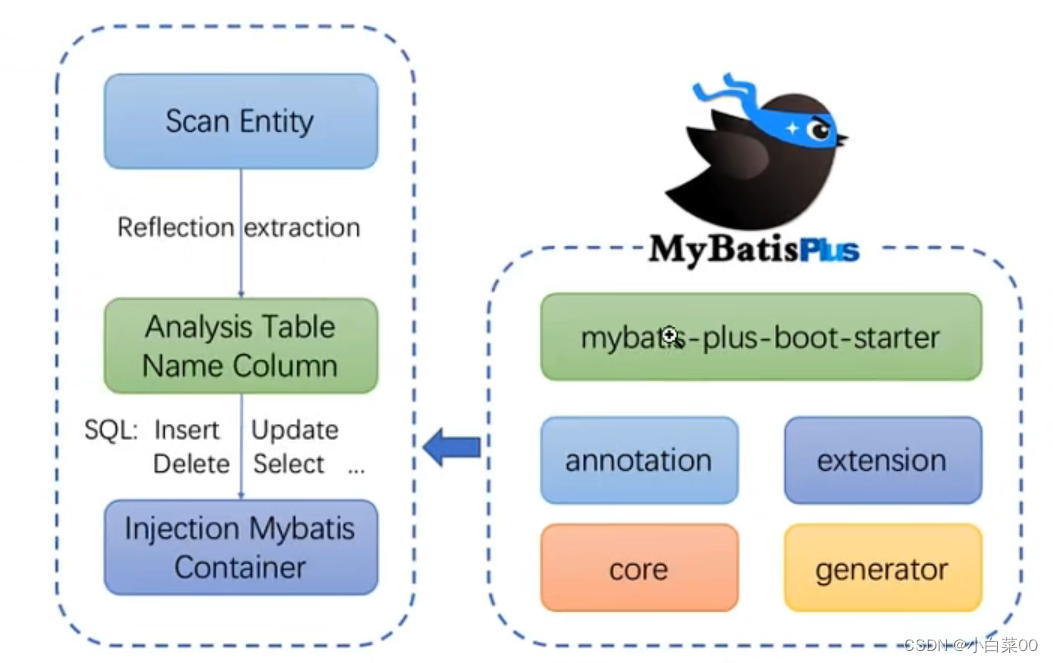
含义:mybatis-plus是个mybatis的增强工具,在mybatis的基础上只做增强不做改变,为简化开发,提高效率而生
注意:我们可以直接在mybatis的基础上直接去集成mybatisplus,这样并不会影响mybatis的功能,同时我们也可以使用他所提供的功能。
理解:
<dependencies>
<!--springboot启动器-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!--springboot测试-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--lombok依赖-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!--MP启动器-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
<!--mysql驱动包--><!--测试功能的启动器-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>spring:
#设置数据源信息
datasource:
#配置数据源类型
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql:///mybatis_plus?characterEncoding=utf-8&userSSL=false&serverTimezone=GMT%2B8
username: root
password: root
mybatis-plus:
configuration:
#MP提供了日志功能
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
#驼峰映射(默认就是开启的)
map-underscore-to-camel-case: true
#设置MP的全局配置
global-config:
db-config:
#这样设置的话,那么实体类所有的表都会加上t_前缀
table-prefix: t_
#设置统一主键生成策略
id-type: auto
#映射文件路径
mapper-locations: classpath:/mapper/UserMapper.xml
#配置类型别名所对应的包
type-aliases-package: cn.tedu.mybatisplus.pojo
#扫描通用枚举的包
type-enums-package: cn.tedu.mybatisplus.enums//使用MP提供的通用mapper——BaseMapper
//BaseMapper里的泛型表示实体类的类型
@Mapper
public interface UserMapper extends BaseMapper<User> {
}注意:
注意:使用前注入userMapper
User user = new User();
user.setName("lili").setAge(23).setEmail("lili@qq.com");
int insert = userMapper.insert(user);
System.out.println(insert);
//mybatis-plus会自动获取id
System.out.println(user.getId()); int i = userMapper.deleteById(7);
System.out.println(i); Map<String,Object> map=new HashMap<>();
map.put("name", "张三");
map.put("age", 23);
//删除name为张三,age为23的人
int i = userMapper.deleteByMap(map);
System.out.println(i); List<Long> list = Arrays.asList(1L, 2L, 3L);
int i = userMapper.deleteBatchIds(list);
System.out.println(i); User user = new User();
user.setId(3L).setName("lan").setEmail("lan@qq.com");
//根据id修改元素
int i = userMapper.updateById(user);
System.out.println(i); User user = userMapper.selectById(1L);
System.out.println(user); List<Long> list = Arrays.asList(1L, 2L, 3L);
List<User> users = userMapper.selectBatchIds(list);
users.forEach(System.out::println); HashMap<String, Object> map = new HashMap<>();
map.put("name", "lan");
map.put("age", 28);
List<User> users = userMapper.selectByMap(map);
//list会直接打印对象数组
System.out.println(users);说明:通用Service封装了IService接口,进一步封装了CRUD采用get查询单行,remove删除,list查询集合,page分页等前缀命名方式,区分Mapper层,避免混淆
//service接口
public interface UserService extends IService<User> {
}//service实现类
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
}注意:
//查询总记录数
long count = userService.count();
System.out.println(count); ArrayList<User> list = new ArrayList<>();
for (int i = 1; i <=10 ; i++) {
User user = new User();
user.setName("cjc"+i).setAge(10+i);
