🏆作者提出了一个单目相机的视频序列进行深度估计与运动估计,作者的方法是完全无监督的,端到端的学习,作者使用了单视角深度网络和多姿态网络,提出了一个图像(predict)与真实的下一帧(goundturth)计算loss,作为无监督的依据,实现无监督学习。使用KITTI数据集证明了他们的有效性:1.合成的深度图与监督学习的方法是可比的;2. 在可比较的输入设置下,姿势估计与已建立的SLAM系统相比性能优越
文章目录

会议/期刊:CVPR2017
论文题目:《Unsupervised Learning of Depth and Ego-Motion from Video》
论文链接:Unsupervised Learning of Depth and Ego-Motion from Video (arxiv.org)
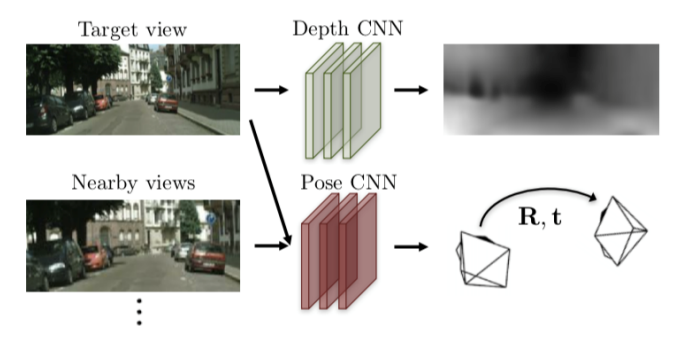
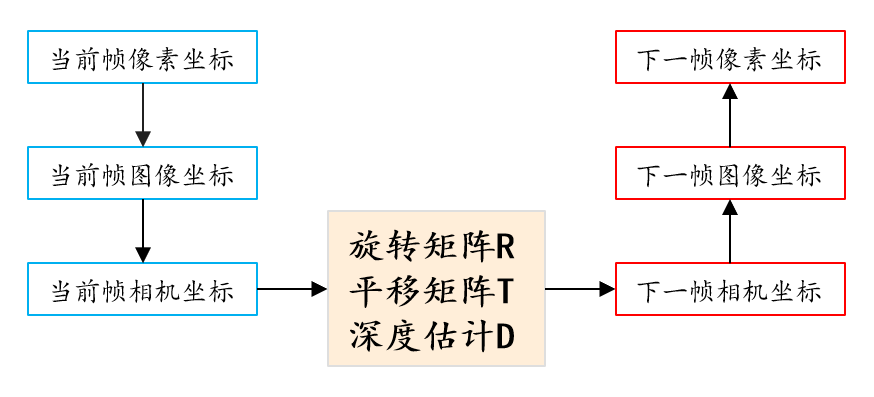
SfMLearner算法的原理:
利用Depth CNN对当前图像进行深度估计,得到当前图像的深度图
将相邻帧(包括当前帧、上一帧、下一帧)输入Pose CNN,得到旋转矩阵R和平移矩阵T,预测相机的位姿变化
将1、2得到的当前深度图和相邻帧对的R、T矩阵,计算出当前帧和下一帧的映射关系,然后将当前帧warp到下一帧
深度学习论文中的warp是指什么?
