从github上下载CLAM代码,上传Camelyon-16中的部分WSI图像,将代码跑通。
CLAM项目地址:
按如下代码进行配置,参考链接:https://github.com/mahmoodlab/CLAM/blob/master/docs/INSTALLATION.md
// (1)安装openslide-tools
sudo apt-get install openslide-tools
// (2)使用项目已经写好的库依赖创建环境
conda env create -n clam -f docs/clam.yaml
// (3)由于topk库必须使用github安装,因而先退出CLAM文件夹克隆topk库,并进行安装
git clone https://github.com/oval-group/smooth-topk.git
cd smooth-topk
python setup.py install但是由于我的CUDA版本为11.4,clam.yaml中安装的pytorch版本过低会导致与CUDA版本不匹配的问题。前一篇博文已解决此问题,参考链接
关于pytorch与CUDA版本匹配问题_DragonJ__的博客-CSDN博客
CLAM所用需要使用WSI图像,本人所用数据集为Camelyon16,下载地址
Data - Grand Challenge (grand-challenge.org)
在下载后数据集按如何方式组织在项目主文件夹下建立一个Original_Image文件夹,并把所下载数据集放到该文件夹下,如下:
数据集调整好后,为方便模型的训练需要对WSI进行切片,并存储相应的坐标,运行如下代码:
// Original_Image文件夹下存储原始WSI图像
// Split Image下存储切片后的图像坐标相关信息
python create_patches_fp.py --source Original_Image --save_dir Split_Image --patch_size 256 --seg --patch --stitch
切割完成后会在主目录下得到Split_Image文件夹,并按如下方式进行组织:

CLAM首先使用预训练的ResNet50提取图像特征,执行如下代码:
// 其中process_list.csv为切割patch自动生成的process_list_autogen.csv去掉文件名的后缀得到的
// Extracted_feature 为提取后的特征的存储路径
CUDA_VISIBLE_DEVICES=0,1 python extract_features_fp.py --data_h5_dir Split_Image/ --data_slide_dir Original_Image/ --csv_path Split_Image/process_list.csv --feat_dir Extracted_feature/ --batch_size 512 --slide_ext .tif
在执行特征提取后,特征会提取到Extracted_Feature文件夹下,以.pt文件格式存储,Extracted_Feature文件夹下目录如下:

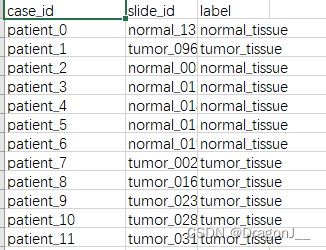
在训练开始前需要将数据集划分为训练集、验证集、测试集。这里是按照csv文件进行划分,共需要两个调整。首先在dataset_csv文件夹下创建一个test.csv文件,包含所有的样例,内部内容如下:
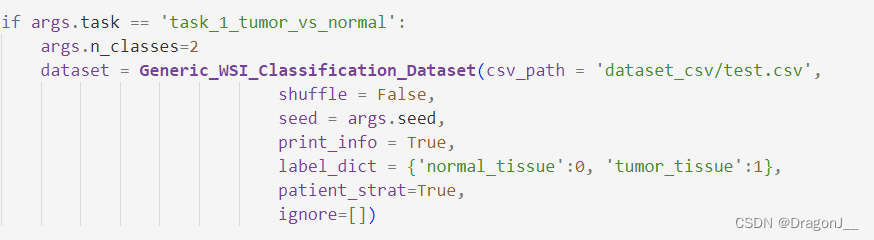
其次更改create_splits_seq代码将csv文件路径更改到test.csv,更改部分如下:
最后执行如下代码:
// 训练集占75%,共划分10次,类似10折交叉验证,每次划分均随机且不同。
python create_splits_seq.py --task task_1_tumor_vs_normal --seed 1 --label_frac 0.75 --k 10
划分后会在splits/task_1_tumor_vs_normal文件夹下产生10次划分的结果如下:
模型训练需要更改main.py中csv文件路径,如下:

随后输入如下代码即可训练:
CUDA_VISIBLE_DEVICES=0 python main.py --drop_out --early_stopping --lr 2e-4 --k 10 --label_frac 0.75 --exp_code task_1_tumor_vs_normal_CLAM_75 --weighted_sample --bag_loss ce --inst_loss svm --task task_1_tumor_vs_normal --model_type clam_sb --log_data --data_root_dir Extracted_feature
上篇说到RK3588编译OpenCV,这篇记录一下跑通YOLOv5+DeepSORT的愉(chi)快(shi)历程.1.保证编译OpenCV时关联了ffmpeg如果本身缺少ffmpeg而编译了没有ffmpeg版本的OpenCV,则视频无法读取.解决方案参照CSDN,首先安装ffmpeg:sudoaptinstall-yffmpeg之后安装一堆dev:libavcodec-dev、libavformat-dev、libavutil-dev、libavfilter-dev、libavresample-dev、libswresample-dev、libswscale-dev这个时候再去编译OpenC
本人小白,寒假期间学习了一些ROS知识,试着在虚拟机搭建ORB_SLAM3环境并跑通数据集和摄像头,作本文以记录学习过程。所有用到的资源(软件安装包,镜像文件,库的源码文件都会放在最后百度网盘链接里)目录0.somethingyoushouldknow1.安装VMwareWorkstationPro和Ubuntu18.042.安装ROS3.安装ORB_SLAM3所需的各种库和依赖4.编译ORB_SLAM3并在非ROS环境下跑通数据集&跑自己录制的Video5.编译ORB_SLAM3ROS接口实时跑USB单目摄像头0.somethingyoushouldknow#你需要知道什么是终端,怎么唤起终
文章目录关于StableDiffusionLexica代码实现安装依赖库登陆huggingface查看huggingfacetoken下载模型计算生成设置宽高测试迭代次数生成多列图片关于StableDiffusionAlatenttext-to-imagediffusionmodelStableDiffusion是一个文本到图像的潜在扩散模型,由CompVis、StabilityAI和LAION的研究人员和工程师创建。它使用来自LAION-5B数据库子集的512x512图像进行训练。使用这个模型,可以生成包括人脸在内的任何图像,因为有开源的预训练模型,所以我们也可以在自己的机器上运行它。
项目场景:从github上下载CLAM代码,上传Camelyon-16中的部分WSI图像,将代码跑通。CLAM项目地址:GitHub-mahmoodlab/CLAM:Data-efficientandweaklysupervisedcomputationalpathologyonwholeslideimages-NatureBiomedicalEngineeringData-efficientandweaklysupervisedcomputationalpathologyonwholeslideimages-NatureBiomedicalEngineering-GitHub-mahmood
目录1.一些可用的参考链接2.开始训练yolov72.1--weights2.2--cfg2.3--data2.4--hyp2.5--epochs2.6--batch-size2.7--workers2.8--name1.一些可用的参考链接官方YOLOv7项目地址:https://github.com/WongKinYiu/yolov7如果想设置早停机制,可以参考这个链接:yolov7自动停止(设置patience)且输出最优模型时的PR图(testbest.py)学习train.py中的参数含义,可参考手把手调参最新YOLOv7模型训练部分-最新版本(二)学习detect.py中的参数含义,
目录1.一些可用的参考链接2.开始训练yolov72.1--weights2.2--cfg2.3--data2.4--hyp2.5--epochs2.6--batch-size2.7--workers2.8--name1.一些可用的参考链接官方YOLOv7项目地址:https://github.com/WongKinYiu/yolov7如果想设置早停机制,可以参考这个链接:yolov7自动停止(设置patience)且输出最优模型时的PR图(testbest.py)学习train.py中的参数含义,可参考手把手调参最新YOLOv7模型训练部分-最新版本(二)学习detect.py中的参数含义,
写在前面:这里整理了111个数据分析的案例,每一个都进行了严格的筛选,筛选标准如下:1.有干货:杜绝纯可视化、统计性分析,有一定比例的讲解性文字2.可跑通:所有代码均经过测试,(大概率)可以一键跑通(因为库包更新,或者链接有效性问题,或多或少会存在个别失效情况)数据集可下载:方便大家下载至本地仔细把玩(如果不行,请看我的另一篇博文)希望这份资料可以帮到大家呀~电商数据分析:只会环比下降3%的数据分析师还有救吗?本文用一个实战案例,与大家共同探讨如何撰写一份有业务价值的分析报告教育平台线上课程用户行为分析(含数据可视化处理)此数据集来自泰迪杯个人技能赛,为企业真实数据。该作品为特等奖并获泰迪杯,
写在前面:这里整理了111个数据分析的案例,每一个都进行了严格的筛选,筛选标准如下:1.有干货:杜绝纯可视化、统计性分析,有一定比例的讲解性文字2.可跑通:所有代码均经过测试,(大概率)可以一键跑通(因为库包更新,或者链接有效性问题,或多或少会存在个别失效情况)数据集可下载:方便大家下载至本地仔细把玩(如果不行,请看我的另一篇博文)希望这份资料可以帮到大家呀~电商数据分析:只会环比下降3%的数据分析师还有救吗?本文用一个实战案例,与大家共同探讨如何撰写一份有业务价值的分析报告教育平台线上课程用户行为分析(含数据可视化处理)此数据集来自泰迪杯个人技能赛,为企业真实数据。该作品为特等奖并获泰迪杯,
下载Anaconda:(此处不建议下载到C盘,后续在此路径下载文件较多)Anaconda可以理解为一片土壤,我们的环境生长在这一片土壤上然后在搜索栏里可以找到并打开可以看到路径的前缀是base,这个可以理解为土壤上的大厅,里面会有不同的小房子,可以下载我们所需的不同安装包如何创建一个适用于自己项目的环境:以视频作者的Pix2PixGAN为例(1).GetStarted:首先是下载代码 下载:直接在Github上点击这里,有一个download可以下载下来,得到一个压缩包(2).InstallPyTorch 这里面给了适合不同用户的不同指令eg.第一个pipuser,直接运行后面那个指令即可完成
下载Anaconda:(此处不建议下载到C盘,后续在此路径下载文件较多)Anaconda可以理解为一片土壤,我们的环境生长在这一片土壤上然后在搜索栏里可以找到并打开可以看到路径的前缀是base,这个可以理解为土壤上的大厅,里面会有不同的小房子,可以下载我们所需的不同安装包如何创建一个适用于自己项目的环境:以视频作者的Pix2PixGAN为例(1).GetStarted:首先是下载代码 下载:直接在Github上点击这里,有一个download可以下载下来,得到一个压缩包(2).InstallPyTorch 这里面给了适合不同用户的不同指令eg.第一个pipuser,直接运行后面那个指令即可完成
 https://github.com/mahmoodlab/CLAM
https://github.com/mahmoodlab/CLAM