list.add(user);
}
//批量添加数据
boolean b = userService.saveBatch(list);
//操作成功或失败
System.out.println(b);//设置实体类所对应的表名,若对象与表名一致,则表名中()可以省略
@TableName("t_user")
public class User {
//将当前属性对应的字段指定为主键(将该属性与数据库中的id字段进行映射),并通过雪花算法生成主键id
//type标识主键的生成策略为自动递增,要求数据库的主键为自增策略(默认为雪花算法——IdType.ASSIGN.ID)
@TableId(value = "id")
private Long id;
//将该注解标识的属性与数据库中的name字段一一映射,若属性名与字段名相同,则注解可省略
@TableField(value = "name")
private String name;
private Integer age;
private String email;
//逻辑删除0标识未删除,1标识已删除
//被逻辑删除的数据用户查不到,但是可以在数据库中看到,只是该属性变为1;(为修改操作)
@TableLogic
private Integer isDeleted;
}注意:@TableField(exit=false)注解一般用在注入的属性上,被该注解标识表名当前属性不参与MP的操作
背景:需要合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量
数据库表的扩展方式:业务分库、主从复制、数据库分表
数据库分表的两种方式

将重要的数据放到一个表中,不在业务查询中用到的独立到另一个表中,以提升一定的性能
主键自增:比如按照范围分表(1-9999放入表一,10000-20000放入表二)
取模:主键%数据库个数,余数相同的放入一个表中
雪花算法:
雪花算法是由Twitter分布式主键生成算法,他保证不同表的主键的不重复性,以及相同表的主键的有序性
核心思想:

优点:整体上按照时间自增排序,并且整个分布式系统内不会产生id碰撞
作用:封装当前的条件

AbstractWrapper:用于条件查询封装,生成sql的where条件
AbstractLambdaWrapper
//通过条件构造器查询一个list集合,若没有条件则可以设置null(相当于查询所有)
List<User> users = userMapper.selectList(null);
users.forEach(System.out::println); //查询name为lei的主键字段
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("name", "lei");
List<Object> list = userMapper.selectObjs(queryWrapper);
System.out.println(list); //查询用户名包含a,年龄在20-30之间,邮箱信息不为null的用户信息
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
//queryWrapper可以实现链式加载
queryWrapper.like("name", "a").between("age", 20, 30).isNotNull("email");
List<User> users = userMapper.selectList(queryWrapper);
System.out.println(users); //对象形式
User user = new User();
user.setAge(28);
QueryWrapper<User> queryWrapper = new QueryWrapper<>(user);
List<User> users = userMapper.selectList(queryWrapper);
System.out.println(users);
//user内的属性最终会以and形式拼接 //in查询,查询id为1,2,3的数据
Integer[] ids={1,2,3};
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.in("id",ids);
List<User> users = userMapper.selectList(queryWrapper);
System.out.println(users); //查询id>2的用户,按照年龄降序排序,若年两相同则按照id升序排序
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.gt("id", 2).orderByDesc("age").orderByAsc("id");
List<User> users = userMapper.selectList(queryWrapper);
System.out.println(users);转义字符
//删除邮箱地址为null的用户信息
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.isNull("email");
int i = userMapper.delete(queryWrapper);
System.out.println(i); //将年龄>20并且用户名中包含a或邮箱为null的用户进行修改(默认情况下就是and连接)
//修改条件
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.gt("age", 20).like("name", "a").or().isNull("email");
User user = new User();
user.setName("lei").setEmail("test@cj.com");
int i = userMapper.update(user, queryWrapper);
System.out.println(i); //将用户名中包含a并且(年龄大于20或邮箱为null)的用户信息进行修改
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
//lambda中的条件优先执行(i就表示条件构造器)