warp就是将一个图像上的点变换到另一张图像上
最后将warp出来的图像(predict)与真实的下一帧(goundturth)计算loss,作为无监督的依据,实现无监督学习
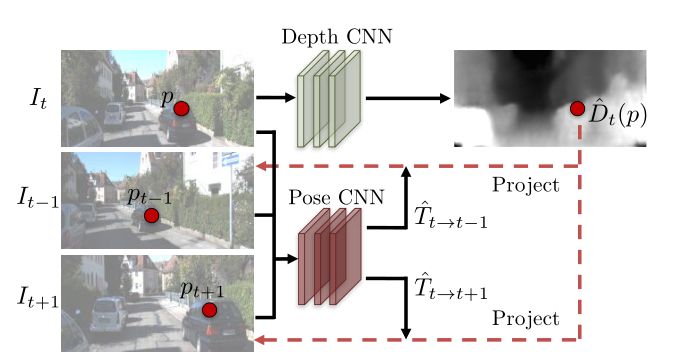
将当前帧 𝐼 𝑡 𝐼_𝑡 It 输入到 Depth CNN 并预测出当前帧的深度图 D t D_t Dt
将其与邻近帧 𝐼 𝑡 − 1 𝐼_{𝑡−1} It−1 和 𝐼 𝑡 + 1 𝐼_{𝑡+1} It+1 组成邻近帧对 { 𝐼 𝑡 , 𝐼 𝑡 − 1 𝐼_𝑡 , 𝐼_{𝑡−1} It,It−1} 和 { 𝐼 𝑡 , 𝐼 𝑡 + 1 𝐼_𝑡 , 𝐼_{𝑡+1} It,It+1} 分别输入到 Pose CNN,预测出六个自由度的帧间位姿变化( r x , r y , r z , t x , t y , t z r_x,r_y,r_z,t_x,t_y,t_z rx,ry,rz,tx,ty,tz)。可以得到旋转矩阵 𝑹 和平移矩阵 𝒕。
其中 R 为 3*3 的旋转矩阵,𝑡 =
[
𝑡
𝑥
,
𝑡
𝑦
,
𝑡
𝑧
]
[𝑡_𝑥 , 𝑡_𝑦 , 𝑡_𝑧 ]
[tx,ty,tz],𝑹 和 𝒕 合成为一个 4 *4 位姿变化矩阵
𝑇
𝑡
→
𝑠
𝑇_{𝑡→𝑠}
Tt→s
T
=
∣
R
t
0
T
1
∣
T=\left|\begin{array}{ll} \boldsymbol{R} & \boldsymbol{t} \\ \mathbf{0}^{T} & 1 \end{array}\right|{\color{Red} }
T=
R0Tt1
现在令
𝑝
𝑡
𝑝_𝑡
pt 为当前帧齐次像素坐标系下的坐标,
𝑝
𝑠
𝑝_𝑠
ps 为邻近 帧齐次像素坐标系下的坐标,根据 CNN 预测出的当前帧深度图
𝑫
𝑡
𝑫_𝑡
Dt 和帧间位姿 变化矩阵
𝑻
𝑡
→
𝑠
𝑻_{𝑡→𝑠}
Tt→s,可以得到
𝐼
𝑡
,
𝐼
𝑠
𝐼_𝑡 , 𝐼_𝑠
It,Is 帧间映射关系:
p
s
∼
K
T
t
→
s
D
t
(
p
t
)
K
−
1
p
t
p_{s} \sim \boldsymbol{K} \boldsymbol{T}_{t \rightarrow s} \boldsymbol{D}_{t}\left(p_{t}\right) \boldsymbol{K}^{-1} p_{t}{\color{Purple} }
ps∼KTt→sDt(pt)K−1pt
其中𝑲 为相机内参矩阵,在本文实验中相机内参矩阵 𝑲 是已知的。下面对该映射关系公式进行分析