queryWrapper.like("name", "a").and(i-> i.gt("age", 20).or().isNull("email"));
User user = new User();
user.setName("red").setEmail("test@cj.com");
int i = userMapper.update(user, queryWrapper);
System.out.println(i); //查询出来一个以map为泛型的list集合
//查询用户名、年龄、邮箱信息
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.select("name","age","email");
List<Map<String, Object>> maps = userMapper.selectMaps(queryWrapper);
System.out.println(maps); //select * from t_user where id in(select id from t_user where id<=100)
//查询id<=100的用户信息
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.inSql("id", "select id from t_user where id<=100");
List<User> users = userMapper.selectList(queryWrapper);
System.out.println(users); String name=null;
String age="21";
//判断字符串是否为null或空串若为返回false,不为返回true
boolean pn = StringUtils.hasLength(name);
boolean pa = StringUtils.hasLength(age);
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
//判断属性是否为true,为true则执行该条件,不为则忽略该条件
queryWrapper.eq(pn,"name",name).eq(pa, "age", age);
List<User> users = userMapper.selectList(queryWrapper);
System.out.println(users);注意:queryWrapper.clear();为清除多余的条件,清除后queryWrapper可以继续使用
//查询用户名中包含a(年龄>20或邮箱为null)的员工信息
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
//修改条件
updateWrapper.like("name", "a").and(i->i.gt("age", 20).isNull("email"));
//修改内容
updateWrapper.set("name", "lala").set("email", "www@cjc.com");
int i = userMapper.update(null, updateWrapper);
System.out.println(i);作用:防止我们太笨,而把字段名写错进而提供了一个函数式接口来访问我们实体类中的某一个属性,当我们把属性访问之后,那么他就可以自动的获取属性所对应的字段名,来当作作为条件的哪个字段
String name="a";
Integer ageBegin=null;
Integer ageEnd=30;
//主要避免了名称写错进而提供了直接访问表达式::
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.like(StringUtils.isNotBlank(name), User::getName,name)
.ge(ageBegin!=null, User::getAge,ageBegin)
.le(ageEnd!=null, User::getAge,ageEnd);
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users); //查询用户名中包含a(年龄>20或邮箱为null)的员工信息
LambdaUpdateWrapper<User> updateWrapper = new LambdaUpdateWrapper<>();
//修改条件
updateWrapper.like(User::getName, "a").and(i->i.gt(User::getAge, 20).isNull(User::getEmail));
//修改内容
updateWrapper.set(User::getName, "lala").set(User::getEmail, "www@cjc.com");
int i = userMapper.update(null, updateWrapper);
System.out.println(i);@Configuration
public class MPConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
//创建mybatisplus拦截器
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
//向拦截器中添加分页插件
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}//测试类内
//两个参数——当前页页码,每页信息条数
Page<User> page = new Page<>(2,3);
//两个参数——分页对象,条件构造器
userMapper.selectPage(page, null);//因为我对所有的查询所以条件构造器为null——返回值还为page
//获取当前页数据
List<User> records = page.getRecords();
System.out.println(records);
//获取总记录数
long total = page.getTotal();
System.out.println(total);
//获取总页数
long pages = page.getPages();
System.out.println(pages);
//是否有下一页
System.out.println(page.hasNext());
//是否有上一页
System.out.println(page.hasPrevious());//自定义接口:
//mybatisplus提供的分页对象,必须为于第一个参数的位置
Page<User> selectPageVo(@Param("page") Page<User> page,@Param("age") Integer age);
//自定义配置文件sql
<select id="selectPageVo" resultType="User">
select id,name,age,email from t_user where age>#{age}
</select> //测试类
Page<User> page = new Page<>(2, 2);
userMapper.selectPageVo(page,20);
//获取当前页数据
List<User> records = page.getRecords();
System.out.println(records);
//获取总记录数
long total = page.getTotal();
System.out.println(total);
//获取总页数
long pages = page.getPages();
System.out.println(pages);
//是否有下一页
System.out.println(page.hasNext());
//是否有上一页
System.out.println(page.hasPrevious());@Data
public class Product {
private Long id;
private String name;
private Integer price;
@Version//用来标识乐观锁版本号字段
private Integer version;
}@Configuration
public class MPConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
//创建mybatisplus拦截器
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
//向拦截器中添加乐观锁插件
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
return interceptor;
}
}注意:下面小王和小李拿的是同一个数据
//小李查询商品价格
Product productLi = productMapper.selectById(1);
System.out.println("小李"+productLi.getPrice());
//小王查询商品价格
Product productWang = productMapper.selectById(1);
System.out.println("小王"+productWang.getPrice());
//小李将商品价格+50
productLi.setPrice(productLi.getPrice()+50);
productMapper.updateById(productLi);
//小王将商品价格-30
productWang.setPrice(productWang.getPrice()-30);
int result = productMapper.updateById(productWang);
if (result==0){
//操作失败后重试
Product productNew = productMapper.selectById(1);
productNew.setPrice(productNew.getPrice()-30);
productMapper.updateById(productNew);
}实体类中有枚举类型,那么怎么将该枚举类型存入到数据库中呢
//为该枚举添加注解
@Getter
public enum SexEnum {
MALE(1,"男"),
FEMALE(2,"女");
@EnumValue//将注解所标识的属性的值存储到数据库中(因为数据库中存放的是数字)
private Integer sex;
private String sexName;
SexEnum(Integer sex, String sexName) {
this.sex = sex;
this.sexName = sexName;
}
}配置通用枚举扫描包
mybatis-plus.type-enums-package=cn.tedu.mybatisplus.enums将有枚举的对象插入到数据库
@Component
public class MyMetaObjectHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
this.setFieldValByName("created", new Date(), metaObject);
this.setFieldValByName("updated", new Date(), metaObject);
}
@Override
public void updateFill(MetaObject metaObject) {
this.setFieldValByName("updated", new Date(), metaObject);
}
}@Data
@Accessors(chain = true)
public class Product {
private Long id;
private String name;
private Integer price;
//在插入数据时自动填充
@TableField(fill = FieldFill.INSERT)
private Date created;
//在插入和更新操作时自动填充
@TableField(fill = FieldFill.INSERT_UPDATE)
private Date updated;
@Version//用来标识乐观锁版本号字段
private Integer version;
} //测试
Product product = new Product();
product.setName("cake").setId(3L).setPrice(66);