当前帧的像素坐标系下坐标为
p
t
p_t
pt,首先要将坐标从像素坐标系转换到成像坐标系,成像坐标系:
𝑝
𝑡
’
𝑝_𝑡 ’
pt’ ∼
𝑲
−
1
𝑝
𝑡
𝑲^{−1}𝑝_𝑡
K−1pt,然后要将坐标从成像坐标系转换成相机坐标系,相机坐标系:
𝑝
𝑡
’’
∼
𝑫
𝑡
(
𝑝
𝑡
)
𝑝
𝑡
’
𝑝_𝑡 ’’ ∼ 𝑫_𝑡 (𝑝_𝑡 )𝑝_𝑡 ’
pt’’∼Dt(pt)pt’,即
𝑝
𝑡
’’
∼
𝑫
𝑡
(
𝑝
𝑡
)
𝑲
−
1
𝑝
𝑡
𝑝_𝑡 ’’ ∼ 𝑫_𝑡 (𝑝_𝑡 )𝑲^{−1}𝑝_𝑡
pt’’∼Dt(pt)K−1pt;此时坐标是三维坐标, 左乘位姿变化坐标就可以得到变换后的三维坐标:
𝑝
𝑠
’
=
𝑻
𝑡
→
𝑠
𝑝
𝑡
’’
𝑝_𝑠 ’ = 𝑻_{𝑡→𝑠}𝑝_𝑡 ’’
ps’=Tt→spt’’;最后将变换后的三维坐标从相机坐标系转换到像素坐标系:
𝑝
𝑠
∼
𝑲
𝑝
𝑠
’
𝑝_𝑠 ∼ 𝑲𝑝_𝑠 ’
ps∼Kps’,即:
p
s
∼
K
T
t
→
s
D
t
(
p
t
)
K
−
1
p
t
p_{s} \sim \boldsymbol{K} \boldsymbol{T}_{t \rightarrow s} \boldsymbol{D}_{t}\left(p_{t}\right) \boldsymbol{K}^{-1} p_{t}
ps∼KTt→sDt(pt)K−1pt
参考链接:https://blog.csdn.net/qq_46058802/article/details/126227358
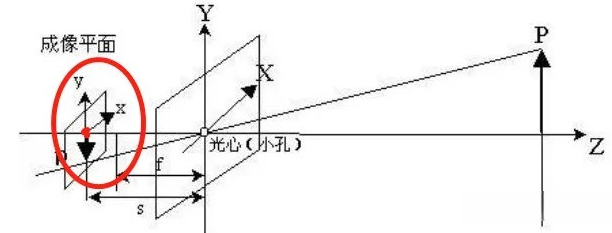
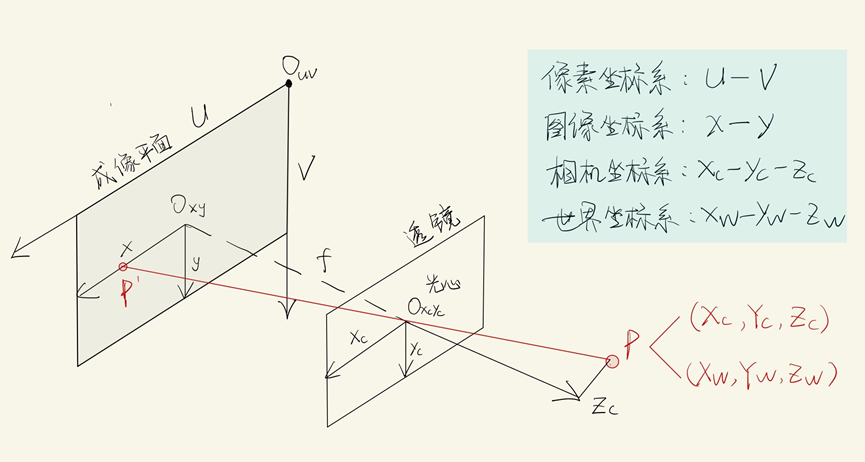
像素坐标系:像素坐标系的原点在左上角,并且单位为像素。比如一张224*224的图片,它的原点就在左上角的地方,然后x轴长224,y轴长224
成像坐标系:图像坐标系的坐标原点是成像平面的中心。例如:红色圈出来的区域,即是图像坐标系, 红色的原点,可以记为图像坐标系的原点
相机坐标系:下图红色坐标轴表示的,即是一个相机坐标。 与世界坐标非常像,只是世界坐标的原点是固定的,而相机坐标的原点,可以是任意的相机位置

😎世界坐标、相机坐标、图像坐标和像素坐标的关系:
最后,得到了帧间的像素级映射关系后,我们就可以像光流一样进行帧间的 warp 操作
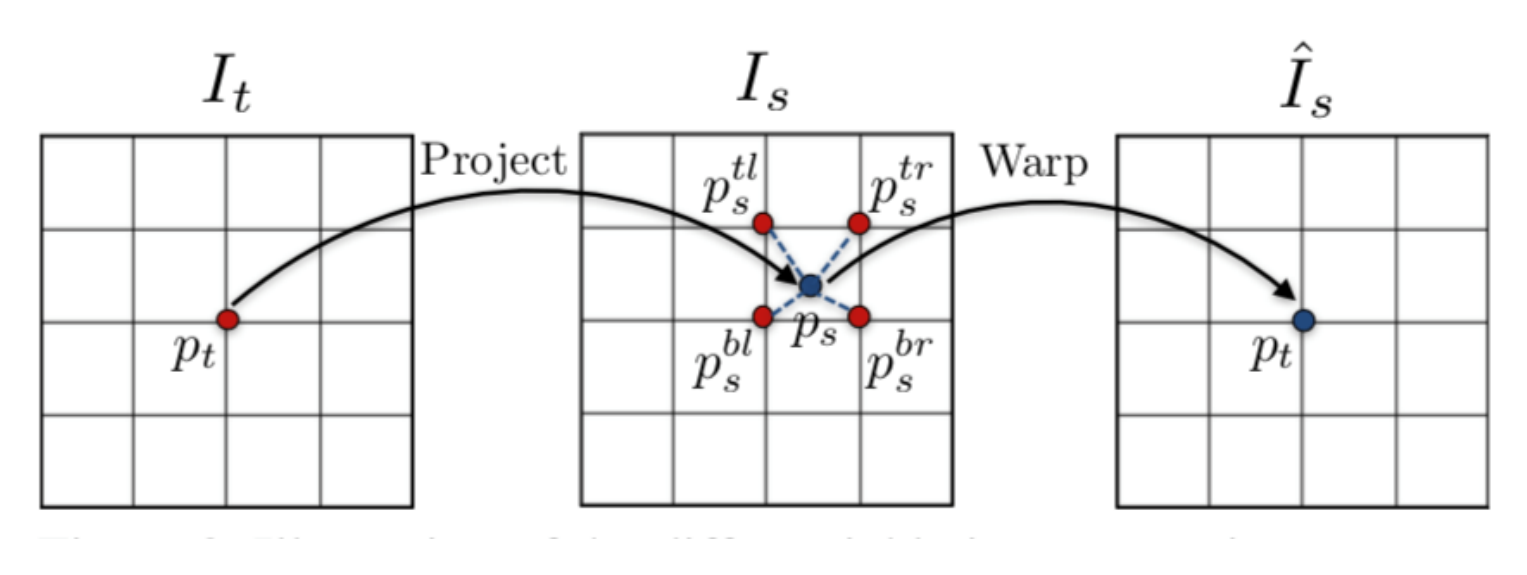
图中当前帧 𝐼 𝑡 𝐼_𝑡 It 上的像素点 𝑝 𝑡 𝑝_𝑡 pt 可以根据预测出的深度图和位姿变化矩阵,映射到 邻近帧 𝐼 𝑠 𝐼_𝑠 Is 上的 𝑝 𝑠 𝑝_𝑠 ps 点。该映射后的点不一定会刚好映射到 𝐼 𝑠 𝐼_𝑠 Is 的像素点上,而是大概率如图中一样,映射到由 𝐼 𝑠 𝐼_𝑠 Is 上的 𝑝 𝑠 𝑡 𝑙 𝑝^{𝑡𝑙}_𝑠 pstl , 𝑝 𝑠 𝑡 𝑟 𝑝^{𝑡𝑟}_𝑠 pstr , 𝑝 𝑠 𝑏 𝑙 𝑝^{𝑏𝑙} _𝑠 psbl , 𝑝 𝑠 𝑏 𝑟 𝑝^{𝑏𝑟}_𝑠 psbr 四个像素点组成的方格里。因 此这里和 DFF 的 warp 操作一样,要用双线性插值算法,求出 𝑝 𝑠 𝑝_𝑠 ps 的值,再将此值 返回给当前帧 𝐼 𝑡 𝐼_𝑡 It 的像素点 𝑝 𝑡 𝑝_𝑡 pt,从而完成 warp 操作
图片中没有运动的对象,场景是静态的
目标视图和源视图之间没有遮挡
表面是朗伯型的,使得光一致性误差是有意义的
朗伯面是指在一个固定的照明角度下从所有视场方向上观测都具有相同亮度的表面,也就是反射亮度是一个常数。理想朗伯面是物体表面对入射光进行完全的反射,吸收率为0
为了提高对第一点因素(图片中没有运动的对象,场景是静态的)的抗性,作者额外训练了一个解释模型。输出一个像素级的粗糙蒙版(掩码),用来过滤掉会运动的物体,该 mask 用于 loss 计算的时候,对运动 的物体赋予一个较小的权重,对背景区域赋予一个较大的权重,以实现让网络自动屏蔽掉对场景变换估计有干扰的区域
在下图中,Pose CNN和解释模型共享前面的解码器流程,然后分别扩展到预测6-DOF相对姿势和多尺度可解释性掩码两个分支网络。经过红色网络的即是解释模型
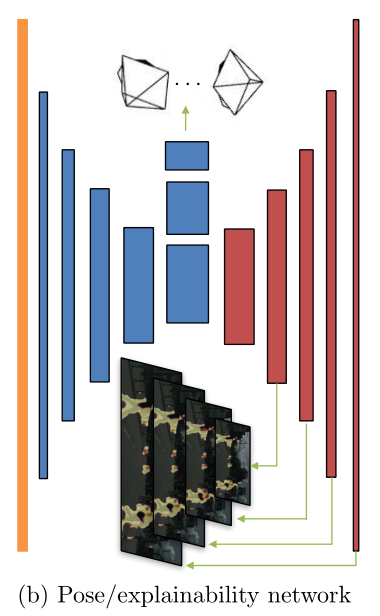
高亮的部分就是估计出来运动的对象,该块像素会被赋予一个比较低的权重计算loss

深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
目前我正在使用这个正则表达式从YoutubeURL中提取视频ID:url.match(/v=([^&]*)/)[1]我怎样才能改变它,以便它也可以从这个没有v参数的YoutubeURL获取视频ID:http://www.youtube.com/user/SHAYTARDS#p/u/9/Xc81AajGUMU感谢阅读。编辑:我正在使用ruby1.8.7 最佳答案 对于Ruby1.8.7,这就可以了。url_1='http://www.youtube.com/watch?v=8WVTOUh53QY&feature=feedf'url
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