int insert = productMapper.insert(product);
System.out.println(insert);
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
文章目录一、项目场景二、基本模块原理与调试方法分析——信源部分:三、信号处理部分和显示部分:四、基本的通信链路搭建:四、特殊模块:interpretedMATLABfunction:五、总结和坑点提醒一、项目场景 最近一个任务是使用simulink搭建一个MIMO串扰消除的链路,并用实际收到的数据进行测试,在搭建的过程中也遇到了不少的问题(当然这比vivado里面的debug好不知道多少倍)。准备趁着这个机会,先以一个很基本的通信链路对simulink基础和相关的debug方法进行总结。 在本篇中,主要记录simulink的基本原理和基本的SISO通信传输链路(QPSK方式),计划在下篇记
【动态规划】一、背包问题1.背包问题总结1)动规四部曲:2)递推公式总结:3)遍历顺序总结:2.01背包1)二维dp数组代码实现2)一维dp数组代码实现3.完全背包代码实现4.多重背包代码实现一、背包问题1.背包问题总结暴力的解法是指数级别的时间复杂度。进而才需要动态规划的解法来进行优化!背包问题是动态规划(DynamicPlanning)里的非常重要的一部分,关于几种常见的背包,其关系如下:在解决背包问题的时候,我们通常都是按照如下五部来逐步分析,把这五部都搞透了,算是对动规来理解深入了。1)动规四部曲:(1)确定dp数组及其下标的含义(2)确定递推公式(3)dp数组的初始化(4)确定遍历顺
1,Camera基本工作原理答案:光线通过镜头Lens进入摄像头内部,然后经过IRFilter过滤红外光,最后到达sensor(传感器),senor分为按照材质可以分为CMOS和CCD两种,可以将光学信号转换为电信号,再通过内部的ADC电路转换为数字信号,然后传输给DSP(如果有的话,如果没有则以DVP的方式传送数据到基带芯片baseband,此时的数据格式RawData,后面有讲进行加工)加工处理,转换成RGB、YUV等格式输出。数据流是如何从sensor到APP的?上述描述结束后,在ISP处理后面的阶段,数据会进行分流,分为capture,preview,video等以供后续动作使用。例如
📢博客主页:https://blog.csdn.net/dxt19980308📢欢迎点赞👍收藏⭐留言📝如有错误敬请指正!📢本文由肩匣与橘编写,首发于CSDN🙉📢生活依旧是美好而又温柔的,你也是✨目录🔴线性表1.1顺序表1.1.1顺序表定义1.1.2顺序表基本操作1.2单链表1.2.1单链表节点定义1.2.2单链表基本操作1.3双链表1.3.1双链表节点定义1.3.2双链表基本操作1.4静态链表🟠栈和队列2.1栈2.1.1顺序栈2.1.2链式栈2.2队列2.2.1顺序队列2.2.2链式队列2.3应用🟡串3.1串的定义与实现3.2串的模式匹配🟢树与二叉树4.1二叉树4.1.1二叉树的概念4.1.2
目录MyBatisPlusMP特点MP框架结构MP使用准备导入依赖springboot整合mybatisplus配置文件定义好实体类User后编辑mapper接口@Mapper与@MapperScan("包名")区别MP基本操作新增操作删除操作通过id删除用户通过map作为条件删除通过多个id实现删除更新用户通过id进行用户更新查询用户 根据id查询用户根据多个id查询用户根据map集合作为条件查询用户通用Service接口一些操作 查询总记录数批量添加数据MP常用注解雪花算法前言垂直分表水平分表条件构造器继承结构使用条件构造器实现查询操作查询所有用户根据构造器查询主键字段集合根据条件构造器查
本文总结了在以太坊智能合约中使用Solidity在合约内创建合约以及引用其他合约的方法,包括了如何使用mochai进行测试的方法。在这之前先明白一个比较:Contract{}相当于面向对象语言的类当部署后获得到address后,address相当于对象,address0x.......本身就类似指针地址然后我们讨论下Solidity代码中对合约类,合约对象的操作。Solidity首先区分下三种写法:import'ContractB.sol';ConractBB=newConractB(arg1,arg2...);ContractBB=ContractB(Baddress);functionse
智慧医院不良事件精细化管理平台——微信小程序总结一、实现的功能二、项目收获三、总结(经历分享)一、实现的功能到目前为止,微信小程序开发,到此就算是结束了,其中实现了不少功能,如下:1.1角色与权限(后端同学实现的,写这个方便介绍后面的功能)平台可以配置不同的用户角色并授予其不同的操作权限。每个用户在使用平台时都需要指定一个角色。1.2可视范围——根据角色绑定的权限菜单全体职工可以查看自己上报的事件(待审核、已通过、被驳回)。质控人员可以查看所有的事件(待审核、待评价、已通过、已驳回、已评价)。职能人员可以查看自己/自己部门负责的事件(待整改、待评价、已评价)。各科室医务人员可以查看本科室相关的
我得到了[objectObject]9778177结果,我尝试解析该值但都无济于事,出了点问题。letx=[{"total_count":7},{"total_count":9},{"total_count":778},{"total_count":177}]letsum=x.reduce((accum,obj)=>{returnaccum+obj.total_count})console.log(sum) 最佳答案 您可以添加一个起始值,因为第一次迭代从累加器的对象开始,而您没有所需的属性。letsum=x.reduce((acc
一、知识框架二、练习题调节一个装瓶机使其对每个瓶子的灌装量均值为μ盎司,通过观察这台装瓶机对每个瓶子的灌装量服从标准差σ=1.0盎司的正态分布。随机抽取这台机器灌装的9个瓶子组成一个样本,并测定每个瓶子的灌装量。试确定样本均值偏离总体均值不超过0.3盎司的概率。解:设每个瓶子的灌装量为X,X为样本均值,样本容量为n。由于总体X服从正态分布,样本均值X也服从正态分布,且均值相同,标准差为所以三、简述题1什么是统计量?为什么要引进统计量?统计量中为什么不含任何未知参数?答:(1)统计量的定义:设X1,X2,…,Xn是从总体X中抽取的容量为n的一个样本,如果由此样本构造一个函数T(X1,X2,…,X