进行这种深度检查的最佳方法是什么:{:a=>1,:b=>{:c=>2,:f=>3,:d=>4}}.include?({:b=>{:c=>2,:f=>3}})#=>true谢谢 最佳答案 我想我从那个例子中明白了你的意思(不知何故)。我们检查子哈希中的每个键是否在超哈希中,然后检查这些键的对应值是否以某种方式匹配:如果值是哈希,则执行另一次深度检查,否则,检查值是否相等:classHashdefdeep_include?(sub_hash)sub_hash.keys.all?do|key|self.has_key?(key)&&ifs
我有一个Rails应用程序,它从WorldWeatherOnlineAPI获取响应。我正在使用rest-clientgem,响应采用JSON格式。我使用以下方法解析响应:parsed_response=JSON.parse(response)parsed_response显然是一个散列。我需要的数据是哈希内的字符串,数组内的哈希,另一个数组内的哈希,另一个哈希内的另一个哈希内的字符串。最内层的嵌套散列在["hourly"]中,这是一个由8个散列组成的数组,每个散列有20个键,拥有各种天气参数的字符串值。数组中的每个哈希值都是一天中的不同时间(预测是每三小时一次,3*8=24小时)。因此
一、习惯约定图片来自PSINS(高精度捷联惯导算法)PSINS工具箱入门与详解.pptx二、基本旋转矩阵绕x轴逆时钟旋转α\alphaα角度Rx(α)=[ 1000cosαsinα0−sinαcosα]R_x(\alpha)=\begin{bmatrix}\1&0&0\\0&\cos\alpha&\sin\alpha\\0&-\sin\alpha&\cos\alpha\end{bmatrix}Rx(α)= 1000cosα−sinα0sinαcosα绕y轴逆时钟旋转α\alphaα角度Ry(α)=[ cosα0−sinα010sinα0cosα]R_y(\alpha
我的项目中有一个类别和子类别模型。我想以灵活的方式拥有许多子级别。我想制作一个self引用的“父”外键,但我不太确定该怎么做。有任何想法吗?谢谢!Cat1Sub1SubSub1SubSub2Sub2Cat2Sub1Cat3Sub1Sub2SubSub1 最佳答案 试试acts_as_tree插件 关于ruby-on-rails-在Rails中实现具有灵活深度的类别和子类别的最佳方法?,我们在StackOverflow上找到一个类似的问题: https://st